本文為您介紹Realtime ComputeFlink版連接器方面的常見問題。
Kafka
DataHub
MaxCompute
MySQL
RDS MySQL
ClickHouse
Print
Tablestore
訊息佇列RocketMQ
Hologres
Log ServiceSLS
流式資料湖倉Paimon
Hudi
AnalyticDB MySQL版(ADB)3.0
自訂連接器
Flink如何擷取Kafka中的JSON資料?
如果您需要擷取普通JSON資料,方法詳情請參見JSON Format。
如果您需要擷取嵌套的JSON資料,則源表DDL中使用ROW格式定義JSON Object,結果表DDL中定義好要擷取的JSON資料對應的Key,在DML語句中設定好Key擷取的方式,就可以擷取到對應的嵌套Key的Value。程式碼範例如下:
測試資料
{ "a":"abc", "b":1, "c":{ "e":["1","2","3","4"], "f":{"m":"567"} } }源表DDL定義
CREATE TEMPORARY TABLE `kafka_table` ( `a` VARCHAR, b int, `c` ROW<e ARRAY<VARCHAR>,f ROW<m VARCHAR>> --c是一個JSON Object,對應Flink裡面是ROW;e是json list,對應ARRAY。 ) WITH ( 'connector' = 'kafka', 'topic' = 'xxx', 'properties.bootstrap.servers' = 'xxx', 'properties.group.id' = 'xxx', 'format' = 'json', 'scan.startup.mode' = 'xxx' );結果表DDL定義
CREATE TEMPORARY TABLE `sink` ( `a` VARCHAR, b INT, e VARCHAR, `m` varchar ) WITH ( 'connector' = 'print', 'logger' = 'true' );DML語句
INSERT INTO `sink` SELECT `a`, b, c.e[1], --Flink從1開始遍曆數組,本樣本為擷取數組中的元素1。如果擷取整個數組,則去掉[1]。 c.f.m FROM `kafka_table`;測試結果

Flink和Kafka網路連通,但Flink無法消費或者寫入資料?
問題原因
如果Flink與Kafka之間存在代理或連接埠映射等轉寄機制,則Kafka用戶端拉取Kafka服務端的網路地址為Kafka伺服器本身的地址而非代理的地址。此時,雖然Flink與Kafka之間網路連通,但是Flink無法消費或者寫入資料。
Flink和Kafka用戶端(Flink Kafka連接器)之間建立串連分為兩個步驟:
Kafka用戶端拉取Kafka服務端(Kafka Broker)元資訊,包括Kafka服務端所有Broker的網路地址。
Flink使用Kafka用戶端拉取下拉的Kafka服務端網路地址來消費或者寫入資料。
排查方法
通過以下步驟來確認Flink與Kafka之間是否存在代理或連接埠映射等轉寄機制:
使用ZooKeeper命令列工具(zkCli.sh或zookeeper-shell.sh)登入您Kafka使用的ZooKeeper叢集。
根據您的叢集實際情況執行正確的命令,來擷取您的Kafka Broker元資訊。
通常可以使用
get /brokers/ids/0命令來擷取Kafka Broker元資訊。Kafka的串連地址位於endpoints欄位中。
使用
ping或telnet等命令來測試Endpoint中顯示的地址與Flink的連通性。如果無法連通,則代表Flink與Kafka之間存在代理或連接埠映射等轉寄機制。
解決方案
不使用代理或連接埠映射等轉寄機制,直接打通Flink與Kafka之間的網路,使Flink能夠直接連通Kafka元資訊中顯示的Endpoint。
聯絡Kafka營運人員,將轉寄地址作為Kafka Broker端的advertised.listeners,以使Kafka用戶端拉取的Kafka服務端元資訊包含轉寄地址。
說明僅Kafka 0.10.2.0及以上版本支援將Proxy 位址添加到Kafka Broker的Listener中。
如果您想瞭解更多的關於該問題的原理和解釋,請參見KIP-103:區分內部與外部網路流量和Kafka網路連接問題詳解。
為什麼Kafka源表資料基於Event Time的視窗後,不能輸出資料?
問題詳情
Kafka作為源表,基於Event Time的視窗後,不能輸出資料。
問題原因
Kafka某個分區沒有資料,會影響Watermark的產生,從而導致Kafka源表資料基於Event Time的視窗後,不能輸出資料。
解決方案
確保所有分區都存在資料。
開啟來源資料空閑監測功能。在其他配置中添加如下代碼後儲存生效,具體操作請參見如何配置自訂的作業運行參數?。
table.exec.source.idle-timeout: 5table.exec.source.idle-timeout參數詳情,請參見Configuration。
Kafka中的Commit Offset有什麼作用?
Kafka Commit Offset主要是用於確保流式資料處理的一致性和可靠性,通過記錄已處理資料的位置,避免資料重複或丟失。Commit Offset通常與流式資料處理中的訊息佇列(如Kafka)一起使用,用於控制資料消費的進度。Flink在每次Checkpoint成功時,才會向Kafka提交當前讀取Offset,可以記錄下已經處理的資料的位置。如果未開啟Checkpoint,或者Checkpoint設定的間隔過大,在Kafka端可能會查詢不到當前讀取的Offset從而導致資料處理的重複或者丟失。
如何通過Kafka連接器解析嵌套JSON格式的資料?
例如如下JSON格式的資料,直接用JSON format解析,會被解析成一個ARRAY<ROW<cola VARCHAR, colb VARCHAR>> 欄位,就是一個 Row類型的數組,其中這個Row類型包含兩個VARCHAR欄位,然後通過自訂表格值函數(UDTF)解析。
{"data":[{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"}]}如何串連配置了安全資訊的Kafka叢集?
在Kafka DDL的WITH參數中添加要加密和認證相關的安全配置,安全配置詳情請參見SECURITY,程式碼範例如下。
重要需將安全配置加上properties. 首碼。
如何配置Kafka表以使用PLAIN作為SASL機制並提供JAAS配置。
CREATE TABLE KafkaTable ( `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING, `ts` TIMESTAMP(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka', ... 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.sasl.mechanism' = 'PLAIN', 'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";' );使用SASL_SSL作為安全性通訊協定,並使用SCRAM-SHA-256作為SASL機制。
CREATE TABLE KafkaTable ( `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING, `ts` TIMESTAMP(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka', ... 'properties.security.protocol' = 'SASL_SSL', /* SSL配置 */ /* 佈建服務端提供的truststore (CA認證) 的路徑 */ 'properties.ssl.truststore.location' = '/flink/usrlib/kafka.client.truststore.jks', 'properties.ssl.truststore.password' = 'test1234', /* 如果要求用戶端認證,則需要配置keystore(私密金鑰) 的路徑 */ 'properties.ssl.keystore.location' = '/flink/usrlib/kafka.client.keystore.jks', 'properties.ssl.keystore.password' = 'test1234', /* SASL配置 */ /* 將SASL機制配置為SCRAM-SHA-256 */ 'properties.sasl.mechanism' = 'SCRAM-SHA-256', /* 配置JAAS */ 'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";' );說明如果properties.sasl.mechanism是SCRAM-SHA-256,則properties.sasl.jaas.config用org.apache.flink.kafka.shaded.org.apache.kafka.common.security.scram.ScramLoginModule。
如果properties.sasl.mechanism是PLAINTEXT的話,則properties.sasl.jaas.config用 org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule。
在作業的附加依賴檔案中,上傳將要使用到的所有檔案(認證、公開金鑰或私密金鑰)。
上傳後檔案會被儲存在/flink/usrlib目錄下。如何在附加依賴檔案中上傳檔案,詳情請參見部署作業。
重要如果您的Kafka Broker上的使用者名稱和密碼的認證機製為SASL_SSL,但是用戶端上認證機製為SASL_PLAINTEXT,作業在校正時就會報錯OutOfMemory exception。此時,您需要修改用戶端的認證機制。
如何解決欄位命名衝突的問題?
問題現象
來自Kafka資料來源的訊息,這些訊息資料被序列化成了兩個JSON格式的串。這種情況下,鍵(key)和值(value)的內容中,均存在一個相同名稱的欄位(例如樣本中id欄位)。如果將其直接解析為Flink表進行處理,將會引發欄位命名衝突的問題。
key
{ "id": 1 }value
{ "id": 100, "name": "flink" }
解決方案
此問題可以通過使用key.fields-prefix屬性來避免。以下是定義Flink表的SQL語句。
CREATE TABLE kafka_table ( -- 在此定義鍵中和值中的欄位 key_id INT, value_id INT, name STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'test_topic', 'properties.bootstrap.servers' = 'localhost:9092', 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 指定鍵中的欄位和對應的資料類型 'key.format' = 'json', 'key.fields' = 'id', 'value.format' = 'json', 'value.fields' = 'id, name', -- 為鍵中的欄位設定首碼 'key.fields-prefix' = 'key_' );在建立Flink表時,指定了屬性key.fields-prefix為key_。這意味著在處理來自Kafka的資料時,鍵中的欄位(在該環境中就是id欄位)會被添加一個key_的首碼。因此在Flink表中的欄位名會變為key_id,這樣它就被清晰地與區分開了。
現在運行
SELECT * FROM kafka_table;查詢,輸出結果樣本如下。key_id: 1, value_id: 100, name: flink
讀取Kafka源表顯示業務延遲,不符合預期,如何處理?
問題詳情
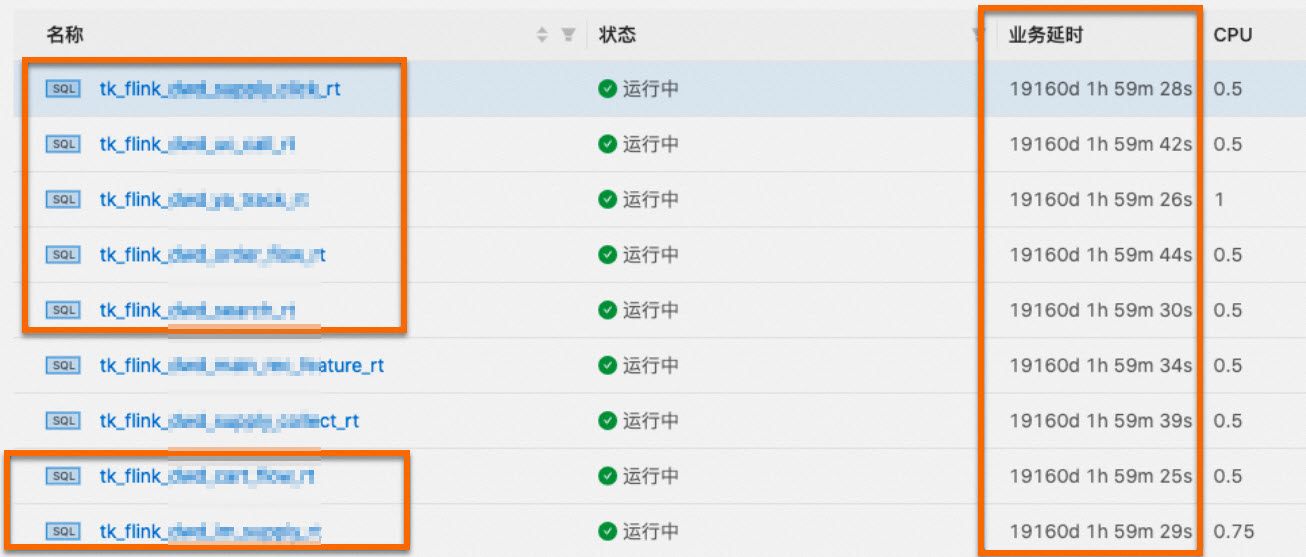
讀取Kafka源表存在currentEmitEventTimeLag 50多年,例如下圖所示。
排查思路
先判斷是JAR作業還是SQL作業。
如果是JAR作業,您還需要再確認下Pom使用的Kafka依賴是否為Realtime ComputeFlink版內建的,開源的沒有彙報曲線。
判斷上遊Kafka是否所有分區都有即時資料進入。
判斷Kafka message上的中繼資料timestamp是不是0或者null,
Kafka source的延遲是用目前時間減去Kafka訊息上帶的時間戳記算出來的,如果訊息上不帶時間戳記的話就會顯示50+年。具體的判斷方式如下:
SQL可以通過定義元資訊列擷取訊息的時間戳記,詳情請參見訊息佇列Kafka源表。
CREATE TEMPORARY TABLE sk_flink_src_user_praise_rt ( `timestamp` BIGINT , `timestamp` TIMESTAMP METADATA, --中繼資料時間戳記。 ts as to_timestamp ( from_unixtime (`timestamp`, 'yyyy-MM-dd HH:mm:ss') ), watermark for ts as ts - interval '5' second ) WITH ( 'connector' = 'kafka', 'topic' = '', 'properties.bootstrap.servers' = '', 'properties.group.id' = '', 'format' = 'json', 'scan.startup.mode' = 'latest-offset', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true' );寫一個簡單的Java程式把訊息用KafkaConsumer讀出來進行測試。
報錯:'upsert-kafka' table require PRIMARY KEY
問題詳情
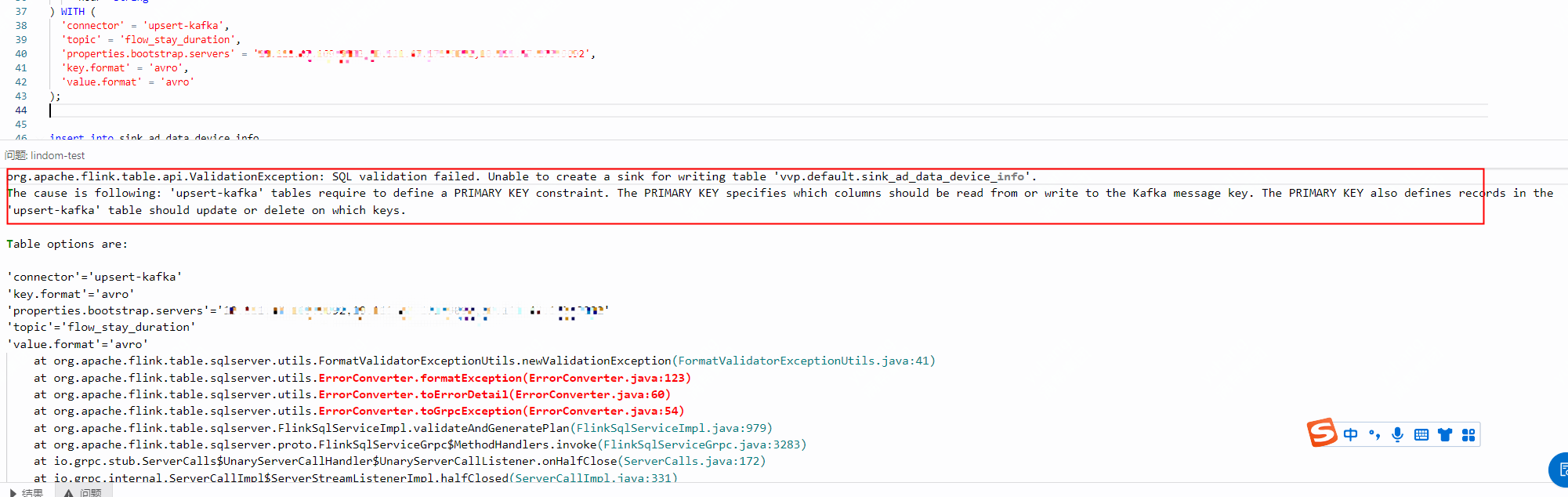
問題原因
在定義DDL時未指定主鍵。若使用upsert-kafka作為結果表,連接器可以消費上遊計算邏輯產生的Changelog流,並將INSERT或UPDATE_AFTER資料寫入的Kafka,將DELETE資料以value為空白的訊息寫入,表示對應key的訊息被刪除。Flink將根據主鍵列的值對資料進行分區,從而保證主鍵上的訊息有序,同一主鍵上的更新或刪除訊息將落在同一分區中。
解決方案
在定義DDL時指定主鍵。
分裂或者縮容DataHub Topic後導致Flink作業失敗,如何恢複?
如果分裂或者縮容了Flink正在讀取的某個Topic,則會導致任務持續出錯,無法自行恢複。該情況下需要重新啟動(先停止再啟動)來使任務恢複正常。
可以刪除正在消費的DataHub Topic嗎?
不支援刪除或重建正在消費的DataHub Topic。
endPoint和tunnelEndpoint是指什嗎?如果配置錯誤會產生什麼結果?
endPoint和tunnelEndpoint參數說明參見Endpoint。VPC環境中這兩個參數如果配置錯誤可能會導致任務異常,異常情況詳情如下:
如果endPoint配置錯誤,則任務上線停滯在91%的進度。
如果tunnelEndpoint配置錯誤,則任務運行失敗。
全量MaxCompute和增量MaxCompute是如何讀取MaxCompute資料的?
全量MaxCompute和增量MaxCompute是通過Tunnel讀取MaxCompute資料的,讀取速度受MaxCompute Tunnel頻寬節流設定。
引用MaxCompute作為資料來源,在作業啟動後,向已有的分區或者表裡追加資料,這些新資料是否能被全量MaxCompute或增量MaxCompute源表讀取?
啟動Flink作業後,如果正在被Source讀取或已經被Source讀取完成的表或分區有新的資料追加,則這部分資料不會被讀取,而且可能導致作業Failover。
全量MaxCompute和增量MaxCompute源表均使用ODPS DOWNLOAD SESSION讀取表資料或者分區資料。建立DOWNLOAD SESSION,服務端會建立一個Index檔案,相當於建立DOWNLOAD SESSION一瞬間資料的映射,後續的資料讀取以這個映射為基礎。因此在建立 DOWNLOAD SESSION 後,追加到MaxCompute表或者分區裡的資料,正常流程下是不會被讀取的。但如果MaxCompute源表中寫入新資料,則會出現兩種異常:
產生報錯:如果Tunnel在讀取資料的過程中寫入新資料,則會產生報錯
ErrorCode=TableModified,ErrorMessage=The specified table has been modified since the download initiated.。資料正確性無法保證:如果在Tunnel已經關閉後寫入新資料,則這些資料不會被讀取。但當作業發生Failover或者暫停後恢複作業,已經讀過的資料可能會被重讀,新寫入的資料可能被讀不全。
全量MaxCompute和增量MaxCompute源表作業是否支援暫停作業後修改並發數,再恢複作業?
對於開啟了useNewApi選項(預設開啟)的MaxCompute源表,在流模式下支援暫停作業後修改並發數再恢複作業。MaxCompute源表順序讀取匹配到的多個分區,在讀取當前分區時會分配每個並發讀取分區中不同範圍的資料。修改並發不改變作業暫停之前正在讀取分區的並發分配方式,當讀取下一個分區時再根據新的並發度分配每個並發的讀取範圍。因此可能出現讀取單個大分區時,增加並發並重啟作業後只有部分MaxCompute運算元讀取資料的情況。
對於指定了useNewApi為false的作業,以及批作業不支援修改並發。
作業啟動位點設定了2019-10-11 00:00:00, 為什麼啟動位點前的分區也會被全量MaxCompute源表讀取?
設定啟動位點只對訊息佇列(例如DataHub)類型的資料來源有效,對MaxCompute源表無效。Flink作業啟動後資料讀取的範圍如下:
分區表:讀取當前所有分區。
非分區表:讀取當前存在的資料。
增量MaxCompute源表監聽到新分區時,如果該分區還有資料沒有寫完,如何處理?
目前暫無機制可以標誌一個分區的資料是否完整,只要監聽到新分區,就會讀入。用增量MaxCompute源表讀取一個MaxCompute分區表T,分區列是ds,推薦的寫入方法為:不建立分區,先執行Insert overwrite table T partition (ds='20191010') ...語句,作業結束且成功後,分區和資料一起可見。
不允許的寫入方法為:先建立好分區,例如ds=20191010,再往分區裡寫資料。增量MaxCompute源表監聽到新分區ds=20191010,立刻讀入,如果此時該分區還有資料沒有寫完,就會漏讀資料。
MaxCompute連接器運行報錯:ErrorMessage=Authorization Failed [4019], You have NO privilege
報錯詳情
作業運行過程中會在Failover頁面或TaskManager.log頁面報錯,報錯資訊如下。
ErrorMessage=Authorization Failed [4019], You have NO privilege'ODPS:***'報錯原因
MaxCompute DDL定義中填寫的使用者身份資訊無法訪問MaxCompute。
解決方案
通過阿里雲帳號、RAM使用者帳號或RAM角色認證使用者身份,詳情請參見使用者認證。
如何填寫增量MaxCompute的startPartition參數?
請按以下步驟填寫startPartition參數。
步驟 | 說明 | 樣本 |
1 | 將每個分區列名及對應的分區值用等號(=)串連。分區值必須是一個固定值。 | 分區列為dt,需要讀取分區值從20220901開始的資料,結果為dt=20220901。 |
2 | 將第一步中得到的結果按分區層級從小到大排序,然後用逗號(,)串連,中間不能有任何空格。這一步得到的結果即為startPartition參數的值。 說明 可以只指定前若干級分區。 |
|
系統在載入分區列表時,會把每個分區列表的所有分區和startPartition按照字典序進行比較,載入字典序大於等於startPartition的分區。例如,一個增量MaxCompute分區表,有一級分區ds和二級分區type兩個分區列,假設表裡有以下6個分區:
ds=20191201,type=a
ds=20191201,type=b
ds=20191202,type=a
ds=20191202,type=b
ds=20191202,type=c
ds=20191203,type=a
當startPartition的值為ds=20191202時,將會讀取ds=20191202,type=a、ds=20191202,type=b、ds=20191202,type=c、ds=20191203,type=a四個分區。當startPartition的值為ds=20191202,type=b時,將會讀取ds=20191202,type=b、ds=20191202,type=c、ds=20191203,type=a三個分區。
startPartition指定的分區不一定需要存在,只要字典序大於等於startPartition的分區就會被讀取。
為什麼帶有增量MaxCompute源表的作業啟動後,遲遲不開始讀取資料?
這是因為目前已經存在的字典序大於等於startPartition的分區數太多,或這些分區裡的小檔案數量太多。增量MaxCompute源表需要首先整理合格存量分區的資訊再開始讀取,因此建議:
不要讀取太多歷史資料。
說明如果您需要處理歷史資料,可以運行帶有MaxCompute源表的批作業。
減少歷史資料中小檔案的數量。
在讀取或寫入分區時,如何填寫Partition參數?
讀取分區
讀取固定分區
源表與維表需要讀取固定分區時,請按以下步驟填寫partition參數。
步驟
說明
樣本
1
對於維表,將每個分區列名及對應的分區值用等號(=)串連。分區值是一個固定值。
對於源表,將每個分區列名及對應的分區值用等號(=)串連。分區值可以是一個固定值,也可以是一個包含萬用字元(*)的值。萬用字元可以匹配任一字元串(含Null 字元串)。
分區列為dt,需要讀取分區值為20220901的資料,結果為
dt=20220901。分區列為dt,需要讀取分區值以202209開頭的資料,結果為
dt=202209*(僅對源表生效)。分區列為dt,需要讀取分區值以2022開頭,01結尾的資料,結果為
dt=2022*01(僅對源表生效)。分區列為dt,需要讀取所有分區的資料,結果為
dt=*(僅對源表生效)。
2
將第一步中得到的結果按分區層級從小到大排序,然後用逗號(,)串連,中間不能有任何空格。這一步得到的結果即為partition參數的值。
可以只對前若干級分區進行指定。
只有一個一級分區dt。需要讀取dt=20220901的資料,直接填寫
'partition' = 'dt=20220901'。有三級分區,一級分區為dt,二級分區為hh,三級分區為mm。需要讀取dt=20220901,hh=08,mm=10的資料,填寫
'partition' = 'dt=20220901,hh=08,mm=10'。有三級分區,一級分區為dt,二級分區為hh,三級分區為mm。需要讀取dt=20220901,hh=08,mm任意的資料,填寫
'partition' = 'dt=20220901,hh=08'或'partition' = 'dt=20220901,hh=08,mm=*'。有三級分區,一級分區為dt,二級分區為hh,三級分區為mm。需要讀取dt=20220901,hh任意的資料,mm=10的資料,填寫
'partition' = 'dt=20220901,hh=*,mm=10'。
如果以上步驟無法滿足篩選分區的需求,也可以將篩選條件寫入SQL語句的WHERE條件中,利用SQL最佳化器的分區下推功能進行分區篩選。有兩級分區,一級分區為dt,二級分區為hh,需要讀取dt>=20220901,且dt<=20220903,且hh>=09,且hh<=17的分區,SQL程式碼範例如下。
CREATE TABLE maxcompute_table ( content VARCHAR, dt VARCHAR, hh VARCHAR ) PARTITIONED BY (dt, hh) WITH ( -- 需要通過PARTITIONED BY指定分區列,否則無法啟用SQL最佳化器的分區下推功能,影響執行效率。 'connector' = 'odps', ... -- 填寫accessId等必填參數。partition可不填寫,由SQL最佳化器進行篩選。 ); SELECT content, dt, hh FROM maxcompute_table WHERE dt >= '20220901' AND dt <= '20220903' AND hh >= '09' AND hh <= '17'; -- 在WHERE條件裡填寫分區篩選條件。讀取字典序最大的分區
如果源表或維表需要讀取字典序最大的分區,partition參數應填寫為
'partition' = 'max_pt()'。如果源表或維表需要讀取字典序最大的兩個分區,partition參數應填寫為
'partition' = 'max_two_pt()'。如果源表或維表需要讀取伴隨有.done的字典序最大的分區,partition參數應填寫為
'partition' = 'max_pt_with_done()'。
在多數應用情境下,字典序最大的分區也是最新產生的分區。有時最新分區的資料還未準備好,希望維表暫時先讀取較老分區的資料時,可以使用max_pt_with_done()這一partition參數值。
當一個分區的資料準備完成後,您需要同時建立一個空分區,該分區的名稱為對應包含資料的分區名.done。例如,當分區dt=20220901的資料準備完成後,您需要同時建立空分區dt=20220901.done。設定了max_pt_with_done()這一partition參數值後,維表只會讀取資料分區與.done分區同時存在的分區,沒有.done分區的資料分區則暫不讀取。詳情請參見max_pt()和max_pt_with_done()的區別是什嗎?。
說明源表僅會在作業啟動時擷取字典序最大的分區,在讀完所有資料後結束運行,不會監控是否有新分區產生。如果您需要持續讀取新分區,請使用增量源表模式。維表在每次更新時都會檢查最新分區並讀取最新資料。
寫入分區
寫入固定分區
結果表需要將資料寫入固定分區時,可以按讀取固定分區中相同的步驟填寫partition參數。
重要結果表的partition參數不支援萬用字元(*)。
寫入動態分區
結果表需要根據寫入資料中分區列具體值寫入對應分區時,需要將分區列名按分區層級從小到大排序,然後用逗號(,)串連,中間不能有任何空格。得到的結果即為partition參數的值。例如,有三級分區,一級分區為dt,二級分區為hh,三級分區為mm,此時可以填寫為
'partition' = 'dt,hh,mm'。
為什麼含有MaxCompute源表的作業一直在啟動中,或作業啟動成功後過了很久才產生資料?
原因有以下幾點:
MaxCompute表小檔案數量太多。
MaxCompute儲存叢集與Flink計算叢集不在同一地區,導致網路通訊時間過長。建議統一儲存叢集與計算叢集的地區後再次嘗試。
MaxCompute使用權限設定不正確,讀取源表需要MaxCompute表的download許可權。
如何選擇資料通道?
MaxCompute提供Batch Tunnel與Streaming Tunnel兩種資料通道。您可以根據一致性與運行效率的需求,選擇不同的資料通道。兩種資料通道的區別如下。
需求 | Batch Tunnel | Streaming Tunnel |
一致性 | 相比Streaming Tunnel,該方式在多數情況下能更穩定地將資料寫入 MaxCompute 表,保證資料不會丟失(At Least Once語義)。 只有當Checkpoint過程中出現異常,且作業同時寫入多個分區時,才有可能在部分分區中產生重複資料。 | 保證資料不會丟失(At Least Once語義),當作業在任意情況下出現異常時,都有可能產生重複資料。 |
運行效率 | 由於需要在Checkpoint過程中提交資料以及在服務端建立檔案等操作,整體效率低於Streaming Tunnel。 | 無需在Checkpoint過程中Commit資料。如果使用了Streaming Tunnel,同時設定numFlushThreads值大於1,在Flush資料的過程中也能不間斷地接收上遊資料,整體效率高於Batch Tunnel。 |
對於目前使用MaxCompute Batch Tunnel的作業,在Checkpoint進行得很慢甚至逾時,且確認下遊可以接受重複資料時,可以考慮使用MaxCompute Stream Tunnel。
如何處理MaxCompute結果表寫入資料出現重複的情況?
在Flink作業通過MaxCompute連接器寫入資料到MaxCompute時出現重複資料時,您可以從以下幾個方面進行排查:
檢查作業邏輯。在MaxCompute結果表中即使聲明了主鍵約束,Flink在向外部儲存寫入資料時也不會進行主鍵唯一性檢查,並且MaxCompute中非事務性表不支援主鍵約束。如果Flink作業邏輯計算出了重複資料,寫入MaxCompute的資料仍會出現重複的情況。
是否存在多個Flink作業同時寫入同一張MaxCompute表。如上文所述,MaxCompute側不支援主鍵約束,若多個Flink作業計算得到了相同結果,則會在MaxCompute表中重複存在。
使用Batch Tunnel時,Flink作業在進行Checkpoint時失敗。Checkpoint時失敗,MaxCompute結果表可能已經將資料提交至服務側,因此從上一個Checkpoint恢複作業時,兩個Checkpoint之間的資料可能出現重複的情況。
使用Stream Tunnel時發生了Flink作業的failover。在開啟Stream Tunnel向MaxCompute寫入資料時,在Checkpoint之間會將資料提交到MaxCompute服務側,因此當作業failover並從最新Checkpoint恢複時,最新Checkpoint完成之後、作業failover之前期間的資料可能會出現重複。詳情請參見如何選擇資料通道?此時,您可以切換到Batch Tunnel模式來避免這種情況產生的重複資料。
使用Batch Tunnel時,Flink作業failover或取消後啟動(例如由autopilot調優觸發)。在vvr-6.0.7-flink-1.15版本之前,MaxCompute結果表會在關閉時提交資料,因此當Flink作業停止並從上一個Checkpoint恢複時,Checkpoint和作業停止之間的資料可能出現重複。您可以將Flink版本升級到vvr-6.0.7-flink-1.15及更高版本來解決該問題。
含有MaxCompute結果表的作業運行過程中報錯Invalid partition spec
報錯原因:因為寫入MaxCompute的資料,分區列的值不合法。不合法的值包括:Null 字元串,空值(null值),以及含有等號(=)、英文逗號(,)或斜杠(/)的值。
解決方案:請檢查是否含有不合法資料。
含有MaxCompute結果表的作業運行過程中報錯No more available blockId
報錯原因:因為寫入MaxCompute結果表的block數量超過限制,說明每次flush的資料量太小而且flush太頻繁。
解決方案:建議調整batchSize與flushIntervalMs參數值大小。
如何使用維表SHUFFLE_HASH註解?
在預設情況下,每個並發都會儲存整張維表的資訊。如果維表資料量較大,可以使用SHUFFLE_HASH註解將維表資料均勻分散到各個並發中,降低JVM堆記憶體的消耗。如下樣本中,維表dim_1和dim_3的資料都分散到了各個並發中,而維表dim_2的資料仍然被完整地緩衝在每個並發中。
-- 建立源表與三張維表。
CREATE TABLE source_table (k VARCHAR, v VARCHAR) WITH ( ... );
CREATE TABLE dim_1 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
CREATE TABLE dim_2 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
CREATE TABLE dim_3 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
-- 將需要分散資料的維表名稱寫在SHUFFLE_HASH註解內。
SELECT /*+ SHUFFLE_HASH(dim_1), SHUFFLE_HASH(dim_3) */
k, s.v, d1.v, d2.v, d3.v
FROM source_table AS s
INNER JOIN dim_1 FOR SYSTEM_TIME AS OF PROCTIME() AS d1 ON s.k = d1.k
LEFT JOIN dim_2 FOR SYSTEM_TIME AS OF PROCTIME() AS d2 ON s.k = d2.k
LEFT JOIN dim_3 FOR SYSTEM_TIME AS OF PROCTIME() AS d3 ON s.k = d3.k;如何填寫CacheReloadTimeBlackList參數?
每天固定時段禁止維表更新的時間段
資料類型:
String用
->串連開始和結束時間。用
,分隔多個時間段。時間格式:
YYYY-MM-DD HH:mm(僅小時分鐘時,預設為每天)。
'cacheReloadTimeBlackList' = '14:00 -> 15:00,23:00 -> 01:00'樣本情境 | 樣本值 |
單一時間段 | 14:00 -> 15:00 |
多時間段 | 14:00 -> 15:00,23:00 -> 01:00 |
特殊時間段 | 14:00 -> 15:00, 23:00 -> 01:00,2025-10-01 22:00 -> 2025-10-01 23:00 |
報錯:java.io.EOFException: SSL peer shut down incorrectly
報錯詳情
Caused by: java.io.EOFException: SSL peer shut down incorrectly at sun.security.ssl.SSLSocketInputRecord.decodeInputRecord(SSLSocketInputRecord.java:239) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketInputRecord.decode(SSLSocketInputRecord.java:190) ~[?:1.8.0_302] at sun.security.ssl.SSLTransport.decode(SSLTransport.java:109) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.decode(SSLSocketImpl.java:1392) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.readHandshakeRecord(SSLSocketImpl.java:1300) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:435) ~[?:1.8.0_302] at com.mysql.cj.protocol.ExportControlled.performTlsHandshake(ExportControlled.java:347) ~[?:?] at com.mysql.cj.protocol.StandardSocketFactory.performTlsHandshake(StandardSocketFactory.java:194) ~[?:?] at com.mysql.cj.protocol.a.NativeSocketConnection.performTlsHandshake(NativeSocketConnection.java:101) ~[?:?] at com.mysql.cj.protocol.a.NativeProtocol.negotiateSSLConnection(NativeProtocol.java:308) ~[?:?] at com.mysql.cj.protocol.a.NativeAuthenticationProvider.connect(NativeAuthenticationProvider.java:204) ~[?:?] at com.mysql.cj.protocol.a.NativeProtocol.connect(NativeProtocol.java:1369) ~[?:?] at com.mysql.cj.NativeSession.connect(NativeSession.java:133) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:949) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:819) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:449) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:242) ~[?:?] at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:198) ~[?:?] at org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider.getOrEstablishConnection(SimpleJdbcConnectionProvider.java:128) ~[?:?] at org.apache.flink.connector.jdbc.internal.AbstractJdbcOutputFormat.open(AbstractJdbcOutputFormat.java:54) ~[?:?] ... 14 more報錯原因
該錯誤通常發生在MySQL資料庫啟用了SSL協議,但用戶端未正確配置SSL串連時。例如在MySQL driver版本為8.0.27時,MySQL資料庫開啟了SSL協議,但預設訪問方式不通過SSL串連資料庫,導致報錯。
解決方案
建議WITH參數中連接器設定為RDS,且MySQL維表URL參數中追加
characterEncoding=utf-8&useSSL=false,例如:'url'='jdbc:mysql://***.***.***.***:3306/test?characterEncoding=utf-8&useSSL=false'
為什麼主鍵為bigint unsigned的MySQL表註冊Flink Catalog,主鍵會變為decimal?但是使用CTAS同步到Hologres後,主鍵又變為text?
由於Flink不支援bigint unsigned,考慮到數值範圍的限制,Flink會將MySQL的bigint unsigned主鍵識別為decimal類型。而在進行Hologres同步時,由於Hologres不支援bigint unsigned,並且不支援將decimal類型用作主鍵,因此系統會自動將其轉換為了text類型。
建議在開發和設計過程中根據這一規範進行調整。如果您希望此列依然使用decimal類型,可以在Hologres端提前手動建表,並將其他欄位設定為主鍵或者不設定主鍵。然而,這可能導致資料重複問題,因為不同或缺失的主鍵會影響資料的唯一性。因此,需要在應用程式層面解決這一問題,例如可以容忍一定程度的資料重複或加入去重邏輯。
Flink的結果資料寫入RDS表,是按主鍵更新的,還是產生1條新的記錄?
如果在DDL中定義了主鍵,會採用INSERT INTO tablename(field1,field2, field3, ...) VALUES(value1, value2, value3, ...) ON DUPLICATE KEY UPDATE field1=value1,field2=value2, field3=value3, ...;的方式更新記錄,即對於不存在的主鍵欄位會直接插入,存在的主鍵欄位則更新相應的值。如果DDL中沒有聲明PRIMARY KEY,則會用insert into方式插入記錄,追加資料。
使用RDS表中的唯一索引進行GROUP BY時需要注意什嗎?
需要在作業中的GROUP BY中聲明該唯一索引。
RDS中只有一個自增主鍵,Flink作業中不能聲明為PRIMARY KEY。
為什麼MySQL物理表(包含RDS MySQL和ADB)的INT UNSIGNED欄位類型,在Flink SQL中要被聲明為其他類型?
因為MySQL的JDBC Driver在擷取資料時,由於精度問題,會採用不同的資料類型進行承接。具體來說,對於MySQL的INT UNSIGNED類型,在Java中會使用LONG類型來承接資料,對應Flink SQL中為BIGINT。而對於MySQL的BIGINT UNSIGNED類型,Java中會使用BIGINTEGER類型來承接資料,對應Flink SQL中為DECIMAL(20, 0)。
報錯:Incorrect string value: '\xF0\x9F\x98\x80\xF0\x9F...' for column 'test' at row 1
報錯詳情
Caused by: java.sql.BatchUpdateException: Incorrect string value: '\xF0\x9F\x98\x80\xF0\x9F...' for column 'test' at row 1 at sun.reflect.GeneratedConstructorAccessor59.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at com.mysql.cj.util.Util.handleNewInstance(Util.java:192) at com.mysql.cj.util.Util.getInstance(Util.java:167) at com.mysql.cj.util.Util.getInstance(Util.java:174) at com.mysql.cj.jdbc.exceptions.SQLError.createBatchUpdateException(SQLError.java:224) at com.mysql.cj.jdbc.ClientPreparedStatement.executeBatchedInserts(ClientPreparedStatement.java:755) at com.mysql.cj.jdbc.ClientPreparedStatement.executeBatchInternal(ClientPreparedStatement.java:426) at com.mysql.cj.jdbc.StatementImpl.executeBatch(StatementImpl.java:796) at com.alibaba.druid.pool.DruidPooledPreparedStatement.executeBatch(DruidPooledPreparedStatement.java:565) at com.alibaba.ververica.connectors.rds.sink.RdsOutputFormat.executeSql(RdsOutputFormat.java:488) ... 15 more報錯原因
資料中存在特殊的字元或編碼格式,導致資料庫編碼不能被正常解析。
解決方案
在使用JDBC串連MySQL資料庫時,URL地址後面加上UTF-8,例如
jdbc:mysql://<內網地址>/<databaseName>?characterEncoding=UTF-8。
寫MySQL(TDDL/RDS)時,出現死結(DeadLock)
問題詳情
寫MySQL(TDDL/RDS)時,出現死結(DeadLock)。
重要在Realtime ComputeFlink中,下遊資料庫使用MySQL等關聯式資料庫(對應的連接器為TDDL/RDS),當Realtime ComputeFlink版頻繁寫入某個表或者資源時,存在死結風險。
死結形成的樣本如下:
假設完成一次INSERT需要依次搶佔(A,B)2個鎖。A是一個範圍鎖,有2個事務(T1,T2),表的Schema為(id(自增主鍵),nid(唯一鍵))。T1包含2條insert(null,2),(null,1),T2包含1條insert(null,2)。
t時刻,T1第一條INSERT插入,此時T1持有(A,B)2個鎖。
t+1時刻T2開始插入,需要等待鎖A來鎖住(-inf,2],此時A被T1擁有,且鎖住了(-inf,2],區間存在內含項目關聯性,所以T2依賴T1釋放A。
t+2時刻T1第二條INSERT執行,需要A鎖住(-inf,1],該區間屬於(-inf,2],所以需要排隊等T2釋放鎖,所以T1依賴T2釋放A。
當T1和T2相互依賴且相互等待時死結形成。
RDS/TDDL、OTS資料庫引擎鎖的區別
RDS/TDDL:InnoDB的行鎖是針對索引加的鎖,不是針對單條記錄加的鎖。因此,雖然是訪問不同行的記錄,但是如果使用相同的索引鍵,會出現鎖衝突,導致整個地區的資料都無法更新。
OTS:單行鎖,不影響其他資料更新。
死結的解決方案
高QPS/TPS或高並發寫入情境,建議使用OTS作為結果表,可以解決死結的問題。通常,不建議使用TDDL或者RDS作為Flink Job的結果表。
如果必須要使用MySQL等關聯式資料庫作為Sink節點,以下是一些建議:
確保沒有其他讀寫業務方的幹擾。
如果Job的資料量不大可以嘗試單並發寫入。但是在高QPS/TPS、高並發情況下,寫入效能會降低。
儘可能不使用UniqueKey(唯一主鍵),帶UniqueKey表的寫入可能會導致死結。如果業務要求表必須包含UniqueKey,請按照欄位區分能力從大到小排列來定義UniqueKey,可以大幅降低死結出現機率。例如,您可以把MD5函數放在day_time(20171010)前面,就可以使得欄位區分能力從大到小排列來定義UniqueKey,從而解決死結問題。
根據業務特點做分庫分表,儘可能避免單表寫入,實施細節請聯絡對應的資料庫管理員。
更新了MySQL中的表結構,但是下遊的表結構沒有變化是怎麼回事?
表結構的變更同步並不識別具體的DDL,而是捕獲前後兩條資料之間的Schema變化。如果僅僅發生了DDL變更,但是上遊無任何新增資料或者資料變更,則不會觸發下遊的資料變更。詳細說明請參見表結構變更的同步策略。
Source出現finish split response timeout異常,是什麼原因?
該異常是因為Task的CPU使用率過高導致來不及響應Coordinator的RPC請求。此時,您需要在資源配置頁面增加Task Manager的CPU資源。
在MySQL CDC全量階段發生表結構變更有什麼影響?
全量階段發生了表結構變更,可能會導致作業報錯或無法同步表結構變更。此時需要先停止作業,然後刪除同步的下遊表,並無狀態地啟動作業。
如果CTAS/CDAS同步期間發生了不支援的表結構變更,導致作業報錯同步失敗,該怎麼解決?
您需要重新同步該表的資料。即先停止作業,然後刪除下遊表並重新無狀態啟動同步作業。請您避免這種不相容的修改,否則重啟作業後還會報錯同步失敗。表結構變更支援情況詳情請參見CREATE TABLE AS(CTAS)語句。
ClickHouse結果表是否支援回撤更新資料?
當Flink結果表的DDL上指定了Primary Key,且參數 ignoreDelete設定為false時,則支援回撤更新資料,但效能會顯著下降。
因為ClickHouse是一個用於聯機分析(OLAP)的列式資料庫管理系統,對UPDATE和DELETE的支援不夠完善,如果在Flink DDL上指定了Primary Key,則會嘗試使用ALTER TABLE UPDATE和ALTER TABLE DELETE來更新和刪除資料,更新和刪除的效率很低。
何時才可以在ClickHouse中看到寫入到結果表的資料?
對於沒開啟exactlyOnce語義(預設不開啟)的ClickHouse結果表,只要緩衝中的資料條數達到了batchSize參數值,或者等待時間超過flushIntervalMs後,系統就會自動將緩衝中的資料寫入ClickHouse表中,此時就可以在ClickHouse中看到寫入到結果表的資料,並不需要等checkpoint執行成功。
對於開啟exactlyOnce語義的ClickHouse結果表,則需要等checkpoint執行成功後才可以在ClickHouse中看到寫入到結果表的資料。
如何在控制台查看print資料結果?
查看print資料結果的步驟,有以下兩種方式:
在Realtime Compute開發控制台查看:
在Realtime Compute開發控制台左側導覽列,選擇。
單擊目標作業名稱。
單擊作業日誌。
在左側作業記錄頁簽,單擊作業右側的下拉框,選擇正在運行作業。

在運行 Task Managers頁簽,單擊Path, ID。

單擊日誌,查看print資料結果。
跳轉到Flink UI介面查看:
在Realtime Compute開發控制台左側導覽列,選擇。
單擊目標作業名稱。
在目標作業狀態總覽頁簽,單擊Flink UI。

單擊Task Managers。
單擊Path, ID。
在logs頁簽,查看print資料結果。
維表進行JOIN時,如果查詢不到資料,應該如何處理?
檢查DDL語句和物理表中的Schema類型和名稱是否一致。
max_pt()和max_pt_with_done()的區別是什嗎?
max_pt()選取的是所有分區中字典序最大的分區。max_pt_with_done()選取的是所有分區中字典序最大,且伴隨有.done分區的分區。如果分區列表示例如下:
ds=20190101
ds=20190101.done
ds=20190102
ds=20190102.done
ds=20190103
則max_pt()和max_pt_with_done()的區別如下:
`partition`='max_pt_with_done()'匹配的分區是ds=20190102。`partition`='max_pt()',匹配的分區是ds=20190103。
寫Paimon作業出現Heartbeat of TaskManager timed out
此類報錯最有可能的原因是Task Manager堆記憶體不足。Paimon使用堆記憶體的主要方式為:
Paimon主鍵表writer運算元的每個並發都有一個記憶體Buffer用於排序。該buffer的大小受
write-buffer-size表參數控制,預設值為256 MB。Paimon預設使用ORC檔案格式,因此還需要一個記憶體Buffer將記憶體裡的資料分批轉為列存格式。該Buffer的大小受
orc.write.batch-size表參數控制,預設值為1024,即預設儲存1024行資料。每個被修改的分桶都有一個專用的writer對象處理該分桶的寫入資料。
基於堆記憶體的使用方式,可能導致堆記憶體不足的原因和相應解決方案如下:
write-buffer-size的值過大。可適當減小該參數。但buffer太小會導致磁碟被頻繁寫入,觸發小檔案合并的頻率也會變高,影響寫入效能。
單條資料的大小太大。
例如,資料中包含一個大小為4 MB的JSON欄位,此時ORC Buffer大小將達到4 MB × 1024 = 4 GB,佔用大量的堆記憶體。有以下兩種解決方案:
調小
orc.write.batch-size的值。如果您不需要對Paimon結果表進行即席查詢(OLAP),只需進行批式或流式消費,可以在建表時通過設定
'file.format' = 'avro'以及'metadata.stats-mode' = 'none'這兩個表參數,來使用AVRO格式,並關閉統計資訊的收集。說明參數僅支援在建表時設定,建表完成後無法通過ALTER TABLE語句或SQL Hint進行修改。
同時寫入的分區數太多或每個分區的分桶數太多,導致writer對象建立太多。
需檢查分區列的設定是否合理,是否由於SQL編寫錯誤導致分區列被寫入其它資料,以及分桶數是否合理。建議每個分桶中的資料總量在2 GB左右,最大不超過5 GB,分桶數調整請參見調整固定分桶表的分桶數量。
寫Paimon作業出現Sink materializer must not be used with Paimon sink
Sink materializer運算元原本用於解決流作業中級聯JOIN導致的資料亂序問題。然而,在寫入Paimon表的作業時,該運算元不僅會引入額外的開銷,在使用Aggregation資料合併機制時還可能導致計算結果錯誤。因此,寫入Paimon表的作業中不能使用Sink materializer運算元。
您可以通過SET語句或運行參數配置將table.exec.sink.upsert-materialize參數設為false,來關閉Sink materializer運算元。如果您同時還需要解決級聯JOIN導致的資料亂序問題,請參見亂序資料處理。
寫Paimon作業出現File deletion conflicts detected或LSM conflicts detected
出現該報錯的原因可能有以下幾種:
有多個作業同時寫入同一張Paimon表的同一個分區,此時Paimon表需要通過失敗重啟的方式解決衝突,這是正常現象。如果報錯沒有重複出現則無需處理。
從一個已存在的老狀態恢複作業。此時該報錯會重複出現,您需要從最新狀態恢複作業,或無狀態啟動作業。
在同一個作業中,使用多條INSERT語句寫入同一張Paimon表。Paimon目前暫不支援在同一個作業中通過多條INSERT語句分別寫入,請使用UNION ALL語句將多條資料流寫入Paimon表。
Global Committer節點或寫入Append Scalable表時的Compaction Coordinator節點的並發數大於1。這兩個節點的並發數必須為1,否則無法保證資料的一致性。
讀Paimon作業出現File xxx not found, Possible causes
Paimon表的消費依賴快照檔案,快照到期時間太短或消費作業效率低會導致正在消費的快照檔案因到期被刪除,消費作業將會報錯。
您可以考慮調整快照檔案到期時間、指定Consumer ID或消費作業最佳化。如果您需要查詢目前可用的快照檔案,以及每個快照檔案建立的時間點,請參見Snapshots系統資料表。
Paimon作業出現No space left on device
如果該作業涉及到Paimon的查詢過程(如使用Paimon table作為維表,或寫入Paimon表時使用changelog-producer=lookup等),可通過SQL Hints設定如下參數,以限制查詢過程中磁碟佔用的最大空間和緩衝到期時間,避免過多快取檔案導致磁碟空間不足問題。
lookup.cache-max-disk-size:查詢快取能使用的最大本地磁碟空間大小。建議取256mb、512mb、1gb等數值。lookup.cache-file-retention:查詢快取到期時間。建議取30min、15min或更小的時間。
對於寫入Paimon表的作業,可通過SQL Hints設定如下參數,以限制寫出過程中本地臨時檔案的總大小,避免過多臨時檔案導致磁碟空間不足問題。
write-buffer-spillable:寫資料緩衝溢出到磁碟的總開關。設定為false可直接避免所有本緩衝佔用磁碟空間的情況。write-buffer-spill.max-disk-size:寫資料緩衝可溢出到磁碟的最大空間。建議取256mb、512mb、1gb等數值。
OSS上有大量Paimon檔案如何處理?
Paimon連接器寫入資料的可見度和Checkpoint間隔有關係嗎?
有關係。Paimon的exactly-once語義是依賴於系統檢查點(Checkpoint)來保證。只有在每次Checkpoint時,Paimon才會真正提交資料,使這些資料對下遊可見。在提交之前,本地Buffer中的資料被Flush到遠程檔案系統中,但不會通知下遊可以讀取這些資料。
寫Paimon作業長時間內出現記憶體佔用緩慢上漲的現象
如果作業rps同樣也在緩慢上漲,則作業記憶體佔用同樣上漲屬於正常現象。
如果是使用Paimon FileSystem Catalog讀寫OSS,請確保您在Catalog參數中配置過
fs.oss.endpoint、fs.oss.accessKeyId與fs.oss.accessKeySecret。否則該Flink作業保持長時間運行,可能會存在社區已知的記憶體緩慢泄漏問題。
報錯:IllegalArgumentException: timeout value is negative
報錯詳情

報錯原因
如果有一段時間沒有消費到新的MQ訊息,MetaQSource線程休眠,而休眠的時間長度為pullIntervalMs參數設定的值。但是pullIntervalMs參數預設值是-1。如果用-1作為休眠時間長度的值時,作業就會報錯。
解決方案
設定pullIntervalMs參數為非負數。
RocketMQ Topic擴容時,RocketMQ如何感知Topic分區數變化?
FlinkRealtime Compute引擎VVR 6.0.2以下版本的實現是每5-10分鐘擷取一次當前分區數,如果分區數量連續三次都與原來的分區數不同,就會觸發Failover。因此分區數發生變化後10-30分鐘Source能感知到,並且發生Failover,作業重啟後會按新的分區讀取。
FlinkRealtime Compute引擎VVR 6.0.2及以上版本的實現是預設固定每5分鐘擷取一次當前分區數,當發現新的分區之後,直接交給TM的Source運算元讀取新的分區資料,不需要作業Failover。因此Source能在1-5分鐘內感知分區發生的變化。
報錯:BackPressure Exceed reject Limit
報錯詳情
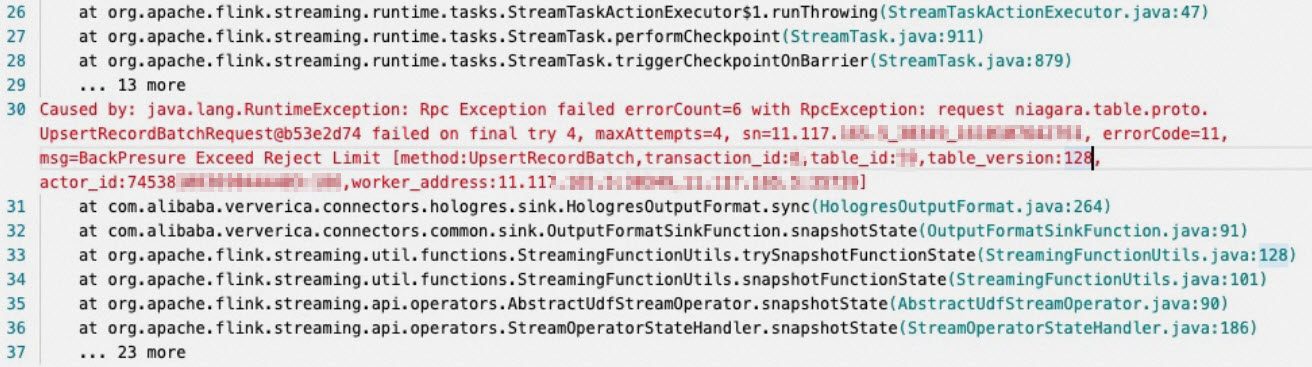
報錯原因
Hologres寫入壓力比較大導致的。
解決方案
可以將執行個體資訊提供給Hologres支援人員,以進行升級操作。
報錯:remaining connection slots are reserved for non-replication superuser connections
報錯詳情
Caused by: com.alibaba.hologres.client.exception.HoloClientWithDetailsException: failed records 1, first:Record{schema=org.postgresql.model.TableSchema@188365, values=[f06b41455c694d24a18d0552b8b0****, com.chot.tpfymnq.meta, 2022-04-02 19:46:40.0, 28, 1, null], bitSet={0, 1, 2, 3, 4}},first err:[106]FATAL: remaining connection slots are reserved for non-replication superuser connections at com.alibaba.hologres.client.impl.Worker.handlePutAction(Worker.java:406) ~[?:?] at com.alibaba.hologres.client.impl.Worker.run(Worker.java:118) ~[?:?] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_302] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_302] ... 1 more Caused by: com.alibaba.hologres.org.postgresql.util.PSQLException: FATAL: remaining connection slots are reserved for non-replication superuser connections at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2553) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.readStartupMessages(QueryExecutorImpl.java:2665) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.<init>(QueryExecutorImpl.java:147) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl(ConnectionFactoryImpl.java:273) ~[?:?] at com.alibaba.hologres.org.postgresql.core.ConnectionFactory.openConnection(ConnectionFactory.java:51) ~[?:?] at com.alibaba.hologres.org.postgresql.jdbc.PgConnection.<init>(PgConnection.java:240) ~[?:?] at com.alibaba.hologres.org.postgresql.Driver.makeConnection(Driver.java:478) ~[?:?] at com.alibaba.hologres.org.postgresql.Driver.connect(Driver.java:277) ~[?:?] at java.sql.DriverManager.getConnection(DriverManager.java:674) ~[?:1.8.0_302] at java.sql.DriverManager.getConnection(DriverManager.java:217) ~[?:1.8.0_302] at com.alibaba.hologres.client.impl.ConnectionHolder.buildConnection(ConnectionHolder.java:122) ~[?:?] at com.alibaba.hologres.client.impl.ConnectionHolder.retryExecute(ConnectionHolder.java:195) ~[?:?] at com.alibaba.hologres.client.impl.ConnectionHolder.retryExecute(ConnectionHolder.java:184) ~[?:?] at com.alibaba.hologres.client.impl.Worker.doHandlePutAction(Worker.java:460) ~[?:?] at com.alibaba.hologres.client.impl.Worker.handlePutAction(Worker.java:389) ~[?:?] at com.alibaba.hologres.client.impl.Worker.run(Worker.java:118) ~[?:?] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_302] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_302] ... 1 more報錯原因
一般為串連數超出。
解決方案
查看每個接入節點(Frontend,FE) 串連的app_name,查看flink-connector使用的HoloGRES Client串連數。
查看是否有其他作業在串連Hologres。
釋放串連數。詳情請參見串連數管理。
報錯:no table is defined in publication
報錯詳情
刪除表並重建同名表可能導致作業出現
no table is defined in publication。問題原因
表被刪除時,和表綁定的publication沒有被刪除。
解決方案
在Hologres中執行
select * from pg_publication where pubname not in (select pubname from pg_publication_tables);命令,查詢刪表時未一起被清理的publication資訊。執行
drop publication xx;語句刪除殘留的publication。重新啟動作業。
Flink的Hologres Sink連接器的Checkpoint間隔和Hologres資料的最終可見度有什麼關係?
Flink Hologres Sink連接器的Checkpoint(CP)間隔與Hologres資料的最終可見度沒有直接關係,CP間隔影響資料恢複的SLA,但並不決定最終資料在Hologres中的可見時間。
Hologres連接器不支援事務,僅定期將資料flush到資料庫。CP間隔僅保證每次CP時資料一定已重新整理到資料庫,但並不代表最長會等待該間隔時間。事實上,如果緩衝區滿足一定條件(詳見即時數倉Hologres、即時數倉Hologres和即時數倉Hologres),資料就會更早flush到下遊。一般數倉不需要保證事務一致性,連接器會在後台非同步重新整理資料,在CP時再強制執行一次flush,以備異常恢複。
作業上線拋出permission denied for database異常
報錯原因
Realtime Compute引擎VVR 8.0.4起,連接器如果發現使用者使用的Hologres執行個體大於2.0版本,會強制使用JDBC模式消費Binlog。如果Hologres執行個體是2.0及以上版本,且使用者不是Superuser,使用JDBC模式消費Binlog需要特別進行許可權的配置。
解決方案
如果使用者不是SuperUser,使用JDBC模式消費Binlog需要進行許可權配置。
user_name為阿里雲帳號ID或RAM使用者,詳情請參見帳號概述。
-- 專家許可權模型下為使用者授予CREATE許可權,以及賦予使用者執行個體的Replication Role許可權 GRANT CREATE ON DATABASE <db_name> TO <user_name>; alter role <user_name> replication; -- 如果Database開啟了簡單許可權模型(SLMP),無法執行GRANT語句,使用spm_grant為使用者授予DB的Admin許可權,也可以在Holoweb中直接賦權 call spm_grant('<db_name>_admin', '<user_name>'); alter role <user_name> replication;
作業從檢查點恢複過程中,發生table id parsed from checkpoint is different from the current table id異常
報錯原因
這是由於Realtime Compute引擎VVR 8.0.5~VVR 8.0.8版本,Hologres Binlog源表從checkpoint恢複時,會強制檢查hologres表的table id,如果當前表的table id和checkpoint中儲存的不一致,會無法從checkpoint恢複。此異常表示作業運行期間,使用者對源表進行了TRUNCATE或其他重建表操作。
解決方案
建議升級到VVR-8.0.9及以上版本啟動作業。考慮到業務情境的複雜性,在VVR 8.0.9取消了對table id的強制檢查,但仍然不推薦對Binlog源表做重建表操作。重建表時原有錶的歷史Binlog會全部清除,Flink使用舊錶的消費位點去消費新表的資料,可能導致資料不一致等不符合預期的情況。
通過JDBC模式消費Binlog時資料精度不符合預期問題
問題原因
Realtime Compute引擎VVR 8.0.10及之前版本中,如果Flink DDL中聲明的Binlog源表
DECIMAL類型的精度與Hologres不一致,會導致精度不符合預期。解決方案
在VVR 8.0.11中,該問題已得到修複。但仍請確保Flink與Hologres 的
DECIMAL類型精度一致,以避免精度缺失導致的資料丟失。
刪除表並重建同名表可能導致作業出現no table is defined in publication或者The table xxx has no slot named xxx異常
報錯原因
表被刪除時,和表綁定的publication沒有被刪除。
解決方案
方案1:可以在hologres中執行
select * from pg_publication where pubname not in (select pubname from pg_publication_tables);語句,查詢刪表時未一起被清理的publication,並執行drop publication xx;語句刪除殘留的publication,之後重新啟動作業即可。方案2:選擇VVR 8.0.5及以上版本,連接器會自動執行清理操作。
報錯:Caused by: com.aliyun.openservices.aliyun.log.producer.errors.LogSizeTooLargeException: the logs is 8785684 bytes which is larger than MAX_BATCH_SIZE_IN_BYTES 8388608
報錯詳情
Caused by: com.aliyun.openservices.aliyun.log.producer.errors.LogSizeTooLargeException: the logs is 8785684 bytes which is larger than MAX_BATCH_SIZE_IN_BYTES 8388608 at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.ensureValidLogSize(LogAccumulator.java:249) at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.doAppend(LogAccumulator.java:103) at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.append(LogAccumulator.java:84) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:385) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:308) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:211) at com.alibaba.ververica.connectors.sls.sink.SLSOutputFormat.writeRecord(SLSOutputFo rmat.java:100)報錯原因
寫入SLS的單行日誌超過8 MB,無法再寫入資料。
解決方案
更改啟動位點,跳過超大異常資料,詳情請參見作業啟動。
恢複失敗的Flink程式時,TaskManager發生OOM,源表報錯java.lang.OutOfMemoryError: Java heap space
報錯原因
通常是由於SLS訊息體過大導致。SLS連接器是通過批量擷取的方式請求資料,LogGroup由batchGetSize參數控制,預設為100。因此每次會收到最多100個LogGroup。在日常運行時,Flink消費及時,一般不會收到100個LogGroup,但在Failover時會積攢了大量未消費的資料。如果單個LogGroup佔用記憶體*100>JVM可用記憶體,則TaskManager會發生OOM。
解決方案
減小batchGetSize參數值。
如何設定Paimon源表的消費位點?
您可以通過scan.mode參數設定Paimon源表的消費位點。scan.mode參數的可選值以及行為如下。
參數值 | 批讀行為 | 流讀行為 |
default | 預設值,根據其他參數確定實際的行為。
如果以上兩個參數都沒有設定,則行為與latest-full參數值相同。 | |
latest-full | 產出表的最新snapshot。 | 作業啟動時,首先產生表的最新snapshot,之後持續產生增量資料。 |
compacted-full | 產出表最近一次compact後的snapshot。 | 作業啟動時,首先產出表最近一次compact後的snapshot,之後持續產出增量資料。 |
latest | 與latest-full相同。 | 作業啟動時不產生表的最新snapshot,之後持續產生增量資料。 |
from-timestamp | 產出表在 | 作業啟動時不產出snapshot,之後持續產出從 |
from-snapshot | 產出表的snapshot,snapshot編號由 | 作業啟動時不產出snapshot,之後持續產出從 |
from-snapshot-full | 與from-snapshot相同。 | 作業啟動時產出表的snapshot,snapshot編號由 |
如何設定分區自動到期?
Paimon表支援自動刪除存活時間長度大於分區到期時間長度的分區的功能,以節省儲存成本。詳情如下:
存活時間長度:當前系統時間減去分區值轉化後的時間戳記。分區值轉化後的時間戳記是按照以下順序轉化而得:
通過格式串
partition.timestamp-pattern參數,將一個分區值轉換為時間字串。在該格式串中,分區列由貨幣符號($)加上列名表示。例如,假設分區列由year、month、day、hour四列組成,格式串
$year-$month-$day $hour:00:00會將分區year=2023,month=04,day=21,hour=17轉換為字串2023-04-21 17:00:00。通過格式串
partition.timestamp-formatter參數,將時間字串轉換為時間戳記。如果該參數沒有設定,將預設嘗試
yyyy-MM-dd HH:mm:ss與yyyy-MM-dd兩個格式串。任何Java的DateTimeFormatter相容的格式串都可以使用。
分區到期時間:您設定的
partition.expiration-time參數值。
儲存中一直查不到資料,應該如何處理?
如果是資料未刷盤,這是正常現象,因為Flink的writer是按照以下策略去刷資料到磁碟的:
某個bucket在記憶體積攢到一定大小(預設值為64 MB)。
總的buffer大小積攢到一定大小(預設值為1 GB)。
觸發Checkpoint,將記憶體裡的資料全部flush出去。
如果是流寫,請確保已開啟Checkpoint。
資料有重複時,應該如何去做?
如果您是COW寫,則需要開啟參數write.insert.drop.duplicates。
COW寫每個bucket的第一個檔案預設是不去重的,只有增量的資料會去重,全域去重需要開啟該參數;MOR寫不需要開啟任何參數,定義好primary key後預設全域去重。
說明從Hudi 0.10.0版本開始,該屬性改名為write.precombine,且預設值為true。
如果需要多partition去重,則需開啟參數index.global.enabled為true。
說明從Hudi 0.10.0版本開始,該屬性預設為true。
當
index.type=bucket時,設定index.global.enabled參數為true是無效的,因為Bucket索引不支援跨分區的變更。因此,即使開啟了全域索引,也無法實現多分區的去重功能。
對於長時間周期的更新,例如更新一個月前的資料,需將index.state.ttl調大(單位為天)。
索引是判斷資料重複的核心資料結構,index.state.ttl設定了索引儲存的時間,預設為1.5天,設定小於0代表永久儲存。
說明從Hudi 0.10.0版本開始,該屬性預設為0。
為什麼Merge On Read只有log檔案?
問題原因:Hudi只有在執行壓縮後才會產生Parquet檔案,否則只有Log檔案。而Merge On Read預設開啟非同步壓縮,策略是5個commits壓縮一次,只有當條件滿足才會觸發壓縮任務。
解決方案:通過調整壓縮間隔compaction.delta_commits參數,更快觸發壓縮任務。
報錯:multi-statement be found
問題詳情
Flink作業寫資料至AnalyticDB MySQL版(ADB),作業異常重啟報錯
Caused by: java.sql.SQLSyntaxErrorException: [13000, 2024101216171419216823505703151806929] multi-statement be found.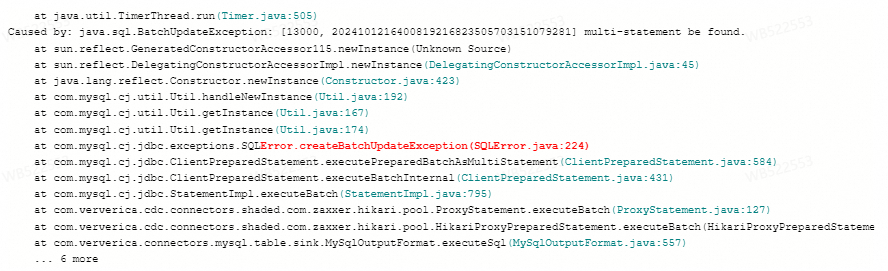
問題原因
AnalyticDB MySQL版(ADB)資料庫啟用
ALLOW_MULTI_QUERIES=true配置時,與MySQL JDBC Driver 8.x版本結合使用,出現相容性問題。解決方案
聯絡支援人員擷取5.1.46版本的MySQL JDBC Driver的自訂ADB 3.0連接器,然後將它應用於您的Flink任務中,自訂連接器使用方法請參見管理自訂連接器。
在ADB表的URI上配置參數
allowMultiQueries=true,例如jdbc:mysql://xxxxx.ads.aliyuncs.com:3306/xxx?allowMultiQueries=true'。
報錯No suitable driver found for
問題原因
自訂連接器未找到對應的驅動程式(Driver)。
解決方案
通過
Class.forName提前在工廠類(Factory)中載入驅動程式(Driver)。把Driver驅動放到附加依賴裡,並且添加參數
kubernetes.application-mode.classpath.include-user-jar: true,添加參數方法請參見如何配置自訂的作業運行參數?