DLF-Auth组件是数据湖构建DLF(Data Lake Formation)产品提供的,通过该组件可以开启数据湖构建DLF的数据权限功能,可以对数据库、数据表、数据列、函数进行细粒度权限控制,实现数据湖上统一的数据权限管理。本文为您介绍如何开启DLF-Auth权限。
背景信息
数据湖构建DLF是一款全托管的快速帮助用户构建云上数据湖的服务,提供了云上数据湖统一的权限管理和元数据管理,详细信息请参见数据湖构建产品简介。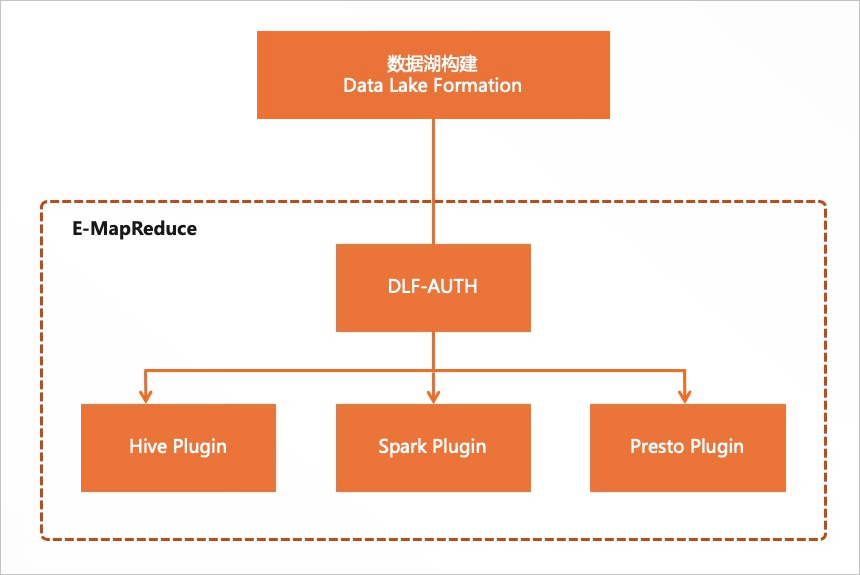
前提条件
已创建E-MapReduce集群,并选择了OpenLDAP服务,详情请参见创建集群。
在创建集群的软件配置页面,元数据使用默认的DLF统一元数据。
使用限制
数据湖构建DLF权限仅支持通过RAM用户进行权限管理,因此需要在EMR控制台通过用户管理功能添加用户。
数据湖构建DLF的数据权限管理功能支持区域请参见已开通的地域和访问域名。
DLF-Auth启用Hive或Spark后,Ranger将无法点击启用或禁用Hive或Spark;Ranger启用Hive或Spark后,DLF-Auth将无法点击启用或禁用Hive或Spark。
DLF-Auth支持的EMR版本及计算引擎列表。
EMR 主版本
Hive
Spark
Presto
Impala
EMR 3.x版本
EMR-3.39.0及以前版本
不支持
不支持
不支持
不支持
EMR-3.40.0
支持
支持
支持
不支持
EMR-3.41.0至EMR-3.43.1
支持
支持
不支持
不支持
EMR-3.44.0及以上版本
支持
支持
支持
支持
EMR 5.x版本
EMR-5.5.0及以前版本
不支持
不支持
不支持
不支持
EMR-5.6.0
支持
支持
支持
不支持
EMR-5.7.0至EMR-5.9.1
支持
支持
不支持
不支持
EMR-5.10.0 及以上版本
支持
支持
支持
支持
操作流程
通过本文操作,您可以开启DLF-Auth,实现数据湖上全托管的统一的权限管理。
步骤一:开启Hive权限控制
进入DLF-Auth页面。
登录EMR on ECS。
在顶部菜单栏处,根据实际情况选择地域和资源组。
在EMR on ECS页面,单击目标集群操作列的集群服务。
在集群服务页面,单击DLF-Auth服务区域的状态。
开启Hive权限控制。
在DLF-Auth服务页面,打开enableHive开关。
在弹出的对话框中,单击确定。
重启HiveServer。
在集群服务页面,选择Hive服务。
在Hive服务页面,单击HiveServer操作列的。
在弹出的对话框中,输入执行原因,单击确定。
在确认对话中,单击确定。
步骤二:添加RAM用户
您可以通过用户管理功能添加用户,详细操作如下。
进入用户管理页面。
登录EMR on ECS。
在顶部菜单栏处,根据实际情况选择地域和资源组。
在EMR on ECS页面,单击目标集群操作列的集群服务。
单击上方的用户管理页签。
在用户管理页面,单击添加用户。
在添加用户对话框中,在用户名下拉列表中,选择已有的RAM用户作为EMR用户的名称,输入密码和确认密码。
单击确定。
步骤三:验证权限
如果RAM用户已拥有AliyunDLFDssFullAccess权限,或者RAM用户被授予了AdministratorAccess,则该RAM用户具备了所有DLF细粒度资源的访问权限,无需进行数据授权操作。
授权前验证当前用户权限。
使用SSH方式登录到集群,详情请参见登录集群。
执行以下命令访问HiveServer2。
beeline -u jdbc:hive2://master-1-1:10000 -n <user> -p <password>说明<user>和<password>为步骤二:添加RAM用户中您设置的用户名和密码。
查看已有数据表信息。
例如,执行以下命令,查看test表信息。
testdb.test请根据您实际信息修改。select * from testdb.test;因为当前用户没有权限,会报没有权限而查询失败的错。

为RAM用户添加权限。
登录数据湖构建控制台。
在左侧导航栏中,选择。
在数据授权页面,单击新增授权。
在新增授权页面,配置以下参数。
参数
描述
授权主体
主体类型
默认RAM用户。
主体选择
在主体选择下拉列表中,选择您在步骤二:添加RAM用户中添加的用户。
授权资源
授权方式
默认资源授权。
资源类型
根据您实际情况选择。
本文示例为元数据表。
权限配置
数据权限
本文示例为Select。
授权权限
单击确定。
授权后验证当前用户权限。
参见步骤1重新查看数据表的信息,因为已经授权,所以可以查询到相关数据表的信息。
(可选)步骤四:开启Hive LDAP认证
如果开启了DLF-Auth权限,建议您开启Hive LDAP认证,以便于连接Hive的用户都可以通过LDAP认证后执行相关脚本。
进入集群服务页面。
登录EMR on ECS。
在顶部菜单栏处,根据实际情况选择地域和资源组。
在EMR on ECS页面,单击目标集群操作列的集群服务。
开启LDAP认证。
在集群服务页面,单击Hive服务区域的状态。
打开enableLDAP开关。
EMR-5.11.1及之后版本,EMR-3.45.1及之后版本
在服务概述区域,打开enableLDAP开关。
在弹出的对话框中,单击确定。
EMR-5.11.0及之前版本,EMR-3.45.0及之前版本
在组件列表区域,选择HiveServer操作列的
 > enableLDAP。
> enableLDAP。在弹出的对话框中,输入执行原因,单击确定。
在确认对话框中,单击确定。
重启HiveServer。
在组件列表区域,单击HiveServer操作列的重启。
在弹出的对话框中,输入执行原因,单击确定。
在确认对话框中,单击确定。