This topic describes common failure scenarios for a full and incremental synchronization task for an entire database and provides corresponding solutions.
Failure scenarios for real-time writes
Scenario | Related documentation |
Full and incremental synchronization tasks with no Binlog loss | |
Full and incremental synchronization tasks with Binlog loss | |
Merge task failures in a full and incremental synchronization task |
Scenarios without Binlog loss
An unsupported DDL statement causes the real-time task to fail.
Solution:
Go to the page, find the destination task, and then click . You can remove the table from the task, submit the task, and then re-add the table to trigger a resynchronization. This action skips the unsupported DDL statement for that table.
Edit the task and modify the DDL handling policy. You can set the policy to Ignore for the specific DDL type or configure an Alert to receive notifications for DDL events.
The real-time task fails due to dirty data.
A common cause is that a column type in the destination table is incompatible with the source data. Check the run logs of the real-time task and the content of the dirty data to determine if the source data or the destination table is causing the issue. If the destination table structure is the problem, recreate it to recover the real-time task.
Reload the table: Back up the original table. Then, edit the full and incremental synchronization task to remove the table. Then, re-add it and select the option to use the existing destination table. This process reloads the table data. Before reloading, ensure the destination table's fields are compatible with the source data to recover the task.
The task fails to write data to MaxCompute due to a Tunnel service issue.
Check the run logs of the real-time task. If you see errors such as
InternalServerErrororException when calling callable. Exception Msg: Read timed out, it indicates an issue with the Tunnel service. Contact MaxCompute support for troubleshooting. After the issue is resolved, restart the real-time task.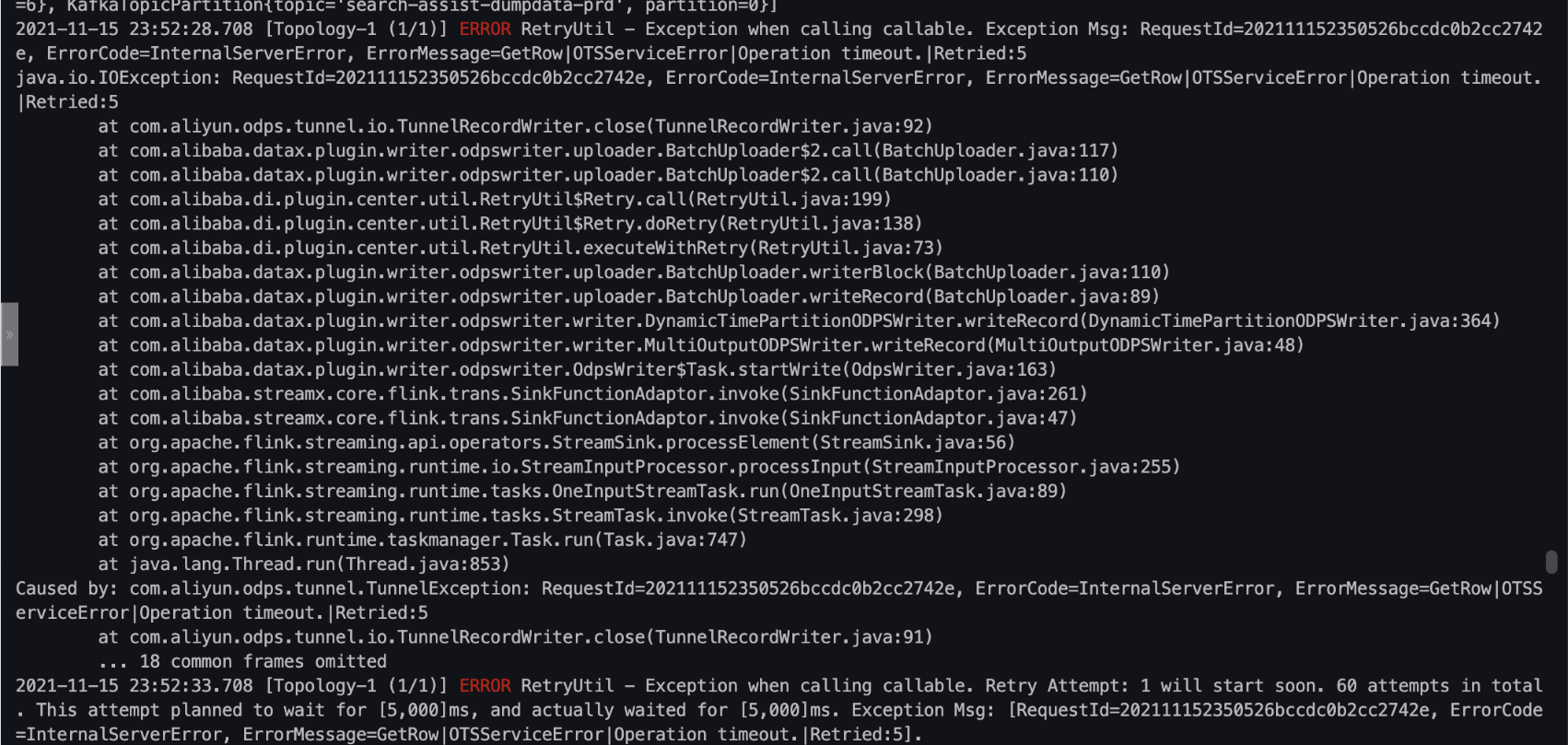
Scenarios with Binlog loss
If Binlog data is lost, incremental data cannot be fully backfilled. In this case, you need to re-initialize the full dataset and restart the incremental synchronization. Use the following methods to recover the task.
Recover with force rerun
Use cases
The real-time task has been failing for an extended period, which clears the Binlog and prevents incremental data backfill.
A new column is missing from the destination table.
Data in the destination table is missing or incorrect.
Procedure
Go to the page and find the destination task.
In the Actions column, choose . This forces a full and incremental initialization for all source tables and re-migrates the data to the destination tables for fast data recovery.
You can click Execution Details in the Actions column of the task to view run details.
ImportantBefore you rerun a full and incremental synchronization task for an entire database, check for potential conflicts with running or scheduled Merge task instances. If they run simultaneously with the same business date, partition data or table data might be overwritten.
You can check the status of the Merge task instance for the synchronization task on the View auto triggered instances page in the DataWorks Operation Center. If a conflict occurs, you can:
Postpone the rerun operation until the Merge task completes.
Freeze the upcoming Merge task instance, and then resume it after the rerun operation succeeds.
After the rerun is complete, do not perform other operations, such as full synchronization or adding or removing tables, until the synchronization pipeline is stable. Performing other operations invalidates the rerun, requiring you to run the task again.
After the rerun is complete, if the next day's data is not generated or the Merge task does not resume automatically, manually check and resume the Merge task instance:
If the real-time task is delayed, resolve the latency. For more information, see Solutions for real-time sync task latency.
If the instance from the previous cycle did not run or failed, remove its dependency on the previous cycle. For more information, see View auto triggered instances.
Recover by backfilling full data
Resume the task.
Go to the page and restart the destination task to resume incremental data collection first.
Backfill the full data.
Go to the page and find the destination task.
In the Actions column of the task, click Backfill All Data and configure the parameters.
Select a business date for the data backfill.
Select the previous day as the business date.
Select the tables to backfill.
In the left-side panel, select the tables to fully synchronize, and then click the
 icon to add them to the right-side panel. To recover the entire task, select all tables.
icon to add them to the right-side panel. To recover the entire task, select all tables.Click OK to start the full data backfill.
View execution details.
You can click Execution Details in the Actions column of the task to view run details.
ImportantBefore you backfill full data, confirm the business date to avoid potential conflicts with running or scheduled Merge task instances. If they run simultaneously with the same business date, partition data or table data might be overwritten.
You can check the status of the Merge task instance for the synchronization task on the View auto triggered instances page in the DataWorks Operation Center. If a conflict occurs, you can:
Pause the full data backfill and wait for the Merge task to complete.
Freeze the upcoming Merge task instance, and then resume it after the data backfill is complete.
The full data backfill feature is not supported for full and incremental synchronization tasks for sharded databases and tables.
Before you perform this operation, review the notes in this section. Check the execution result on the following day. If the data is not generated or the Merge task does not resume automatically, manually check and resume the Merge task instance.
Recreate the synchronization task
Go to the page. Then, Stop and Delete the original task.
Recreate the task using the existing destination tables. Then, Configure a real-time synchronization task for a whole database and run the new task.
Recover data for specific tables
Go to the page, find the destination task, and click . Re-add the desired tables to the task to resume their synchronization.
Restore historical data.
For a full and incremental synchronization task for an entire database, use the Recover by backfilling full data method to synchronize the current full dataset to a historical partition. Backfilling historical data for a specific time range is not supported.
For a real-time synchronization task for an entire database, manually create a batch synchronization task to backfill historical data.
Merge task failures
For details about troubleshooting and recovering from Merge task failures, see Troubleshoot full and incremental database synchronization tasks.