本文列举了阿里云Elasticsearch(ES)相关的常见问题,包括购买、退订、配置、访问、查询、写入、插件、分词、日志、重启、负载或状态异常、备份与恢复、监控报警等。
常见问题概览
购买或退订实例问题
产品功能咨询问题
数据迁移与同步问题
重启实例问题
集群负载或状态异常问题
集群查询与写入问题
集群配置与变更问题
插件、分词、同义词问题
日志问题
数据备份与恢复问题
集群监控报警问题
访问集群问题
索引相关问题
购买或退订实例问题
购买ES实例时选错配置,如何处理?
当您购买ES实例后,发现所选的配置不符合预期时,可以参考下表,匹配您的配置信息,选择合适的解决方案。
在下表解决方案中,如果涉及到退订,请在退订前先备份数据(手动备份与恢复)。退订后数据会被清除,无法恢复。
配置 | 解决方案 |
付费模式 | 如果您购买的是按量付费的实例,可转换为包年包月,详情请参见按量付费转包年包月。 |
版本 | 实例需要满足以下任意一种情况,才支持进行版本变更:
实例版本升级,详情请参见升级版本。不满足上述情况的版本变更,建议退订后重新购买。 |
地域 | 不支持变更,建议退订后重新购买。 |
可用区 | 可迁移可用区,详情请参见迁移与升级可用区。 说明 在迁移可用区时,请确保ES实例已创建成功,即实例状态为正常。 |
可用区数量 | 不支持变更,建议退订后重新购买。 |
实例规格 | 支持变更,详情请参见升配集群。 |
存储类型 | 支持变更,详情请参见升配集群。 |
云盘加密 | 不支持变更,建议退订后重新购买。 |
单节点存储空间 | 支持变更,详情请参见升配集群。 |
数据节点数量 | 支持变更,详情请参见升配集群。 |
网络类型、专有网络、虚拟交换机 | 不支持变更,建议退订后重新购买。 说明 目前只支持专有网络。 |
登录名 | 默认的管理员账号为elastic,不支持更改。您也可以在Kibana中创建用户,并为该用户授予对应的权限,详情请参见通过Elasticsearch X-Pack角色管理实现用户权限管控。 |
登录密码 | 支持变更,详情请参见重置实例访问密码。 |
ES购买页的版本具体对应的是哪个版本?
购买页版本 | 具体版本 |
8.15 | 8.15.1 |
8.13 | 8.13.4 |
8.9 | 8.9.1 |
8.5 | 8.5.1 |
7.16 | 7.16.2 |
7.10 | 7.10.0 |
7.7 | 7.7.1 |
6.8 | 6.8.6 |
6.7 | 6.7.0 |
6.3 | 6.3.2 |
5.6 | 5.6.16 |
5.5 | 5.5.3 |
购买时,如果您已拥有自建集群,建议您选择相近的版本,比如小版本相近;如果没有自建集群,建议您选择最新版本。
购买ES实例时,专有网络为空,如何处理?
请参见查看RAM用户信息,检查是否已经为RAM用户授予了获取专有网络VPC(Virtual Private Cloud)列表的权限。如果没有授权,请参见创建自定义权限策略,为RAM用户授权。
购买ES实例时,已拥有对应的专有网络,但无法选择虚拟交换机或虚拟交换机为空,报错vSwitch: may not be empty,如何解决?
此报错是由于您选择的可用区下没有可用的虚拟交换机。需要回到购买页的集群配置页面,查看所选的可用区,同时进入专有网络控制台下的交换机页面,确认对应可用区下是否有可用的交换机。如果没有需要创建,创建方式请参见搭建IPv4专有网络。
已购买的实例退订后重新购买,实例的访问地址会变吗?
会变化。建议您购买新实例后,先修改对应的客户端代码,再退订旧实例,保证业务不间断。
如何释放或退订ES实例?
我可以购买单机版的ES实例吗?
不支持,购买时至少需要选择两个数据节点,详情请参见购买页面参数。
购买实例时,资源已经售罄怎么办?
如果在创建实例时遇到资源售罄的情况,建议您采取以下措施:
更换地域
更换可用区
更换资源配置
如果调整需求后仍然没有资源,建议您等待一段时间再购买。实例资源是动态的,如果资源不足,阿里云会尽快补充资源,但是需要一定时间。
为什么建议还在使用存量1核2 GiB规格的用户尽快升级规格?
受规格库存及性能稳定性影响,自2021年5月起,阿里云Elasticsearch不再提供1核2 GiB规格的数据节点的新购,存量节点使用不受影响。1核2 GiB规格实例只适合于学习场景,不适用于生产环境,根据产品SLA协议不在售后保障范围内。建议您尽快将1核2 GiB规格升级至高规格,详情请参见升配集群。
购买ES后一直在创建中,如何处理?
实例创建后,需要一段时间才能生效。时间长短与您的集群规格、数据结构和大小等相关,一般在小时级别。
ES集群创建完成后,还需要单独购买Kibana吗?
购买ES集群时,Kibana节点默认为启用状态,不可更改。您可以根据需求选择Kibana节点的规格,具体操作请参见创建阿里云Elasticsearch实例。
受规格性能及稳定性影响,推荐购买2核4 GiB及以上规格的Kibana节点;1核2 GiB规格的Kibana节点免费赠送,但仅建议在测试场景中使用。
为什么找不到已创建的实例?
请您检查下所选地域是否正确,建议您在ES控制台上方选择地域处查看。 如果地域正常,ES实例仍然找不到,建议您清除浏览器缓存或更换本地网络环境进行尝试。
购买ES实例时,什么情况下需要购买专有主节点和协调节点?
专有主节点的主要功能是对集群进行操作,例如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康非常重要,建议在以下场景下购买独立的专有主节点:
集群中承担主节点角色的数据节点压力比较大的场景。
写入场景下。
对集群的稳定性要求较高的场景。
协调节点主要承担所有的查询和写入请求,为数据节点做请求转发,同时merge数据节点的查询结果,一般agg场景建议购买独立的协调节点。一般建议按数量1:5添加独立的协调节点(1协调对应5个数据节点,最少2个),规格建议和数据节点保持一致。更详细的规格容量评估方案,请参见规格容量评估。
购买ES实例时,输入密码的默认账号是什么?
默认账号是elastic。您也可以创建自定义账号,具体操作请参见通过Elasticsearch X-Pack角色管理实现用户权限管控。
产品功能咨询问题
阿里云ES支持版本升级或降级吗?
仅部分版本(5.5升级5.6版本、5.6升级6.3版本、6.3升级6.7版本)支持直接升级版本。
如果您有其他版本间的升级需求或降版本需求,请先购买目标版本ES实例,再将原实例中的数据迁移至目标实例中,最后退订或释放原实例,间接完成版本升级或降级。
阿里云ES免费试用实例仅支持8.5、8.9版本,且创建后不许用修改。
直接升级版本,请参见升级版本。
创建新ES实例,请参见创建阿里云ES实例。
阿里云ES实例间数据迁移,请参见阿里云ES实例间数据迁移方案选取指南。
ES支持通过SSH登录集群修改配置吗?
不支持。为确保安全性,ES不支持通过SSH登录集群。如果您需要修改集群配置,可通过ES的集群配置功能实现,详情请参见集群配置。
6.7版本的Logstash和6.3版本的ES能够兼容吗?
可以兼容。更多兼容性说明请参见产品兼容性。
Quick BI支持ES数据源吗?
Quick BI支持通过公网连接ES,但需要将Quick BI的IP地址添加至ES的公网白名单。
ES支持评分插件吗?
ES支持通过索引创建分词器进行数据搜索,同时也支持评分排序,详情请参见初级版:从实例创建到数据检索。
ES支持LDAP功能吗?
ES产品侧支持LDAP功能。如果您需要使用LDAP协议对接ES进行认证,需要先在本地搭建对应ES版本集群环境进行测试,测试没问题后再在ES控制台配置对应的模板,详情请参见X-Pack集成LDAP认证最佳实践。
ES有Java SDK吗?
有的,不同的ES版本对应不同的SDK,具体使用方式请参见Java API。
ES实例的内核版本在哪里查看?
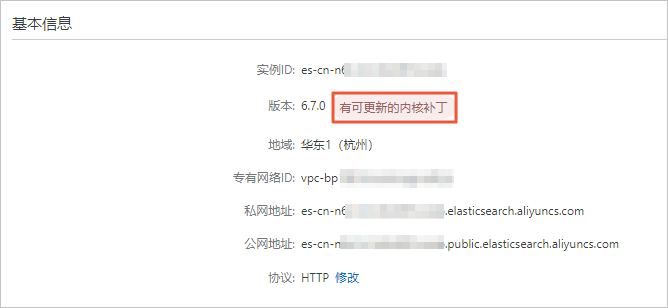
ES在使用过程中,什么情况下可以使用强制重启功能,使用该功能后会有什么影响?
如果实例状态显示为非正常状态(黄色或红色),则不支持重启操作。此时,您需要对实例进行强制重启。使用该功能,可能会导致服务在重启阶段不稳定、数据丢失或者读写数据失败等,请谨慎操作。
如何确认ES的Log4j2漏洞已修复?
集群重启成功即可完成漏洞修复,详细信息请参见【漏洞预警】Apache Log4j2远程代码执行漏洞。
修复Log4j2漏洞需要升级ES版本吗?
不需要,直接按照修复流程操作即可。
如何实现跨地域ES实例内网互通?
您可以通过以下两种方式实现跨地域ES实例内网互通:
VPC对等连接方式,详细信息请参见使用VPC对等连接实现VPC私网互通。
云企业网方式,详细信息请参见使用云企业网实现跨地域网络实例互通。
如何在Elasticsearch集群间迁移数据?
不同的迁移场景(阿里云Elasticsearch间迁移、自建Elasticsearch迁移至阿里云、第三方Elasticsearch迁移至阿里云等)需要使用不同的迁移方案和工具,详细信息请参见迁移方案选取指南。
开启HTTPS协议是否需要购买协调节点?
以下ES版本开启HTTPS时不需要购买协调节点,且已购买的协调节点可以关闭。
7.16及以上版本。
除上述版本外,其他ES版本开启HTTPS时必须开启协调节点,且协调节点购买后不支持退订和关闭。
为了提高安全性,在开启HTTPS后,阿里云Elasticsearch会定期维护并更新所依赖的证书。因低版本(7.10及以下)暂不支持热更新安装在数据节点上的证书,为了降低更新证书时重启节点对线上业务的影响,阿里云Elasticsearch会将证书部署在负责转发请求的协调节点上。如果您还未购买协调节点,在打开HTTPS协议前,系统会提示您购买协调节点,请按照提示购买协调节点后再进行操作,详细信息请参见使用HTTPS协议。
ES单节点最大支持多少分片?
ES 7.x版本最大支持1000个分片,其他版本无限制。您需要根据集群规格,合理设置单个数据节点的shard数,详细信息请参见规格容量评估和Size your shards。
您可以使用如下命令,通过max_shards_per_node参数,临时修改集群的最大分片数:
PUT /_cluster/settings
{
"transient": {
"cluster": {
"max_shards_per_node":10000
}
}
}作为长期解决方案不建议将该参数值设置过大。建议您增加节点数或减少集群的分片数,对shard进行合理规划,避免集群压力过大导致集群稳定性问题。
以.monitoring-es开头的索引是怎么生成的?作用是什么?
默认情况下,X-Pack监控客户端会每隔10s采集一次集群的监控信息,并保存到对应阿里云Elasticsearch实例的以.monitoring-*为前缀的索引中。以6.x版本实例为例,主要有.monitoring-es-6-*和.monitoring-kibana-6-*这两种索引,以天为单位滚动创建。采集完的信息会保存在以.monitoring-es-6-为前缀,以当前日期为后缀的索引中。
其中.monitoring-es-6-*索引占用磁盘空间较大,主要存放了集群状态、集群统计、节点统计、索引统计等信息,更多详细信息请参见配置Monitoring监控日志。
ES数据盘开启云盘加密,使用的加密算法是什么?
ES的云盘加密采用行业标准的AES-256加密算法,利用密钥管理服务KMS(Key Management Service)加密云盘,详细信息请参见加密云盘。
阿里云ES服务是否支持9300端口?
仅阿里云ES 5.x版本同时支持9300端口(基于TCP)和9200端口(基于HTTP或HTTPS),其他版本只支持9200端口。
阿里云ES 6.0及以上版本的实例,不支持通过Transport Client访问9300端口。如果您要访问9300端口,需要购买5.x版本的实例。
数据迁移与同步问题
如何将MongoDB数据同步至阿里云ES?
您可以通过Monstache将MongoDB数据实时同步至阿里云Elasticsearch,具体操作请参见通过Monstache实时同步MongoDB数据至Elasticsearch。
重启实例问题
重启ES实例或节点需要多久?
在重启ES实例或节点时,页面上会显示预估时间,这个时间是根据您的集群规格、数据结构和大小等进行评估的。重启实例耗时较长,一般在小时级别,详情请参见重启集群或节点。
打开或关闭ES实例的公网访问时,会触发实例重启吗?
不会。但是会有短暂的生效状态变更,不影响正常使用。
修改集群访问密码,会触发集群重启吗?
不会。密码变更只会触发集群重新加载,不会触发重启,详细信息请参见重置实例访问密码。
索引没有副本,是否会影响集群重启?
会影响,可能会导致重启过程中无法对外持续提供服务。如果集群整体负载不高且索引存在副本分片,一般情况下重启过程中可对外持续提供服务。但在某些场景下,重启过程中可能会出现访问超时,例如强制重启并发度高、集群负载很高并且已经存在集群访问不可用的情况、没有副本分片、在重启或强制重启过程中存在大量的写入和查询等场景,建议重启前先在客户端设计好重试机制并且在业务低峰期进行操作。
如何重启角色节点(例如Kibana节点)或单个节点?
重启角色节点
在实例的基本信息页面单击重启,选择操作类型为角色节点重启,并选择对应的角色节点,即可对该角色节点进行重启。具体操作请参见重启集群或节点。
重启单个节点
您可以通过以下两种方式重启单个节点:
在实例的基本信息页面单击重启,选择操作类型为节点重启,并选择对应的节点,即可对该节点进行重启。具体操作请参见重启集群或节点。
在实例的基本信息页面下方的节点可视化区域中,将鼠标移动到对应节点上,在弹出框中单击重启即可。具体操作请参见查看集群状态和节点信息。
重启实例卡住了怎么办?
建议您先在任务列表中查看实例变更任务详情(除7.16版本外,其他版本实例的重启时间都在小时级别),具体操作请参见查看实例任务进度。如果存在变更进度长时间无变化的情况,可参考以下说明排查解决。
可能原因 | 解决方案 |
插件问题导致节点无法启动 | 删除对应插件。 |
磁盘使用率太高导致shard无法分配 说明 您可以通过集群监控查看集群的磁盘使用率,详细信息请参见指标含义与异常处理建议。 | 删除索引或者将索引副本数暂时设置为0。 |
集群参数设置问题导致shard无法分配 | 通过 |
副本数大于节点数 | 重新设置副本数。 |
集群规格过小,出现OOM(Out Of Memory) | 升配集群。 |
ES实例能设置定期重启节点吗?
目前不支持定期重启节点。如果您有该需求,可以尝试使用API(RestartInstance)的方式,但是需要您自己写定时任务和配置对应的节点信息。
集群负载或状态异常问题
使用ES实例时,一部分节点的CPU和负载正常,另一部分处于空闲状态,如何处理?
此现象是集群负载不均问题引起的。导致阿里云ES集群负载不均问题的原因很多,目前主要包括shard设置不合理、segment大小不均、冷热数据需求、负载均衡及多可用区架构部署的长连接不释放等。请根据具体现象进行排查,详情请参见集群负载不均问题的分析方法及解决方案。
在排查问题前,请先查看您的集群规格,如果为1核2 GiB(学习规格),请先将规格升配至2核4 GiB或以上,详情请参见升配集群。
1核2 GiB规格实例只适合于学习场景,不适用于生产环境,根据产品SLA协议不在售后保障范围内。由于该规格实例稳定性较弱,产品已不再支持购买。建议您尽快将1核2 GiB规格升级至高规格。
2核4 GiB规格实例建议在测试环境中使用,生产环境建议您使用更高规格。
ES集群状态yellow,如何处理?
问题原因
当您设置的索引副本数大于当前节点数减1时,会导致集群处于yellow状态。
解决方案
通过
GET _cat/indices?v命令查看索引分片的分布情况,定位yellow状态的索引,并将其副本分片数设置为0。等待集群恢复正常后,再将对应索引的副本分片数设置为原来的值。警告将副本分片数设置为0后,当节点掉线时,可能会导致数据丢失,请谨慎操作。待集群恢复正常后(大约1分钟),请尽快将副本分片数恢复到原来的值。
PUT test/_settings { "index" : { "number_of_replicas":"0" } }
ES集群负载高导致状态red,如何处理?
主分片所在的节点异常会导致集群red。您可以通过GET /_cat/indices?v命令查看索引分片的分布情况,定位到red索引,并按照以下常见原因和解决方案排查解决。
常见原因 | 解决方案 |
负载不均导致集群资源不足。 | 建议您优化分片负载,调整主+副分片为集群数据节点的整数倍,详细信息请参见shard分配不均,如何调整?。 |
集群中包含无用的索引数据。 | 建议定时清理无用的索引数据,尤其是以.monitor开头的索引监控数据,具体操作请参见配置Monitoring监控日志。 |
分片未分配。 | 通过 |
缓存导致资源占用。 | 建议使用 |
在进行升配等集群变更操作。 | 建议中断当前变更,在升配页面选择强制变更,具体操作请参见升配集群。 |
实例规格较低资源不足,例如1核2 GiB、2核4 GiB等规格。 | 建议升配集群,具体操作请参见升配集群。 说明
|
磁盘水位超过85% | 建议删除不需要的历史数据或扩磁盘,详细信息请参见集群磁盘使用率过高和read_only问题的排查与处理方法。 |
通过监控查看到或收到集群报警,集群CPU占比过高,如何处理?
常见的问题原因及对应的解决方案如下。
常见原因 | 解决方案 |
写入或查询QPS增加导致CPU增加。 | 降低并发写入量、降低写入查询QPS或扩容集群规格,建议您结合生产环境进行压测,选择合适的规格。 |
索引缓存占用资源。 | 建议使用 |
集群规格太低。 | 建议升配集群,具体操作请参见升配集群。 |
单节点CPU高,负载不均。 | 优化分片负载,设置主+副分片为集群数据节点的整数倍,详细信息请参见shard分配不均,如何调整?。 |
ES磁盘使用率过高,如何处理?
建议您使用DELETE /索引名命令删除无用索引,待磁盘使用率降到75%以下时,再在控制台强制升级集群磁盘和规格容量,具体操作请参见升配集群。当单节点的磁盘使用率过高时,您还需要优化分片,详细信息请参见shard分配不均,如何调整?。
为避免磁盘使用率过高影响Elasticsearch服务,建议开启磁盘使用率监控报警,及时查收报警短信,提前做好防御措施,具体操作请参见指标含义与异常处理建议。磁盘使用率超过的比例不同,对集群产生的影响不同,具体说明如下:
超过85%:导致新的分片无法分配。
超过90%:ES会尝试将对应节点中的分片迁移到其他磁盘使用率比较低的数据节点中。
超过95%:系统会对Elasticsearch集群中的每个索引强制设置read_only_allow_delete属性,此时索引将无法写入数据,只能读取和删除对应索引。
通过监控查看到或收到集群报警,ES内存占比过高,如何处理?
常见的问题原因及对应的解决方案如下。
常见原因 | 解决方案 |
集群缓存占用内存。 | 短期内可以通过 |
查询写入过高。 | 建议停止读写后安装限流插件,并开启集群限流,具体操作请参见使用集群限流插件(aliyun-qos)。 |
无用索引占用内存。 | 删除无用的索引释放资源,尤其是以.monitoring-*为前缀的监控索引,可设置其保留周期,具体操作请参见配置Monitoring监控日志。 |
单节点内存高,分片不均。 | 优化分片负载,设置主+副分片为集群数据节点的整数倍,详细信息请参见shard分配不均,如何调整?。 |
异常查询,例如业务侧触发的一串长特殊字符。 | 通过 |
shard分配不均,如何调整?
建议重新分配并合理规划shard,确保主shard数与副shard数之和是集群数据节点的整数倍,让数据均摊到每个数据节点上,避免负载不均导致单个节点负载过大。主副shard数的分配示例如下:
假如当前集群的数据节点数为3个,那么您可以设置主分片3个,副本分片为1份,即分片之和为6个。
假如当前集群的数据节点数为8个,那么您可以设置主分片4个,副本分片为1份,即分片之和为8个;或主分片8个,副本分片为1份,即分片之和为16个。
调整分片后需要对原有数据生效,在业务低峰期对索引reindex。副本分片越多,集群的可用性和查询性能会更好,同时也会占用更多内存空间。
shard大小和数量是影响Elasticsearch集群稳定性和性能的重要因素之一。Elasticsearch集群中任何一个索引都需要有一个合理的shard规划。合理的shard规划能够防止因业务不明确,导致分片庞大消耗Elasticsearch本身性能的问题。shard规划建议请参见评估Shard。
shard分配不均会导致集群负载不均,您可以通过以下方式查看集群是否存在shard分配不均:
指标含义与异常处理建议,如果某个节点的CPU、内存、磁盘等负载较高,说明shard分配不均。
使用
GET _cat/shards?v命令,查看索引的shard信息。如果索引的shard在负载高的节点上呈现的数量较多,说明shard分配不均。
集群负载高,且主日志报错:java.lang.StackOverflowError for the entire cluster,如何处理?
主日志报错:java.lang.StackOverflowError for the entire cluster,表示Lucene堆栈溢出,与正则和模糊查询相关,目前Elasticsearch 6.0及以上版本已修复。建议您尽快升级集群版本,或者优化查询语句,详细信息请参见java.lang.StackOverflowError for the entire cluster。
如何查询JVM配置实际分配了多少内存?
可通过GET _nodes/stats/jvm?pretty命令查看,默认为集群内存的一半,不支持修改。
集群查询与写入问题
如何调整队列大小?
可以通过在YML参数配置中,指定thread_pool.write.queue_size参数的大小来调整队列大小,具体操作请参见配置YML参数。在调整前,您可以通过GET /_cat/thread_pool?v命令查看队列使用情况。
对于6.0以下版本的Elasticsearch集群,需要使用thread_pool.index.queue_size参数。
如何查询或导出指定时间段内的数据?
您可以通过Elasticsearch中的range查询实现查询指定时间段内的数据,详细信息请参见Range query。
如果要导出指定时间段内的数据,可以通过Logstash进行过滤,详细信息请参见Logstash配置文件说明。
ES使用批量插入操作是否有数量限制?
Bulk默认设置批量提交的数据量不能超过100 MB。如果超过该限制,您可以调整写入数据量。每次写入请求的数据量=文档数量*单个文档的大小。仅凭文档数量可能无法准确评估写入数据量的大小,它取决于您每个文档的大小及复杂性。如果您的单个文档数据量很大,可以适当减少文档数量。一般建议每次写入请求的数据量从5 MB~15 MB开始调试,默认不能超过100 MB(详细信息请参见HTTP settings)。具体调试方案,请参见官方使用和调试批量请求文档。
Elasticsearch查询结果与实际存在时间差,如何处理?
Elasticsearch默认是UTC时间(世界标准时间),和实际时间会存在时间差。Elasticsearch本身不支持调整时区,您可根据时区差进行转换,例如UTC时间比北京时间晚8小时(Elasticsearch存储的时间要比实际的时间晚8小时),可通过以下方式转换:
查询日期类型数据时,带上time_zone或者时间戳方式存储时间,详细信息请参见Parameters for <field>。
写入时间数据时指定时区,例如
"time" : "2022-07-15T12:58:17.136+0800"(东八区时间)。使用Kibana展示数据。Kibana从Elasticsearch中获取到date类型的字段后,会通过JS获取本机或本地时区,并将时间字段从Elasticsearch的UTC时间转换为浏览器所在时区后展示出来,详细信息请参见如何调整Kibana可视化展示数据的时区?。
如果是Logstash同步数据,导致同步前后数据的时区相差8小时的场景,需要手动在管道配置中增加对应的时间,参考解决方案示例:
filter{ ruby{ code => "event.set('update_time', event.get('update_time').time.localtime + 8*60*60)" } }。
ES集群查询较长时间后返回结果,或不返回结果,如何处理?
长时间后返回结果,或不返回结果为慢查询。您可以通过控制台慢查询日志查看慢日志,结合指标含义与异常处理建议定位原因。常见原因及对应的解决方案如下。
常见原因 | 解决方案 |
集群分片负载不均。 | 建议您优化分片负载,调整主+副分片为集群数据节点的整数倍,详细信息请参见shard分配不均,如何调整?。 |
集群资源不足。 | 如果存在agg、term、脚本和模糊查询等消耗性能较大的操作,建议您优化操作命令或者升配集群。升配集群的具体操作请参见升配集群。 说明 Elasticsearch集群查询性能与集群的健康状况有关。内存使用率低于80%,节点负载均衡的情况下查询性能较好。 |
集群写入报错Data too large... which is larger than the limit of,如何处理?
问题原因
写入过高,触发熔断,集群资源无法满足目前大量的写入。
解决方案
重要如果以下操作无法执行,需要先停止所有查询和写入,然后强制重启集群,待集群恢复正常状态后再操作。
执行
POST /索引名/_cache/clear?fielddata=true命令,清理索引缓存。如果无法解决,继续执行以下步骤。执行
GET /_cat/indices?v命令,查看集群中是否存在shard分配不均的问题,详细说明及调整方法请参见shard分配不均,如何调整?。如果无法解决,继续执行以下步骤。降低并发写入量,删除无用的索引释放资源,减少Kibana monitoring的使用。
关闭Kibana monitoring,执行以下命令:
PUT _cluster/settings { "persistent": { "xpack.monitoring.collection.enabled": false } }如果无法解决,继续执行以下步骤。
通过升配集群扩容集群规格。
ES支持批量删除索引吗?
支持。需要配置YML参数,将删除索引指定名称设置为删除或关闭时索引名称支持通配符,重启成功后就可以使用通配符批量删除索引。具体操作请参见配置YML参数。
索引删除后不可恢复,请谨慎使用此配置。
新建索引时会偶现索引UUID冲突报错(index uuid conflicted ),索引文档写不进去,怎么办?
已知问题,需要将实例的内核版本升级到1.5.0及以上版本,具体操作请参见升级版本。
如何修改index.max_result_window(分页查询时查询的最大文档数量)?
ES默认的index.max_result_window(分页查询时查询的最大文档数量)参数值为10000(from+size),查询时超过该值将报错Result window is too large, from + size must be less than or equal to: [10000]。
个别深分页搜索场景可能需要扩大该参数值。可以根据具体需求,执行如下命令修改index.max_result_window的值(示例中的值仅供参考)。命令执行后,再重启ES集群时,该配置不会失效。
PUT /my_index/_settings
{
"index": {
"max_result_window": 50000
}
}当查询召回结果过多,不推荐使用from+size做深分页,否则会消耗大量的CPU和内存资源。深度分页场景建议使用scroll或search after。
ES更新数据时报错:Rejecting mapping update to [] as the final mapping would have more than 1 type,如何处理?
此报错是由于进行update操作时,使用了与原索引不同的type。由于ES不允许一个索引有多个type,因此更新数据的时候,需要使用与原索引相同的type。
官方Elasticsearch 7.0及以上版本将移除mapping中的type类型定义,type类型固定为_doc。
如何查询索引中文档的详细内容?
可登录Kibana控制台,执行以下命令查看:
GET _search
{
"query": {
"match_all": {}
}
}您也可以通过Kibana中的discover工具查看(需要先创建Index Pattern),具体操作请参见Kibana Guide。
集群配置与变更问题
使用ES前,如何合理规划集群的资源和规格以及shard的大小和数量?
您可以参见规格容量评估进行规划。
如何查看ES实例的配置参数?
可在实例的基本信息页面查看,详情请参见查看实例的基本信息。
当您使用Transport Client访问ES实例时,cluster.name为实例ID,详情请参见Transport Client(5.x)。
变更集群配置会影响ES服务吗?
变更集群配置会导致集群重启。目前阿里云ES集群重启是采用滚动重启的方式,在集群状态正常(绿色)、索引至少包含1个副本的情况下,如果资源使用率也不是特别高(可在集群监控页面查看,例如节点CPU使用率为80%左右,节点HeapMemory使用率为50%左右,节点load_1m低于当前数据节点的CPU核数),那么集群在重启期间能够持续提供服务。但建议在业务低峰期进行操作。
变更节点数后,集群会自动重新规划分片吗?
会。 ES数据节点数变更后,集群会自动重新规划分片,但自动重新规划分片也不能保证所有数据一定是完全均匀分配的。受索引大小、分片数、节点数等多种因素影响,数据重新分配后依然有概率出现数据在分片上的分配不均匀情况。分片分配不均的排查方法和解决方案,请参见集群负载不均问题的分析方法及解决方案。
ES实例支持变更云盘类型吗?
支持。云盘降配时,支持云盘存储性能由高到低依次为:ESSD云盘、SSD云盘、高效云盘;云盘升配时,支持云盘存储性能由低到高依次为:高效云盘、SSD云盘、ESSD云盘。
ES支持将其他类型的节点变为冷数据节点吗?
不支持,会导致实例不稳定,详情请参见“Hot-Warm” Architecture in Elasticsearch 5.x。
升级了实例规格后,可以降低配置吗,如何操作?
业务量临时突增,如何变更集群配置,来保证业务正常进行?
升配集群时,提示UpgradeVersionMustFromConsole如何处理?
出现此问题的原因是版本变更不符合要求。目前阿里云ES只支持5.5.3版本升级到5.6.16版本、5.6.16版本升级到6.3.2版本、6.3.2版本升级到6.7.0版本,暂不支持其他版本间的升级。
升级ES版本需要多长时间?
具体时长与您集群中的数据大小、数据结构、集群规格等都有关系。一般为1个小时左右。
升级ES版本会影响集群服务吗?
升级期间可以继续向集群写入数据或从集群读取数据,但不能进行其他变更操作,建议在流量低峰期进行。升级的注意事项和操作步骤请参见升级版本。
升配集群报错或超时,如何处理?
导致升配集群报错或超时的最常见原因是集群状态不正常。出现此种情况时,建议您先停止查询和写入,参见ES集群负载高导致状态red,如何处理?进行处理,待集群状态正常后再进行升配操作。您也可以在升配时进行强制变更,忽略集群健康状态,但此操作可能会影响ES服务,请谨慎操作。
其他原因导致的升配问题,需要您根据报错信息自行排查解决。
集群无法变配,如何处理?
建议按照以下方式排查解决:
检查您的集群节点规格是否带有本地盘。本地盘不支持变配,如果需要升级规格,需要先更换云盘类型。
如果前端校验返回库存不足,建议您更换可用区进行变配或者是等其他用户释放该可用区的实例。
如果前端校验返回集群状态不健康,需要检查集群中是否有close状态的索引,并将状态暂时修改为open。如果集群状态为red,需要检查是否有节点离线、shard无法分配等情况,优先解决集群问题。
降配集群是否满足条件:
降配所选的目标规格的CPU和内存均需大于或等于当前规格的1/2,且不支持将节点规格降配至1核2 GiB、2核2 GiB、2核4 GiB和4核4 GiB。
说明如果您需要降配至2核4 GiB或4核4 GiB,请新建一个2核4 GiB或4核4 GiB的实例,然后通过数据迁移的方式(例如通过Logstash)将数据迁移到新实例中。
集群负载满足条件才可降配,降配使用限制和注意事项请参见降配集群。
降配时不支持缩小磁盘容量大小。
是否可以在集群的YML文件配置中,调整http.max_content_length和discovery.zen.ping_timeout值?
不支持。阿里云ES仅支持配置产品提供的参数,详细信息请参见配置YML参数。不支持配置未提供的参数。
discovery.zen.ping_timeout、discovery.zen.fd.ping_timeout、discovery.zen.fd.ping_interval、discovery.zen.fd.ping_retries参数通常是不需要调整的。
我可以切换ES实例的VPC吗?
不支持切换。您可以重新购买一个对应VPC下的ES实例,然后迁移数据,再释放原实例。
ES实例变更云盘类型会导致已有的数据丢失吗?
不会。已经存在的数据不会丢失,但是持续写入的新数据有丢失的风险,建议在业务低峰期或者停止写入后执行升配,详细信息请参见升配集群。
集群升配时,提示集群不健康,但是集群状态确认是Green,如何处理?
集群中可能存在close状态的索引,可通过POST /<index_name>/_open命令,将对应索引的状态暂时设置为open,详细信息请参见升配集群。
ES可以直接升配CPU,避免数据迁移吗?
不可以。升配或降配CPU会触发蓝绿变更,导致节点IP地址发生变化,并且数据会从旧节点迁移到新节点。
为什么冷数据节点无法降配?
集群降配是有一定条件限制的,例如降配所选的目标规格的CPU和内存均需大于或等于当前规格的1/2,且不支持将节点规格降配至1核2 GiB、2核2 GiB、4核4 GiB和2核4 GiB等,详细信息请参见降配集群。
如果不满足降配条件,您可以选择新建实例,迁移数据后再释放原来的集群,迁移数据的具体方案可参见迁移方案选取指南。
缩容集群数据节点时,出现“该操作会导致当前集群资源(Disk/CPU/Memory)不足或shard分配异常”的报错,如何处理?
可能原因 | 解决方案 |
集群资源不足。 集群在缩容后,磁盘、内存、CPU等资源不足,不足以承担当前系统数据或者负载。 | 使用 |
shard分配异常。 按照Lucene原理,对于任意一个数据节点中同一个索引的副本,Elasticsearch不会把2个或者2个以上的副本同时迁移到同一个数据节点中。这会导致缩容后集群中索引的副本数可能大于等于数据节点数,从而导致shard分配异常。 | 使用 |
缩容集群数据节点时,出现“集群当前状态异常或有未完成任务”的报错,如何处理?
建议您通过智能运维诊断集群健康状况,并根据诊断结果和诊断建议处理报错。具体操作请参见诊断集群健康状况。
缩容集群数据节点时,出现“保留节点数需大于2”的报错,如何处理?
为保证集群的可靠性,保留的节点数必须大于等于2;对于多可用区实例,还需确保每个可用区节点数大于等于2,且每个可用区剩余节点数相同。如果不满足要求,需要重新选择迁移或缩容的节点或者升配集群。
缩容集群数据节点时,出现“当前ES集群配置不支持该操作”的报错,如何处理?
使用GET _cluster/settings命令查看集群配置,判断是否存在不允许数据分配的配置,即"cluster.routing.allocation.enable" : "none"。如果存在,可将其暂时设置为允许,即"cluster.routing.allocation.enable" : "all"。如果该配置会影响您的其他操作,待缩容完成后需要再设置回去。
使用auto_expand_replicas索引,导致数据迁移或者节点缩容失败,如何处理?
原因
部分用户使用了X-Pack提供的权限管理功能,在早期版本中,该功能对应的.security索引默认会使用
"index.auto_expand_replicas" : "0-all"配置,该配置会使得数据迁移或者节点缩容失败。解决方案
查看索引配置。
GET .security/_settings返回如下结果。
{ ".security-6" : { "settings" : { "index" : { "number_of_shards" : "1", "auto_expand_replicas" : "0-all", "provided_name" : ".security-6", "format" : "6", "creation_date" : "1555142250367", "priority" : "1000", "number_of_replicas" : "9", "uuid" : "9t2hotc7S5OpPuKEIJ****", "version" : { "created" : "6070099" } } } } }选择其中一种方式修改配置。
方式一
PUT .security/_settings { "index" : { "auto_expand_replicas" : "0-1" } }方式二
PUT .security/_settings { "index" : { "auto_expand_replicas" : "false", "number_of_replicas" : "1" } }重要number_of_replicas表示索引的副本个数,可以根据实际需求进行配置,但要保证至少有1个,且不大于可用的数据节点个数。
ES如何清理缓存?
您可以登录Kibana控制台,执行如下命令清理缓存:
清除特定索引的缓存
POST /<索引名>/_cache/clear?fielddata=true清除所有缓存
POST /_cache/clear
如何变更ES集群的可用区?
参见迁移与升级可用区操作。
ES集群支持磁盘独立扩容吗?
支持。具体操作请参见升配集群。
扩容会触发集群滚动重启,建议在业务低峰期操作。
ES支持修改JVM参数吗?
阿里云ES的JVM参数使用的是官方ES推荐的参数配置,默认为集群内存的一半,不支持修改,最大可分配32 GB。详细信息请参见Heap size settings。
插件、分词、同义词问题
使用IK分词器时,如何自定义扩展分词词典内容?
您可以通过阿里云ES的IK分词插件的冷更新或热更新功能,添加或删除词典中的内容,详情请参见使用IK分词插件(analysis-ik)。
使用IK分词插件时,提示ik startOffset报错,如何处理?
以上报错触发了ES 6.7版本的bug,需要您重启集群,详情请参见重启集群或节点。
本地IK词库文件丢失,可以在集群管理页面找回吗?
无法找回,只能在集群管理页面上进行删除和更新操作。建议您下载官方主分词和停用分词文件,把对应的主分词和停用词改成您系统词库中的名词,然后重新上传。
更新IK分词词库后,如何使新的词库对之前的数据生效?
需要重建索引。已经配置了IK分词的索引,在IK词典冷更新或热更新操作完成后将只对新数据生效。如果您希望对全部数据生效,需要重建索引,详情请参见配置reindex白名单。
FullGC有标准值吗?
FullGC(清理整个堆空间)是否存在问题,需要通过业务延时,以及对比历史和现在的状况来分析。CMS回收器在内存为75%就会开始回收,需要留一点空间以应付突增流量。
不使用的系统插件可以卸载吗?
部分可卸载。可在系统默认插件列表中查看,如果插件对应的操作列下出现卸载,则表示该插件可卸载,具体操作步骤请参见安装或卸载系统默认插件。
阿里云ES的IK分词插件和开源版本的IK插件的词库一致吗?
一致。阿里云ES IK插件内置的词库就是对应版本的开源IK的词库,详情请参见IK Analysis for Elasticsearch。
自定义插件可以访问外部网络吗,例如读取Github上的词库文件?
自定义插件不支持访问外网。如果要访问外部文件,可将文件上传至阿里云OSS上,通过连接OSS读取文件。
自定义插件支持热更新功能吗?
不支持。如果需要热更新,可参考IK词典热更新的方式,自行配置,详情请参见IK Analysis for Elasticsearch。
analysis-aliws分词是如何配置的,文件的格式是什么样的?
具体配置方式请参见使用AliNLP分词插件(analysis-aliws)。
词典文件要求如下:
文件名:必须是aliws_ext_dict.txt。
文件格式:必须是UTF-8格式。
内容:每行一个词,前后不能有空白字符;需要使用UNIX或Linux的换行符,即每行结尾是\n。如果是在Windows系统中生成的文件,需要在Linux机器上使用dos2unix工具将词典文件处理后再上传。
ES同义词、IK分词、AliNLP分词有哪些区别?
分词类型 | 使用方式 | 功能描述 | 支持上传的文件类型 | 分词器或分析器 |
同义词 | 在集群配置模块,上传同义词文件后使用。 | 在文件中写入几个同义词,查询其中一个,其他的也会显示。 | UTF-8编码的TXT文件 | 自定义 |
IK分词 | analysis-ik插件方式。 | 根据main.dic文件,对一段话进行拆分。查询时,只要查询的内容中包含了拆分后的词,查询结果中就会显示该段话。同时还包含了停用词stop.dic,拆分后,stop.dic文件中包含的词会被过滤掉。对应的词库可以在官方文档中查看。 | UTF-8编码的DIC文件 | 分词器:
|
AliNLP分词 | analysis-aliws插件方式。 | 与IK分词大致相同,但不包含单独的停用词文件。停用词集成在主分词词库:aliws_ext_dict.txt文件中,且词库不对外开放。目前不支持自定义停用词。 | 文件名必须为:aliws_ext_dict.txt,UTF-8编码 |
|
ES IK分词模式在哪里配置?
阿里云ES提供了analysis-ik插件,默认已安装不能卸载。您可以对默认词典进行冷热更新,并在创建索引mappings时应用,详细信息请参见使用IK分词插件(analysis-ik)。
阿里云ES支持哪些内置的中文分词器?
目前阿里云ES支持的内置中文分词器包括analysis-ik和analysis-aliws,您需要配置对应的词典即可使用。
通过OSS热更新词典文件,OSS侧词典文件内容发生变化,ES侧会自动更新吗?
不会。阿里云ES暂时不支持OSS文件热更新,OSS文件内容发生变化后,需要重新手动配置上传才能生效,不支持自动同步更新。并且对于已经配置了IK分词、同义词或AliNLP分词的索引,词典更新后将只对新数据生效。如果您希望对全部数据生效,需要重建索引。
阿里云ES使用的IK分词器是否支持远程字典?
不支持。阿里云ES提供的IK分词器支持上传或更新词典,详细信息请参见使用IK分词插件(analysis-ik)。不支持远程词典及相关配置,例如IKAnalyzer.cfg.xml等。
阿里云ES 7.10版本实例如何安装向量检索插件(aliyun-knn)?
阿里云ES 7.10版本实例的向量检索插件默认集成在apack插件中(默认已安装),安装或卸载向量检索插件都需对apack插件进行操作,详细信息请参见使用apack插件的物理复制功能。其他版本的安装说明,请参见使用向量检索插件(aliyun-knn)。
当实例的内核小版本大于等于1.4.0时,apack插件版本已为最新版本,无需更新。使用时,可通过GET _cat/plugins?v命令获取插件版本。
安装插件重启会影响集群服务吗?
如果集群整体负载不高且索引存在副本分片,一般情况下重启(变更)过程中可对外持续提供服务。但在某些场景下,重启(变更)过程中可能会出现访问超时,例如强制重启并发度高、集群负载很高并且已经存在集群访问不可用的情况、没有副本分片、在重启或强制重启过程中存在大量的写入和查询等场景,建议重启前先在客户端设计好重试机制并且在业务低峰期进行操作。
日志问题
ES支持设置.security日志的保存时间吗?
支持。可以通过ILM索引生命周期进行配置,具体操作请参见通过索引生命周期管理Heartbeat数据。
.security索引保存elastic账号相关信息,定期删除可能会导致账号无法登录ES。
ES如何将日志保存到本地?
可调用ListsearchLog API实现,详情请参见ListSearchLog。
查看不到ES的查询和更新日志,如何处理?
可通过设置慢日志,降低日志记录的时间戳查看,详情请参见相关文档。
如何配置和查看ES实例的慢日志?
如何通过程序定期获取ES实例的慢日志?
可调用阿里云ES的ListSearchLog API实现,详情请参见ListSearchLog。
如何查有哪些客户端在使用ES实例?
可通过ES的访问日志或审计日志查看:
如果您需要查看对应实例的增、删、改、查等操作信息,需要开启审计日志。
如果您需要查看集群node和IP地址、bodySize、请求内容、请求时间、发起请求的客户端IP地址、uri等信息,需要开启访问日志。
访问日志和审计日志的使用限制、注意事项以及开启操作等详细信息,请参见查询日志。
数据备份与恢复问题
ES实例的快照能恢复到其他版本的实例中吗?
如果是自动备份,则只能将快照恢复到原实例中或通过跨集群快照恢复功能进行操作,详情请参见自动备份与恢复和设置跨集群OSS仓库。
如果是手动备份,可以将快照恢复到其他实例中。一般是建议在相同版本之间恢复,不同版本之间可能存在兼容性问题,详情请参见手动备份与恢复。
阿里云ES控制台上升级版本,备份ES数据时,提示集群状态不健康,如何处理?
ES集群状态不健康时,无法成功触发快照备份,建议您优先恢复集群状态为green。
开启了自动备份,但是没有设置过OSS,是不是没有备份成功?
阿里云ES默认为您提供了一个OSS Bucket,您可以参见登录Kibana控制台,在Kibana中使用GET _snapshot/aliyun_auto_snapshot/_all命令,获取自动备份的数据。
通过快照迁移(恢复)数据时,目标端显示分片异常。通过分片恢复指令POST /_cluster/reroute?retry_failed=true依旧无法成功,且对应索引显示异常,如何处理?
快照迁移(恢复)数据时,出现如下异常情况:
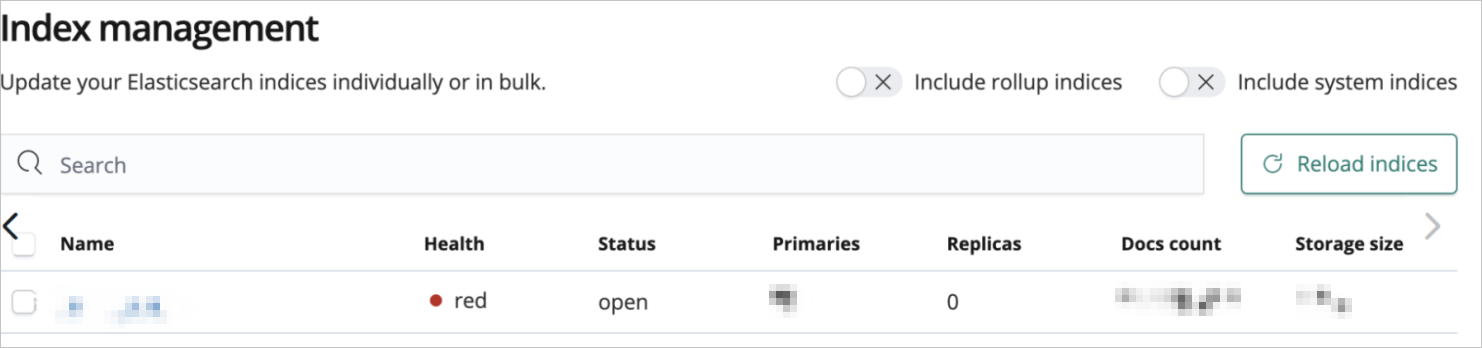
尝试删除问题索引后,再通过_restore API进行恢复。恢复命令中需要添加max_restore_bytes_per_sec参数,限制节点的恢复速度,默认为每秒40 MB。
POST /_snapshot/aliyun_snapshot_from_instanceId/es-cn-instanceId_datetime/_restore
{
"indices": "myIndex",
"settings": {
"max_restore_bytes_per_sec" : "150mb"
}
}您还可以添加其他参数说明,例如:
compress:是否压缩,默认为true。
max_snapshot_bytes_per_sec:每个节点的快照速率,默认为每秒40 MB。
阿里云ES中的数据是否可以导出到本地?
阿里云ES提供了数据备份功能,详情请参见数据备份。您可以先将数据备份到OSS中,再通过OSS的控制台下载文件功能将数据存储到本地。
如何实现跨集群恢复快照?
跨集群恢复快照的具体操作、限制条件和注意事项,请参见设置跨集群OSS仓库。对于同账号跨地域的数据迁移场景,可以通过快照备份与恢复命令实现,更多迁移方案请参见迁移方案选取指南。
阿里云ES有哪些数据备份方案?
阿里云ES的数据备份方案,以及对应方案的使用场景和限制请参见数据备份。
集群监控报警问题
如何配置X-Pack Watcher报警?
配置钉钉机器人接收X-Pack Watcher报警的具体操作,请参见配置钉钉机器人接收X-Pack Watcher报警;配置钉钉机器人接收X-Pack Watcher报警的具体操作,请参见配置企业微信机器人接收X-Pack Watcher报警。
通过为阿里云ES添加X-Pack Watcher,可以实现当满足某些条件时执行某些操作。例如当logs索引中出现error日志时,触发系统自动发送钉钉消息。可以简单地理解为X-Pack Watcher是一个基于ES实现的监控报警服务。
出现GC内存无法分配的报警,如何处理?
可能原因包括:集群负载过高、查询QPS太高或者写入数据太大等,请按照以下说明排查处理:
集群负载过高:参见集群磁盘使用率过高和read_only问题的排查与处理方法处理。
查询QPS太高或者写入数据太大:建议安装集群限流插件(aliyun-qos),使用aliyun-qos插件进行读写限流,详情请参见使用集群限流插件(aliyun-qos)。
说明对于图片检索,建议安装向量检索插件(aliyun-knn),并参见使用向量检索插件(aliyun-knn)进行集群和索引规划。
集群状态指标数值分别表示什么意思?
集群状态指标展示了集群的健康度,数值为0.00时表示正常。指标各数值的含义如下,更多详细信息请参见指标含义与异常处理建议。
数值 | 含义 |
0.00 | 集群状态正常。 |
1.00 | 集群处于亚健康状态。当前集群中某个或某几个索引的副本分片丢失,不影响继续使用。 |
2.00 | 集群状态异常。当前集群中某个或某几个索引的主分片丢失(unassigned),影响集群正常使用,需要尽快修复。 |
如何查看ES的磁盘使用情况?
您可以通过控制台或Kibana的X-Pack监控查看ES的磁盘使用情况,详细信息请参见指标含义与异常处理建议和配置Monitoring监控日志。
CMS GC时报错promotion failed,如何处理?
阿里云Elasticsearch在使用CMS垃圾回收器时可能会遇到该错误,这通常表示老年代空间不足,对象晋升(promotion)到老年代失败。在阿里云Elasticsearch中,若出现此类CMS垃圾回收相关的问题,您可以考虑以下解决措施:
监控与日志分析:
查看GC日志获取详细的垃圾回收信息,分析是否存在频繁的CMS GC操作或Full GC操作,确认是否因老年代空间不足导致
CMS GC promotion failed。登录阿里云Elasticsearch日志查询页面,搜索包含
promotion failed的相关日志记录,进一步了解问题的具体原因。
调整堆内存大小及垃圾回收器设置:
如果Elasticsearch版本>=6.7.0且数据节点内存>=32GB,建议您将垃圾回收器切换至G1,以优化垃圾回收性能。
根据集群实际资源使用情况和业务需求,评估是否需要扩展实例内存。
调优建议:
如果持续出现内存相关问题,可能需要整体评估索引数据量、查询负载以及集群资源配置,必要时联系阿里云技术支持寻求专业调优指导。
基础监控无监控数据如何处理?
问题描述:Elasticsearch实例基础监控页面的监控指标无数据。进入基础监控并查看指标详情,请参见查看集群监控详情。
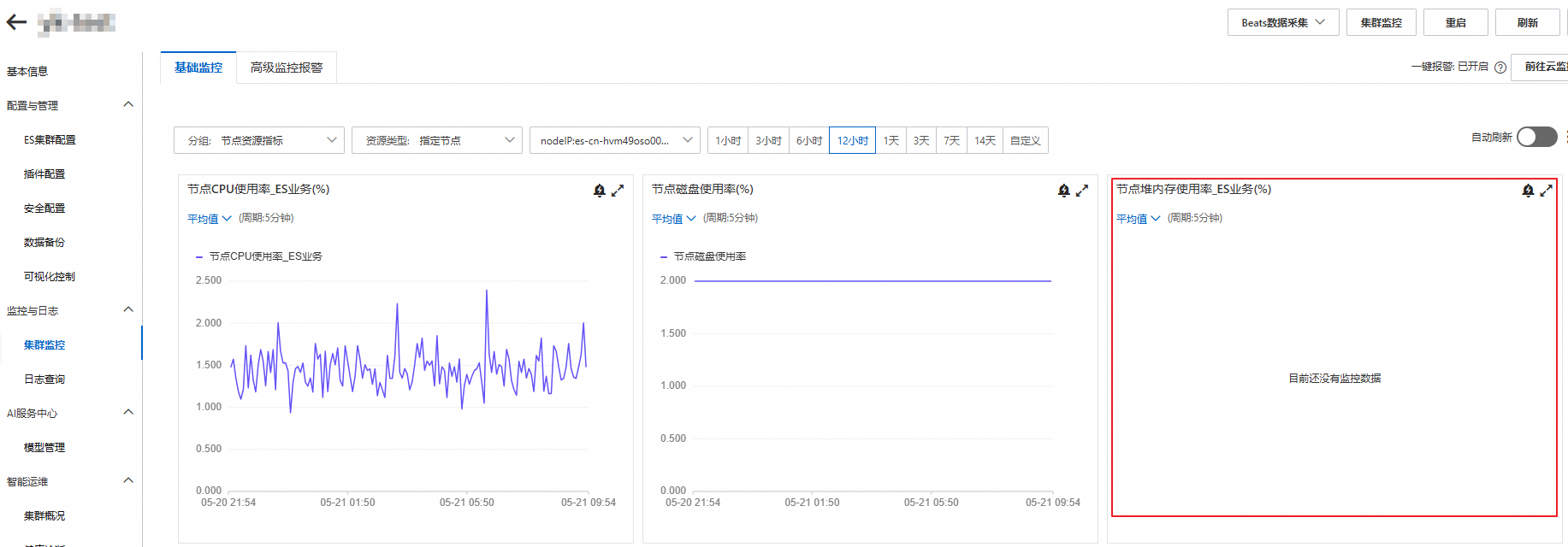
问题原因:监控指标无数据,可能由于后端监控服务异常、集群状态异常或手动关闭监控所导致。
解决方案:请排查是否已开启X-Pack监控功能,并检查其数据收集行为是否符合预期。
说明若Elasticsearch在处理请求时检测到某些数据量超过预设的资源限制(例如,内存不足、查询或索引相关操作存在资源限制),可能会出现
Data too large... which is larger than the limit of报错。为避免集群因资源不足触发熔断,部分用户可能会基于该原因将X-Pack监控功能关闭。使用如下代码查看集群配置信息。
GET /_cluster/settings?pretty开启X-Pack监控功能。
若X-Pack的监控功能关闭,即X-Pack配置为
xpack.monitoring.collection.enabled: false,可执行如下命令开启。PUT _cluster/settings --启用X-Pack监控功能的数据收集。Persistent表示持久化设置,即修改后即使集群重启也会保留当前配置。 { "persistent": { "xpack.monitoring.collection.enabled": true } }
true:表示监控功能开启。
false:表示监控功能关闭。
若执行上述步骤后,基础监控仍无监控数据,请提交工单联系技术支持人员处理。
访问集群问题
如何使用客户端连接阿里云ES集群,与开源ES有什么区别?
使用阿里云ES的内网或外网地址连接,对应开源ES的集群地址,详情请参见通过客户端访问阿里云Elasticsearch。
通过客户端访问ES实例时,可以关闭Basic Auth(安全认证)吗?
不可以。Basic Auth是X-pack自带的Kibana认证机制,ES实例包含X-Pack功能,因此不支持关闭Basic Auth。
阿里云ECS和ES的VPC相同,但可用区不同,那ECS可以通过内网访问ES吗?
可以。只要ECS和ES在同一VPC下,就可以通过内网访问。
如何配置ES的公网或私网访问白名单?
当您需要通过公网或私网来访问阿里云Elasticsearch实例时,可将待访问设备的IP地址加入到实例的公网或私网访问白名单组中,具体操作请参见配置实例公网或私网访问白名单。配置时,需要注意:
配置公网地址访问白名单时,需要先打开公网地址开关(默认关闭),再进行操作。
白名单下的IP地址或者IP网段数量最多支持50个。
如果您设置的白名单为IP网段的形式,那么您填写的IP地址需要为掩码计算后子网网段的第一个IP地址。
阿里云Elasticsearch不允许同时配置0.0.0.0/0和一个或多个具体的IP地址或IP网段,否则系统会提示报错。如果您需要配置0.0.0.0/0用来测试,请单独配置。
如何通过外网连接ES实例?
可通过实例的公网地址来连接,并且需要配置公网地址访问白名单,详情请参见配置实例公网或私网访问白名单。连接时需要配置访问域名、用户名和密码等参数,详情请参见通过客户端访问阿里云Elasticsearch。
无法访问ES,报错Failed to establish a new connection: [Errno 61] Connection refused
可能原因及解决方案如下。
可能原因 | 解决方案 |
公网访问不通 | 在通过公网域名访问ES的场景下,请按照以下方式排查解决:
|
私网访问不通 | 在通过私网域名访问ES的场景下,请按照以下方式排查解决:
|
集群自身状况不佳 | 在网络都连通的情况下,出现无法访问ES,请按照以下方式排查集群自身状况,根据具体情况自行解决:
|
重置密码是否会影响ES访问?
控制台重置密码会影响您使用elastic账号访问阿里云ES实例,不影响其他非elastic账号访问该实例。因此建议不要在程序中通过elastic账号访问实例,而是通过自定义用户来访问(需要给用户赋予相应的权限)。详细信息,请参见通过Elasticsearch X-Pack角色管理实现用户权限管控。
密码修改完成并确认提交后,不会触发实例重启。
Elasticsearch-Head插件5.0.0版本无法访问阿里云ES(所有版本),如何处理?
该类问题一般与Chrome限制跨域相关,下面是Mac安装Chrome后解决Chrome跨域问题的方法,其他操作系统请以Chrome跨域配置为准。
新建一个空的文件夹。
打开终端输入以下命令。
open-n/Applications/Google\Chrome.app/--args--disable-web-security--user-data-dir=新建的空文件夹路径
由于Elasticsearch-Head插件在5.x版本之后已不再维护,因此建议您使用Cerebro访问阿里云ES实例,详细信息请参见通过Cerebro连接集群。
索引相关问题
如何关闭索引?
当ES中的索引状态被设置为close后,该索引将不再支持查询和写入。
POST /<index_name>/_open #将索引设置为open状态
POST /<index_name>/_close #将索引设置为close状态