本文汇总了YARN使用时的常见问题。
集群问题汇总
组件问题汇总
RM
NM
UI或REST API
TimelineServer
集群有状态重启包括哪些内容?
集群有状态重启包括RM Restart和NM Restart两部分,ResourceManager(简称RM)负责维护应用级基础信息与状态,NodeManager(简称NM)负责维护运行时的Container信息与状态,它们持续将相关状态同步至外部存储(Zookeeper、LevelDB和HDFS等),并在重启后重新加载状态自行恢复,保证集群升级或重启后应用自动恢复,通常情况下可以做到应用无感知。
如何启用RM HA?
您可以在EMR控制台YARN服务的配置页签,检查或者配置以下参数启用RM HA。
参数 | 描述 |
yarn.resourcemanager.ha.enabled | 设置为true,表示开启HA。 默认值为false。 |
yarn.resourcemanager.ha.automatic-failover.enabled | 使用默认值true,表示启用自动切换。 |
yarn.resourcemanager.ha.automatic-failover.embedded | 使用默认值true,表示使用嵌入的自动切换方式。 |
yarn.resourcemanager.ha.curator-leader-elector.enabled | 设置为true,表示使用curator组件。 默认值为false。 |
yarn.resourcemanager.ha.automatic-failover.zk-base-path | 使用默认值/yarn-leader-electionleader-elector。 |
如何配置热更新?
以下操作内容适用于Hadoop 3.2.0及后续版本。
开启关键配置。
您可以在EMR控制台YARN服务的配置页签,检查或者配置以下参数。
参数
描述
参数值(推荐)
yarn.scheduler.configuration.store.class
使用的后备存储的类型。例如,设置为fs,表示使用FileSystem类型存储。
fs
yarn.scheduler.configuration.max.version
保留历史版本的最大数量,超出自动清理。
100
yarn.scheduler.configuration.fs.path
capacity-scheduler.xml文件存储路径。
不存在存储路径时,则自动创建。不指定前缀时,则默认defaultFs的相对路径。
/yarn/<集群名>/scheduler/conf
重要将<集群名>替换为集群名称以便区分,可能有多个YARN集群对应同一分布式存储的情况。
查看capacity-scheduler.xml配置。
方式一(REST API):http://<rm-address>/ws/v1/cluster/scheduler-conf。
方式二(HDFS文件):${yarn.scheduler.configuration.fs.path}/capacity-scheduler.xml.<timestamp>,其中后缀<timestamp>值最大的文件是最新的配置文件。
更新配置。
示例:更新一个配置项yarn.scheduler.capacity.maximum-am-resource-percent,并删除配置项yarn.scheduler.capacity.xxx,删除某配置项只需去掉其Value值。
curl -X PUT -H "Content-type: application/json" 'http://<rm-address>/ws/v1/cluster/scheduler-conf' -d ' { "global-updates": [ { "entry": [{ "key":"yarn.scheduler.capacity.maximum-am-resource-percent", "value":"0.2" },{ "key":"yarn.scheduler.capacity.xxx" }] } ] }'
如何处理Queue内应用分配不均?
以下操作内容适用于Hadoop 2.8.0及后续版本。
Queue内部资源通常会被大作业占据,小作业较难获得资源,希望各作业能公平获得资源。您可以通过以下步骤处理:
修改Queue配置yarn.scheduler.capacity.<queue-path>.ordering-policy,使其调度次序由fifo(默认值)改为fair。
说明FIFO Scheduler为先进先出调度器,Fair Scheduler为公平调度器。
您还可以修改参数yarn.scheduler.capacity.<queue-path>.ordering-policy.fair.enable-size-based-weight,该参数默认值false,表示按used资源值从小到大排序,参数值为true时表示按照used或demand计算值从小到大排序。
开启队列内抢占。
队列内抢占常用参数如下表所示。
参数
描述
参数值(推荐)
yarn.resourcemanager.scheduler.monitor.enable
抢占功能总开关,在yarn-site.xml中配置,其余参数是在capacity-scheduler.xml中配置。
true
yarn.resourcemanager.monitor.capacity.preemption.intra-queue-preemption.enabled
队列内抢占开关(队列间抢占无开关,默认开启)。
true
yarn.resourcemanager.monitor.capacity.preemption.intra-queue-preemption.preemption-order-policy
抢占策略优先考虑应用优先级,默认值为userlimit_first。
priority_first
yarn.scheduler.capacity.<queue-path>.disable_preemption
指定Queue不被抢占,默认false。
true表示不允许指定Queue资源被抢占,子Queue未配置则继承父Queue配置值。
true
yarn.scheduler.capacity.<queue-path>.intra-queue-preemption.disable_preemption
指定Queue不开启队列内抢占,默认值false。
true表示禁用Queue内抢占,子Queue未配置则继承父Queue配置值。
true
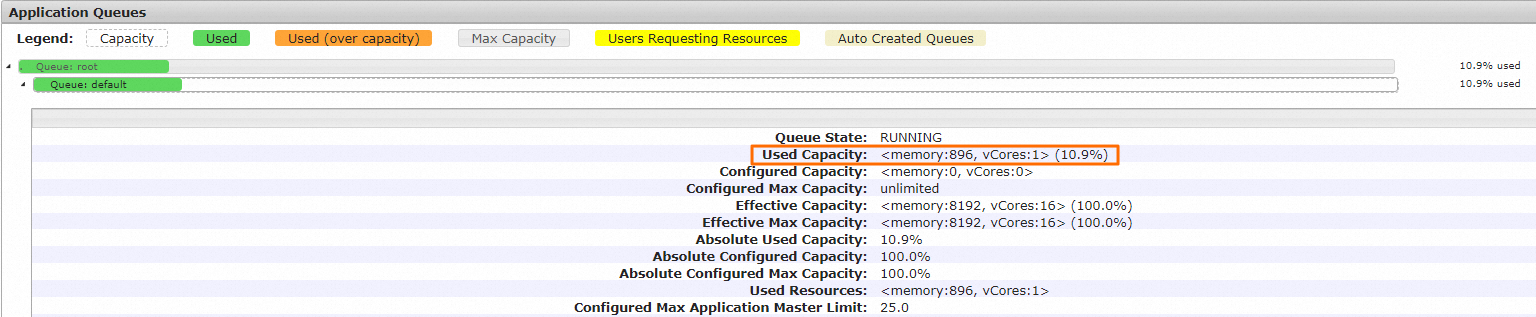
如何查看队列资源使用情况?
要查看队列资源使用情况,您可以在YARN WebUI页面查看Used Capacity参数。Used Capacity参数表示该队列已使用的资源占该队列整体资源的百分比,分别计算Memory和vCores占总体的比例,并选取最大值作为队列整体资源使用的比例。具体查看操作如下:
访问YARN UI,详情请参见通过控制台访问开源组件Web界面。
在All Applications页面,单击目标作业的ID。
单击Queue行的队列。
在Application Queues区域,可以查看队列资源使用情况。
YARN服务组件.out日志为何会大量堆积且无法自动清理?
问题原因:Hadoop组件部分依赖库使用Java Logging APIs来生成日志记录,不支持使用log4j配置的日志轮转。目前这些daemon组件的stderr输出被重定向到
.out文件中,没有自动清理机制,长时间积累可能导致数据盘存储空间被占满。处理方法:可以使用
head和tail命令结合日志中生成的时间戳信息,来判断是否由于Java Logging APIs生成的日志导致存储空间占用过大。通常情况下,这些依赖库产生的都是INFO级别日志,不影响组件正常功能使用,但为了避免数据盘存储空间被占用,可以采取修改配置的方式禁用此类日志的生成。例如,在优化TimelineServer组件以关闭jersey依赖库的日志生成时,操作步骤如下:
通过以下命令,监控YARN日志路径中与
hadoop-timelineserver-相关的.out日志文件。DataLake集群的日志路径为/var/log/emr/yarn/,Hadoop集群日志路径为/mnt/disk1/log/hadoop-yarn。tail /var/log/emr/yarn/*-hadoop-timelineserver-*.out观察到输出日志中包含由com.sun.jersey组件产生的记录。

为了禁止组件输出Jersey库的INFO级别日志到.out 文件,创建并配置一个文件来关闭其日志生成。在运行有TimelineServer组件的EMR节点上,可以通过执行以下命令以root权限创建并编辑配置文件。
sudo su root -c "echo 'com.sun.jersey.level = OFF' > $HADOOP_CONF_DIR/off-logging.properties"在EMR控制台中YARN服务的配置页面,查找
YARN_TIMELINESERVER_OPTS参数(Hadoop集群为yarn_timelineserver_opts),并在此参数值后添加-Djava.util.logging.config.file=off-logging.properties,指定刚刚创建的配置文件位置。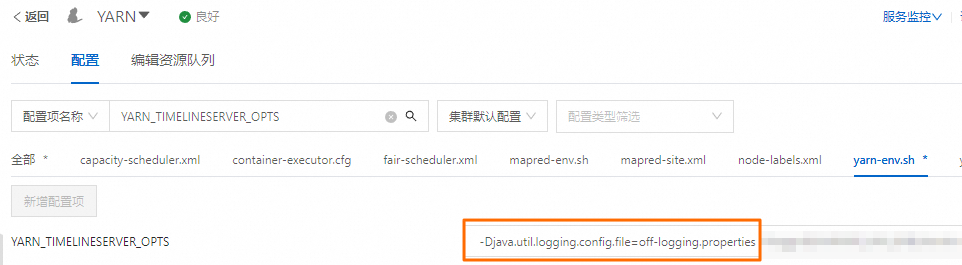
保存上述配置更改后,重启TimelineServer组件使新设置生效。持续观察一段时间,如果TimelineServer组件正常启动,并且
.out日志中不再出现任何与com.sun.jersey相关的日志信息,则说明关闭jersey依赖库日志的操作已成功完成。
如何检查ResourceManager服务是否正常?
您可以通过以下方式检查:
检查ResourceManager HA状态(如果集群已启用HA,需确保有且只有一个Active ResourceManager),以下方式任选一种,检查字段haState是否为ACTIVE或STANDBY,haZooKeeperConnectionState是否为CONNECTED:
命令行:yarn rmadmin -getAllServiceState
REST API:http://<rmAddress>/ws/v1/cluster/info
示例如下。

检查应用状态。
执行以下命令,查看是否有持续的SUBMITTED或ACCEPTED状态。
yarn application -list查看提交的新应用是否可以正常运行并结束。命令示例如下。
hadoop jar <hadoop_home>/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*-tests.jar sleep -m 1 -mt 1000 -r 0您可以在
sleep -m之间新增配置项以指定Queue,新增的参数为-Dmapreduce.job.queuename,参数值为default。
如何了解应用运行状况?
您可以查看以下信息。
查询信息 | 描述 |
基本信息 | 包括ID、User、Name、Application Type、State、Queue、App-Priority、StartTime、FinishTime、State、FinalStatus、Running Containers、Allocated CPU VCores、Allocated Memory MB和Diagnostics(诊断信息)等。
|
Queue信息 |
|
Container日志 |
|
应用问题排查流程
检查App状态,通过App详情页或App REST API检查App状态。
未找到App状态,可能原因:
客户端向YARN提交之前失败退出:客户端组件问题(检查提交客户端日志:BRS、flowagent等组件)。
客户端无法连接YARN RM:检查连接RM地址是否正确、网络是否存在问题。如有网络问题,客户端可能存在报错:
com.aliyun.emr.flow.agent.common.exceptions.EmrFlowException: ###[E40001,RESOURCE_MANAGER]: Failed to access to resource manager, cause: The stream is closed。
NEW_SAVING:该状态处于Zookeeper State Store写入应用信息阶段。持续该状态可能原因如下:
Zookeeper存在问题,检查Zookeeper服务是否正常。
Zookeeper读写数据问题,处理方法请参见RM处于Standby状态,无法自动恢复Active状态,该如何处理?。
SUBMITTED:该状态极少遇到,可能原因为Node Update请求太多造成Capacity Scheduler内部抢锁堵塞,通常发生在大规模集群,需优化相关流程。相关案例,请参见YARN-9618。
ACCEPTED:检查Diagnostics。请根据提示信息,选择相应的处理方式。
报错提示Queue's AM resource limit exceeded。
可能原因:Queue AM已使用资源和AM资源之和超出了Queue AM资源上限,UI条件为${Used Application Master Resources} + ${AM Resource Request} < ${Max Application Master Resources}。
处理方法:上调该Queue的AM资源上限。例如,设置参数yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent为0.5。
报错提示User's AM resource limit exceeded。
可能原因:Queue user AM已使用资源和AM资源之和超出了Queue user AM资源上限。
处理方法:提高user-limit比例。您可以修改参数yarn.scheduler.capacity.<queue-path>.user-limit-factor和yarn.scheduler.capacity.<queue-path>.minimum-user-limit-percent的参数值。
报错提示AM container is launched, waiting for AM container to Register with RM。
可能原因:AM已启动,内部初始化未完成(例如,Zookeeper连接超时等)。
处理方法:需要根据AM日志进一步排查问题。
报错提示Application is Activated, waiting for resources to be assigned for AM。
执行步骤3,检查AM资源分配为何未满足。
RUNNING:执行步骤2,检查Container资源请求是否完成。
FAILED:检查diagnostics。请根据提示信息,选择相应的处理方式。
报错提示Maximum system application limit reached,cannot accept submission of application
可能原因:集群内运行中的总应用数超过上限(配置项:yarn.scheduler.capacity.maximum-applications,默认值:10000)。
处理方法:检查JMX Metrics,确认各队列运行的应用数是否符合预期,找出并处理有大量重复提交的问题应用。如果应用都正常,可以根据集群水位情况适当调大上述配置。
报错提示Application XXX submitted by user YYY to unknown queue: ZZZ
可能原因:提交到不存在的queue。
处理方法:提交到已存在的leaf queue。
报错提示Application XXX submitted by user YYY to non-leaf queue: ZZZ
可能原因:提交到parent queue。
处理方法:提交到已存在的leaf queue。
报错提示Queue XXX is STOPPED. Cannot accept submission of application: YYY
可能原因:提交到STOPPED或DRAINING queue(已下线或正在下线的queue)。
处理方法:提交到RUNNING queue(工作状态正常的queue)。
报错提示Queue XXX already has YYY applications, cannot accept submission of application: ZZZ
可能原因:queue应用数达到上限。
处理方法:
检查queue内是否有大量重复提交的问题应用。
调整配置:yarn.scheduler.capacity.<queue-path>.maximum-applications。
报错提示Queue XXX already has YYY applications from user ZZZ cannot accept submission of application: AAA
可能原因:user应用数达到上限。
处理方法:
检查该user是否有大量重复提交的问题应用。
调整配置:yarn.scheduler.capacity.<queue-path>.maximum-applications、yarn.scheduler.capacity.<queue-path>.minimum-user-limit-percent、yarn.scheduler.capacity.<queue-path>.user-limit-factor。
确认YARN资源分配还未完成。
在apps列表页,单击appID进入AM页面。
单击下方列表的AM-ID,进入AM-Attempt页面。
查看Total Outstanding Resource Requests列表中是否有Pending资源(也可以通过PendingRequests REST API查询):
没有Pending资源:说明YARN已分配完毕,退出该检查流程,检查AM情况。

有Pending资源:说明YARN资源分配未完成,继续下一步检查。
资源限制检查。
检查集群或Queue资源,查看资源信息,例如,Effective Max Resource和Used Resources。
检查集群资源或所在Queue资源或其父Queue资源是否已用完。
检查叶子队列某维度资源是否接近或达到上限。
当集群资源接近用满时(例如85%以上),应用的分配速度可能会变慢,因为大部分机器都没有资源了,分配的机器没有资源就会reserve,reserve到一定个数后分配就会变慢,另外也可能是由于内存资源和CPU资源不成比例,例如,有的机器上内存资源有空闲但CPU资源已经用满,有的机器上CPU资源有空闲但内存已经用满。
检查是否存在Container资源分配成功但启动失败的情况,YARN UI的App Attempt页面可以看到已分配的Container数(间隔一小段时间观察是否变化),如果有Container启动失败,查看对应的NM日志或Container日志进一步排查失败原因。
动态修改日志级别:在YARN UI的logLevel页面(http://RM_IP:8088/logLevel),将org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity(CapacityScheduler调度逻辑所在的package)参数的日志级别改为DEBUG,如下图所示。
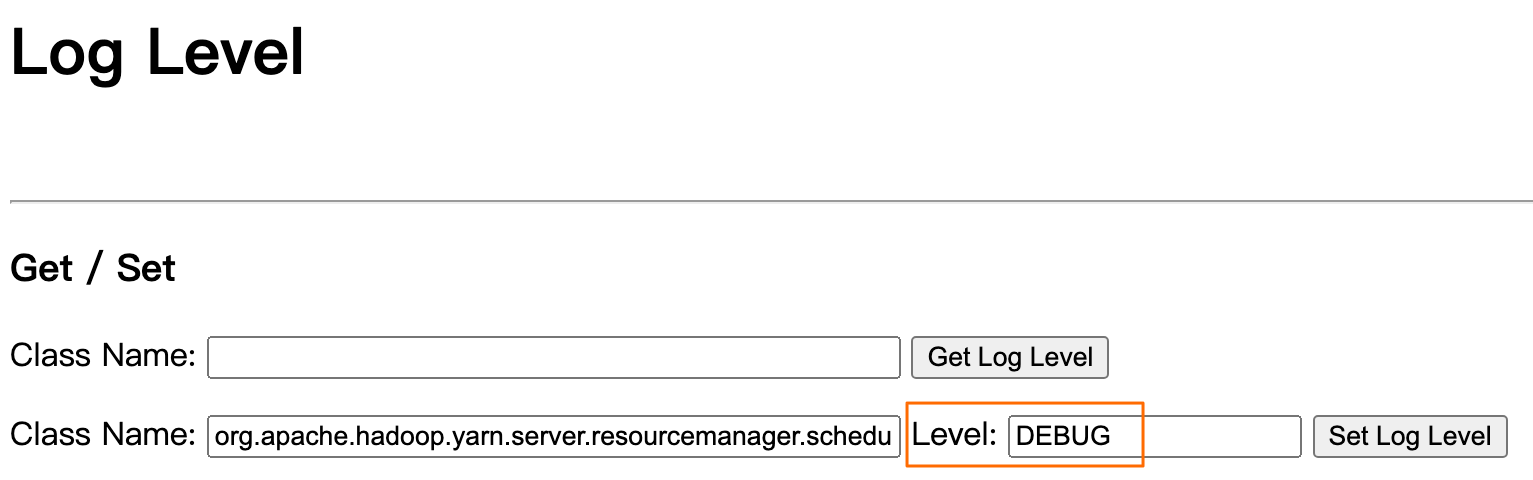 重要
重要您需要在复现问题的同时打开,持续几十秒(由于日志刷新的很快,无需持续太长时间),日志级别改回INFO即可恢复。
单任务/容器(Container)最大可用资源由哪些配置项决定?
由调度器或队列(queue)配置项决定:
配置项 | 配置说明 | 默认值 |
yarn.scheduler.maximum-allocation-mb | 集群级最大可调度内存资源,单位:MB。 | EMR默认值为:创建集群时最大非master实例组的可用内存(与最大实例组的 yarn.nodemanager.resource.memory-mb参数的配置值相同)。 |
yarn.scheduler.maximum-allocation-vcores | 集群级最大可调度CPU资源,单位:VCore。 | EMR默认值为32。 |
yarn.scheduler.capacity.<queue-path>.maximum-allocation-mb | 指定队列的最大可调度内存资源,单位:MB。 | 默认未配置,配置则覆盖集群级配置,仅对指定队列生效。 |
yarn.scheduler.capacity.<queue-path>.maximum-allocation-vcores | 指定队列的最大可调度CPU资源,单位:VCore。 | 默认未配置,配置则覆盖集群级配置,仅对指定队列生效。 |
如果申请资源超过单任务或容器(Container)的最大可用资源配置,应用日志中能够发现异常信息InvalidResourceRequestException: Invalid resource request… 。
YARN配置修改未生效,如何处理?
可能原因
非热更新配置,配置关联的组件未重启。
热更新配置,配置生效所需的指定操作未执行。
解决方案:请确保相关配置修改的后续操作正确执行。
配置集
配置类型
更新后续操作
capacity-scheduler.xml
fair-scheduler.xml
调度器配置。
热更新配置,需要执行RM组件的refresh_queues操作。
yarn-env.sh
yarn-site.xml
mapred-env.sh
mapred-site.xml
YARN组件运行配置。
重启配置关联组件。例如:
修改配置yarn-env.sh中的YARN_RESOURCEMANAGER_HEAPSIZE、yarn-site.xml中的yarn.resourcemanager.nodes.exclude-path等配置项后,需重启RM。
修改配置yarn-env.sh中的YARN_NODEMANAGER_HEAPSIZE、yarn-site.xml中的yarn.nodemanager.log-dirs等配置项后,需重启NM。
修改配置mapred-env.sh中的MAPRED_HISTORYSERVER_OPTS、mapred-site.xml中的mapreduce.jobhistory.http.policys等配置项后,需重启MRHistoryServer。
客户端异常,提示Exception while invoking getClusterNodes of class ApplicationClientProtocolPBClientImpl over rm2 after 1 fail over attempts. Trying to fail over immediately
问题现象:无法正常访问Active ResourceManager。ResourceManager日志异常,提示信息:WARN org.apache.hadoop.ipc.Server: Incorrect header or version mismatch from 10.33.**.**:53144 got version 6 expected version 9。
问题原因:Hadoop版本太旧,导致客户端RPC版本不兼容。
处理方法:使用匹配的Hadoop版本。
RM处于Standby状态,无法自动恢复Active状态,该如何处理?
您可以通过以下方式排查问题:
检查支持自动恢复的必选配置项是否配置正确。
参数
描述
yarn.resourcemanager.ha.enabled
需要配置为true。
yarn.resourcemanager.ha.automatic-failover.enabled
需要配置为true。
yarn.resourcemanager.ha.automatic-failover.embedded
需要配置为true。
修改为上述配置后,问题还未解决,您可以通过以下方式排查问题:
检查Zookeeper服务是否正常。
检查Zookeeper客户端(RM)读取数据是否超出其Buffer上限。
问题现象:RM日志内存在异常,提示Zookeeper error len*** is out of range!或Unreasonable length = ***。
处理方法:在EMR控制台YARN服务的配置页面,单击yarn-env页签,更新参数yarn_resourcemanager_opts的参数值为-Djute.maxbuffer=4194304 ,然后重启RM。
Zookeeper服务端写入数据是否超出其Buffer上限。
问题现象:Zookeeper日志内存在异常,提示Exception causing close of session 0x1000004d5701b6a: Len error ***。
处理方法:Zookeeper服务各节点新增或更新配置项-Djute.maxbuffer= (单位:bytes) ,将Buffer上限调大超过异常显示的长度。
如果RM或Zookeeper日志都找不到异常,可能是因为RM选主Zookeeper Ephemeral Node(${yarn.resourcemanager.zk-state-store.parent-path}/${yarn.resourcemanager.cluster-id}/ActiveStandbyElectorLock)被其他Session持有未释放,可在zkCli命令窗口中stat该节点确认,默认选主方式可能存在未知问题或触发Zookeeper问题。
建议修改选主方式,在yarn-site页签中,新增或更新配置项yarn.resourcemanager.ha.curator-leader-elector.enabled为true ,然后重启RM。
RM组件OOM如何处理?
RM OOM包括多种问题类型,您需要先根据RM日志确定问题类型,可能的问题类型及对应的原因和解决方案如下:
Java heap space或GC overhead limit exceeded或频繁FullGC
原因
直接原因:JVM堆空间不足,RM进程内部对象无法获取到足够的资源,并且在抛出OOM之前已经进行过一轮或多轮FullGC回收了失效的对象,仍无法获取足够的堆空间用于分配。
原因分析:RM有很多常驻对象(不能被JVM回收的对象),包括集群、队列(queue)、应用、执行任务容器(container)、节点(node)等各类信息。这些信息占用的堆空间随着集群规模增大而增大,因此对于规模较大的集群需要保证RM进程的内存配置也较大。另一方面,由于需要保留应用的历史信息,随着时间推移历史应用占用的存储空间越来越大,即使是只有1个节点的最小规模集群,也需要确保有一定的存储空间(建议不低于2 GB)。
解决方案
如果Master节点资源足够,建议适当增大RM堆内存(yarn-env.sh配置项YARN_RESOURCEMANAGER_HEAPSIZE)。
对于小规模集群,也可以考虑适当减小需要存储的历史应用数量(yarn-site.xml配置项yarn.resourcemanager.max-completed-applications,默认:10000)。
unable to create new native thread
原因:RM所在节点上已用的总线程数达到系统上限,无法创建新的线程。
线程数上限由用户最大可用线程数(查看命令:
ulimit -a | grep "max user processes")和PID最大可用数(查看命令:cat /proc/sys/kernel/pid_max)决定。解决方案
如果可用线程数配置过低,调大相关系统配置。通常规格小的节点可用线程数需配置数万量级,规格大的节点需配置十几万或几十万量级。
如果可用线程数配置正常,通常是节点上存在个别问题进程占用过多线程导致,可以进一步定位哪些进程占用线程较多。
执行命令:
ps -eLf | awk '{print $2}' | uniq -c | awk '{print $2"\t"$1}' | sort -nrk2 | head,查看占用线程数最多的Top10进程,格式:[进程ID] [占用线程数]。
为什么节点启动任务时Localize失败或任务日志无法采集与删除?
问题现象:NM日志异常,提示java.io.IOException: Couldn't create proxy provider class org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider。
可能原因:HDFS配置异常。
处理方法:
以上是封装后的异常,非根因,需要打开DEBUG级别日志查看:
hadoop客户端命令行环境(例如执行
hadoop fs -ls /命令),开启DEBUG调试信息。export HADOOP_LOGLEVEL=DEBUG有Log4j配置的运行环境,Log4j末尾增加
log4j.logger.org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider=DEBUG。
以下示例的根因是用户曾修改过NameServices配置,将emr-cluster修改为了hadoop-emr-cluster,但是扩容节点时使用了修改前的配置。
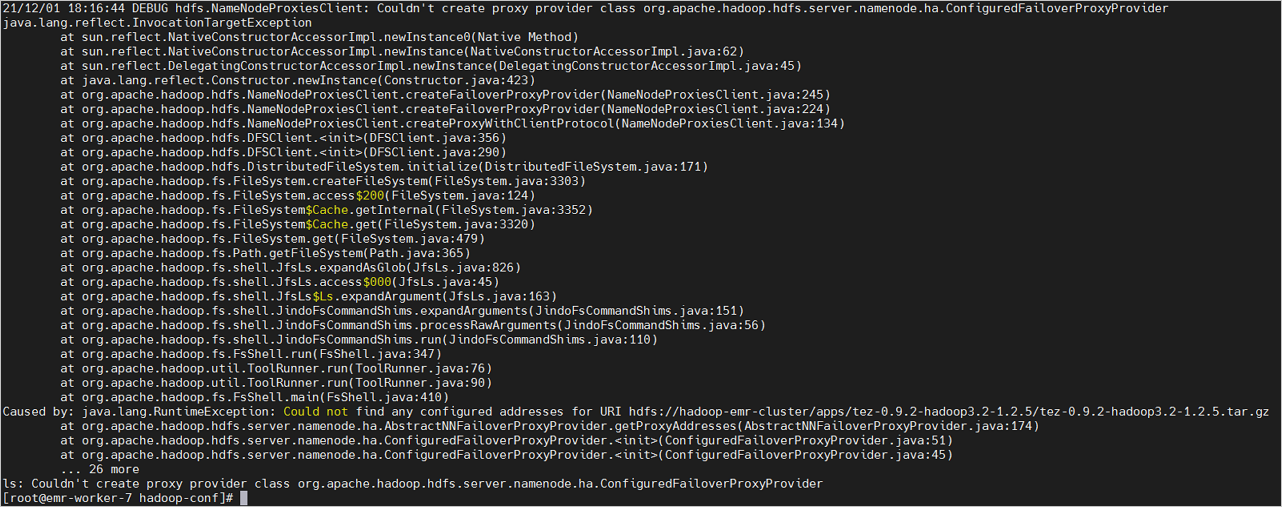
在EMR控制台HDFS服务的配置页面,检查各项配置是否正确。
资源本地化异常,该如何处理?
问题现象:
Job AM Container启动失败,异常信息如下。
Failed job diagnostics信息为:Application application_1412960082388_788293 failed 2 times due to AM Container for appattempt_1412960082388_788293_000002 exited with exitCode: -1000 due to: EPERM: Operation not permitted在资源本地化过程中(下载后解压时)报错,NodeManager日志信息如下。
INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ResourceLocalizationService: Failed to download rsrc { { hdfs://hadoopnnvip.cm6:9000/user/heyuan.lhy/apv/small_apv_20141128.tar.gz, 1417144849604, ARCHIVE, null },pending,[(container_1412960082388_788293_01_000001)],14170282104675332,DOWNLOADING} EPERM: Operation not permitted at org.apache.hadoop.io.nativeio.NativeIO$POSIX.chmodImpl(Native Method) at org.apache.hadoop.io.nativeio.NativeIO$POSIX.chmod(NativeIO.java:226) at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:629) at org.apache.hadoop.fs.DelegateToFileSystem.setPermission(DelegateToFileSystem.java:186) at org.apache.hadoop.fs.FilterFs.setPermission(FilterFs.java:235) at org.apache.hadoop.fs.FileContext$10.next(FileContext.java:949) at org.apache.hadoop.fs.FileContext$10.next(FileContext.java:945) at org.apache.hadoop.fs.FSLinkResolver.resolve(FSLinkResolver.java:90) at org.apache.hadoop.fs.FileContext.setPermission(FileContext.java:945) at org.apache.hadoop.yarn.util.FSDownload.changePermissions(FSDownload.java:398) at org.apache.hadoop.yarn.util.FSDownload.changePermissions(FSDownload.java:412) at org.apache.hadoop.yarn.util.FSDownload.changePermissions(FSDownload.java:412) at org.apache.hadoop.yarn.util.FSDownload.call(FSDownload.java:352) at org.apache.hadoop.yarn.util.FSDownload.call(FSDownload.java:57) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:744)
问题原因:压缩包内含有软链接导致资源本地化异常。
处理方法:删除该压缩包内包含的软链接。
Container启动失败或运行异常,报错提示No space left on device,该如何处理?
可能原因及排查思路如下:
磁盘已满。
检查/sys/fs/cgroup/cpu/hadoop-yarn/cgroup.clone_children和/sys/fs/cgroup/cpu/cgroup.clone_children的Cgroups配置。
如果cgroup.clone_children的值为0,请修改为1,开机启动项时,设置命令
echo 1 > /sys/fs/cgroup/cpu/cgroup.clone_children。如果没有上述问题,请检查同级的cpuset.mems或cpuset.cpus文件,hadoop-yarn目录中的值需要和上层一样。
可能是Cgroups目录的子目录数超出上限65535造成的,检查YARN配置yarn.nodemanager.linux-container-executor.cgroups.delete-delay-ms或者yarn.nodemanager.linux-container-executor.cgroups.delete-timeout-ms。
节点NM服务或任务运行时无法正常解析域名,该如何处理?
问题现象:报错提示java.net.UnknownHostException: Invalid host name: local host is: (unknown)。
问题原因及处理方法:
查看是否正确配置了DNS服务器。
通过以下命令,检查配置信息。
cat /etc/resolv.conf查看防火墙是否设置了53端口的相关规则。
如果设置了,请关闭防火墙。
查看是否开启了DNS的NSCD缓存服务。
通过以下命令,检查服务状态。
systemctl status nscd如果开启了DNS的NSCD缓存服务,可以执行以下命令,停止缓存服务。
systemctl stop nscd
NM组件OOM如何处理?
NM OOM包括多种问题类型,您需要先根据NM日志确定问题类型,可能的问题类型及对应的原因和解决方案如下:
Java heap space或GC overhead limit exceeded或频繁FullGC
原因
直接原因:JVM堆空间不足,NM进程内部对象无法获取到足够的资源,并且在抛出OOM之前已经进行过一轮或多轮FullGC回收了失效的对象,仍无法获取足够的堆空间用于分配。
原因分析:NM进程中的常驻对象不多,一般只包含当前节点、运行应用、执行任务容器(Container)等基本信息,这部分占用空间不会很大。可能占用空间较大的是External Shuffle Service的Cache和Buffer,这部分受Shuffle Service相关配置(例如Spark:spark.shuffle.service.index.cache.size或spark.shuffle.file.buffer,MapReduce:mapreduce.shuffle.ssl.file.buffer.size或mapreduce.shuffle.transfer.buffer.size等)影响,并且与使用了Shuffle Service的运行应用数(或执行任务容器数)成正比。这些信息占用的堆空间随着使用ShuffleService应用数或任务容器数的增大而增大,因此对于规格较大可运行任务较多的节点需要保证NM进程的内存配置也较大(建议最小不低于1 GB)。
解决方案
如果节点资源足够,建议适当增大NM堆内存(yarn-env.sh配置项YARN_NODEMANAGER_HEAPSIZE)。
检查Shuffle Service相关配置是否合理,例如Spark Cache配置不应该占用大部分堆内存。
Direct buffer memory
原因
直接原因:堆外内存溢出导致的OOM,通常与External Shuffle Service有关,例如有的Shuffle Service服务的RPC调用使用了NIO DirectByteBuffer,就会用到堆外内存。
原因分析:堆外内存跟使用ShuffleService的应用数或任务容器数成正比。对于使用Shuffle Service的任务较多的节点,需要确认NM进程的堆外内存配置是否过小。
解决方案
检查堆外内存配置-XX:MaxDirectMemorySize(yarn-env.sh配置项YARN_NODEMANAGER_OPTS)是否合理。无此配置时默认与堆内存大小相同,不合理时适当调大堆外内存空间。
unable to create new native thread
参见RM组件OOM如何处理?中的unable to create new native thread部分的内容进行分析解决。
ECS实例重启后NM启动失败:cgroup目录丢失,如何处理?
详细异常信息:ResourceHandlerException: Unexpected: Cannot create yarn cgroup Subsystem:cpu Mount point:/proc/mounts User:hadoop Path:/sys/fs/cgroup/cpu/hadoop-yarn
原因:ECS异常重启可能是ECS内核缺陷(已知问题版本:4.19.91 -21.2.al7.x86_64)导致的。重启后CPU cgroup失效问题,原因是重启后cgroup的内存数据会被销毁掉。
解决方案:修改存量集群节点执行和扩容节点的引导脚本,在当前环境中创建cgroup目录并且用rc.local在以后ECS启动的时候创建目录。
# enable cgroups mkdir -p /sys/fs/cgroup/cpu/hadoop-yarn chown -R hadoop:hadoop /sys/fs/cgroup/cpu/hadoop-yarn # enable cgroups after reboot echo "mkdir -p /sys/fs/cgroup/cpu/hadoop-yarn" >> /etc/rc.d/rc.local echo "chown -R hadoop:hadoop /sys/fs/cgroup/cpu/hadoop-yarn" >> /etc/rc.d/rc.local chmod +x /etc/rc.d/rc.local
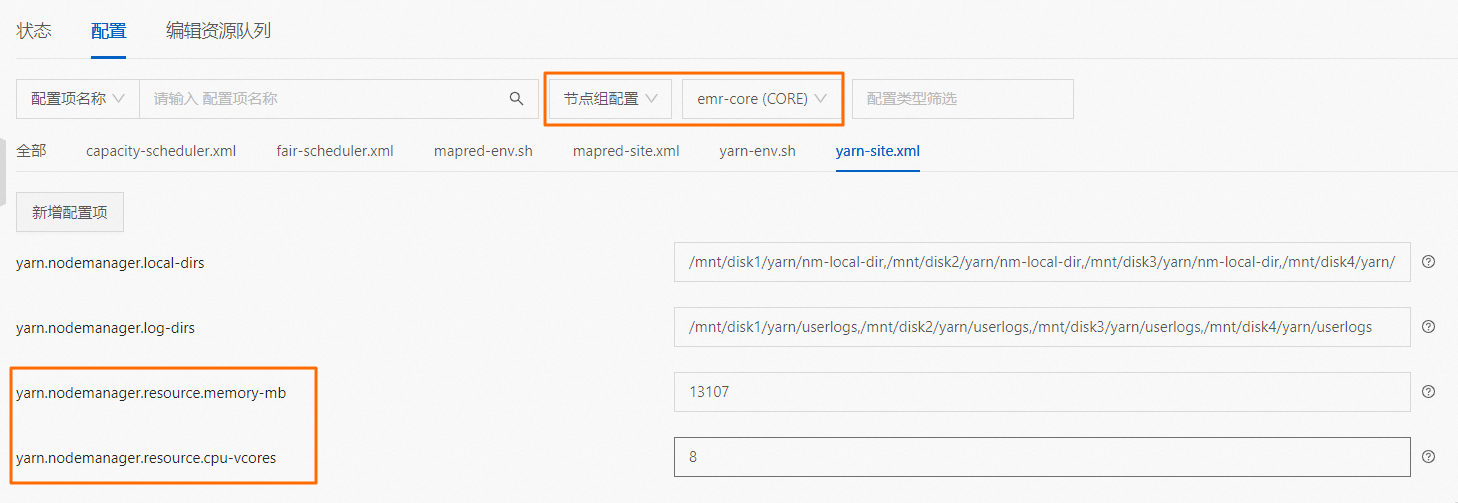
修改NM resource配置,保存重启后未生效,如何处理?
报错说明:修改yarn.nodemanager.resource.cpu-vcores和yarn.nodemanager.resource.memory-mb参数,保存重启NM后,NM资源数未修改。
问题原因:由于机器组可能使用不同CPU内存规格的实例,所以修改yarn.nodemanager.resource.cpu-vcores和yarn.nodemanager.resource.memory-mb参数,需要修改节点组维度的配置才能生效。
解决方案:在EMR控制台,选择节点组维度,选择需要配置的NM所在节点组修改资源数的配置,具体操作请参见管理配置项。
节点出现Unhealthy问题,如何处理?
原因:
磁盘检查发现异常:当正常目录数或总目录数比率低于磁盘健康比例(yarn-site.xml配置项yarn.nodemanager.disk-health-checker.min-healthy-disks,默认值:0.25)时,将节点标记为UnHealthy。例如NM节点使用4块磁盘,当4块磁盘上的目录均不正常时节点才会标记为UnHealthy,否则只在NM状态报告中显示local-dirs are bad或log-dirs are bad,参见节点磁盘问题:local-dirs are bad/log-dirs are bad,如何处理?。
NM健康检查脚本发现异常:该项检查默认未启用,需要主动配置健康检查脚本(yarn-site.xml配置项yarn.nodemanager.health-checker.script.path)才能开启。
解决方案
磁盘问题,请参见节点磁盘问题:local-dirs are bad/log-dirs are bad,如何处理?中的解决方案。
健康检查脚本问题,请根据自定义脚本处理。
节点磁盘问题:local-dirs are bad/log-dirs are bad,如何处理?
原因:磁盘检查发现异常。该项检查默认开启,周期性检查local-dirs(任务运行缓存目录,包括任务运行依赖的各类文件、中间数据文件等)与log-dirs(任务运行日志目录,包含全部日志运行)是否满足以下条件,只要有一项不满足就会被标记为bad。
可读
可写
可执行
磁盘空间使用率是否低于配置阈值(yarn-site.xml配置项yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage,默认:90%)
磁盘剩余可用空间是否大于磁盘最小可用空间的配置值(yarn-site.xml配置项yarn.nodemanager.disk-health-checker.min-free-space-per-disk-mb,默认:0)
解决方案
一般都是磁盘空间不足引起,如果确认存在下述场景之一,建议扩容磁盘:
NM节点规格较大,可运行任务数较多。
磁盘空间相对较小。
任务运行所依赖的数据或文件较大。
任务运行产生的中间数据较多。
任务日志相对较大(磁盘空间占比高)。
检查yarn-site.xml配置项yarn.nodemanager.localizer.cache.target-size-mb,如果相对磁盘比例过大会造成历史任务缓存占用磁盘空间过多(超出配置值后才能自动清理)。
坏盘问题,请参见自助坏盘维修流程更换集群损坏的本地盘。
报错提示User [dr.who] is not authorized to view the logs for application ***,该如何处理?
问题现象:打开日志页面时,提示信息如下。

问题原因:访问NodeManager Log页面时会检查ACL规则。如果启用了ACL规则,远程用户就要符合以下任一个条件:
是admin用户。
是app owner。
满足app自定义ACL规则。
处理方法:检查是否满足以上条件中的任一条。
报错提示HTTP ERROR 401 Authentication required或HTTP ERROR 403 Unauthenticated users are not authorized to access this page,该如何处理?
问题现象:访问UI或REST API时报错HTTP ERROR 401或HTTP ERROR 403。HTTP ERROR 401详细信息如下图。
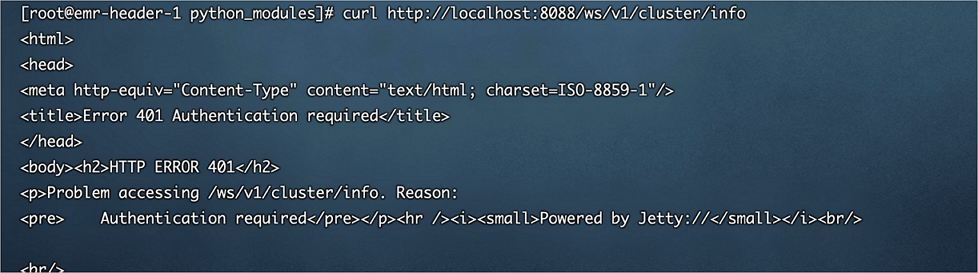
问题原因:YARN启用了Simple认证且不允许匿名访问,详情请参见Authentication for Hadoop HTTP web-consoles。
处理方法:
方式一:URL参数中显示指定远程用户,例如,user.name=***。
方式二:您可以在E-MapReduce控制台的HDFS服务的配置页签,在搜索区域搜索参数hadoop.http.authentication.simple.anonymous.allowed,修改其参数值为true允许匿名访问,参数含义请参见Authentication for Hadoop HTTP web-consoles。然后重启服务,请参见重启服务。
为什么TotalVcore显示值不准确?
在YARN UI右上方,Cluster或Metrics REST API结果中,TotalVcore显示值不准确。此问题是由于社区2.9.2之前版本TotalVcore计算逻辑有问题,详情请参见https://issues.apache.org/jira/browse/YARN-8443。
EMR-3.37.x和EMR-5.3.x及后续版本已修复此问题。
TEZ UI展示的应用信息不全,该如何处理?
您可以打开浏览器的开发者工具,排查并处理遇到的问题:
如果是路径为http://<rmAddress>/ws/v1/cluster/apps/APPID的异常,则可能原因是该应用已经被RM清理出去(YARN RM最多保留一定数量的历史应用信息,默认1000个,超出的会将历史应用按启动顺序清理出去)。
如果是路径为http://<tsAddress>/ws/v1/applicationhistory/...的异常,直接访问该URL(http://<tsAddress>/ws/v1/applicationhistory/... )返回500异常(提示找不到app),则可能原因是该应用信息未成功存储(RM发起,查看yarn.resourcemanager.system-metrics-publisher.enabled配置项),或已被Timeline Store清理(查看LevelDB TTL相关配置)。
如果是路径为http://<tsAddress>/ws/v1/timeline/...的异常,直接访问该URL(http://<tsAddress>/ws/v1/timeline/...)返回正常(code为200),但是内容是NotFound信息。
查看AM日志(syslog)启动时打印信息,正常初始化信息如下:
[INFO] [main] |history.HistoryEventHandler|: Initializing HistoryEventHandler withrecoveryEnabled=true, historyServiceClassName=org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService [INFO] [main] |ats.ATSHistoryLoggingService|: Initializing ATSHistoryLoggingService with maxEventsPerBatch=5, maxPollingTime(ms)=10, waitTimeForShutdown(ms)=-1, TimelineACLManagerClass=org.apache.tez.dag.history.ats.acls.ATSHistoryACLPolicyManager如果有以下异常信息,说明AM运行时yarn.timeline-service.enabled配置异常,可能原因为FlowAgent问题(FlowAgent里对Hive作业有2种实现,一种是Hive命令,另外一种是Beeline命令,此时默认配置yarn.timeline-service.enabled为false。)
[WARN] [main] |ats.ATSHistoryLoggingService|: org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService is disabled due to Timeline Service being disabled, yarn.timeline-service.enabled set to false
为什么YARN UI页面有一个正在运行的Spark Thrift JDBC/ODBC Server任务?
如果您在创建集群时选择了Spark服务,集群会自动启动一个默认的Spark Thrift Server服务。该服务会占用一个YARN Driver的资源。在Spark Thrift Server中运行的任务,默认会通过该Driver向YARN申请所需的资源。
yarn.timeline-service.leveldb-timeline-store.path是否支持使用OSS地址?
yarn.timeline-service.leveldb-timeline-store.path参数不支持使用OSS地址。
如果您创建的是Hadoop集群,则yarn.timeline-service.leveldb-timeline-store.path的默认值与hadoop.tmp.dir参数相同。请不要修改HDFS的hadoop.tmp.dir参数,因为这会影响yarn.timeline-service.leveldb-timeline-store.path的配置。
Timeline Server连接超时、CPU或Memory占用异常高问题,该如何处理?
在Tez任务特别多的情况下,写入YARN的Timeline Server时,可能会出现连接超时的问题。这是因为Timeline Server进程占用大量CPU导致节点CPU使用率达到极限,进而影响到了作业开发和其他非核心业务(例如报表生成),所以临时停止TimelineServer进程来减轻节点的CPU负载。您可以通过修改以下配置项来解决此问题。
在EMR控制台修改Tez和YARN服务的相应配置,新增或修改配置的具体操作,请参见管理配置项。
在EMR控制台Tez服务的配置页面的tez-site.xml页签,新增参数为tez.yarn.ats.event.flush.timeout.millis,参数值为60000的配置项,该参数用来设置Tez任务将事件写入YARN的Timeline Server时的超时时间。
在EMR控制台YARN服务的配置页面的yarn-site.xml页签,新增或修改以下配置项。修改完配置项后需要在YARN服务的状态页面重启下TimelineServer。
参数
参数值
说明
yarn.timeline-service.store-class
org.apache.hadoop.yarn.server.timeline.RollingLevelDBTimelineStore
用于指定YARN Timeline Server的事件存储类。
yarn.timeline-service.rolling-period
daily
用于设置YARN Timeline Server的事件滚动周期
yarn.timeline-service.leveldb-timeline-store.read-cache-size
4194304
用于设置YARN Timeline Server LevelDB存储的读取缓存大小。
yarn.timeline-service.leveldb-timeline-store.write-buffer-size
4194304
用于设置YARN Timeline Server LevelDB存储的写入缓冲区大小。
yarn.timeline-service.leveldb-timeline-store.max-open-files
500
用于设置YARN Timeline Server LevelDB存储的最大打开文件数。