PAI-DLC可以協助您快捷地建立單機或分布式訓練任務,其底層使用Kubernetes拉起計算節點。這避免了您手動購買機器並配置運行環境,同時無需改變使用習慣。適用於需要快速啟動訓練任務的使用者,支援多種深度學習架構,並提供靈活的資源配置選項。
前提條件
使用主帳號開通PAI並建立工作空間。登入PAI控制台,在頁面上方開通地區,然後一鍵授權和開通產品,詳情見開通PAI並建立工作空間。
操作帳號授權。當使用主帳號操作時,可跳過此步。當使用RAM帳號時,需要具有演算法開發、演算法營運、空間管理員中任意一個角色,操作帳號授權請參見管理工作空間 > 成員角色配置。
通過控制台建立任務
初次使用DLC的使用者,推薦您使用控制台的方式建立任務,除此之外,DLC還提供了通過SDK或命令列建立任務的方式。
進入建立任務頁面。
登入PAI控制台,在頁面上方選擇目標地區,並選擇目標工作空間,然後單擊進入DLC。
在分布式訓練(DLC)頁面,單擊建立任務。
分別在以下幾個地區,配置訓練任務相關參數。
基本資料
配置任務名稱和標籤。
環境資訊
參數
描述
镜像配置
除了可以選擇官方鏡像外,還支援以下鏡像類型:
自訂鏡像:可使用添加到PAI的自訂鏡像,鏡像倉庫需要設定為公開拉取狀態,或將鏡像儲存在Container RegistryACR中,詳情請參見自訂鏡像。
說明當資源配額選擇靈駿智算資源並使用自訂鏡像時,為充分利用靈駿的高效能RDMA網路,需手動安裝RDMA,詳情請參見RDMA:使用高效能網路進行分布式訓練。
鏡像地址:支援配置公網環境下可訪問的自訂鏡像或官方鏡像地址。
如果是私人鏡像地址,需要單擊輸入帳號密碼,並配置鏡像倉庫使用者名稱和密碼
提升鏡像拉取速度,可參見鏡像加速。
資料集掛載
資料集用於提供模型訓練時所需的資料檔案,支援以下兩種資料集類型:
自訂資料集:您可以建立自訂資料集來存放訓練所需的資料檔案,支援設定是否唯讀,支援在版本列表中選擇資料集版本。
公用資料集:PAI預置有公開的資料集,只支援唯讀掛載模式。
掛載路徑:表示資料集掛載到DLC容器的路徑,例如
/mnt/data,在代碼中您可以檢索該路徑擷取資料集。更多掛載配置資訊請參見在DLC訓練任務中使用雲端儲存。重要如果配置了CPFS類型的資料集,則DLC需要配置Virtual Private Cloud,且與CPFS的VPC一致。否則,提交的任務可能長時間處於環境準備中狀態。
儲存掛載
您也可以通過直接掛載資料來源路徑來讀取需要的資料,或存放過程及結果檔案。
支援資料來源類型:OSS、通用型NAS、極速型NAS、BMCPFS(僅靈駿智算資源可用)。
進階配置:不同資料來源類型可通過進階配置實現特性功能,如:
OSS:在進階配置中設定
{"mountType":"ossfs"},以使用ossfs方式掛載OSS儲存。通用型NAS和CPFS:在進階配置中設定nconnect參數,以提升DLC容器訪問NAS的吞吐效能,詳情請參見如何解決Linux作業系統上訪問NAS效能不好?。例如
{"nconnect":"<樣本值>"},請將<樣本值>替換為具體的正整數。
更多內容請參見在DLC訓練任務中使用雲端儲存。
啟動命令
設定任務啟動命令,支援Shell命令,並且DLC會自動注入Pytorch和Tensorflow通用環境變數,如
MASTER_ADDR、WORLD_SIZE,可以通過$環境變數名來擷取,啟動命令樣本如下:運行Python:
python -c "print('Hello World')"torch多機多卡分布式訓練:
python -m torch.distributed.launch \ --nproc_per_node=2 \ --master_addr=${MASTER_ADDR} \ --master_port=${MASTER_PORT} \ --nnodes=${WORLD_SIZE} \ --node_rank=${RANK} \ train.py --epochs=100設定shell檔案路徑作為啟動命令:
/ml/input/config/launch.sh
環境變數
除自動注入的Pytorch和Tensorflow通用環境變數外,您可以提供自訂的環境變數,格式為
Key:Value,最多支援配置20個環境變數。三方庫配置
如果配置的容器鏡像中缺少部分三方庫,您可以通過三方庫配置添加,支援以下兩種方式:
三方庫列表:直接在下方文字框中輸入三方庫名稱。
requirements.txt檔案目錄:將第三方庫寫入requirements.txt檔案中,然後通過代碼配置、資料集或直接掛載方式將該檔案上傳到DLC容器中,並在文字框中指定該檔案在容器中的路徑。
代碼配置
將訓練所需代碼檔案上傳到DLC容器中。支援以下兩種配置方式:
線上配置:如果您已有Git代碼倉庫,並且有存取權限,則可以通過建立代碼集的方式關聯此倉庫,使DLC擷取到任務代碼。
本地上傳:單擊
 按鈕上傳本地代碼檔案,上傳成功後,將掛載路徑配置為容器內部的指定路徑,例如
按鈕上傳本地代碼檔案,上傳成功後,將掛載路徑配置為容器內部的指定路徑,例如/mnt/data。
資源資訊
參數
描述
資源類型
預設為通用計算,僅華北6(烏蘭察布)、新加坡、華南1(深圳)、華北2(北京)、華東2(上海)和華東1(杭州)地區支援選擇靈駿智算。
資源來源
公用資源:
計費模式:隨用隨付。
適用情境:公用資源可能會遇到排隊延時,因此,建議在任務量相對較少,任務時效性要求不高的情境下使用。
使用限制:支援啟動並執行資源上限為GPU 2卡、CPU 8核,如果需要超出此上限,請聯絡您的商務經理來提升資源限制。
資源配額:包括通用計算資源或靈駿智算資源
計費模式:訂用帳戶。
適用情境:適用在任務量相對較多,且需要高保障的執行任務的情境。
特殊參數:
資源配額:可設定GPU、CPU等資源數量,如何準備資源配額,請參見新增資源配額。
優先順序:表示同時啟動並執行任務執行的優先順序,取值範圍為[1,9],其中1表示優先順序最低。
競價資源:
計費模式:隨用隨付。
適用情境:如果您希望降低資源成本,可使用競價資源,其通常在價格上有一定幅度的折扣。
使用限制:不承諾穩定可用,有可能出現無法立即搶佔或被回收的情況,更多資訊請參見使用競價任務。
架構
支援以下深度學習訓練架構和訓練工具:TensorFlow、PyTorch、ElasticBatch、XGBoost、OneFlow、MPIJob和Ray。
說明當資源配額選擇靈駿智算資源時,僅支援提交TensorFlow、PyTorch、ElasticBatch、MPIJob和Ray類型的任務。
任務資源
根據您選擇的架構,支援配置Worker、PS、Chief、Evaluator和GraphLearn類型節點的資源。當選擇Ray架構時,您可以通過單擊新增Role自訂Worker角色,從而實現異構資源的混合運行。
使用公用資源:支援配置以下參數:
節點數量:運行DLC任務的節點數量。
資源規格:可選擇資源規格,控制台介面將顯示相應價格,更多計費資訊,請參見DLC計費說明。
使用資源配額:可配置各類型節點的節點數量、CPU(核心數)、GPU(卡數)、記憶體(GiB)和共用記憶體(GiB),還可配置如下特殊參數:
指定節點調度:您可以在指定計算節點上執行任務。
閑時資源:使用閑時資源時,任務可運行在其他Quota下的空閑資源上,有效提升資源使用率,但當此資源需要被原Quota任務使用時,閑時計算任務將會被終止,自動歸還資源,更多內容請參見:使用閑時資源。
CPU親和性:啟用CPU親和性,能夠將容器或Pod中的進程綁定到特定的CPU核心上執行。通過這種方式,可以減少CPU緩衝未命中、環境切換等現象,從而提高CPU使用率,提升應用效能,適用於對效能敏感和即時性要求高的情境。
使用競價資源:除了節點數量和資源規格外,還可配置出價參數,其通過設定最高出價來申請使用競價資源。您可以單擊
 按鈕,選擇出價方式:
按鈕,選擇出價方式:按折扣:最高價是基於資源規格的市場價格,從1折到9折的離散選項,表示參與競價的上限。當競價資源的最高出價≥市場價格且庫存充足時,可申請到競價資源。
按價格:最高價的出價範圍為市場價格區間。
專用網路配置
不配置專用網路,將使用公用網路和公有網關。由於公有網關的頻寬有限,可能導致任務執行過程中出現卡頓或無法正常進行的情況。
配置專用網路,並選擇對應的交換器與安全性群組後,可提升網路的頻寬、穩定性和安全性,並且,任務啟動並執行叢集可以直接存取此專用網路內的服務。
重要使用VPC時,需保障任務資源群組執行個體、資料集儲存(OSS)在同一地區的VPC網路環境中,且與代碼倉庫的網路是連通狀態。
使用CPFS類型的資料集時,需要配置專用網路,且選擇的專用網路需要與CPFS一致。否則,提交的DLC訓練任務可能長時間處於環境準備中狀態。
當使用靈駿智算競價資源提交DLC任務時,需要配置專用網路。
此外,還可以配置公網訪問網關,支援以下兩種方式:
公有網關:其網路頻寬受限,在使用者高並發或下載大型檔案時,網路速度可能無法滿足需求。
專有網關:為解決公有網關頻寬節流設定問題,可以在DLC的專用網路中建立公網NAT Gateway、綁定EIP並配置SNAT條目,詳情請參考通過專有網關提升公網訪問速率。
容錯與診斷
參數
描述
自動容錯
開啟自動容錯開關並配置相應參數後,系統將提供作業檢測和控制能力,能夠及時檢測任務演算法層面的報錯並規避,從而提升GPU的利用率。詳情請參見AIMaster:彈性自動容錯引擎。
說明啟用自動容錯功能後,系統將啟動一個AIMaster執行個體與任務執行個體一起運行,這會佔用一定的計算資源。關於AIMaster執行個體資源使用詳情如下:
資源配額:1個CPU核和1 GiB記憶體。
公用資源:使用ecs.c6.large規格。
健康檢測
開啟健康檢測開關,健康檢測會對參與訓練的資源進行全面檢測,自動隔離故障節點,並觸發後台自動化營運流程,有效減少任務訓練初期遇到問題的可能性,提升訓練成功率。詳情請參見SanityCheck:算力健康檢測。
說明僅基於靈駿智算資源配額提交的Pytorch類型的訓練任務且GPU(卡數)大於0時,支援開啟健康檢測功能。
角色與許可權
執行個體RAM角色配置說明如下。關於該功能更詳細的內容介紹,請參見配置DLC RAM角色。
執行個體RAM角色
描述
PAI預設角色
基於服務角色AliyunPAIDLCDefaultRole運作,它僅擁有訪問ODPS、OSS的許可權,且許可權更加精細。基於PAI預設角色簽發的臨時訪問憑證:
在訪問MaxCompute表時,將擁有等同於DLC執行個體所有者的許可權。
在訪問OSS時,僅能訪問當前工作空間配置的預設OSS儲存空間(Bucket)。
自訂角色
選擇或填寫一個自訂的RAM角色。在執行個體內基於STS臨時憑證訪問雲產品時,擁有的許可權將與該自訂角色的許可權保持一致。
不關聯角色
不為DLC任務關聯RAM角色,預設選擇該方式。
參數配置完成後,單擊確定。
相關文檔
提交訓練任務後,您可以執行以下操作:
查看任務基本資料、資源檢視和動作記錄。詳情請參見查看訓練詳情。
管理工作,包括複製、停止和刪除任務等。詳情請參見管理訓練任務。
通過TensorBoard查看結果分析報告。詳情請參見視覺化檢視Tensorboard。
設定任務的監控與警示。詳情請參見訓練監控與警示。
查看任務啟動並執行賬單明細。詳情請參見賬單明細。
將當前工作空間中的DLC任務日誌轉寄至指定的SLS日誌庫,實現自訂分析。詳情請參見訂閱任務日誌。
在PAI工作空間的事件中心中建立訊息通知規則,以便跟蹤和監控DLC任務的狀態。詳情請參見訊息通知。
有關在執行DLC任務過程中可能出現的問題及其解決方案,請參考DLC常見問題。
關於DLC的使用案例,請參見DLC使用案例匯總。
附錄
通過SDK或命令列建立任務
Python SDK
步驟一:安裝阿里雲的Credentials工具
當您通過阿里雲SDK調用OpenAPI進行資源操作時,必須安裝Credentials工具配置憑證資訊。要求:
Python版本 >= 3.7。
使用V2.0代系的阿里雲SDK。
pip install alibabacloud_credentials步驟二:擷取帳號AccessKey
本樣本使用AK資訊配置訪問憑證,為防止帳號資訊洩漏,建議您將AccessKey配置為環境變數,id和secret環境變數名分別為ALIBABA_CLOUD_ACCESS_KEY_ID,ALIBABA_CLOUD_ACCESS_KEY_SECRET。
擷取AccessKey資訊,請參見建立AccessKey。
如何設定環境變數,請參見配置環境變數。
其它Credentials憑證配置方式,請參見安裝Credentials工具。
步驟三:安裝Python SDK
安裝工作空間SDK。
pip install alibabacloud_aiworkspace20210204==3.0.1安裝DLC SDK。
pip install alibabacloud_pai_dlc20201203==1.4.17
步驟四:提交任務
使用公用資源提交任務
建立並提交任務的具體調用代碼如下所示。
使用預付費資源配額提交任務
登入PAI控制台。
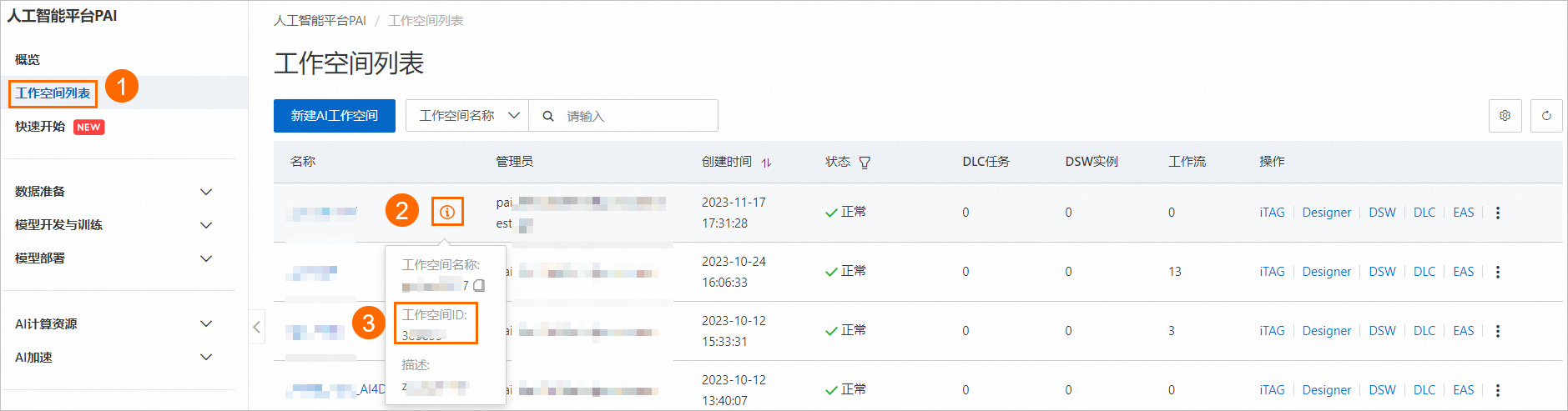
按照下圖操作指引,在工作空間列表頁面查看您所在的工作空間ID。

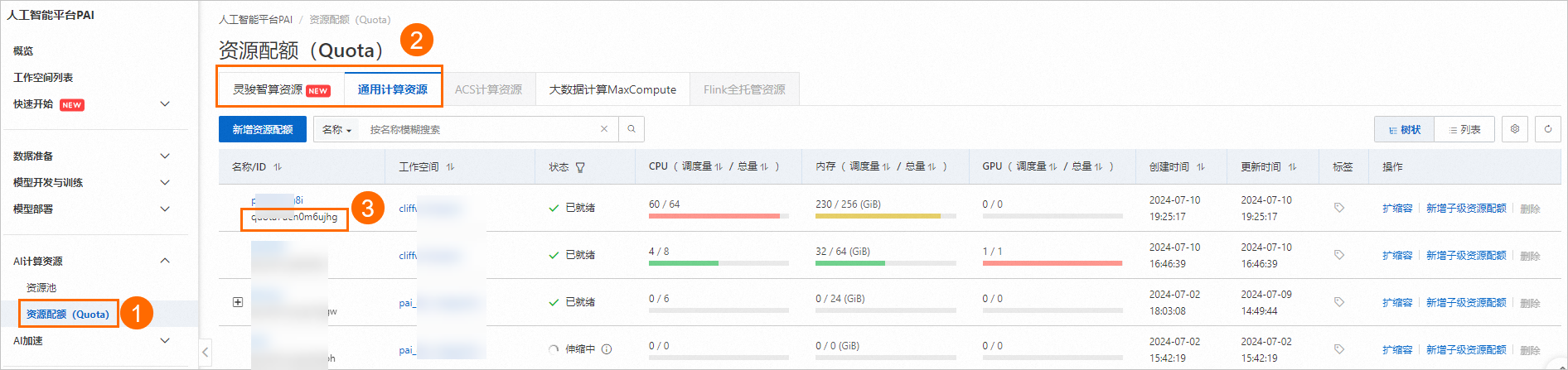
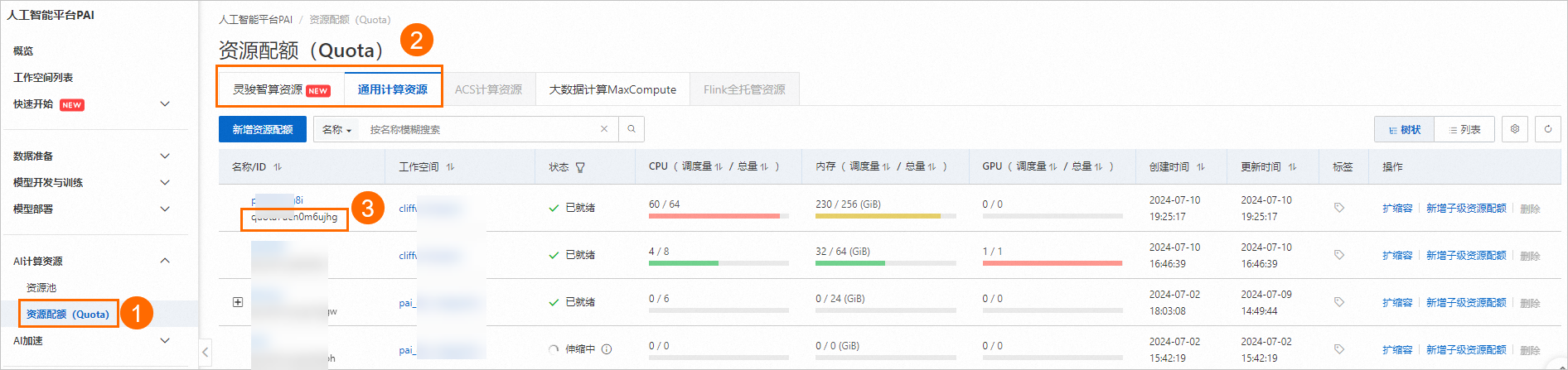
按照下圖操作指引,查看您的專有資源群組的資源配額ID。
使用以下代碼建立並提交任務。可使用的公用鏡像列表,詳情請參見步驟二:準備鏡像。
from alibabacloud_pai_dlc20201203.client import Client from alibabacloud_credentials.client import Client as CredClient from alibabacloud_tea_openapi.models import Config from alibabacloud_pai_dlc20201203.models import ( CreateJobRequest, JobSpec, ResourceConfig, GetJobRequest ) # 初始化一個Client,用來訪問DLC的API。 region = 'cn-hangzhou' # 阿里雲帳號AccessKey擁有所有API的存取權限,建議您使用RAM使用者進行API訪問或日常營運。 # 強烈建議不要把AccessKey ID和AccessKey Secret儲存到工程代碼裡,否則可能導致AccessKey泄露,威脅您帳號下所有資源的安全。 # 本樣本通過Credentials SDK預設從環境變數中讀取AccessKey,來實現身分識別驗證為例。 cred = CredClient() client = Client( config=Config( credential=cred, region_id=region, endpoint=f'pai-dlc.{region}.aliyuncs.com', ) ) # 聲明任務的資源配置,關於鏡像選擇可以參考文檔中公用鏡像列表,也可以傳入自己的鏡像地址。 spec = JobSpec( type='Worker', image=f'registry-vpc.cn-hangzhou.aliyuncs.com/pai-dlc/tensorflow-training:1.15-cpu-py36-ubuntu18.04', pod_count=1, resource_config=ResourceConfig(cpu='1', memory='2Gi') ) # 聲明任務的執行內容。 req = CreateJobRequest( resource_id='<替換成您自己的資源配額ID>', workspace_id='<替換成您自己的WorkspaceID>', display_name='sample-dlc-job', job_type='TFJob', job_specs=[spec], user_command='echo "Hello World"', ) # 提交任務。 response = client.create_job(req) # 擷取任務ID。 job_id = response.body.job_id # 查詢任務狀態。 job = client.get_job(job_id, GetJobRequest()).body print('job status:', job.status) # 查看任務執行的命令。 job.user_command
使用競價資源提交任務
SpotDiscountLimit(Spot折扣)
#!/usr/bin/env python3 from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_pai_dlc20201203.client import Client as DLCClient from alibabacloud_pai_dlc20201203.models import CreateJobRequest region_id = '<region-id>' # DLC任務所在地區ID,例如華東1(杭州)為cn-hangzhou。 cred = CredClient() workspace_id = '12****' # DLC任務所在工作空間ID。 dlc_client = DLCClient( Config(credential=cred, region_id=region_id, endpoint='pai-dlc.{}.aliyuncs.com'.format(region_id), protocol='http')) create_job_resp = dlc_client.create_job(CreateJobRequest().from_map({ 'WorkspaceId': workspace_id, 'DisplayName': 'sample-spot-job', 'JobType': 'PyTorchJob', 'JobSpecs': [ { "Type": "Worker", "Image": "dsw-registry-vpc.<region-id>.cr.aliyuncs.com/pai/pytorch-training:1.12-cpu-py39-ubuntu20.04", "PodCount": 1, "EcsSpec": 'ecs.g7.xlarge', "SpotSpec": { "SpotStrategy": "SpotWithPriceLimit", "SpotDiscountLimit": 0.4, } }, ], 'UserVpc': { "VpcId": "vpc-0jlq8l7qech3m2ta2****", "SwitchId": "vsw-0jlc46eg4k3pivwpz8****", "SecurityGroupId": "sg-0jl4bd9wwh5auei9****", }, "UserCommand": "echo 'Hello World' && ls -R /mnt/data/ && sleep 30 && echo 'DONE'", })) job_id = create_job_resp.body.job_id print(f'jobId is {job_id}')SpotPriceLimit(Spot價格)
#!/usr/bin/env python3 from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_pai_dlc20201203.client import Client as DLCClient from alibabacloud_pai_dlc20201203.models import CreateJobRequest region_id = '<region-id>' cred = CredClient() workspace_id = '12****' dlc_client = DLCClient( Config(credential=cred, region_id=region_id, endpoint='pai-dlc.{}.aliyuncs.com'.format(region_id), protocol='http')) create_job_resp = dlc_client.create_job(CreateJobRequest().from_map({ 'WorkspaceId': workspace_id, 'DisplayName': 'sample-spot-job', 'JobType': 'PyTorchJob', 'JobSpecs': [ { "Type": "Worker", "Image": "dsw-registry-vpc.<region-id>.cr.aliyuncs.com/pai/pytorch-training:1.12-cpu-py39-ubuntu20.04", "PodCount": 1, "EcsSpec": 'ecs.g7.xlarge', "SpotSpec": { "SpotStrategy": "SpotWithPriceLimit", "SpotPriceLimit": 0.011, } }, ], 'UserVpc': { "VpcId": "vpc-0jlq8l7qech3m2ta2****", "SwitchId": "vsw-0jlc46eg4k3pivwpz8****", "SecurityGroupId": "sg-0jl4bd9wwh5auei9****", }, "UserCommand": "echo 'Hello World' && ls -R /mnt/data/ && sleep 30 && echo 'DONE'", })) job_id = create_job_resp.body.job_id print(f'jobId is {job_id}')
其中關鍵配置說明如下:
參數 | 描述 |
SpotStrategy | 競價策略。僅該參數設定為SpotWithPriceLimit時,出價類型才會生效。 |
SpotDiscountLimit | 出價類型為Spot折扣。 說明
|
SpotPriceLimit | 出價類型為Spot價格。 |
UserVpc | 使用靈駿競價資源提交任務時,該參數必填。配置任務所在地區的專用網路、交換器和安全性群組ID。 |
命令列
步驟一:下載用戶端並執行使用者認證
根據您使用的作業系統下載Linux 64或Mac版本的用戶端工具並完成使用者認證,詳情請參見準備工作。
步驟二:提交任務
登入PAI控制台。
按照下圖操作指引,在工作空間列表頁面查看您所在的工作空間ID(WorkspaceID)。
按照下圖操作指引,查看您的資源配額ID。
參考以下檔案內容準備參數檔案
tfjob.params。更多關於參數檔案的配置方法,請參見提交命令。name=test_cli_tfjob_001 workers=1 worker_cpu=4 worker_gpu=0 worker_memory=4Gi worker_shared_memory=4Gi worker_image=registry-vpc.cn-beijing.aliyuncs.com/pai-dlc/tensorflow-training:1.12.2PAI-cpu-py27-ubuntu16.04 command=echo good && sleep 120 resource_id=<替換成您的資源配額ID> workspace_id=<替換成您的WorkspaceID>使用以下程式碼範例傳入params_file參數提交任務,可以將DLC任務提交到指定的工作空間和資源配額。
./dlc submit tfjob --job_file ./tfjob.params使用以下代碼查看您提交的DLC任務。
./dlc get job <jobID>
進階參數列表
參數(key) | 支援的架構類型 | 參數說明 | 參數取值(value) |
| ALL | 配置自訂資源釋放規則。可不配置,不配置時資源以Job結束整體釋放所有Pod的資源。若配置,當前只支援設定為pod-exit,即在您的Pod退出時釋放該Pod的資源。 | pod-exit |
| ALL | 載入GPU驅動時是否開啟IBGDA功能。 |
|
| ALL | 是否安裝GDRCopy核心模組,當前安裝的2.4.4版本。 |
|
| ALL | 是否開啟numa。 |
|
| ALL | 支援提交作業時檢測quota中總資源(節點規格)是否能夠滿足作業的所有role的規格。 |
|
| PyTorch | 是否允許worker間網路互連。
開啟後,每個worker的網域名稱即為worker名,如 |
|
| PyTorch | 允許使用者定義每個worker上開放的網路連接埠,可與 若未配置,則預設僅有master上開放23456號連接埠。因此也請注意在該自訂連接埠列表中避開23456號連接埠。 重要 該參數與 | 分號分隔的一組字串,其中每個字串為一個連接埠號碼,或由虛線串連的一個連接埠範圍,如 |
| PyTorch | 允許使用者請求為每個worker開放若干個網路連接埠,可與 若未配置,則預設僅在master上開放23456號連接埠。DLC會根據參數定義的連接埠數目,為worker隨機分配連接埠,具體分配的連接埠號碼會通過環境變數 重要
| 整數(最大為65536) |
| Ray | 當架構為Ray時,支援通過手動設定RayRuntimeEnv來定義運行環境。 重要 環境變數和三方庫配置將被此配置覆蓋。 | 配置環境變數和三方庫( |
| Ray | 外部 GCS Redis 地址。 | 字串 |
| Ray | 外部 GCS Redis 使用者名稱。 | 字串 |
| Ray | 外部 GCS Redis 密碼。 | 字串 |
| Ray | Submitter 重試次數。 | 正整數(int) |
| Ray | 為節點配置共用記憶體。例如,為每個節點配置1 GiB共用記憶體,配置樣本如下: | 正整數(int) |