Serverless K8s支援Pod粒度的彈性,具有秒級啟動、秒級計費、2000每分鐘的並發等優勢,因此越來越多的使用者開始使用Serverless K8s來運行Argo。本文介紹如何基於ACK叢集,使用ECI運行Argo工作流程。
搭建Kubernetes+Argo環境
搭建阿里雲Serverless K8s叢集。
(推薦)建立ACK Serverless叢集。具體操作,請參見建立叢集。
建立ACK叢集,並部署ack-virtual-node組件產生虛擬節點。具體操作,請參見建立ACK託管叢集和通過虛擬節點將Pod調度到ECI上運行。
在Kubernetes叢集中部署Argo。
(推薦)安裝ack-workflow組件。具體操作,請參見ack-workflow。
自行部署Argo。具體操作,請參見Argo Quick Start。
安裝Argo命令。具體操作,請參見argo-workflows。
最佳化基礎資源配置
預設情況下,完成Argo部署後,argo-server和workflow-controller這兩個核心組件並沒有指定對應Pod的resources,這會導致這兩個組件對應Pod的QoS層級較低,在叢集資源不足時會出現組件OOM Kill、Pod被驅逐的情況。因此,建議您根據自身叢集規模調整上述兩個組件對應Pod的resources,建議其requests或limits設定在2 vCPU,4 GiB記憶體及以上。
使用OSS作為artifacts倉庫
預設情況下,Argo使用minio作為artifacts倉庫,在生產環境中則需要考慮artifacts倉庫的穩定性,ack-workflow支援使用OSS作為artifacts倉庫。關於如何配置OSS作為artifacts倉庫,請參見Configuring Alibaba Cloud OSS。
配置成功後,您可以使用以下樣本建立Wokrflow進行驗證。
將以下內容儲存為workflow-oss.yaml。
apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: artifact-passing- spec: entrypoint: artifact-example templates: - name: artifact-example steps: - - name: generate-artifact template: whalesay - - name: consume-artifact template: print-message arguments: artifacts: # bind message to the hello-art artifact # generated by the generate-artifact step - name: message from: "{{steps.generate-artifact.outputs.artifacts.hello-art}}" - name: whalesay container: image: docker/whalesay:latest command: [sh, -c] args: ["cowsay hello world | tee /tmp/hello_world.txt"] outputs: artifacts: # generate hello-art artifact from /tmp/hello_world.txt # artifacts can be directories as well as files - name: hello-art path: /tmp/hello_world.txt - name: print-message inputs: artifacts: # unpack the message input artifact # and put it at /tmp/message - name: message path: /tmp/message container: image: alpine:latest command: [sh, -c] args: ["cat /tmp/message"]建立Workflow。
argo -n argo submit workflow-oss.yaml查看Workflow的執行結果。
argo -n argo list預期返回:

選擇Executor
Argo建立的每個工作Pod中至少會有以下兩個容器:
main容器
實際的業務容器,真正運行商務邏輯。
wait容器
Argo的系統組件,以Sidecar的形式注入到Pod內。其核心作用如下:
啟動階段
載入main容器依賴的artifacts、inputs。
運行階段
等待main容器退出,Kill關聯的Sidecars容器。
收集main容器的outputs、artifacts,上報main容器狀態
Executor是wait容器訪問和控制main容器的“橋樑”,Argo將其抽象為ContainerRuntimeExecutor,其介面定義如下:
GetFileContents:擷取main容器的輸出參數(outputs/parameters)。
CopyFile:擷取main容器的產物(outputs/artifacts)。
GetOutputStream:擷取main的標準輸出(含標準錯誤)。
Wait:等待main容器退出。
Kill:Kill關聯的Sidecar容器。
ListContainerNames:列舉Pod內容器的名稱列表。
目前Argo已支援多種Executor,其工作原理不同,但都是針對原生K8s架構設計的。由於阿里雲Serverless K8s與原生K8s在架構上存在差異,因此需要選擇合適的Executor。建議您選擇Emisarry作為Serverless K8s情境運行Argo的Executor,相關說明如下:
Executor | 說明 |
Emisarry | 通過EmptyDir共用檔案的方式實現相關能力,依賴EmptyDir。 由於該Executor僅依賴標準能力EmptyDir,無其他依賴,因此推薦使用該Executor。 |
Kubernetes API | 通過Kubernetes API方式實現相關功能,依賴Kubernetes API但功能不完整。 由於該Executor功能不完整,且在大規模情境中會給K8s控制層面帶來壓力,影響叢集規模,因此不推薦使用該Executor。 |
PNS | 基於Pod內的PID共用和chroot實現相關功能,會汙染Pod的進程空間,並且依賴特權。 由於Serverless K8s具有更高的安全隔離性,不支援使用特權,因此無法使用該Executor。 |
Docker | 通過Docker CLI實現相關功能,依賴底層容器運行時Docker。 由於Serverless K8s沒有真實節點,不支援訪問節點上的Docker組件,因此無法使用該Executor。 |
Kubelet | 通過Kubelet Client API實現相關功能,依賴Kubernetes底層組件Kubelet。 由於Serverless K8s沒有真實節點,不支援訪問節點上的Kubelet組件,因此無法使用該Executor。 |
調度Argo任務到ECI
ACK Serverless叢集預設會將所有Pod都調度到ECI,因此不需要額外配置。ACK叢集需要配置後才能將Pod調度到ECI,具體配置方式請參見調度Pod到x86架構的虛擬節點。
以下YAML以配置Label的方式為例:
添加
alibabacloud.com/eci: "true"的Label:添加相應Label後,Pod會被自動調度到ECI。(可選)指定
{"schedulerName": "eci-scheduler"}:建議配置,虛擬節點(VK)升級或變更時,WebHook會有短暫不可用,配置後可以避免Pod調度到普通節點。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: parallelism-limit1-
spec:
entrypoint: parallelism-limit1
parallelism: 10
podSpecPatch: '{"schedulerName": "eci-scheduler"}' #指定調度到ECI
podMetadata:
labels:
alibabacloud.com/eci: "true" #配置Label將Pod調度到ECI
templates:
- name: parallelism-limit1
steps:
- - name: sleep
template: sleep
withSequence:
start: "1"
end: "10"
- name: sleep
container:
image: alpine:latest
command: ["sh", "-c", "sleep 30"]提升Pod建立成功率
在生產環境中,運行一條Argo工作流程通常會涉及到多個計算Pod,工作流程中的任意一個Pod失敗都會導致整條工作流程失敗。如果Argo工作流程的成功率不高,您就需要多次重新運行Argo工作流程,這不僅影響任務的執行效率,也會增加計算成本。因此,您需要採取一些策略來提升Pod成功率:
定義Argo工作流程時
建立ECI Pod時
配置多可用性區域,避免因可用性區域庫存不足導致Pod建立失敗。具體操作,請參見多可用性區域建立Pod、
指定多規格,避免因特定規格庫存不足導致Pod建立時報。具體操作,請參見多規格建立Pod。
優先使用指定vCPU和記憶體的方式建立Pod,ECI會自動根據庫存情況匹配符合要求的規格。
使用2 vCPU,4 GiB及以上規格建立Pod,這類規格執行個體都是獨佔的企業級執行個體,可以確保效能的穩定性。
設定Pod故障處理策略,設定Pod建立失敗後是否嘗試重新建立。具體操作,請參見設定ECI Pod的故障處理策略。
配置樣本如下:
編輯eci-profile配置多可用性區域。
kubectl edit -n kube-system cm eci-profile在
data中配置vSwitchIds的值為多個交換器ID:data: ...... vSwitchIds: vsw-2ze23nqzig8inprou****,vsw-2ze94pjtfuj9vaymf**** #指定多個交換器ID來配置多可用性區域 vpcId: vpc-2zeghwzptn5zii0w7**** ......建立Pod時使用多個策略提升成功率。
配置
k8s.aliyun.com/eci-use-specs指定多種規格,本樣本指定了三個規格,匹配順序依次為ecs.c6.large、ecs.c5.large、2-4Gi。配置
k8s.aliyun.com/eci-schedule-strategy設定多可用性區域調度策略,本樣本使用VSwitchRandom,表示隨機調度。配置
retryStrategy設定Argo重試策略,本樣本設定retryPolicy: "Always",表示重試所有失敗的步驟。配置
k8s.aliyun.com/eci-fail-strategy設定Pod故障處理策略,本樣本使用fail-fast,表示快速失敗。Pod建立失敗後直接報錯。Pod顯示為ProviderFailed狀態,由上層編排決定是否重試,或者把Pod建立調度到普通節點。
apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: parallelism-limit1- spec: entrypoint: parallelism-limit1 parallelism: 10 podSpecPatch: '{"schedulerName": "eci-scheduler"}' podMetadata: labels: alibabacloud.com/eci: "true" annotations: k8s.aliyun.com/eci-use-specs: "ecs.c6.large,ecs.c5.large,2-4Gi" k8s.aliyun.com/eci-schedule-strategy: "VSwitchRandom" k8s.aliyun.com/eci-fail-strategy: "fail-fast" templates: - name: parallelism-limit1 steps: - - name: sleep template: sleep withSequence: start: "1" end: "10" - name: sleep retryStrategy: limit: "3" retryPolicy: "Always" container: image: alpine:latest command: [sh, -c, "sleep 30"]
最佳化Pod使用成本
ECI支援多種計費方式,對於不同的業務負載,合理規劃其計費方式可以有效降低計算資源的使用成本。
具體最佳化成本的方式請參見:
加速Pod建立
啟動Pod時需要先拉取您指定的容器鏡像,但因網路和容器鏡像大小等因素,鏡像拉取耗時往往成了Pod啟動的主要耗時。為加速ECI Pod的建立速度,ECI提供鏡像緩衝功能。您可以預先將需要使用的鏡像製作成鏡像緩衝,然後基於該鏡像緩衝來建立ECI Pod,以此來避免或者減少鏡像層的下載,從而提升Pod建立速度。
鏡像緩衝分為以下兩類:
自動建立:ECI預設已開啟自動建立鏡像緩衝功能。建立ECI Pod時,如果沒有完全符合的鏡像,ECI會自動使用該Pod對應的鏡像製作鏡像緩衝。
手動建立:支援通過CRD的方式
執行高並發Argo任務前建議先手動建立鏡像緩衝。鏡像緩衝完成建立後,指定該鏡像緩衝,並將Pod的鏡像拉取原則設定為IfNotPresent,實現Pod在啟動階段無需拉取鏡像,可以加速Pod建立,縮短Argo任務的運行時間長度,降低運行成本。更多資訊,請參見使用ImageCache加速建立Pod。
如果之前已經執行了上文的樣本進行測試,則目前ECI已經自動建立了鏡像緩衝,您可以登入Elastic Container Instance控制台查看鏡像緩衝狀態。基於已有的鏡像緩衝,您可以使用以下YAML建立Wokrflow,以此測試Pod啟動速度。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: parallelism-limit1-
spec:
entrypoint: parallelism-limit1
parallelism: 100
podSpecPatch: '{"schedulerName": "eci-scheduler"}'
podMetadata:
labels:
alibabacloud.com/eci: "true"
annotations:
k8s.aliyun.com/eci-use-specs: "ecs.c6.large,ecs.c5.large,2-4Gi"
k8s.aliyun.com/eci-schedule-strategy: "VSwitchRandom"
k8s.aliyun.com/eci-fail-strategy: "fail-fast"
templates:
- name: parallelism-limit1
steps:
- - name: sleep
template: sleep
withSequence:
start: "1"
end: "100"
- name: sleep
retryStrategy:
limit: "3"
retryPolicy: "Always"
container:
imagePullPolicy: IfNotPresent
image: alpine:latest
command: [sh, -c, "sleep 30"]建立成功後,從Wokrflow對應的ECI Pod的事件中,可以看到匹配到的鏡像緩衝ID,且Pod啟動時跳過了鏡像拉取過程。

加速資料載入
Argo廣泛應用於AI推理領域,計算任務通常需要訪問大量的資料,在目前流行的存算分離的架構中,計算節點載入資料的效率會直接影響整批任務的耗時和成本。如果Argo任務需要大量並發訪問儲存中的資料,儲存的頻寬和效能會成為瓶頸。以OSS為例,當Argo任務並發載入OSS中的資料,OSS Bucket的頻寬達到瓶頸時,Argo任務的每個計算節點都會阻塞在資料載入階段,導致每個計算節點耗時延長,不僅影響計算效率,也會增加計算成本。
對於上述問題,資料加速Fluid可以有效改善這類問題。執行批次運算之前,您可以先建立Fluid Dataset並進行預熱,將OSS中的資料預緩衝到少量的緩衝節點,然後再啟動並發的Argo任務。使用Fluid後,Argo任務從緩衝節點讀取資料,緩衝節點可以擴充OSS的頻寬,提升計算節點的資料載入效率,最終提升Argo任務的執行效率,降低Argo任務的運行成本。更多關於Fluid的資訊,請參見資料加速Fluid概述。
配置樣本如下,以下樣本示範100個並發任務從OSS載入10 GB的測試檔案並計算MD5。
部署Fluid。
在左側導覽列,選擇市場>應用市場。
找到ack-fluid,單擊對應的卡片。
在ack-fluid頁面,單擊一鍵部署。
在彈出面板選擇目的地組群,並完成參數配置,單擊確定。
部署完成後,將自動轉到ack-fluid發布詳情頁面,返回Helm頁面可以看到ack-fluid的狀態為已部署;您也可以通過kubectl命令檢查Fluid是否部署成功。

準備測試資料。
部署Fluid後可以通過Fluid的Dataset實現資料加速。執行後續操作前,需要在OSS Bucket中上傳一個10 GB的測試檔案。
產生測試檔案。
dd if=/dev/zero of=/test.dat bs=1G count=10上傳測試檔案到OSS Bucket。具體操作,請參見上傳檔案。
建立加速資料集。
建立Dataset和JindoRuntime。
kubectl -n argo apply -f dataset.yamldataset.yaml的內容樣本如下,請根據實際情況替換YAML中的AccessKey和OSS Bucket資訊等。
apiVersion: v1 kind: Secret metadata: name: access-key stringData: fs.oss.accessKeyId: *************** # 有許可權訪問OSS Bucket的AccessKeyID fs.oss.accessKeySecret: ****************** # 有許可權訪問OSS Bucket的AccessKeySecret --- apiVersion: data.fluid.io/v1alpha1 kind: Dataset metadata: name: serverless-data spec: mounts: - mountPoint: oss://oss-bucket-name/ # 您的OSS Bucket路徑 name: demo path: / options: fs.oss.endpoint: oss-cn-shanghai-internal.aliyuncs.com #OSS Bucket對應的Endpoint encryptOptions: - name: fs.oss.accessKeyId valueFrom: secretKeyRef: name: access-key key: fs.oss.accessKeyId - name: fs.oss.accessKeySecret valueFrom: secretKeyRef: name: access-key key: fs.oss.accessKeySecret --- apiVersion: data.fluid.io/v1alpha1 kind: JindoRuntime metadata: name: serverless-data spec: replicas: 10 #建立JindoRuntime緩衝節點的數量 podMetadata: annotations: k8s.aliyun.com/eci-use-specs: ecs.g6.2xlarge #指定合適的規格 k8s.aliyun.com/eci-image-cache: "true" labels: alibabacloud.com/eci: "true" worker: podMetadata: annotations: k8s.aliyun.com/eci-use-specs: ecs.g6.2xlarge #指定合適的規格 tieredstore: levels: - mediumtype: MEM #緩衝類型。如果指定了本地碟規格,可使用LoadRaid0 volumeType: emptyDir path: /local-storage #緩衝路徑 quota: 12Gi #緩衝最大容量 high: "0.99" #儲存容量上限 low: "0.99" #儲存容量下限說明本文使用ECI Pod記憶體作為資料緩衝節點,由於每個ECI Pod都有獨享的VPC網卡,因此頻寬上不會受其他Pod影響。
查看結果。
確認加速資料集的狀態,PHASE為Bound表示建立成功。
kubectl -n argo get dataset預期返回:

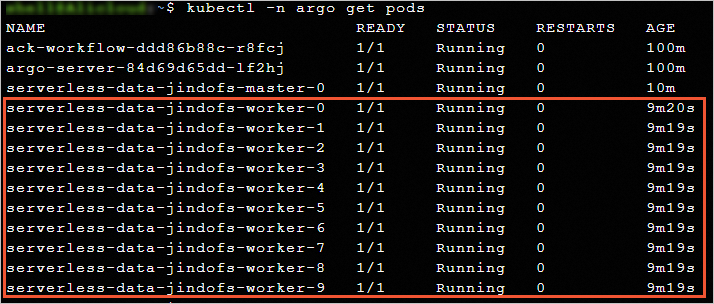
查看Pod資訊,可以看到通過加速資料集已經建立了10個JindoRuntime緩衝節點。
kubectl -n argo get pods預期返回:
預熱資料。
加速資料集就緒後,可以建立Dataload觸發資料預熱。
建立Dataload觸發資料預熱。
kubectl -n argo apply -f dataload.yamldataload.yaml的內容樣本如下
apiVersion: data.fluid.io/v1alpha1 kind: DataLoad metadata: name: serverless-data-warmup namespace: argo spec: dataset: name: serverless-data namespace: argo loadMetadata: true確認Dataload資料預熱的進度。
kubectl -n argo get dataload預期返回如下,可以看到雖然測試檔案有10 GB,但預熱速度是很快的。

運行Argo工作流程。
完成資料預熱後即可並發運行Argo任務,建議配合使用鏡像緩衝進行測試。
準備Argo工作流程設定檔argo-test.yaml。
argo-test.yaml的內容樣本如下:
apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: parallelism-fluid- spec: entrypoint: parallelism-fluid parallelism: 100 podSpecPatch: '{"terminationGracePeriodSeconds": 0, "schedulerName": "eci-scheduler"}' podMetadata: labels: alibabacloud.com/fluid-sidecar-target: eci alibabacloud.com/eci: "true" annotations: k8s.aliyun.com/eci-use-specs: 8-16Gi templates: - name: parallelism-fluid steps: - - name: domd5sum template: md5sum withSequence: start: "1" end: "100" - name: md5sum container: imagePullPolicy: IfNotPresent image: alpine:latest command: ["sh", "-c", "cp /data/test.dat /test.dat && md5sum test.dat"] volumeMounts: - name: data-vol mountPath: /data volumes: - name: data-vol persistentVolumeClaim: claimName: serverless-data建立Workflow。
argo -n argo submit argo-test.yaml查看Workflow執行結果。
argo -n argo list預期返回:

通過
kubectl get pod -n argo --watch命令進一步觀察Pod的執行進度,可以看到樣本情境的100個Argo任務基本在2~4分鐘左右完成。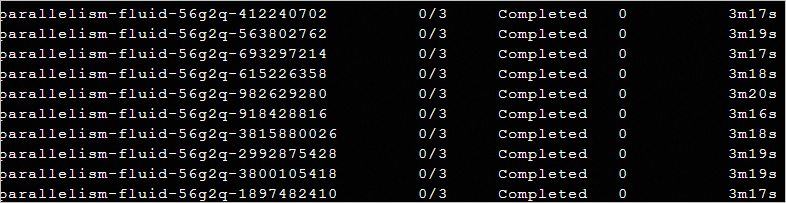
對於同樣的一組Argo任務,如果不使用資料加速,直接從OSS中載入10 G的測試檔案並計算MD5,耗時大概在14~15分鐘左右。
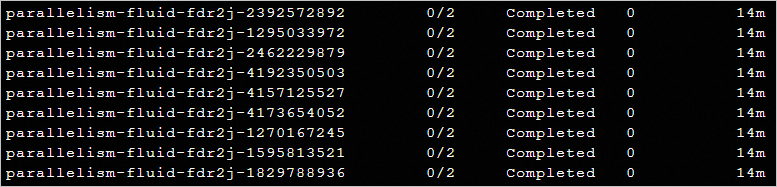
對比可以得出資料加速Fluid既可以提升計算效率,也可以大幅度降低計算成本。