SysOM(System Observer Monitoring)是一種在作業系統核心層提供容器監控可觀測能力的方法,支援容器化部署、遷移及監控。本文介紹如何開啟和使用ack-sysom-monitor功能,並說明相關監控指標。
前提條件
已建立ACK託管版叢集或自2021年10月以後建立的ACK Serverless叢集,並確保叢集版本為1.18.8及以上。如需升級叢集,請參見手動升級叢集。
已開啟阿里雲Prometheus監控。
ack-sysom-monitor組件介紹
ack-sysom-monitor是SysOM的監控組件,基於eBPF技術實現核心級指標採集,覆蓋節點和容器維度。除基礎系統指標外,還提供深度增強指標,可檢測系統抖動、延遲、資源泄漏及Pod記憶體異常等典型問題場。
ack-sysom-monitor監控功能費用說明
啟用ack-sysom-monitor監控功能後,相關組件會自動將監控指標發送至阿里雲Prometheus服務,這些指標將被視為自訂指標。使用自訂指標會引起額外的費用。
為避免產生額外的費用,建議在啟用此功能前,仔細閱讀阿里雲Prometheus的計費概述,瞭解自訂指標的收費策略。費用將根據您的叢集規模和應用數量等因素產生變動。您可以通過資源消耗統計功能,監控和管理您的資源使用方式。
開啟ack-sysom-monitor監控功能
登入ARMS控制台。
在左側導覽列,單擊接入中心。
在接入中心頁面的基礎設施地區,單擊SysOM 系統觀測。
在SysOM 系統觀測面板的開始接入頁簽,選擇待接入的容器叢集,然後單擊確定。
使用ack-sysom-monitor監控功能
操作步驟
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在Prometheus 監控頁面,單擊SysOM系統觀測頁簽查看ack-sysom-monitor監控功能。
ack-sysom-monitor提供節點維度、Pod維度作業系統核心級監控。
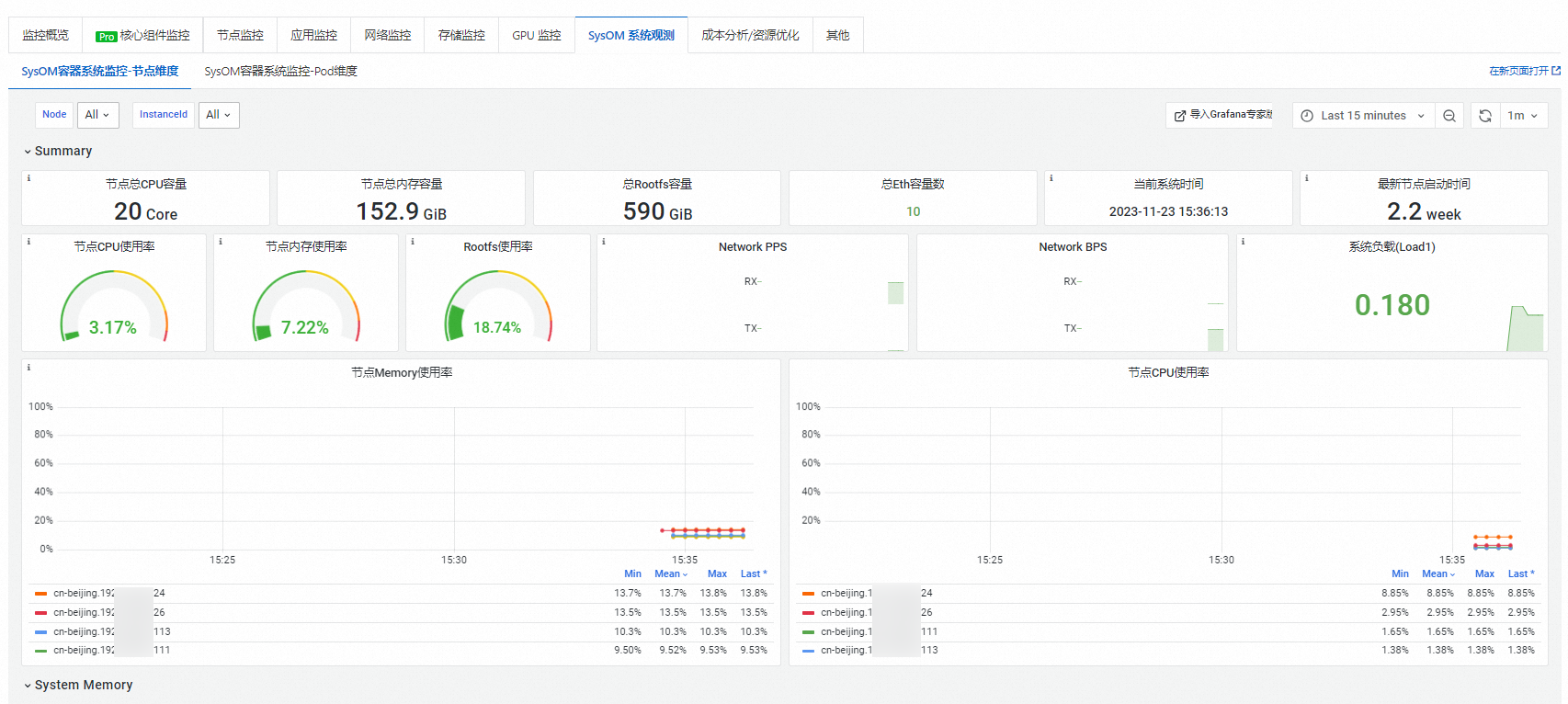
節點維度作業系統核心級監控
在SysOM容器系統監控-節點維度頁簽,您可以從節點維度監控記憶體、CPU和調度、儲存、網路等模組的指標。
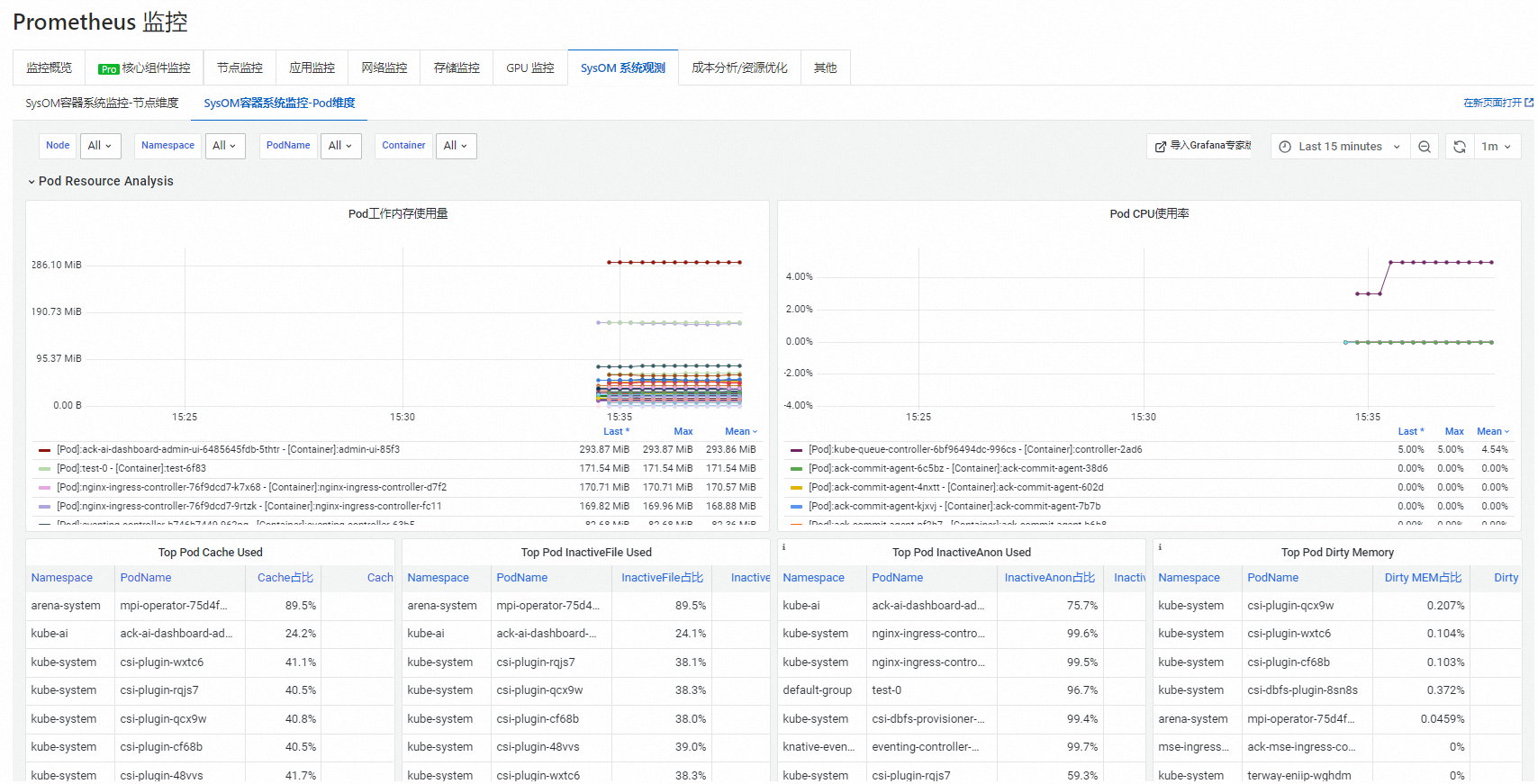
Pod維度作業系統核心級監控
在SysOM容器系統監控-Pod維度頁簽,您可以從Pod維度即時監控記憶體、CPU、網路、IO等模組的指標。
相關操作
如需關閉SysOM核心層容器監控,您可以卸載ack-sysom-monitor組件,避免產生額外計費。操作路徑,請參見管理組件。
指標說明
ack-sysom-monitor的監控指標格式按照標準Prometheus指標格式定義。
節點指標
節點指標可以分為CPU、記憶體、儲存、網路及其他指標。
CPU和調度相關指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_proc_cpu_total | gauge | % | 查看節點總體CPU已耗用時間佔比情況。 表示每種狀態下系統所有CPU的已耗用時間占CPU總已耗用時間的比率。這些狀態包括使用者態、核心態、非強制中斷(softirq)、硬中斷(hardirq)、空閑(idle)和I/O等待(iowait)。 |
sysom_proc_cpus | gauge | % | 查看節點某個CPU的已耗用時間佔比情況。 表示某個CPU在不同系統狀態下的已耗用時間占CPU總已耗用時間的比率。這些狀態包括CPU在使用者態、核心態、非強制中斷(softirq)、硬中斷(hardirq)、空閑(idle)和I/O等待(iowait)。 |
sysom_proc_sirq | gauge | % | 查看節點的非強制中斷情況。 表示各種類型的非強制中斷(softirq)在系統中發生的次數。其中統計的非強制中斷類型包括HI(高優先順序)、TIMER(定時器)、NET_TX(網路發送)、NET_RX(網路接收)、BLOCK(塊裝置)、IRQ_POLL(中斷輪詢)、TASKLET(任務隊列)、SCHED(調度器)、HRTIMER(高解析度定時器)和RCU非強制中斷。 |
sysom_proc_stat_counters | gauge | - | 查看節點是否存在過多的D狀態進程,以瞭解系統的負載情況。 表示系統中處於不同狀態(Running、D狀態)的進程數量。同時,它還提供系統啟動時間以及環境切換次數。 |
sysom_proc_loadavg | gauge | - | 節點的平均負載情況。 表示系統的平均負載(load average)值,包括系統的運行隊列(runq)長度、最近1分鐘的平均負載值、最近5分鐘的平均負載值、最近15分鐘的平均負載值以及系統總進程數。 |
sysom_proc_schedstat | gauge | ns(納秒) | 查看節點的調度延遲情況。 該指標提供了與CPU調度相關的統計資料,包括在當前CPU的調度隊列中等待被調度啟動並執行進程的消耗時間,以及當前CPU中啟動並執行時間片長度。 |
sysom_cpu_dist | gauge | - | 查看節點的總體調度情況。 該指標提供了從進程讓出CPU到下一次被調度到CPU上運行所用時間的統計情況。包括了在不同時間間隔(1us、10us、100us、1ms、10ms、100ms、1s)內,系統中所有進程從讓出CPU到下一次被調度到CPU上啟動並執行次數。 |
記憶體相關指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_proc_meminfo | gauge | KiB | 查看節點各種類型記憶體的佔用情況。 該指標支援查看記憶體的佔用情況,包括但不限於系統總記憶體(Total)、剩餘記憶體(Free)、可用記憶體(Available)、頁緩衝(Cache)、塊緩衝(Buffers)、可回收記憶體(SReclaimable)、不可回收記憶體(SUnreclaim)。 |
sysom_proc_vmstat | gauge | - | 查看節點具體的記憶體使用量情況和記憶體事件情況。 該指標用於表示系統中以頁為單位的系統記憶體統計資料,以及一些記憶體事件的統計。記憶體資訊和事件統計包括:系統空閑頁數(Free Pages)、髒頁數(Dirty Pages)、從磁碟讀入/寫出的頁數(Pages Read/Write)、從Inactive鏈表中回收的頁數(Pages Reclaimed from Inactive List)、OOM(Out of Memory)Kill次數。 |
sysom_proc_buddyinfo | gauge | - | 查看節點核心記憶體管理中夥伴(Buddy)系統的分配和釋放情況的統計資料。 該指標提供了有關核心夥伴系統的詳細資料,包括系統中所有記憶體節點(Node)和地區(Zone),以及不同頁塊大小的夥伴系統鏈表中的頁塊數量。 |
儲存相關指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_proc_disks | gauge | - | 查看節點上每個磁碟和分區的讀取、寫入、I/O請求和延時等統計資料,從而瞭解節點的I/O情況。 該指標提供系統中有關磁碟和分區的統計資訊,具體包括磁碟分割完成的讀寫請求數、讀寫請求總共花費的時間、合并的讀寫請求次數、裝置中未完成(Inflight)的I/O數量等。 |
sysom_fs_stat | gauge | - | 查看節點上已掛載的檔案系統的使用方式。 該指標提供系統中各檔案系統的用量統計資訊,具體包括檔案系統的掛載點、塊大小、已用和可用塊數、已用和可用的Inode數量等資訊。 |
網路相關指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_proc_networks | gauge | - | 查看節點各網卡的流量情況。 該指標提供系統中各網卡的流量統計資訊,具體包括網卡發送/接收的資料包總數、總位元組數、發送/接收時裝置驅動程式丟棄的資料包總數、發送/接收資料包時錯誤總數等。 |
sysom_proc_pkt_status | gauge | - | 查看節點網路通訊協定棧處理資料包的整體情況。 該指標提供系統中網路資料包通過網路通訊協定棧時發生的事件次數,包括在網路通訊協定棧中丟包的次數、發生棧溢出的次數、發生斷言失效的次數等。 |
sysom_sock_stat | gauge | - | 該指標可以協助發現由於應用邏輯、系統參數配置等問題導致的通訊端和緩衝區耗盡等情況。 該指標提供有關節點通訊端和其緩衝區使用方式的統計資訊,包括total/raw/tcp/udp的socket使用量、TCP time wait/orphan狀態的socket數量、TCP/UDP socket的記憶體使用量量等。 |
sysom_softnets | gauge | - | 查看節點每個CPU網卡非強制中斷接收資料包的情況。 該指標提供系統中網路非強制中斷相關統計資料,包括某個CPU在非強制中斷中收包和丟包個數、網路收包非強制中斷處理函數net_rx_action調用次數等。 |
sysom_net_health_hist | gauge | - | 查看節點中所有TCP串連的往返時延分布,從而瞭解TCP鏈路的時延情況。 該指標提供了節點中所有TCP串連的往返時延分布資訊。具體而言,它包括經過平滑處理的RTT(Round Trip Time)時間在不同時間範圍內的次數統計,例如在10ms、100ms和1s內的次數。 |
sysom_net_health_count | gauge | - | 與 |
sysom_net_retrans_count | gauge | - | 查看節點中所有TCP串連的重傳情況,並快速瞭解產生重傳的原因。 該指標提供系統中TCP串連發生重傳的資料包類型以及對應的數目,包括因為RTO(Retransmission Timeout)逾時引起重傳的資料包數目和不同類型資料包重傳數目(例如Syn、Syn-ack、Reset等)。 |
sysom_net_tcp_count | gauge | - | 查看節點中TCP串連的基本情況。 該指標提供系統中TCP串連相關的統計資料,具體包括系統中已建立並且處於活躍狀態的TCP串連數,接收/發送的TCP segment數目、重傳的TCP segment數目以及接收端發生錯誤的資料包數目。 |
sysom_net_udp_count | gauge | - | 查看節點中UDP串連的基本情況。 該指標提供系統中UDP串連相關的統計資料,包括系統中發送/接收的UDP資料包數目、UDP發送/接收緩衝區發生錯誤的次數以及因為無可用連接埠導致的錯誤資料包數目。 |
sysom_net_ip_count | gauge | - | 查看節點中IP層的基本情況。 該指標提供系統中IP層相關的統計資料,包括系統中轉寄、接收和發送的IP資料包數量。 |
sysom_net_icmp_count | gauge | - | 查看節點中ICMP協議的基本情況。 該指標提供系統中ICMP協議相關的統計資料,包括系統中ICMP發送/接收的資料包數目、發送/接收錯誤的資料包數目。 |
其他系統指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_cgroups | gauge | - | 查看系統中各CGroup子系統使用的CGroup數量,觀察是否有CGroup泄露的情況。 該指標提供系統中各CGroup子系統下的CGroup數量,包括CPU、Cpuacct、Memory、Pids、Blkio、Devices等CGroup子系統目錄下CGroup數量。 |
sysom_uptime | gauge | s(秒) | 通過該指標可以一定程度地瞭解系統的負載程度。 指標表示系統啟動到當前經過的時間和系統閒置時間。 |
容器指標
容器指標可以分為CPU、記憶體、IO、網路及其他指標。
CPU和調度相關指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_container_cpu_stat | gauge | - | 可以監視和評估是否需要調整資源配額或進行其他最佳化。 該指標提供有關容器中CPU資源限制的統計資訊,包括CGroup中發生CPU周期性限制次數、發生CPU限制的次數、發生CPU限制的總時間。 |
sysom_container_cpu_acctstat | gauge | % | 查看容器的具體CPU使用方式。 該指標提供容器中所有任務在各個模式下啟動並執行CPU使用率,包括容器在使用者態(User)、核心態(Kernel)以及總體的CPU使用率。 |
sysom_container_cpu_cfsquota | gauge | - | 查看容器受CFS調度器限制的已耗用時間情況。 該指標提供容器在每一個CFS調度時間視窗中可以啟動並執行時間,包括cfs_period_us和cfs_quota_us。
|
記憶體相關指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_container_memory_stat | gauge | KiB | 查看容器各種類型的記憶體佔用情況。 該指標提供有關容器記憶體使用量情況的統計資訊,包括容器的總記憶體(Total)、剩餘記憶體(Free)、可用記憶體大小(Available)、頁緩衝(Cache)、塊緩衝(Buffers)、共用記憶體(Shmem)、可回收記憶體(SReclaimable)、不可回收記憶體(SUnreclaim)的佔用情況等。 |
sysom_container_memory_filecache | gauge | KiB | 通過該指標可以快速瞭解容器中檔案快取的佔用情況,從而定位因為容器檔案緩衝佔用過多導致的記憶體緊缺和記憶體延時抖動問題。 該指標提供有關容器中檔案快取(Page Cache)使用方式的統計資訊,包含每個容器中佔用檔案快取最多的10個檔案,以及它們的大小和佔用的檔案快取大小。 |
sysom_container_memory_gdrcm_latency | gauge | 次 | 查看容器中是否存在因直接記憶體回收產生的延時次數和延時的時間,且直接記憶體回收是因為節點記憶體緊張導致的。 該指標提供有關容器中因直接記憶體回收產生的延遲時間和次數的統計資訊,包括1~5毫秒的延遲次數、5~10毫秒的延遲次數、10~100毫秒的延遲次數、100~500毫秒的延遲次數、500~1000毫秒的延遲次數、大於1000毫秒的延遲次數。 |
sysom_container_memory_cdrcm_latency | gauge | 次 | 查看容器中是否存在因直接記憶體回收產生的延時次數和延時時間,且直接記憶體回收是因為當前記憶體控制組(Memory CGroup)緊張導致的。 說明 該指標只有在當前記憶體控制組是非根(Non-Root)控制組,或者當前記憶體控制組設定了記憶體上限時才有意義。 該指標提供有關容器中因直接記憶體回收產生的延遲時間和次數的統計資訊,包括直接記憶體回收延時1~5毫秒的延遲次數、5~10毫秒的延遲次數、10~100毫秒的延遲次數、100~500毫秒的延遲次數、500~1000毫秒的延遲次數、大於1000毫秒的延遲次數。 |
sysom_container_memory_cpt_latency | gauge | 次 | 查看容器中進程申請記憶體時是否存在因為節點記憶體緊張、記憶體片段過多引起核心記憶體規整動作導致的延時。 該指標提供由於直接記憶體規整導致的延時次數和延時時間的統計資訊,包括1~5毫秒的延遲次數、5~10毫秒的延遲次數、10~100毫秒的延遲次數、100~500毫秒的延遲次數、500~1000毫秒的延遲次數、大於1000毫秒的延遲次數。 |
IO相關指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_container_blkio_stat | gauge | - | 查看容器的基本IO情況。 該指標提供容器在對應磁碟中的IO統計資料,包括容器在對應磁碟中發起的讀/寫IO請求數、請求位元組數、進入排隊隊列的讀/寫IO請求數、請求位元組數以及讀/寫IO等待的時間等。 |
網路相關指標
指標名稱 | 指標類型 | 單位 | 說明 |
sysom_container_network_stat | gauge | - | 查看容器的基本網路流量情況。 該指標提供容器在虛擬網卡中的流量統計資料,包括容器在虛擬網卡中發送/接收的資料包數目、位元組數以及丟包數(丟包只包含被虛擬網卡裝置層的丟包數,不包含網路通訊協定棧的丟包)。 |