Realtime ComputeFlink版提供了豐富強大的資料即時入倉能力。通過Flink的全增量自動切換、元資訊自動探索、表結構變更自動同步和整庫同步等功能,簡化了資料即時入倉的鏈路,使得即時資料同步更加高效便捷。本文介紹如何快速構建一個從MySQL到Hologres的資料攝入作業。
背景資訊
假設MySQL執行個體中有一個tpc_ds庫,裡面有24張表結構不相同的業務表。另外還有user_db1~user_db3三個庫,由於進行了分庫分表的設計,每個庫中分別有3張表結構相同的表,共包含名稱為user01~user09的9張表。在阿里雲DMS控制台觀察到MySQL中的庫和表情況如下圖所示。
此時,如果您希望開發一個資料攝入的作業,將這些表和資料都同步到Hologres中,其中user分庫分表能合并到Hologres的一張表中,則可以按照以下步驟進行:
本文使用Flink CDC資料攝入作業開發(公測中)來完成整庫同步、分庫分表合并同步,一鍵完成資料的全量和增量同步處理,以及即時的表結構變更同步。
前提條件
如果您使用RAM使用者或RAM角色等身份訪問,需要確認已具有Flink控制台相關許可權,詳情請參見許可權管理。
已建立Flink工作空間,詳情請參見開通Realtime ComputeFlink版。
上下遊儲存
已建立RDS MySQL執行個體,詳情請參見(廢棄,重新導向到“第一步”)快速建立RDS MySQL執行個體。
已建立Hologres執行個體,詳情請參見購買Hologres執行個體。
說明RDS MySQL和Hologres需要與Flink工作空間在相同地區相同VPC下,否則需要打通網路,詳情請參見如何訪問跨VPC的其他服務?和如何訪問公網?。
已準備好測試資料,並配置好白名單。詳情請參見準備MySQL測試資料和Hologres資料庫和配置IP白名單。
準備MySQL測試資料和Hologres資料庫
單擊tpc_ds.sql、user_db1.sql、user_db2.sql和user_db3.sql下載測試資料到本地。
在Data Management控制台上,準備RDS MySQL的測試資料。
通過DMS登入RDS MySQL。
在已登入的SQLConsole視窗,輸入如下命令後單擊執行。
建立tpc_ds、user_db1、user_db2和user_db3四個資料庫。
CREATE DATABASE tpc_ds; CREATE DATABASE user_db1; CREATE DATABASE user_db2; CREATE DATABASE user_db3;在頂部捷徑功能表欄,單擊資料匯入。
在批量資料匯入頁簽下選擇需要匯入的資料庫,上傳對應的SQL檔案,單擊提交申請後,單擊執行變更。在彈出的對話方塊中單擊確定執行。
同樣的操作依次為tpc_ds、user_db1、user_db2和user_db3資料庫匯入對應的資料檔案。

在Hologres控制台建立my_user資料庫,用於存放合并後的user表資料。
操作步驟詳情請參見建立資料庫。
配置IP白名單
為了讓Flink能訪問MySQL和Hologres執行個體,您需要將Flink工作空間的網段添加到MySQL和Hologres的白名單中。


步驟一:開發資料同步作業
登入Flink開發控制台,新增作業。
在頁面,單擊建立。
單擊空白的資料攝入草稿。
Flink為您提供了豐富的代碼模板,每種代碼模板都為您提供了具體的使用情境、程式碼範例和使用指導。您可以直接單擊對應的模板快速地瞭解Flink產品功能和相關文法,實現您的商務邏輯。
單擊下一步。
在建立資料攝入作業草稿對話方塊,填寫作業配置資訊。
作業參數
說明
樣本
檔案名稱
作業的名稱。
說明作業名稱在當前專案中必須保持唯一。
flink-test
儲存位置
指定該作業的代碼檔案所屬的檔案夾。
您還可以在現有檔案夾右側,單擊
 表徵圖,建立子檔案夾。
表徵圖,建立子檔案夾。作業草稿
引擎版本
當前作業使用的Flink的引擎版本。引擎版本號碼含義、版本對應關係和生命週期重要時間點詳情請參見引擎版本介紹。
vvr-11.1-jdk11-flink-1.20
單擊確定。
將以下作業代碼拷貝到作業文本編輯區。
將tpc_ds庫中所有表同步至Hologres,並將user的分庫分表合并同步到Hologres的單表中。程式碼範例如下所示。
source: type: mysql name: MySQL Source hostname: localhost port: 3306 username: username password: password tables: tpc_ds.\.*,user_db[0-9]+.user[0-9]+ server-id: 8601-8604 #(可選)同步表注釋和欄位注釋 include-comments.enabled: true #(可選)優先分發無界的分區以避免可能出現的TaskManager OutOfMemory問題 scan.incremental.snapshot.unbounded-chunk-first.enabled: true #(可選)開啟解析過濾,加速讀取 scan.only.deserialize.captured.tables.changelog.enabled: true sink: type: hologres name: Hologres Sink endpoint: ****.hologres.aliyuncs.com:80 dbname: cdcyaml_test username: ${secret_values.holo-username} password: ${secret_values.holo-password} sink.type-normalize-strategy: BROADEN route: # 將user的分庫分表合并同步到my_user.users表中 - source-table: user_db[0-9]+.user[0-9]+ sink-table: my_user.users說明MySQL tpc_ds庫中的所有表直接映射到下遊的同名庫表中,因此不需要在route模組中額外配置映射關係。如果您希望同步到其他名稱的資料庫,例如ods_tps_ds庫,可以配置route模組為:
route: # 將user的分庫分表合并同步到my_user.users表中 - source-table: user_db[0-9]+.user[0-9]+ sink-table: my_user.users # 統一修改表名,將tpc_ds庫下所有表同步到ods_tps_ds庫中 - source-table: tpc_ds.\.* sink-table: ods_tps_ds.<> replace-symbol: <>
步驟二:啟動作業
在頁面,單擊部署後,在彈出的對話方塊中,單擊確認。

在頁面,單擊目標作業操作中的啟動。填寫配置資訊,詳情請參見作業啟動。
單擊啟動。
作業啟動後,您可以在作業營運頁面觀察作業的運行資訊和狀態。

步驟三:觀察全量同步結果
在中繼資料管理頁簽,查看Hologres執行個體下的tpc_ds資料庫中24張表和表資料。

在中繼資料管理頁簽,查看my_user庫下users表結構。
同步後的表結構和資料如下圖所示。
表結構

users表的表結構比MySQL源表中多了_db_name和_table_name兩列,代表資料來源的庫名和表名,且作為聯合主鍵的一部分來保證分庫分表合并後的資料唯一性。
表資料
在users表資訊頁面右上方,單擊查詢表後,輸入如下命令,單擊運行。
select * from users order by _db_name,_table_name,id;表資料結果如下圖所示。

步驟四:觀察增量同步處理結果
同步作業會在全量資料同步完以後自動切換到增量資料同步階段,無需幹預。您可以通過監控警示頁簽的currentEmitEventTimeLag值來確定資料同步的階段。
單擊對應工作空間操作列下的控制台。
在頁面,單擊目標作業名稱。
單擊監控警示(或資料曲線)頁簽。
觀察currentEmitEventTimeLag曲線圖,確定資料同步階段。

值為0時,代表還在全量同步階段。
值大於0時,代表已經進入增量同步處理階段。
驗證即時同步資料變更和結構變更的能力。
MySQL CDC資料來源支援在增量同步處理階段,即時同步表的資料變更以及表的結構變更。您可以在作業進入到增量同步處理階段後,通過修改MySQL的user分表的表結構和資料,來驗證即時同步資料變更和結構變更的能力。
通過DMS登入RDS MySQL。
在user_db2資料庫下,執行如下命令修改user02表的表結構,並插入和更新資料。
USE DATABASE `user_db2`; ALTER TABLE `user02` ADD COLUMN `age` INT; -- 添加age列。 INSERT INTO `user02` (id, name, age) VALUES (27, 'Tony', 30); -- 插入帶有age的資料。 UPDATE `user05` SET name='JARK' WHERE id=15; -- 更新另一張表,名字改成大寫。在Hologres控制台,查看users表結構和資料的變化。
在users表資訊頁面右上方,單擊查詢表後,輸入如下命令,單擊運行。
select * from users order by _db_name,_table_name,id;表資料結果如下圖所示。
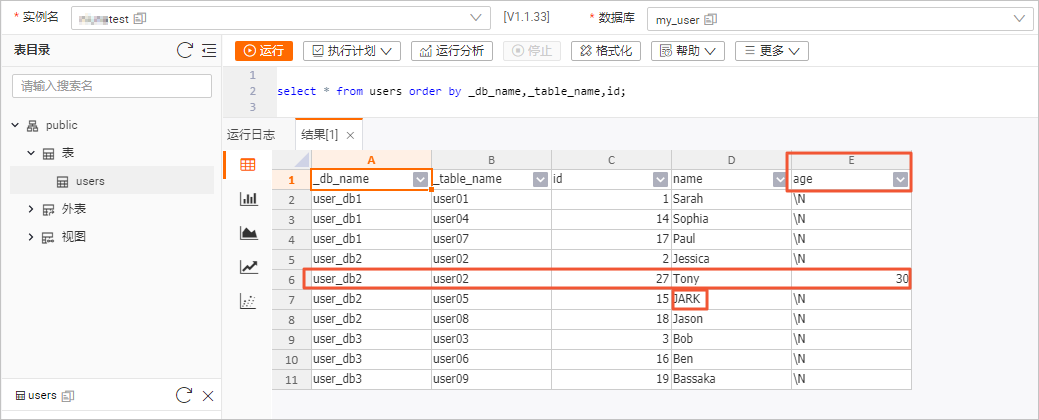 雖然多張分表的Schema並不一致,但是在user02上的表結構變更,以及資料變更都能即時地同步到下遊表中。在Hologres的users表中,看到了新增的age欄位,插入的Tony資料以及更新成大寫的JARK資料。
雖然多張分表的Schema並不一致,但是在user02上的表結構變更,以及資料變更都能即時地同步到下遊表中。在Hologres的users表中,看到了新增的age欄位,插入的Tony資料以及更新成大寫的JARK資料。
(可選)步驟五:作業資源配置
根據資料量的不同,我們往往需要調節並發和TaskManager的資源,以達到更優的作業效能。您可以使用資源配置調節作業並發度和記憶體/CU數。
在頁面,單擊目標作業名稱。
在部署詳情頁簽下,單擊資源配置地區右上方的編輯。
手動設定Task Manager Memory與並發度等資源參數。
在資源配置右側,單擊儲存。
重啟作業。
作業資源配置後,需重啟作業才會生效。
相關文檔
資料攝入各個模組文法介紹,請參見Flink CDC資料攝入作業開發參考。
資料攝入作業運行過程中出現異常,請參見資料攝入作業常見問題和解決方案。