This guide explains how to troubleshoot and resolve common issues with the Merge task when using DataWorks for full and incremental database synchronization.
Merge task
How it works
A full and incremental database synchronization task first performs an offline synchronization of existing data from a source table to a base table (the target table). Simultaneously, a real-time synchronization task starts to read incremental change logs from the source database and writes them to a log table. The next morning (T+1), a Merge task starts. This task combines the incremental data from the log table's partition for day T with the full data from the base table's partition for day T-1 to generate the full data partition for day T. The process is illustrated below (using a partitioned table as an example):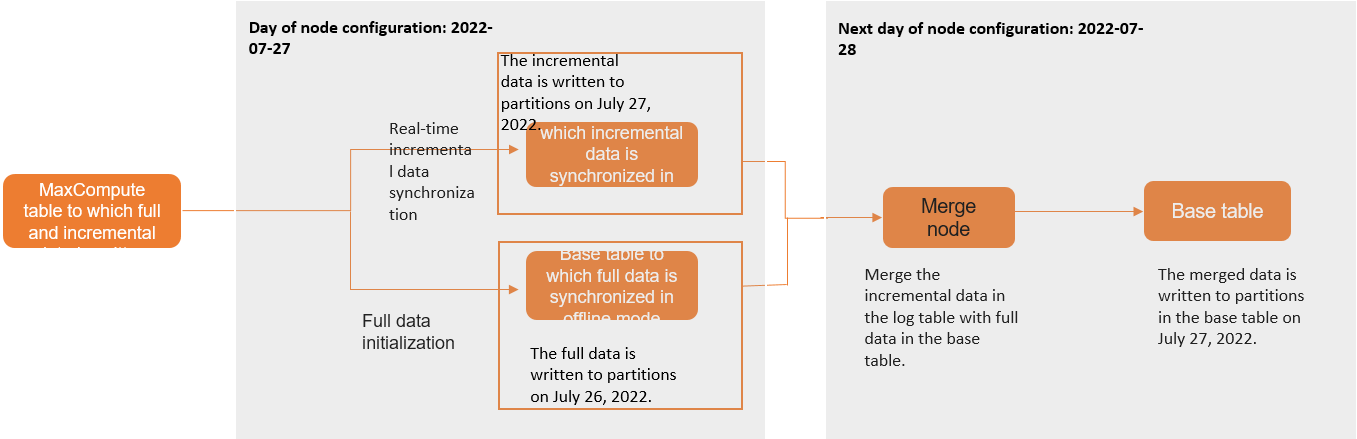
Offline task nodes
After the full and incremental synchronization task is configured and run, Data Integration generates several nodes in the Operation Center. You can view these nodes by navigating to , as shown in the following figure: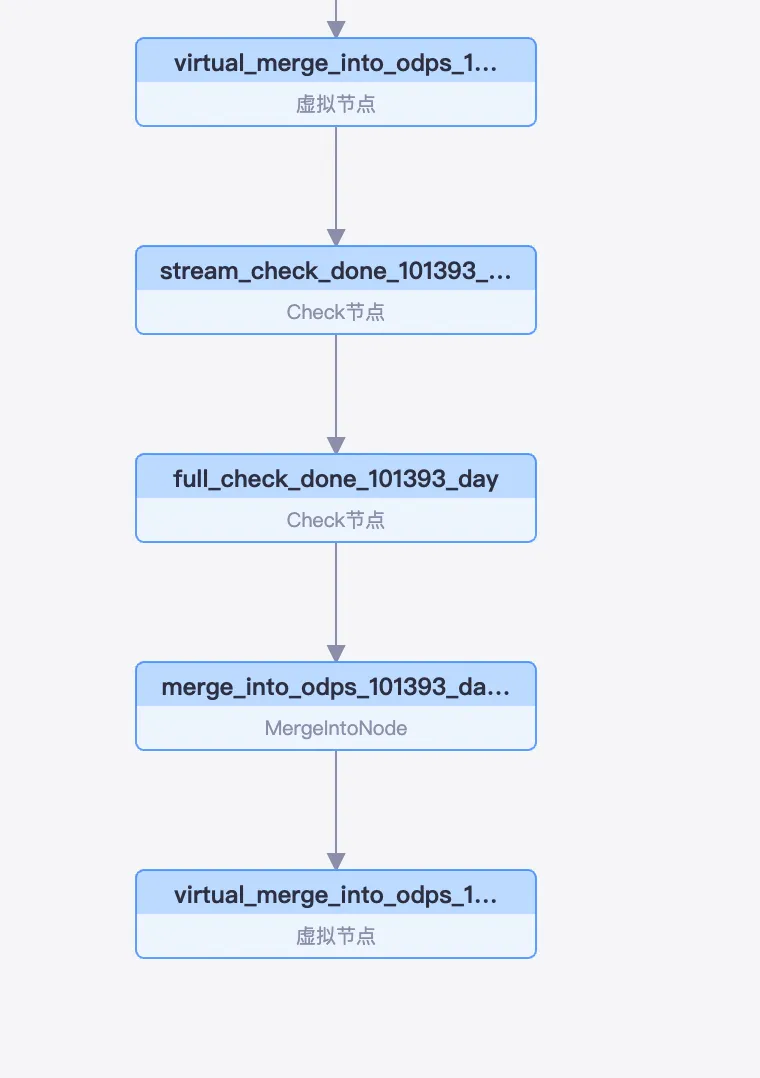
Root virtual node: All subtasks of this synchronization task are created under this node.
Check node (starts with `stream_check`): This node checks the incremental data consumption checkpoint to confirm that the incremental data partition from the previous day has been fully synchronized. The subsequent Merge task can only start after this check is complete.
Check node (starts with `full_check`): This node checks if the full synchronization is complete. A full synchronization of existing data from the source table to the target MaxCompute table runs once when the task is first executed or when a new table is added. This check ensures that all existing data from the source table is synchronized to the target partition before proceeding.
MergeIntoNode: This node merges the incremental data from the log table with the full data from the base table to produce a new full data partition.
Downstream virtual node: This node's output name includes the names of the synchronized tables, enabling SQL tasks in DataStudio to automatically resolve dependencies on this virtual node when referencing the table.
Task execution
In DataWorks, you can view the scheduling dependencies of each node by navigating to .
The daily task instances run in the following order: `stream_check` node, `full_check` node, and `MergeIntoNode`.
The `MergeIntoNode` is scheduled with a self-dependency, meaning each cycle's execution depends on the successful completion of the previous cycle.
This self-dependency mechanism is designed to ensure data integrity. Specifically, the Merge task for day T processes and generates the final data partition for day T-1. Therefore, if the task for day T fails, the system does not generate the data partition for day T-1. The system then blocks the instance for day T+1 to prevent calculation errors from a broken data chain.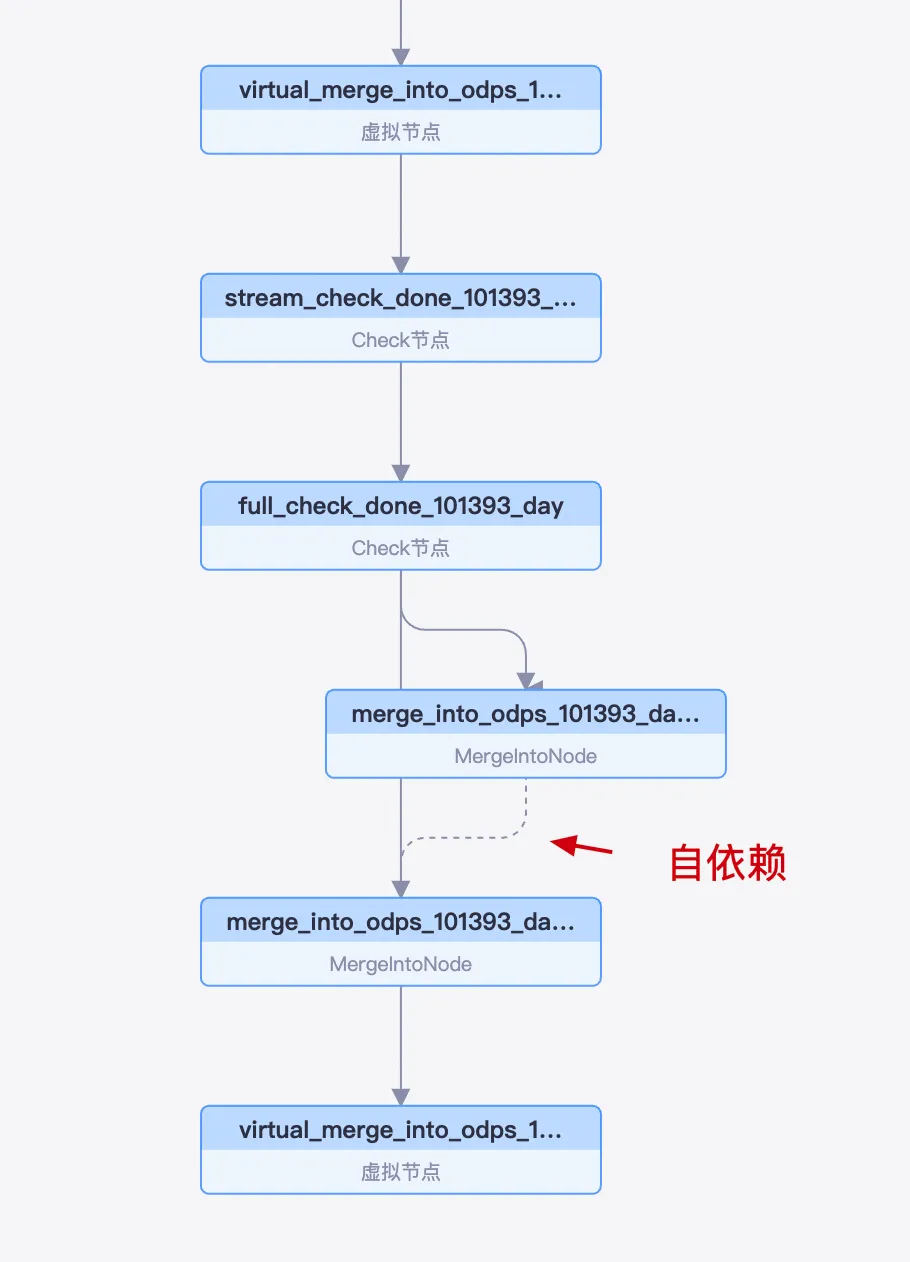
Merge task execution
When the Merge task runs, it generates a SQL subtask for each synchronized table. This subtask reads the table's incremental data from the log table, merges it with the full data from the previous day's partition in the base table, and outputs a new full data partition effective as of the previous day.
The SQL subtasks within a Merge task run in parallel. If a subtask fails, it is automatically retried if it meets the conditions for a retry. If any subtask ultimately fails after all retries, the entire Merge node fails.
Troubleshoot common Merge issues
Merge task failures
Base table partition not exists.Cause: The full data partition from the previous day was not generated. This is uncommon but can occur in the following scenarios:
You manually run a Merge instance to backfill data, but the Merge instance from the previous day did not run. Ensure the previous day's Merge instance completed successfully.
The initial offline full synchronization or the full synchronization after adding a new table did not complete. To resolve this, remove and then re-add the failed tables to reinitialize them.
If the cause is not listed above, you may have encountered an unsupported scenario. Contact on-duty engineers for further investigation.
Run job failed,instance:XXXX.Cause: A MaxCompute SQL subtask failed. Search for the instance ID to locate the error log. The log typically looks like this:
Instance: XXX, Status: FAILED result: MaxCompute-0110061: Failed to run ddltask - Persist ddl plans failed. , Logview: http://Logview.MaxCompute.aliyun.com/Logview/?h=http://service.ap-southeast-1.maxcompute.aliyun-inc.com/api&p=sgods&i=20220807101011355goyu43wa&token=NFBwc2tzaEpJNGF0OVFINmJuREZrem1OamQ4PSxPRFBTX09CTzo1OTMwMzI1NTY1MTk1MzAzLDE2NjAxMjYyMTEseyJTdGF0ZW1lbnQiOlt7IkFjdGlvbiI6WyJvZHBzOlJlYWQiXSwiRWZmZWN0IjoiQWxsb3ciLCJSZXNvdXJjZSI6WyJhY3M6b2RwczoqOnByb2plY3RzL3Nnb2RzL2luc3RhbmNlcy8yMDIyMDgwNzEwMTAxMTM1NWdveXU0M3dhIl19XSwiVmVyc2lvbiI6IjEifQ== ]An error message like MaxCompute-XXXX indicates an internal error in MaxCompute. You can refer to the SQL error codes (MaxCompute-01CCCCX) documentation to find the error and its solution. If the error is not listed in the document or you have other questions, contact MaxCompute technical support.
Request rejected by flow control. You have exceeded the limit for the number of tasks you can run concurrently in this project. Please try later.Cause: The number of concurrent SQL subtasks submitted by the Merge task exceeded the project's concurrency limit in MaxCompute.
Solution: See Merge task exhausts MaxCompute resources.
Partition data not generated
Cause: This occurs if the instance for the current cycle failed or is still running. Go to and check the status of the Merge instance:
If the instance status is "Running", wait for the daily Merge instance to complete.
If the instance status is "Failed", review the Merge task's run log to analyze the cause of the failure. After resolving the issue, right-click the instance and select Rerun.
If the instance status is "Not Running":
Check if the upstream `stream_check` node has completed. If it is still running, check if the real-time synchronization task is experiencing a delay. If there is a delay, resolve it first. The Merge task will be triggered after the delay is resolved. Check the log content for messages similar to the following example:
2023-01-06 00:15:04,692 INFO [DwcheckStreamXDoneNode.java:168] - Data current point time: 1672921729000 2023-01-06 00:15:04,692 WARN [DwcheckStreamXDoneNode.java:183] - Retrying... 2023-01-06 00:20:04,873 INFO [DwcheckStreamXDoneNode.java:168] - Data current point time: 1672921729000 2023-01-06 00:20:04,873 WARN [DwcheckStreamXDoneNode.java:183] - Retrying...An upstream Merge instance that this instance depends on has not completed or has failed. In Operation Center, check the upstream dependencies of the current day's Merge instance to find the most recent one that has not completed or has failed:
If the upstream Merge instance failed: Analyze the run log to determine the cause. After resolving the issue, right-click the instance and select Rerun to trigger normal scheduling.
If the upstream Merge instance is in the "Not Running" state: Check its upstream `stream_check` instance to confirm it is complete and that the real-time synchronization task is not delayed.
This occurs if you reran the full database synchronization task after a previous workflow issue. However, because the Merge node instance has a self-dependency, the new Merge instance cannot run. Find the first Merge instance that was generated after the workflow was rerun, right-click it, and select Remove Dependency. This breaks the dependency on the upstream Merge node, allowing the new Merge instance to run.
Slow or long-running merge task
In Operation Center, view the task's run log to see the SQL tasks that are currently running. The log will contain entries like this:
2022-08-07 18:10:58,919 INFO [LogUtils.java:20] - Wait instance 20220807101058817gbb6ghx5 to finish...
2022-08-07 18:10:58,938 INFO [LogUtils.java:20] - Wait instance 20220807101058818g46v43wa to finish...Search for the instance ID in the log to find the link to the SQL task's Logview (for example, instance20220807101058817gbb6ghx5: Logview Portal). Open the Logview to check the SQL task's execution status. There are many possible reasons for slow SQL execution:
The base table contains a large volume of data, causing too many mappers and reducers to be launched. This can be resolved by adjusting the corresponding MaxCompute parameters at the project level.
Too many SQL tasks were submitted at once, causing a resource shortage. If you open the Logview, you may see that the SQL instance is in a "Waiting" state. To resolve this, you must optimize MaxCompute resource allocation. If necessary, contact on-duty engineers from the MaxCompute team for support.
If you do not find the preceding logs, there might be an issue with submitting the MaxCompute SQL task. Find the Logview of the last successful MaxCompute task and review its log, or contact on-duty engineers from the MaxCompute team to help analyze the Logview.
Merge task exhausts MaxCompute resources
To control resource consumption or optimize task performance, you can adjust the concurrency of the Merge task by following these steps:
Navigate to the task editing page and expand Advanced Settings in the right-side panel.
Under Runtime Configurations, find the Merge Task Concurrency parameter and modify its value based on your requirements.
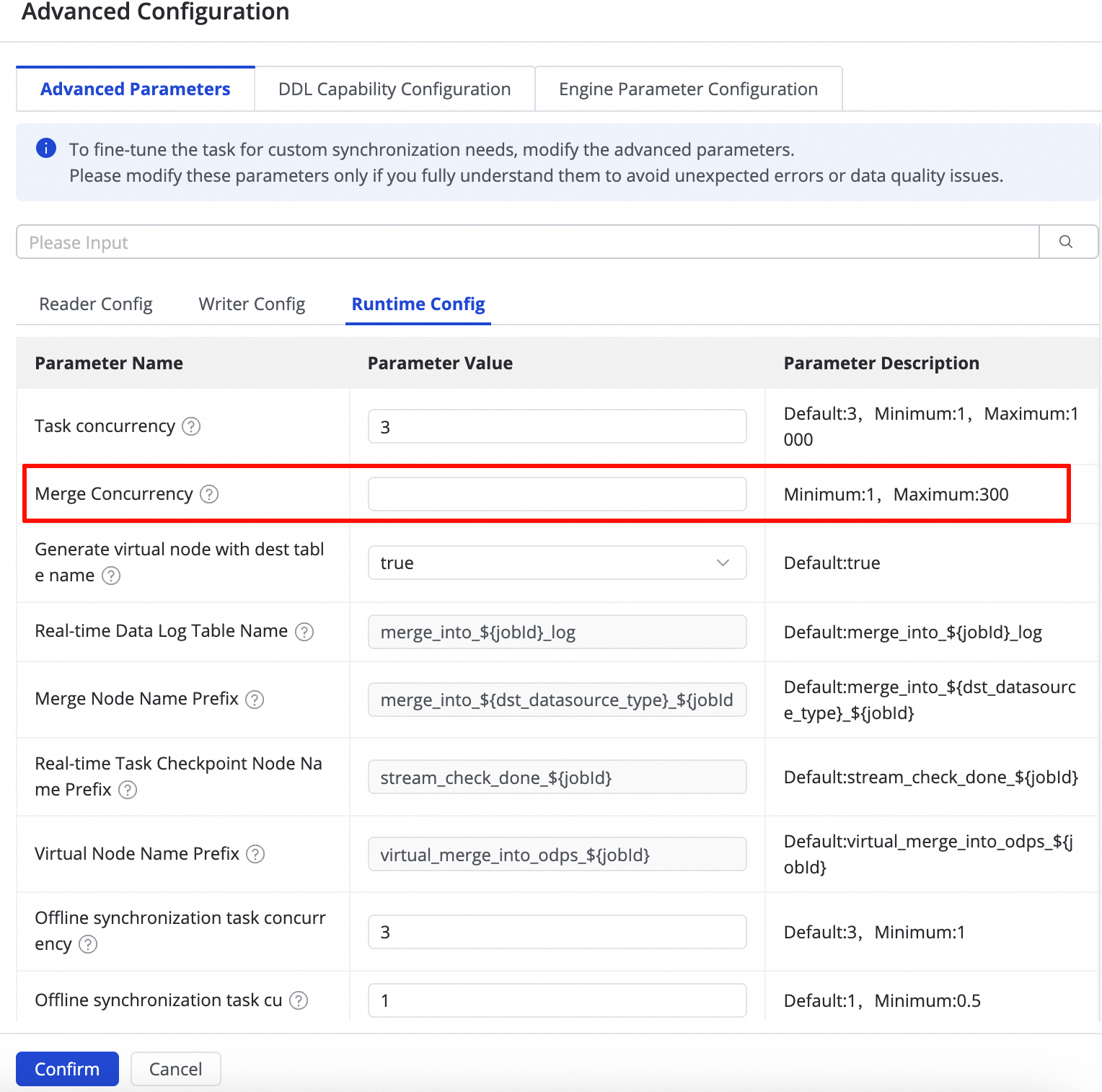
Parameter description:
Default value:
300Recommendation: Lower this value if the task fails due to insufficient resources or to reduce overall resource consumption.
Activation: The change applies after the task is restarted.
Change the scheduling time of the Merge task to run it during off-peak hours.