如果您在使用PolarDB MySQL遇到查詢慢的問題時,可以通過Data Transmission Service將企業線上的PolarDB MySQL中的生產資料即時同步到Elasticsearch(簡稱ES)中進行搜尋分析。DTS同步適用於對即時同步要求較高的關係型資料庫中資料的同步情境。
背景資訊
本文涉及以下三個雲產品,相關介紹如下:
Data Transmission Service:一種集資料移轉、資料訂閱及資料即時同步於一體的Data Transmission Service。DTS支援同步的SQL操作包括:Insert、Delete、Update。 詳情請參見Data Transmission Service、同步方案概覽。
PolarDB:阿里雲自研的下一代關係型雲資料庫,有三個獨立的引擎,分別可以100%相容MySQL、100%相容PostgreSQL、高度相容Oracle文法。儲存容量最高可達100TB,單庫最多可擴充到16個節點,適用於企業多樣化的資料庫應用情境。詳情請參見PolarDB MySQL概述。
Elasticsearch:一個基於Lucene的即時分布式的搜尋與分析引擎,它提供了一個分布式服務,可以使您快速的近乎於准即時的儲存、查詢和分析超巨量資料集,通常被用來作為構建複雜查詢特性和需求強大應用的基礎引擎或技術。詳情請參見什麼是Elasticsearch。
注意事項
DTS不支援同步DDL操作,如果源庫中待同步的表在同步的過程中已經執行了DDL操作,您需要先移除同步對象,然後在ES執行個體中移除該表對應的索引,最後新增同步對象。詳情請參見移除同步對象和新增同步對象。
如果源庫中待同步的表需要執行增加列的操作,您只需先在ES執行個體中修改對應表的mapping,然後在源庫中執行相應的DDL操作,最後暫停並啟動DTS增量資料同步任務。
DTS在執行全量資料初始化時將佔用源庫和目標庫一定的讀寫資源,可能會導致資料庫的負載上升,在資料庫效能較差、規格較低或業務量較大的情況下(例如源庫有大量慢SQL、存在無主鍵表或目標庫存在死結等),可能會加重資料庫壓力,甚至導致資料庫服務不可用。因此您需要在執行資料同步前評估源庫和目標庫的效能,同時建議您在業務低峰期執行資料同步(例如源庫和目標庫的CPU負載在30%以下)。
在業務高峰期全量同步資料,可能造成全量資料同步失敗,重啟全量同步任務即可。
在業務高峰期增量同步處理資料,可能出現資料同步延遲的情況。
操作步驟
完成資料同步主要包括兩個步驟:
準備環境:在源庫PolarDB MySQL中準備待同步資料,然後建立目標庫ES執行個體,並為ES執行個體開啟自動建立索引功能。
建立資料同步任務:在DTS控制台建立源庫到目標庫的資料同步鏈路,購買並啟動同步鏈路任務後資料會自動進行全量和增量同步處理。
步驟一:環境準備
文本以將PolarDB MySQL 8.0.1企業版叢集中的資料同步到阿里雲ES 7.10版本執行個體中為例。
準備源庫待同步資料
建立PolarDB MySQL 8.0.1企業版叢集。具體操作,請參見購買企業版叢集。
為PolarDB MySQL叢集開啟Binlog功能。具體操作,請參見開啟Binlog。
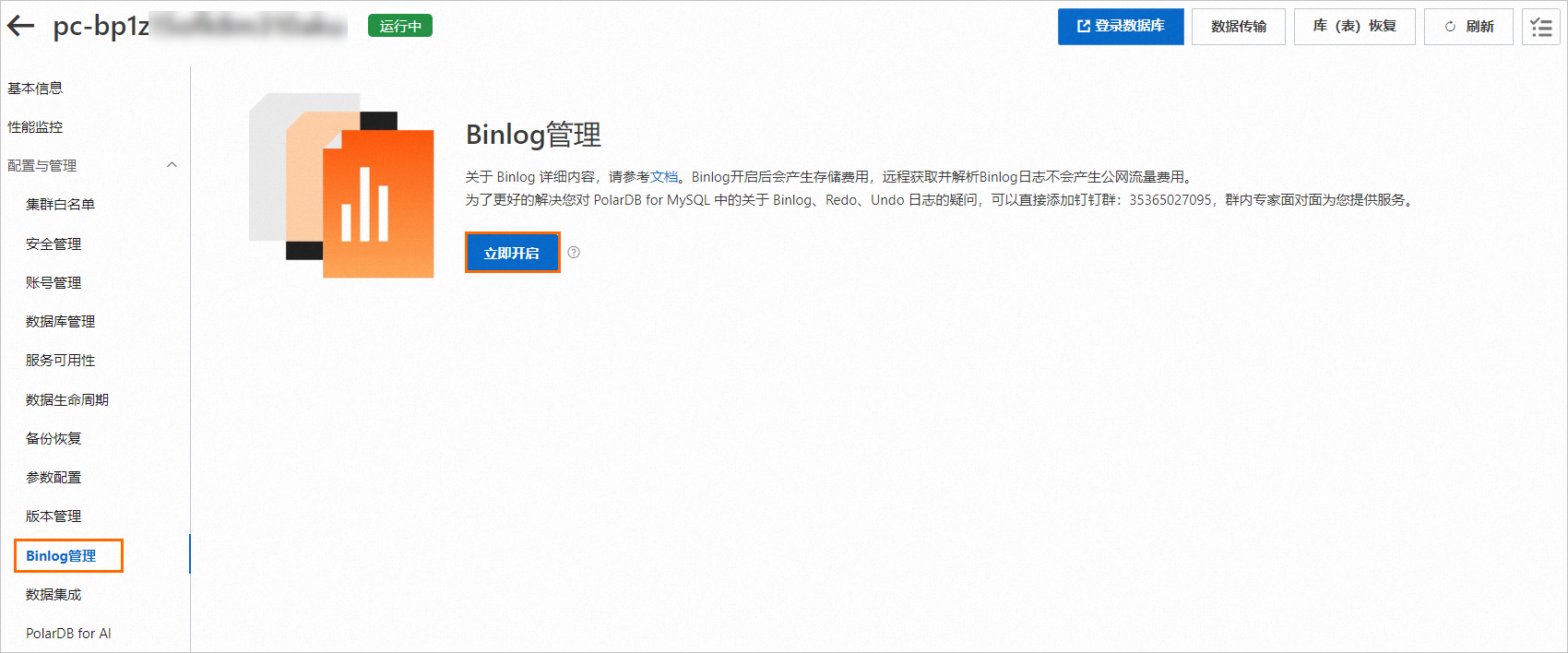
建立帳號和資料庫
test_polardb。 具體操作,請參見建立和管理資料庫帳號、管理資料庫。在資料庫
test_polardb中,建立表product並插入資料。建表語句
CREATE TABLE `product` ( `id` bigint(32) NOT NULL AUTO_INCREMENT, `name` varchar(32) NULL, `price` varchar(32) NULL, `code` varchar(32) NULL, `color` varchar(32) NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8;插入測試資料
INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (1,'mobile phone A','2000','amp','golden'); INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (2,'mobile phone B','2200','bmp','white'); INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (3,'mobile phone C','2600','cmp','black'); INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (4,'mobile phone D','2700','dmp','red'); INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (5,'mobile phone E','2800','emp','silvery');
準備目標庫ES執行個體
建立阿里雲ES 7.10版本執行個體。具體操作,請參見建立Elasticsearch執行個體。
ES執行個體開啟自動建立索引功能。具體操作,請參見配置YML參數。

步驟二:建立資料同步任務
單擊建立任務。
按照頁面提示配置資料同步任務。
以下步驟中涉及的參數的說明,請參見PolarDB MySQL為源的資料同步。
配置源庫及目標庫,在頁面下方單擊測試連接以進行下一步。
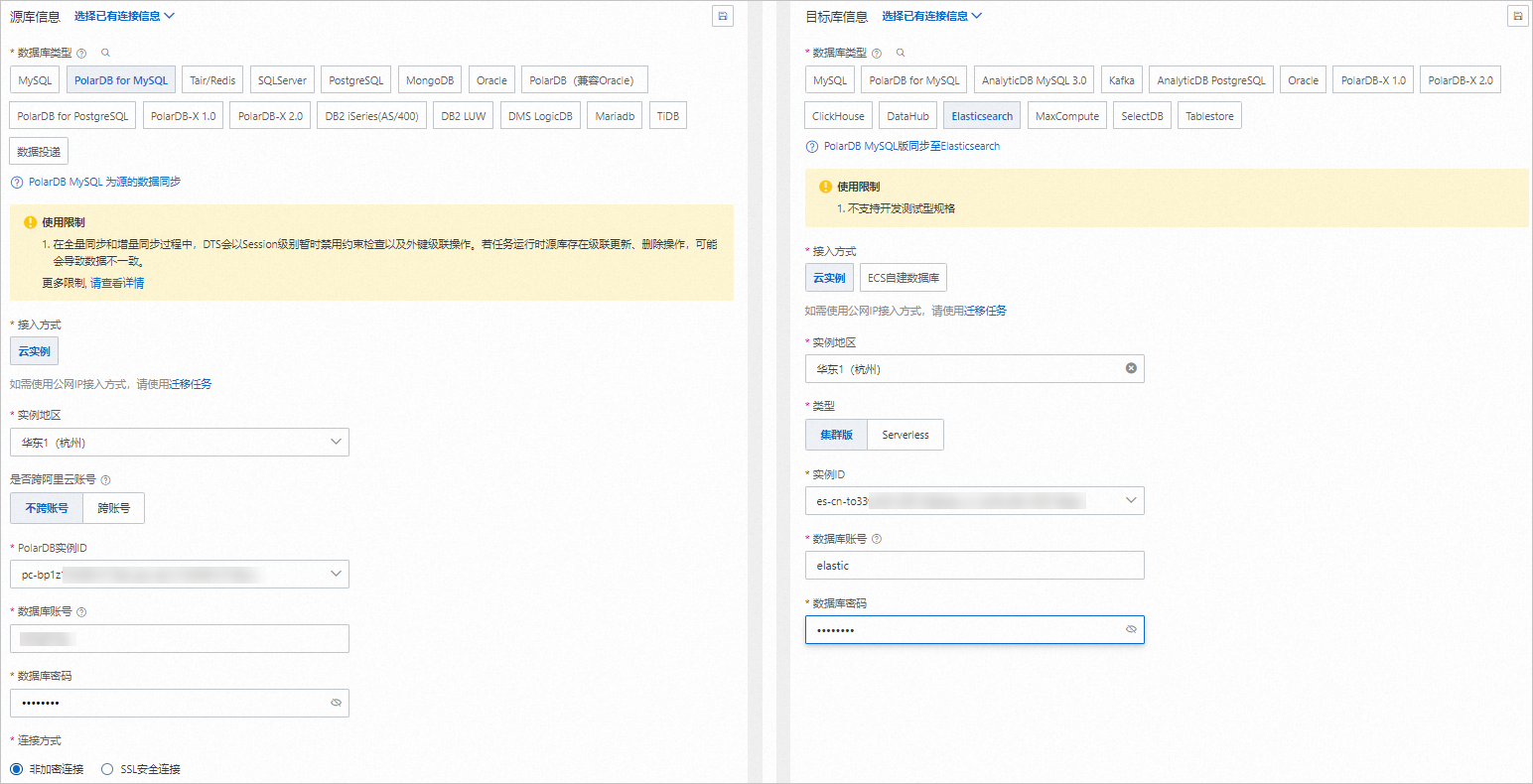
配置任務對象。
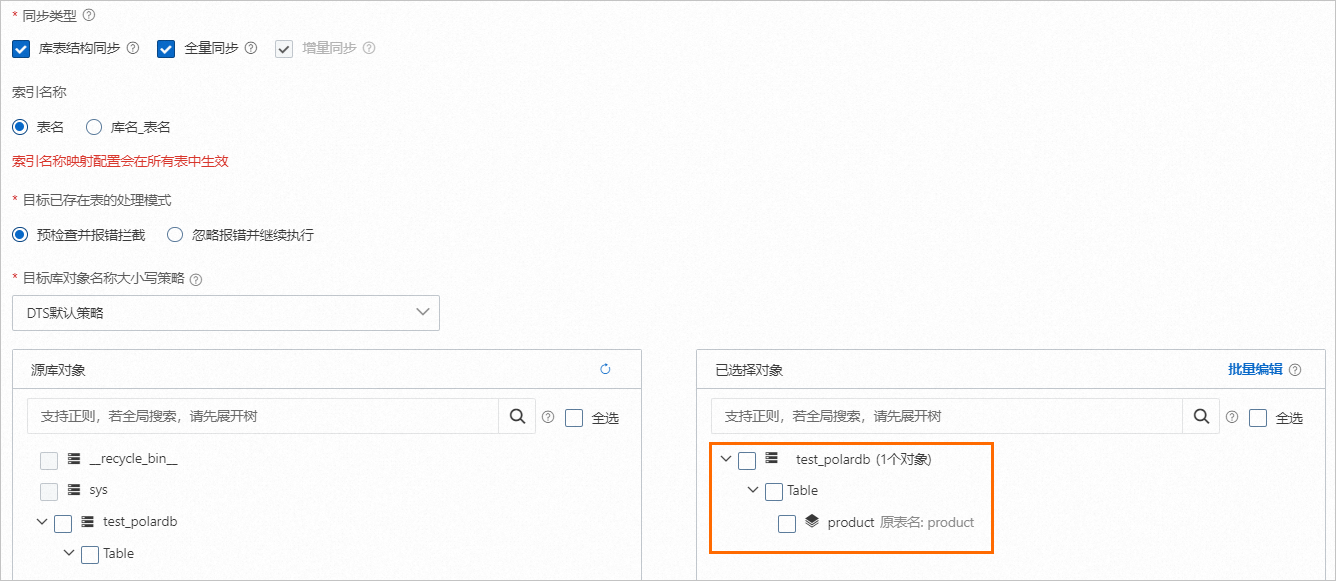
配置進階設定,本文進階配置保持預設。
在庫表列配置頁面,單擊全部設定為非_routing策略,將全部表設定為非_routing策略。
說明目標庫ES執行個體為7.x版本時,全部表必須設定為非_routing策略。
配置完成後,根據頁面提示儲存並預檢查任務、購買並啟動任務。
購買並啟動任務成功後,同步任務正式開始。您可在資料同步介面查看具體任務進度,待全量同步完成後,您即可在ES執行個體中查看同步成功的資料。

步驟三(可選):驗證資料同步結果
登入目標ES執行個體的Kibana控制台。
登入Kibana控制台,請參見登入Kibana控制台。
在Kibana頁面的左上方,選擇
 > Management > 開發工具(Dev Tools),在控制台(Console)中執行以下命令。
> Management > 開發工具(Dev Tools),在控制台(Console)中執行以下命令。驗證全量資料同步結果。
執行以下命令,查看全量資料同步結果。
GET /product/_search預期結果如下:
{ "took" : 3, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "product", "_type" : "product", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "mobile phone C", "price" : "2600", "code" : "cmp", "color" : "black" } }, { "_index" : "product", "_type" : "product", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "mobile phone E", "price" : "2800", "code" : "emp", "color" : "silvery" } }, { "_index" : "product", "_type" : "product", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "mobile phone D", "price" : "2700", "code" : "dmp", "color" : "red" } }, { "_index" : "product", "_type" : "product", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "mobile phone B", "price" : "2200", "code" : "bmp", "color" : "white" } }, { "_index" : "product", "_type" : "product", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "mobile phone A", "price" : "2000", "code" : "amp", "color" : "golden" } } ] } }驗證增量資料同步結果。
通過以下SQL語句,在PolarDB MySQL叢集中插入一條資料。
INSERT INTO `test_polardb`.`product` (`id`,`name`,`price`,`code`,`color`) VALUES (6,'mobile phone F','2750','fmp','white');等待增量同步處理完成後,再次執行命令
GET /product/_search,查看增量資料同步結果。預期結果如下:
{ "took" : 439, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "product", "_type" : "product", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "mobile phone C", "price" : "2600", "code" : "cmp", "color" : "black" } }, { "_index" : "product", "_type" : "product", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "mobile phone E", "price" : "2800", "code" : "emp", "color" : "silvery" } }, { "_index" : "product", "_type" : "product", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "mobile phone D", "price" : "2700", "code" : "dmp", "color" : "red" } }, { "_index" : "product", "_type" : "product", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "mobile phone B", "price" : "2200", "code" : "bmp", "color" : "white" } }, { "_index" : "product", "_type" : "product", "_id" : "6", "_score" : 1.0, "_source" : { "code" : "fmp", "color" : "white", "price" : "2750", "name" : "mobile phone F", "id" : 6 } }, { "_index" : "product", "_type" : "product", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "mobile phone A", "price" : "2000", "code" : "amp", "color" : "golden" } } ] } }