本文為您介紹如何通過Realtime Compute控制台快速構建從Kafka到Hologres的資料同步作業,實現日誌資料的即時入倉部署。
前提條件
如果您使用RAM使用者或RAM角色等身份訪問,需要確認已具有Flink控制台相關許可權,詳情請參見許可權管理。
已建立Flink工作空間,詳情請參見開通Realtime ComputeFlink版。
上下遊儲存
已建立訊息佇列Kafka執行個體,詳情請參見步驟二:購買和部署執行個體。
已建立Hologres執行個體,詳情請參見購買Hologres。
說明訊息佇列Kafka和Hologres需要與Realtime ComputeFlink版工作空間在相同地區相同VPC下,否則需要打通網路,詳情請參見如何訪問跨VPC的其他服務?或如何訪問公網?。
步驟一:配置IP白名單
為了讓Flink能訪問Kafka和Hologres執行個體,您需要將Flink工作空間的網段添加到Kafka和Hologres的白名單中。



步驟二:準備Kafka測試資料
使用Realtime ComputeFlink版的類比資料產生源表作為資料產生器,將資料寫入到Kafka中。請按以下步驟使用Realtime Compute開發控制台將資料寫入至訊息佇列Kafka。
在Kafka控制台建立一個名稱為users的Topic。
操作詳情請參見步驟一:建立Topic。
建立將資料寫入到Kafka的作業。
單擊目標工作空間操作列下的控制台。
在左側導覽列,單擊,單擊建立。
在新增作業草稿對話方塊,選擇目標模板(例如:選擇空白的流作業草稿),完成後單擊下一步,填寫作業配置資訊。
作業參數
樣本
說明
檔案名稱
kafka-data-input
作業的名稱。
說明作業名稱在當前專案中必須保持唯一。
儲存位置
作業草稿
指定該作業的代碼檔案所屬的檔案夾。預設存放在作業草稿目錄。
您還可以在現有檔案夾右側,單擊
 表徵圖,建立子檔案夾。
表徵圖,建立子檔案夾。引擎版本
vvr-8.0.11-flink-1.17
在引擎版本下拉式清單中選擇目標引擎版本。
單擊建立。
編寫SQL作業。
將以下作業代碼拷貝到作業文本編輯區,然後根據實際配置,修改參數配置資訊。
CREATE TEMPORARY TABLE source ( id INT, first_name STRING, last_name STRING, `address` ROW<`country` STRING, `state` STRING, `city` STRING>, event_time TIMESTAMP ) WITH ( 'connector' = 'faker', 'number-of-rows' = '100', 'rows-per-second' = '10', 'fields.id.expression' = '#{number.numberBetween ''0'',''1000''}', 'fields.first_name.expression' = '#{name.firstName}', 'fields.last_name.expression' = '#{name.lastName}', 'fields.address.country.expression' = '#{Address.country}', 'fields.address.state.expression' = '#{Address.state}', 'fields.address.city.expression' = '#{Address.city}', 'fields.event_time.expression' = '#{date.past ''15'',''SECONDS''}' ); CREATE TEMPORARY TABLE sink ( id INT, first_name STRING, last_name STRING, `address` ROW<`country` STRING, `state` STRING, `city` STRING>, `timestamp` TIMESTAMP METADATA ) WITH ( 'connector' = 'kafka', 'properties.bootstrap.servers' = 'alikafka-host1.aliyuncs.com:9092,alikafka-host2.aliyuncs.com:9092,alikafka-host3.aliyuncs.com:9092', 'topic' = 'users', 'format' = 'json' ); INSERT INTO sink SELECT * FROM source;需要修改的參數配置資訊如下:
參數
樣本值
說明
properties.bootstrap.servers
alikafka-host1.aliyuncs.com:9092,alikafka-host2.aliyuncs.com:9092,alikafka-host3.aliyuncs.com:9092
Kafka Broker地址。
格式為host:port,host:port,host:port,以英文逗號(,)分割。您可以在執行個體詳情頁面的存取點資訊地區擷取網路類型為VPC的網域名稱存取點作為該參數的值。
topic
users
Kafka Topic名稱。
啟動作業。
在頁面,單擊部署。
在部署新版本對話方塊中,單擊確定。
配置作業資源,資源設定填寫詳情請參見配置作業資源。
在頁面,單擊目標作業名稱操作列中的啟動。關於作業啟動的配置說明,請參見作業啟動。
您可以在作業營運頁面觀察作業的運行資訊和狀態。

由於faker資料來源是一個有限流,因此在作業處於運行狀態後,大約1分鐘左右後,作業就會處於完成狀態。當作業結束運行代表作業已經將相關的資料寫入到Kafka的users中。其中,寫入到訊息佇列Kafka的JSON資料格式大致如下。
{ "id": 765, "first_name": "Barry", "last_name": "Pollich", "address": { "country": "United Arab Emirates", "state": "Nevada", "city": "Powlowskifurt" } }
步驟三:建立Hologres Catalog
單表同步都需要依賴目標Catalog來建立目標表。因此,您需要通過控制台建立目標Catalog。本文將以目標Catalog為Hologres Catalog為例,為您進行介紹。關鍵配置資訊如下,具體操作步驟請參見建立Hologres Catalog。
配置項 | 說明 |
catalog name | 填寫holo。 |
endpoint | 在Hologres執行個體詳情頁面擷取網路類型為指定VPC的網域名稱資訊。 |
username | 阿里雲帳號的AccessKey。 |
password | 阿里雲帳號的AccessSecret。 |
dbname | 填寫flink_test_db。 重要 您需要在您的目標Hologres執行個體中已建立flink_test_db資料庫,否則建立Catalog會報錯。具體操作請參見建立資料庫。 |
步驟四:建立並啟動資料同步作業
登入Realtime Compute開發控制台,建立資料同步作業。
單擊目標工作空間操作列下的控制台。
在左側導覽列,單擊,單擊建立。
在新增作業草稿對話方塊,選擇目標模板(例如:選擇空白的流作業草稿),完成後單擊下一步,填寫作業配置資訊。
作業參數
樣本
說明
檔案名稱
flink-quickstart-test
作業的名稱。
說明作業名稱在當前專案中必須保持唯一。
儲存位置
作業草稿
指定該作業的代碼檔案所屬的檔案夾。預設存放在作業草稿目錄。
您還可以在現有檔案夾右側,單擊
表徵圖,建立子檔案夾。引擎版本
vvr-8.0.11-flink-1.17
在引擎版本下拉式清單中選擇目標引擎版本。
單擊建立。
編寫SQL作業。將以下作業代碼拷貝到作業文本編輯區,然後根據實際配置,修改參數配置資訊。
將訊息佇列Kafka中名稱為users的Topic資料同步至Hologres的flink_test_db資料庫的sync_kafka_users表中。您可以通過以下任意一種方式完成資料同步。
通過CTAS語句同步
該方式無需您手動在Hologres中建立sync_kafka_users表,也無需指明對應的列類型為JSON或JSONB。
CREATE TEMPORARY TABLE kafka_users ( `id` INT NOT NULL, `address` STRING, `offset` BIGINT NOT NULL METADATA, `partition` BIGINT NOT NULL METADATA, `timestamp` TIMESTAMP METADATA, `date` AS CAST(`timestamp` AS DATE), `country` AS JSON_VALUE(`address`, '$.country'), PRIMARY KEY (`partition`, `offset`) NOT ENFORCED ) WITH ( 'connector' = 'kafka', 'properties.bootstrap.servers' = 'alikafka-host1.aliyuncs.com:9092,alikafka-host2.aliyuncs.com:9092,alikafka-host3.aliyuncs.com:9092', 'topic' = 'users', 'format' = 'json', 'json.infer-schema.flatten-nested-columns.enable' = 'true', -- 自動延伸嵌套列。 'scan.startup.mode' = 'earliest-offset' ); CREATE TABLE IF NOT EXISTS holo.flink_test_db.sync_kafka_users WITH ( 'connector' = 'hologres' ) AS TABLE kafka_users;說明為了避免作業Failover後,作業重啟將重複資料寫入到Hologres中,您可以添加相關主鍵從而唯一地標識資料。當資料重發時,Hologres將會保證相同partition和offset的資料只會保留一份。
需要修改的參數配置資訊如下:
參數
樣本值
說明
properties.bootstrap.servers
alikafka-host1.aliyuncs.com:9092,alikafka-host2.aliyuncs.com:9092,alikafka-host3.aliyuncs.com:9092
Kafka Broker地址。
格式為host:port,host:port,host:port,以英文逗號(,)分割。您可以在執行個體詳情頁面的存取點資訊地區擷取網路類型為VPC的網域名稱存取點作為該參數的值。
topic
users
Kafka Topic名稱。
通過INSERT INTO語句同步
考慮到Hologres中對於JSON和JSONB類型的資料會進行特殊的最佳化,您也可以通過INSERT INTO語句將嵌套JSON寫入到Hologres中。
該方式需要您手動在Hologres中建立sync_kafka_users表,然後通過下文的SQL將資料寫入到Hologres的表中。
CREATE TEMPORARY TABLE kafka_users ( `id` INT NOT NULL, `address` STRING, -- 該列對應的資料為嵌套JSON。 `offset` BIGINT NOT NULL METADATA, `partition` BIGINT NOT NULL METADATA, `timestamp` TIMESTAMP METADATA, `date` AS CAST(`timestamp` AS DATE), `country` AS JSON_VALUE(`address`, '$.country') ) WITH ( 'connector' = 'kafka', 'properties.bootstrap.servers' = 'alikafka-host1.aliyuncs.com:9092,alikafka-host2.aliyuncs.com:9092,alikafka-host3.aliyuncs.com:9092', 'topic' = 'users', 'format' = 'json', 'json.infer-schema.flatten-nested-columns.enable' = 'true', -- 自動延伸嵌套列。 'scan.startup.mode' = 'earliest-offset' ); CREATE TEMPORARY TABLE holo ( `id` INT NOT NULL, `address` STRING, `offset` BIGINT, `partition` BIGINT, `timestamp` TIMESTAMP, `date` DATE, `country` STRING ) WITH ( 'connector' = 'hologres', 'endpoint' = 'hgpostcn-****-cn-beijing-vpc.hologres.aliyuncs.com:80', 'username' = '************************', 'password' = '******************************', 'dbname' = 'flink_test_db', 'tablename' = 'sync_kafka_users' ); INSERT INTO holo SELECT * FROM kafka_users;需要修改的參數配置資訊如下:
參數
樣本值
說明
properties.bootstrap.servers
alikafka-host1.aliyuncs.com:9092,alikafka-host2.aliyuncs.com:9092,alikafka-host3.aliyuncs.com:9092
Kafka Broker地址。
格式為host:port,host:port,host:port,以英文逗號(,)分割。您可以在執行個體詳情頁面的存取點資訊地區擷取網路類型為VPC的網域名稱存取點作為該參數的值。
topic
users
Kafka Topic名稱。
endpoint
hgpostcn-****-cn-beijing-vpc.hologres.aliyuncs.com:80
Hologres端點。
格式為<ip>:<port>。您可以在Hologres執行個體詳情頁面擷取網路類型為指定VPC的網域名稱資訊作為該參數的值。
username
************************
Hologres使用者名稱和密碼,請填寫阿里雲帳號的AccessKey ID和AccessKey Secret。
重要為了避免您的AK資訊泄露,建議您通過密鑰管理的方式填寫AccessKey ID取值,詳情請參見變數管理。
password
******************************
dbname
flink_test_db
Hologres資料庫名稱。
tablename
sync_kafka_users
Hologres表名稱。
說明如果您通過INSERT INTO方式同步資料,則需要提前在目標執行個體的資料庫中建立sync_kafka_users表和欄位。
如果Schema不為Public時,則tablename需要填寫為schema.tableName。
單擊儲存。
在頁面,單擊部署。
在頁面,單擊目標作業名稱操作列中的啟動。關於作業啟動的配置說明,請參見作業啟動。
作業啟動後,您可以在作業營運介面觀察作業的運行資訊和狀態。
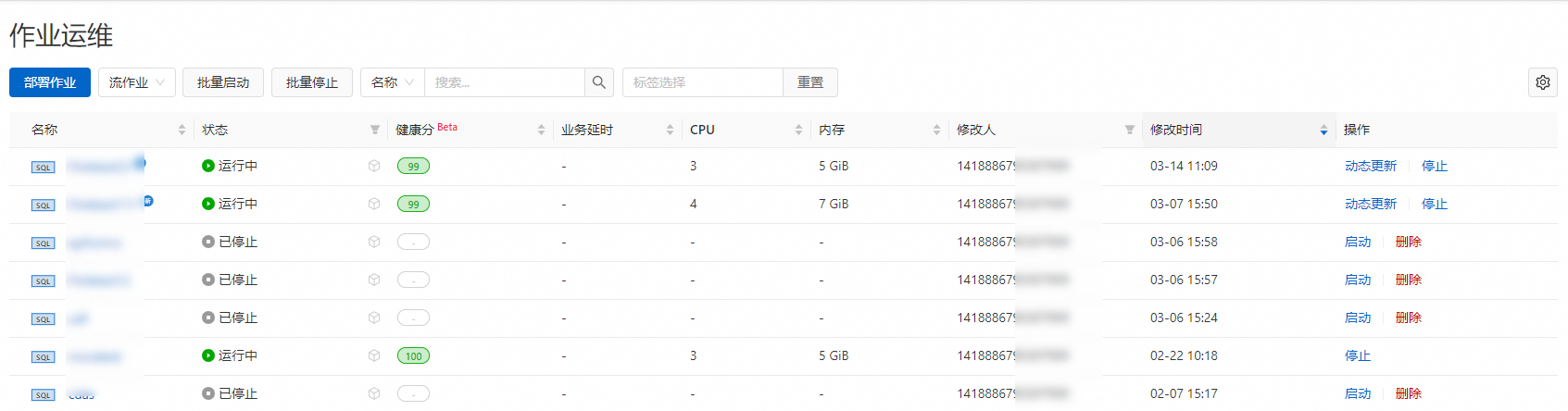
步驟五:觀察全量同步結果
在執行個體列表頁面,單擊目標執行個體名稱。
在頁面右上方,單擊登入執行個體。
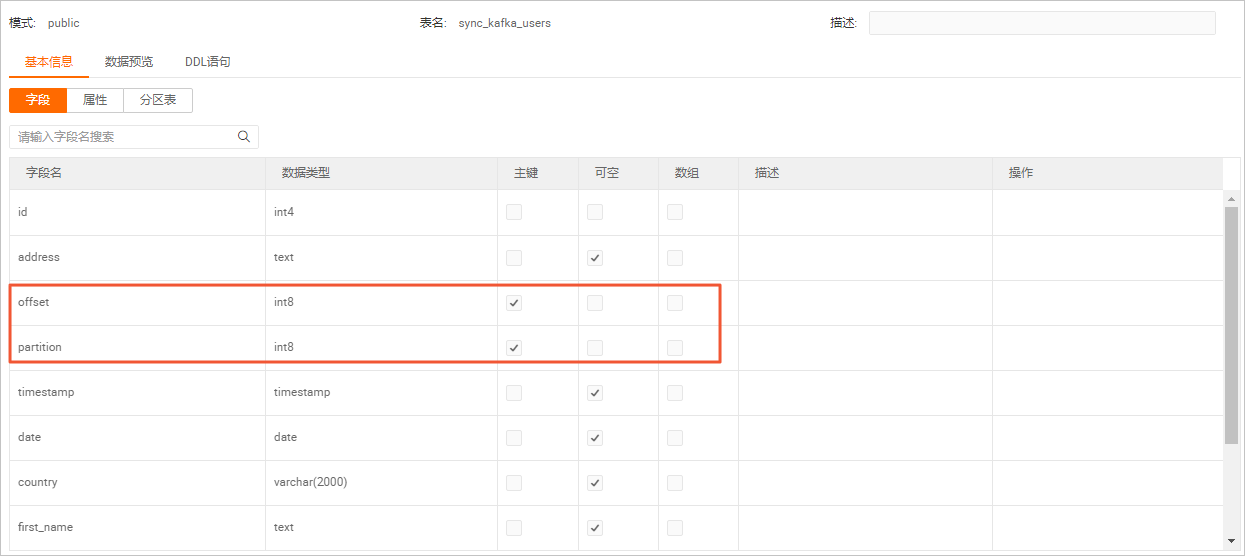
在中繼資料管理頁簽,查看users資料庫中同步的sync_kafka_users表結構和資料。

同步後的表結構和資料如下圖所示。
表結構
雙擊sync_kafka_users表名稱,查看錶結構。
 說明
說明在同步過程中,建議聲明Kafka的Metadata partition和offset作為Hologres表中的主鍵。這樣可以避免由於作業Failover,資料重發導致下遊儲存多份相同資料。
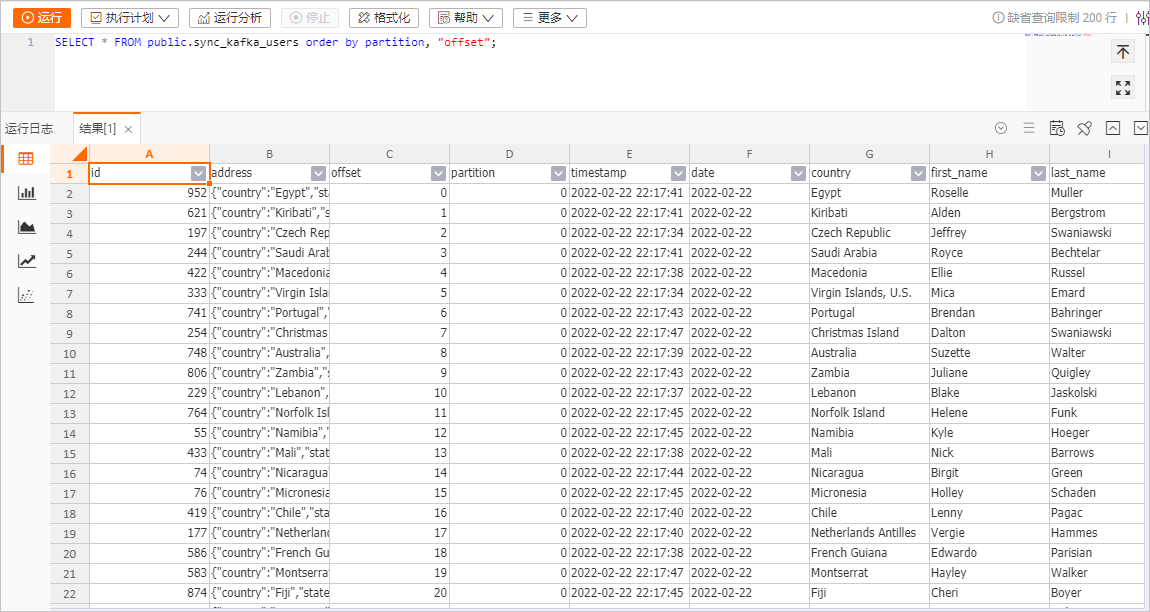
表資料
在sync_kafka_users表資訊頁面右上方,單擊查詢表後,輸入如下命令,單擊運行。
SELECT * FROM public.sync_kafka_users order by partition, "offset";表資料結果如下圖所示。
步驟六:觀察自動同步表結構變更
在Kafka控制台手動發送一條包含新增列的訊息。
在執行個體列表頁面,單擊目標執行個體名稱。
在Topic管理頁面,單擊目標Topic名稱users。
單擊體驗發送訊息。
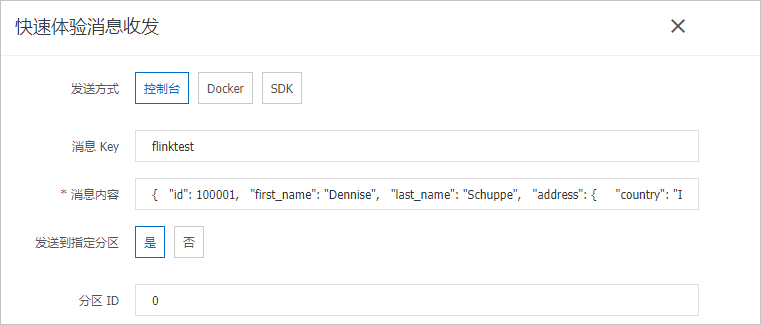
填寫訊息內容。
配置項
樣本
發送方式
選中控制台。
訊息Key
填寫為flinktest。
訊息內容
將以下JSON內容複寫粘貼到訊息內容中。
{ "id": 100001, "first_name": "Dennise", "last_name": "Schuppe", "address": { "country": "Isle of Man", "state": "Montana", "city": "East Coleburgh" }, "house-points": { "house": "Pukwudgie", "points": 76 } }說明該樣本中house-points是一個新增的嵌套列。
發送到指定分區
選中是。
分區ID
填寫為0。
單擊確定。
在Hologres控制台,查看sync_kafka_users表結構和資料的變化。
在執行個體列表頁面,單擊目標執行個體名稱。
在頁面右上方,單擊登入執行個體。
在中繼資料管理頁簽,雙擊sync_kafka_users表名稱。
單擊查詢表後,輸入如下命令,單擊運行。
SELECT * FROM public.sync_kafka_users order by partition, "offset";查看錶資料結果。
表資料結果如下圖所示。
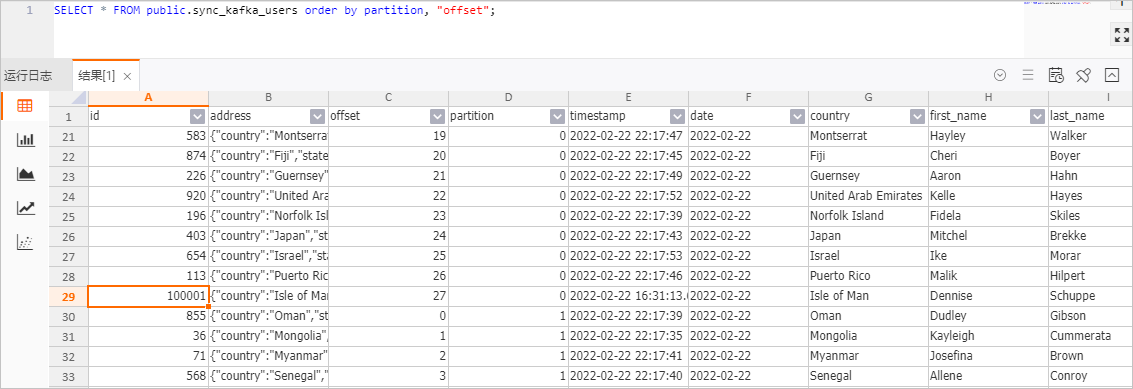
可以觀察到id為100001的資料已經成功地寫入到了Hologres中。同時,Hologres中多了house-points.house和house-points.points 兩列。
說明雖然插入到Kafka中的資料只有一個嵌套列house-points,但是由於在kafka_users表的WITH參數內聲明要求json.infer-schema.flatten-nested-columns.enable,那麼Flink 就會自動展平新增的嵌套列,並用訪問該列的路徑作為展開後的列的名字。
相關文檔
CREATE TABLE AS (CTAS) 文法功能介紹,請參見CREATE TABLE AS(CTAS)語句。
訊息佇列Kafka作為源表或者結果表使用的功能介紹,請參見訊息佇列Kafka。
如果您需要調整節點的並發度和資源來提升作業效能,請參見配置作業部署資訊。