EAS服務部署成功後,您可以在服務監控頁面查看相關指標,瞭解服務的調用和運行情況。本文介紹如何查看服務監控資訊並提供監控指標的詳細說明。
查看服務監控資訊
登入PAI控制台,在頁面上方選擇目標地區,並在右側選擇目標工作空間,然後單擊進入EAS。
單擊目標服務名稱進入詳情頁面,切換到监控頁簽。
查看服務監控資訊。
切換儀錶盤
儀錶盤分為服務和執行個體維度,切換方式如下:

Service:服務維度,預設服務監控儀錶盤名稱格式為
Service-<service_name>,其中<service_name>是EAS服務的名稱。Instance:執行個體維度,分單一實例和多執行個體。
Single Instance:單一實例監控儀錶盤,支援切換不同執行個體查看。
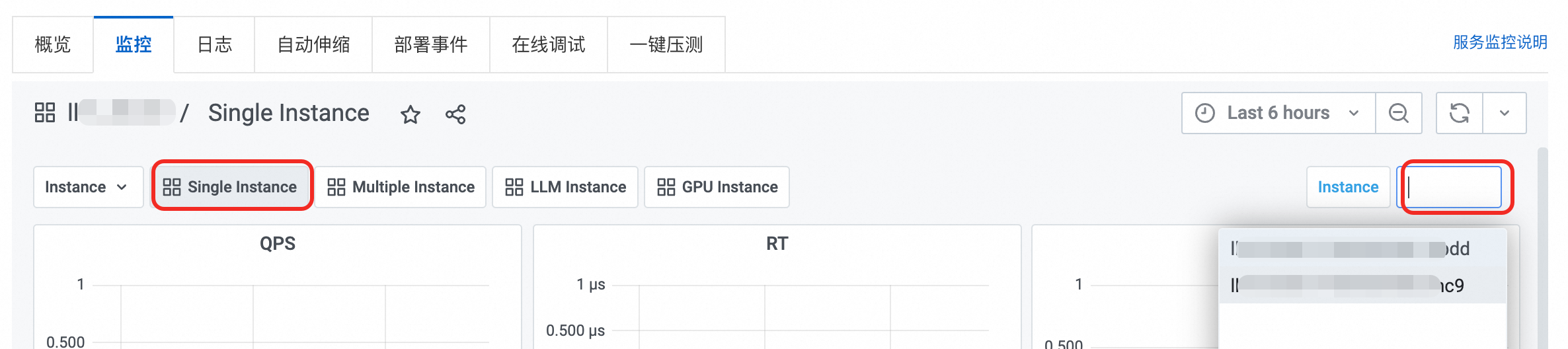
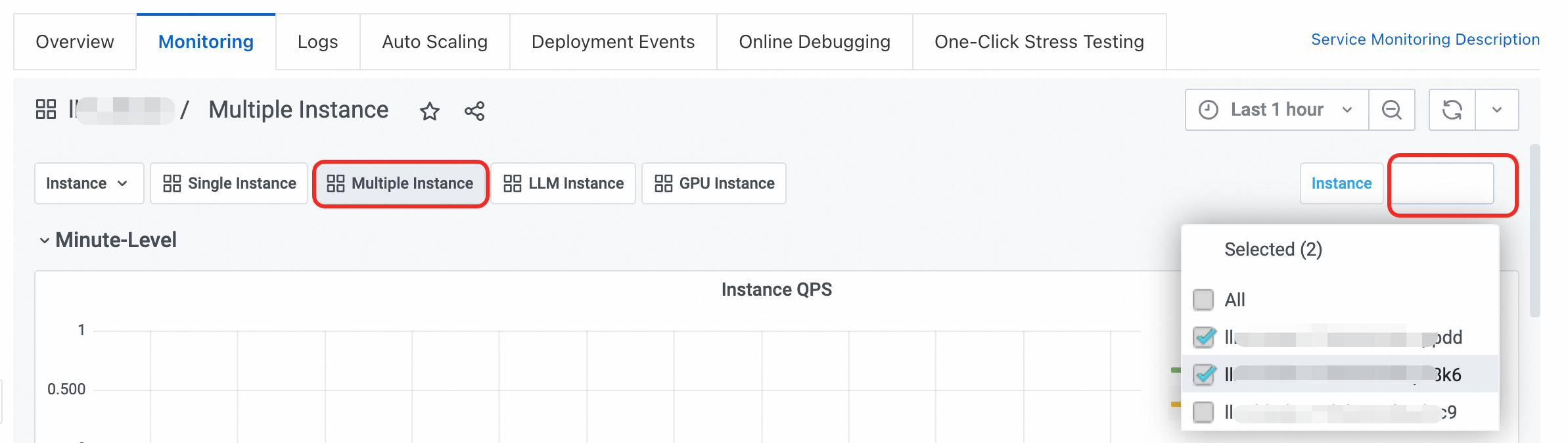
Multiple Instance:多執行個體監控儀錶盤,可自由選擇多個執行個體對比查看。
切換時間範圍
單擊監控地區右側的
 ,切換儀錶盤展示的時間範圍。
,切換儀錶盤展示的時間範圍。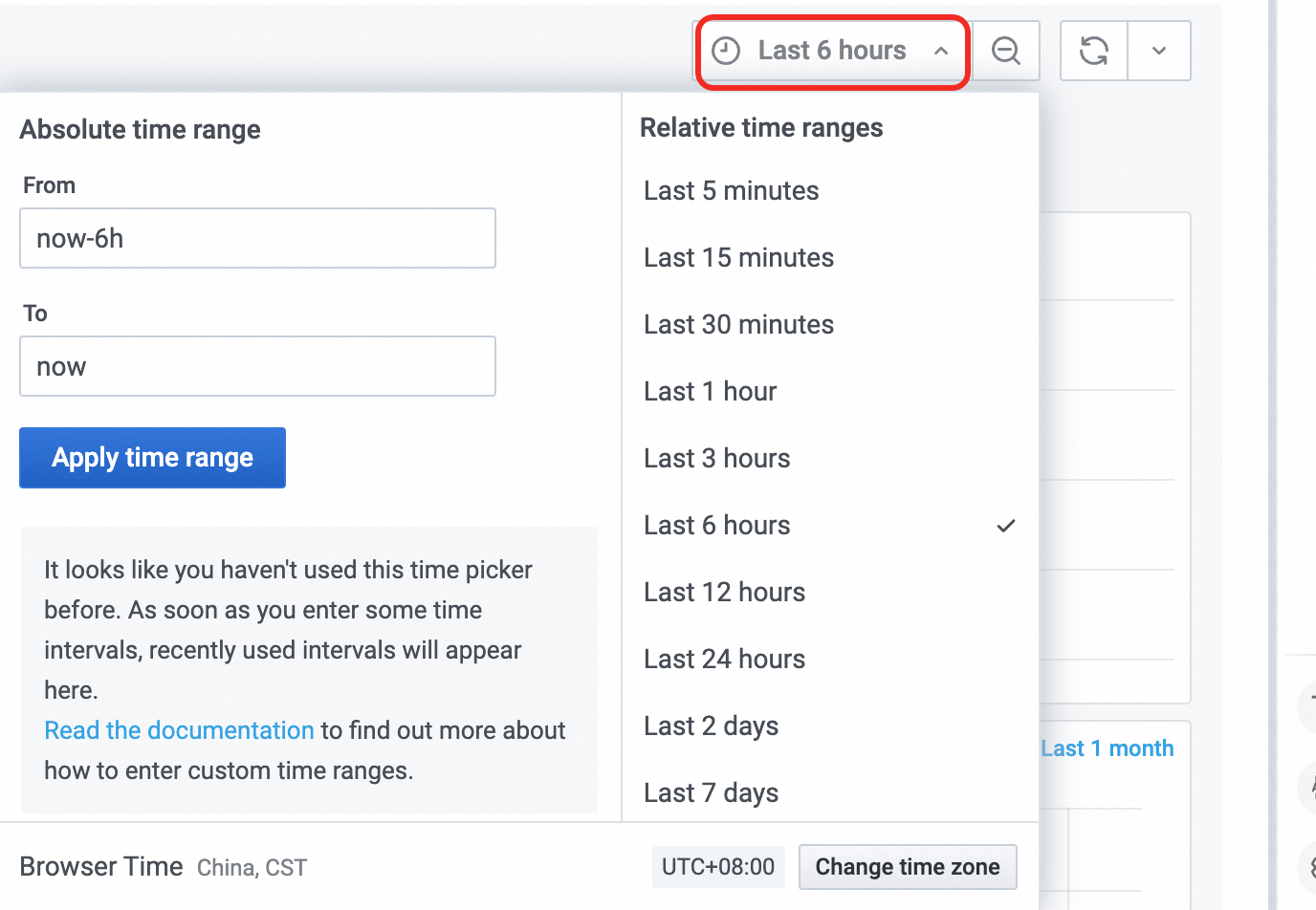 重要
重要目前分鐘級監控指標最多保留1個月,秒級監控指標最多保留1個小時。
重要當服務標籤配置了
"ServiceEngineType": "vllm"或"ServiceEngineType" : "sglang"時,才會展示LLM相關的監控項。
監控指標說明
服務監控儀錶盤(分鐘級)
您可以在該儀錶盤監控以下指標:
指標 | 說明 | |
QPS | 服務每秒的請求數。不同返回碼的請求數會分開計算。如果服務包含多個執行個體,則此處的指標為所有執行個體之和。其中,1d offset表示前一天同一時間的QPS資料,可用於分析環比資料。 | |
Response | 服務在選定時間範圍內接收的響應總數。不同返回碼的響應數會分開計算。如果服務包含多個執行個體,則此處的指標為所有執行個體之和。 | |
RT | 請求的回應時間。
| |
Daily Invoke | 服務每天的調用量,不同返回碼的調用量會分開計算。如果服務包含多個執行個體,則此處的指標為所有執行個體之和。 | |
單執行個體監控儀錶盤(分鐘級)
您可以在該儀錶盤監控以下指標:
指標 | 說明 |
QPS | 該執行個體每秒接收的請求數。不同返回碼的請求數會分開計算。 |
RT | 該執行個體請求的回應時間。 |
Response | 該執行個體在選定時間範圍內接收的響應總數。不同返回碼的響應數會分開計算。 |
多執行個體監控儀錶盤
提供分鐘級、秒級監控指標如下。
Minute-Level(分鐘級)
指標
說明
Instance QPS
每個執行個體每秒的請求數。不同返回碼的請求數會分開計算。
Instance RT
每個執行個體的平均回應時間。
Instance CPU
每個執行個體的CPU使用量,單位為核心數。
Instance Memory -- RSS
每個執行個體常駐實體記憶體大小。
Instance Memory -- Cache
每個執行個體緩衝大小。
Instance GPU
每個執行個體GPU使用率。
Instance GPU Memory
每個執行個體GPU顯存的使用量。
Instance TCP Connections
每個執行個體TCP串連數。
Second-Level(秒級)
重要資料精度精確到5秒層級,只保留最近1個小時的資料。
指標
說明
Instance QPS Fine
每個執行個體每秒接收的請求數。不同返回碼的請求數會分開計算。
Instance RT Fine
每個執行個體接收到請求的平均回應時間。
GPU監控儀錶盤
支援在服務和執行個體層級監控以下GPU指標。如果是服務等級,則指標是所有執行個體的平均值。
指標 | 說明 |
GPU Utilization | 服務在該時間點的GPU使用率。 |
GPU Memory | 服務在該時間點的GPU顯存使用量與顯存總量。
|
Memory Copy Utilization | 服務在該時間點的GPU顯存複製利用率。 |
GPU Memory Utilization | 服務在該時間點的GPU顯存使用率,計算方法為:顯存使用量 ÷ 顯存總量。 |
PCIe | 服務在該時間點的通過DCGM測量的PCIe(Peripheral Component Interconnect Express,高速串列電腦擴充匯流排標準)速率。
|
Memory Bandwidth | 服務在該時間點的GPU顯存頻寬指標。 |
SM Utilization and Occupancy | 服務在該時間點的SM(Streaming Multiprocessor,流式多處理器)相關指標,SM是GPU的核心組成部分,負責執行和調度並行計算任務。
|
Graphics Engine Utilization | 服務在該時間點的GPU圖形引擎利用率。 |
Pipe Active Ratio | 服務在該時間點的GPU運算管道的活躍率。
|
Tflops Usage | 服務在該時間點的GPU運算管道的Tflops(Tera floating-point operations per second,每秒萬億次浮點運算)運算量。
|
DRAM Active Ratio | 服務在該時間點的GPU裝置顯存介面發送或接收資料的活躍率。 |
SM Clock | 服務在該時間點的SM時鐘頻率。 |
GPU Temperature | 服務在該時間點的GPU溫度相關指標。
|
Power Usage | 服務在該時間點的GPU功耗。 |
VLLM監控儀錶盤
如果服務有多個執行個體,以下吞吐相關指標是執行個體的總和,延遲相關指標是執行個體的均值。
指標 | 說明 |
Requests Status | 服務在該時間點的所有請求數。
|
Token Throughput | 服務在該時間點所有請求的輸入與產生的Token數。
|
Request Completion Status | 服務在該時間點所有請求的完成狀態統計。
|
Time To First Token | 服務在該時間點所有請求的首Token延時(從接收到請求到產生第一個Token的時間)。
|
Time Per Output Token | 服務在該時間點所有請求的每Token延時(產生第一個Token之後的每個輸出Token所需的平均時間)。
|
E2E Request Latency | 服務在該時間點所有請求的端到端延時(從接收到請求到返回所有Token的時間)。
|
Queue Time | 服務在該時間點所有請求的排隊等待延時(請求排隊等待被引擎處理的時間)。
|
Inference Time | 服務在該時間點所有請求的推理延時(請求被引擎處理的時間)。
|
Prefill Time | 服務在該時間點所有請求在 Prefill 階段的延時(引擎處理請求輸入Token的時間)。
|
Decode Time | 服務在該時間點所有請求在 Decode 階段的延時(引擎產生輸出Token的時間)。
|
Input Token Length | 服務在該時間點處理的輸入token數。
|
Output Token Length | 服務在該時間點產生的輸出token數。
|
Request Parameters(params_n & max_tokens) | 服務在該時間點所有請求的參數N和參數max_tokens。
|
GPU KV Cache Usage | 服務在該時間點的 GPU KV緩衝平均使用率。 |
CPU KV Cache Usage | 服務在該時間點的 CPU KV緩衝平均使用率。 |
Prefix Cache Hit Rate | 服務在該時間點所有請求的 Prefix緩衝平均命中率。
|
HTTP Requests by Endpoint | 服務在該時間點按要求方法、路徑和響應狀態代碼分組的請求數。 |
HTTP Request Latency | 服務在該時間點不同請求路徑的平均延時。 |
Speculative Decoding Throughput | 服務在該時間點的推測解碼數。如果服務包含多個執行個體,則此處的指標為所有執行個體的平均值。
|
Speculative Decoding Efficiency | 服務在該時間點的推測解碼效能。
|
Token Acceptance by Position | 服務在該時間點在不同產生位置的 Drafts Token 接受數。如果服務包含多個執行個體,則此處的指標為所有執行個體的平均值。 |
SGLang監控儀錶盤
如果服務有多個執行個體,以下吞吐相關指標是執行個體的總和,延遲相關指標是執行個體的均值。
指標 | 說明 |
Requests Num | 服務在該時間點的所有請求數。
|
Token Throughput | 服務在該時間點所有請求的輸入與產生的Token數。
|
Time To First Token | 服務在該時間點所有請求的首Token延時。首Token延時表示從接收到請求到產生第一個Token的時間。
|
Time Per Output Token | 服務在該時間點所有請求的每Token延時。每Token延時表示從產生第一個Token後,後續的每個輸出Token所需的平均時間。
|
E2E Request Latency | 服務在該時間點所有請求的端到端延時。端到端延時表示從接收到請求到返回所有Token的時間。
|
Cache Hit Rate | 服務在該時間點所有請求的 Prefix緩衝平均命中率。 |
Used Tokens Num | 服務在該時間點使用的KV緩衝Token數。如果服務包含多個執行個體,則此處的指標為所有執行個體的平均值。 |
Token Usage | 服務在該時間點的KV緩衝Token平均使用率。如果服務包含多個執行個體,則此處的指標為所有執行個體的平均值。 |
常見問題
Q:監控頁面缺少 LLM 監控儀錶盤
問題概述:使用者通過 EAS 自訂部署方式部署模型後,監控頁面僅顯示通用的 Service 和 GPU 監控,缺失 LLM 監控。
根本原因:服務配置缺少關鍵標籤 ServiceEngineType,該標籤用於顯式聲明後端推理引擎類型。
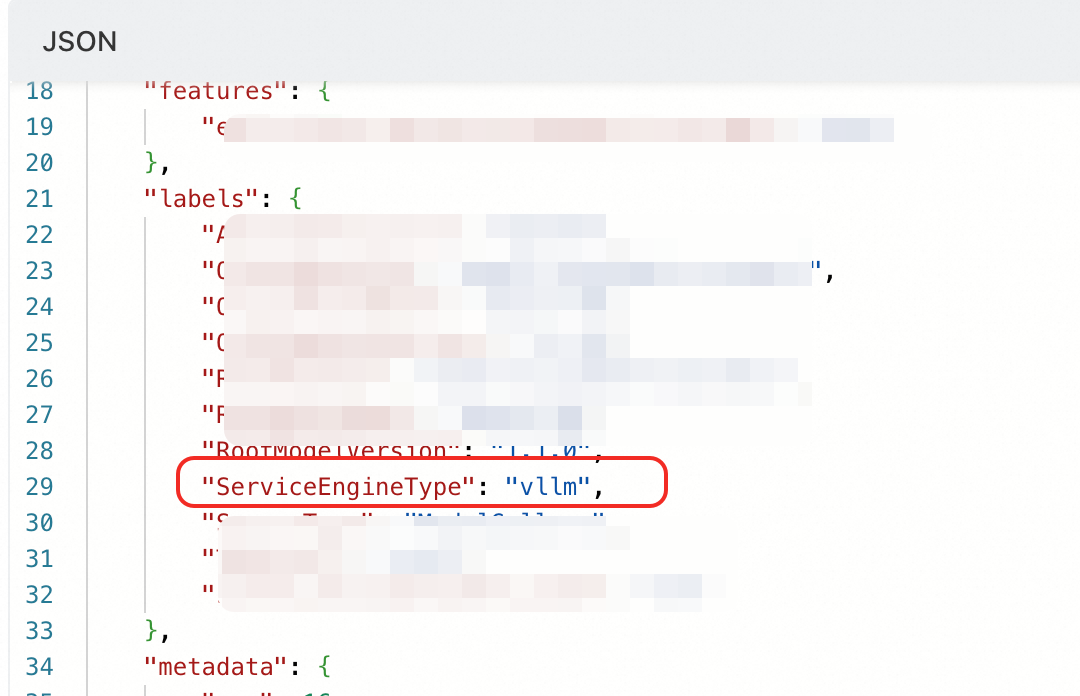
除 ServiceEngineType標籤外,Model Gallery 部署所帶的其他參數均不影響 LLM 監控。
解決方案:更新服務配置,添加ServiceEngineType的標籤,並根據所採用的推理部署引擎設定其值(僅支援 vllm或sglang)。
Q: 日誌裡頻繁出現/metrics 200的原因是什嗎?
當ServiceEngineType標籤正確配置生效後,EAS後端會定期調用推理部署架構的/metrics介面(約10-15秒一次,包含採集間隔及輪詢所有pod的時間)。該介面以Prometheus格式提供即時架構指標,前端據此渲染LLM監控資料。
相關文檔
開通服務監控警示後可在服務觸發警示規則時收到警示通知。
通過CloudMonitor的控制台或API介面查看EASCloudMonitor事件,對事件進行營運、審計或警示設定。
根據商務邏輯設定自訂監控指標進行Auto Scaling,詳情請參見自訂監控及擴縮容指標。