為解決因容器引擎層的不透明性而導致的故障排查困難問題,阿里雲Container Service for Kubernetes (ACK)推出SysOM工具,通過提供作業系統核心層的容器監控資料,增強了對容器記憶體問題的可觀測性。這使您能夠更透明地查看和診斷容器引擎層的問題,從而更順利地進行容器化遷移。本文介紹如何使用SysOM定位容器記憶體問題。
前提條件
已建立ACK託管版叢集或自2021年10月以後建立的ACK Serverless叢集,並確保叢集版本為1.18.8及以上。如需升級叢集,請參見手動升級叢集。
已開啟阿里雲Prometheus監控。
已開啟ack-sysom-monitor監控功能。具體操作,請參見開啟ack-sysom-monitor監控功能。
ack-sysom-monitor監控功能費用說明
啟用ack-sysom-monitor監控功能後,相關組件會自動將監控指標發送至阿里雲Prometheus服務,這些指標將被視為自訂指標。使用自訂指標會引起額外的費用。
為避免產生額外的費用,建議在啟用此功能前,仔細閱讀阿里雲Prometheus的計費概述,瞭解自訂指標的收費策略。費用將根據您的叢集規模和應用數量等因素產生變動。您可以通過資源消耗統計功能,監控和管理您的資源使用方式。
情境描述
容器化因其降低成本、提高效率的優勢,以及提供的靈活性和可擴充性,已成為企業IT架構的最佳實務。
但容器化也引入了容器引擎層的不透明性,導致記憶體佔用過高甚至超出限制,從而觸發OOM(Out of Memory)問題。
阿里雲Container Service for Kubernetes (ACK)團隊聯合阿里雲GuestOS作業系統團隊,通過作業系統核心層的容器監控能力,實現記憶體使用量的精準管控,避免由此引發的OOM問題。
容器記憶體組成
容器的記憶體由應用程式記憶體、核心記憶體和空閑記憶體組成。
記憶體大類 | 記憶體小類 | 說明 |
應用程式記憶體(Application Memory) | 應用程式記憶體由以下幾個部分組成:
| 應用程式運行時所使用的記憶體。 |
核心記憶體(Kernel Memory) | 核心記憶體由以下幾個部分組成:
| 作業系統核心使用的記憶體。 |
空閑記憶體(Free Memory) | 不涉及。 | 未被使用的可用記憶體。 |
實現原理
Kubernetes 採用記憶體工作集(Workingset)來監控和管理容器的記憶體使用量。當容器的記憶體消耗超過設定的限制或節點面臨記憶體壓力時,Kubernetes 會基於 Workingset 來判斷是否需要驅逐或終止容器。通過 SysOM 監控 Pod 的 Workingset,可以提供更為全面和精準的記憶體監控與分析能力,協助營運和開發人員迅速定位並解決 Workingset 過高的問題,從而提升容器的效能和穩定性。
記憶體工作集(Workingset)指的是在一定時間範圍內,容器實際使用的記憶體部分,即容器當前運行所需的記憶體。具體計算公式為 Workingset = InactiveAnon + ActiveAnon + ActiveFile,其中 InactiveAnon 和 ActiveAnon 代表程式匿名記憶體的總大小,而 ActiveFile 代表應用程式活躍檔案快取的大小。通過這樣的監控和分析,營運人員可以更有效地管理資源,確保應用程式的持續穩定運行。
使用SysOM功能
基於阿里雲SysOM提供的作業系統核心層Pod、Node維度監控大盤,您可以即時監控記憶體、網路、儲存等的系統層指標。SysOM功能的詳細指標資訊,請參見SysOM核心層容器監控。
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在Prometheus 監控頁面,單擊SysOM 系統觀測頁簽,然後單擊SysOM容器系統監控-Pod維度頁簽,查看監控大盤的Pod記憶體資料。
根據計算公式,分析如何定位記憶體黑洞問題。
Pod總記憶體 = RSS 常駐記憶體 + Cache(緩衝)≈ inactive_anon+active_anon+inactive_file+active_file
Workingset = inactive_anon + active_anon + active_file
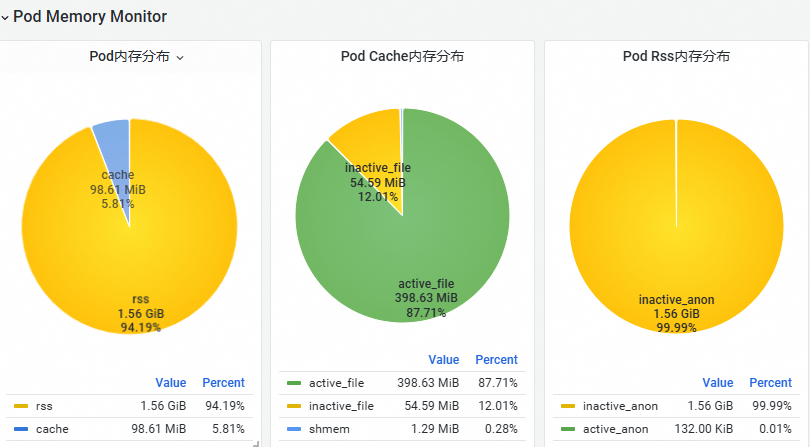
在Pod Memory Monitor地區,根據Pod總記憶體公式,可以先將Pod記憶體分為cache和rss記憶體,然後將cache分為active_file、inactive_file和shmem(共用記憶體)三種類型佔比,rss記憶體分為active_anon和inactive_anon兩種類型佔比。
如下圖所示,inactive_anon記憶體大小佔比最大。
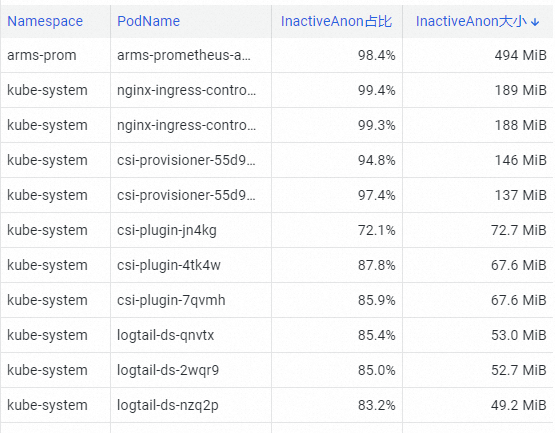
在Pod Resource Analysis地區,通過Top工具快速定位叢集中InactiveAnon記憶體消耗最大的Pod。
如下圖所示,arms-prom的記憶體消耗最大。
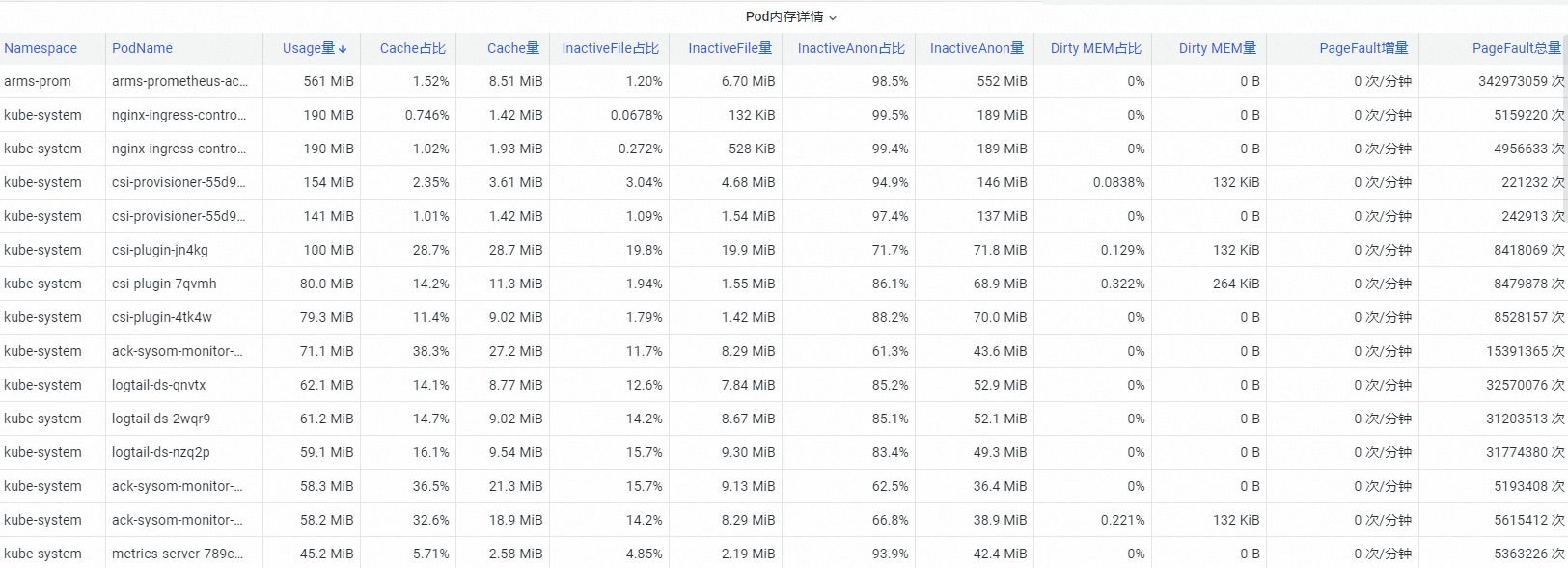
在Pod記憶體詳情地區,查看Pod的詳細記憶體組成。通過Pod Cache(緩衝記憶體)、InactiveFile(非活躍檔案記憶體佔用)、InactiveAnon(非活躍匿名記憶體佔用)、Dirty Memory(系統髒記憶體佔用)等不同記憶體成分的監控展示,發現常見的Pod記憶體黑洞問題。
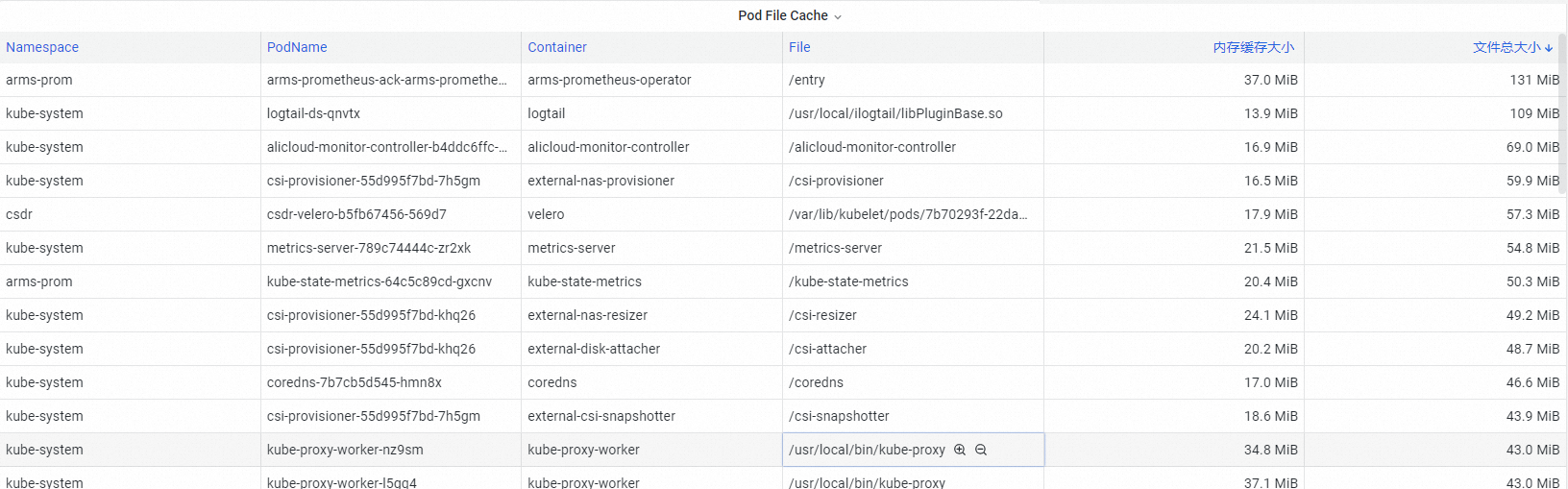
在Pod File Cache地區,查看產生較大緩衝記憶體的原因。
若Pod的記憶體緩衝較大,可能導致Pod工作記憶體佔用升高,這部分緩衝的記憶體會成為Pod工作記憶體的黑洞,最終影響Pod所在的業務體驗。
修複記憶體黑洞問題。
通過觀測發現容器記憶體黑洞問題,即可通過ACK精細化調度功能進行閉環修複。具體操作,請參見啟用容器記憶體QoS。
相關文檔
關於SysOM功能的詳細指標資訊,請參見SysOM核心層容器監控。
關於ACK容器記憶體QoS啟用的核心能力,請參見核心功能與介面概述。