Kubernetes叢集使用etcd作為持久存放裝置,用於儲存叢集的狀態和中繼資料資訊。作為一個分布式KVStore for Redis,etcd保證了叢集資料的強一致性和高可用性。本文介紹etcd組件的監控指標清單、大盤使用指導以及常見指標異常解析。
使用前須知
操作入口
請參見查看叢集控制面組件監控大盤。
指標清單
指標是組件對外透出狀態和參數的方式之一,etcd組件使用的指標清單如下。
指標 | 類型 | 說明 |
cpu_utilization_core | Gauge | CPU使用量。單位:核(Core)。 |
etcd_server_has_leader | Gauge | etcd基於Raft實現一致性演算法。在Raft中,etcd會將叢集中的某個成員(Member)選舉為“Leader”,即主節點,而其他成員則作為“Follower”,即從節點。Leader會定期向所有Member發送心跳,以保持叢集穩定。 此指標表示etcd Member中是否存在Leader。
|
etcd_server_is_leader | Gauge | etcd Member是否是Leader。
|
etcd_server_leader_changes_seen_total | Counter | 過去一段時間內,etcd Member的切主次數,即Leader更換的次數。 |
etcd_mvcc_db_total_size_in_bytes | Gauge | etcd Member Database(資料庫)的總大小。 |
etcd_mvcc_db_total_size_in_use_in_bytes | Gauge | etcd Member Database的實際使用大小。 |
etcd_disk_backend_commit_duration_seconds_bucket | Histogram | etcd後端commit延時,即在etcd中,資料變更寫入到儲存後端並成功提交(commit)所花費的時間。 Bucket閾值為 |
etcd_debugging_mvcc_keys_total | Gauge | etcd中儲存的所有鍵(Key)的數量 |
etcd_server_proposals_committed_total | Gauge | etcd基於Raft實現一致性演算法。在Raft中,任何試圖更改系統狀態的動作都以提案(Proposal)的形式被提出。 此指標指在etcd中,成功提交到Raft日誌中的Proposal數量。 |
etcd_server_proposals_applied_total | Gauge | 成功應用或執行(Apply)的Proposal數量。 |
etcd_server_proposals_pending | Gauge | 正在等待處理的Proposal數量。 |
etcd_server_proposals_failed_total | Counter | 處理失敗的Proposal數量。 |
memory_utilization_byte | Gauge | 記憶體使用量量。單位:位元組(Byte)。 |
如下資源使用率指標已廢棄,請及時去除依賴該指標的警示和監控。
cpu_utilization_ratio:CPU使用率。
memory_utilization_ratio:記憶體使用量率。
大盤使用指導
大盤基於組件指標和相關PromQL繪製,大盤可觀測性展示和功能解析如下。
可觀測性展示
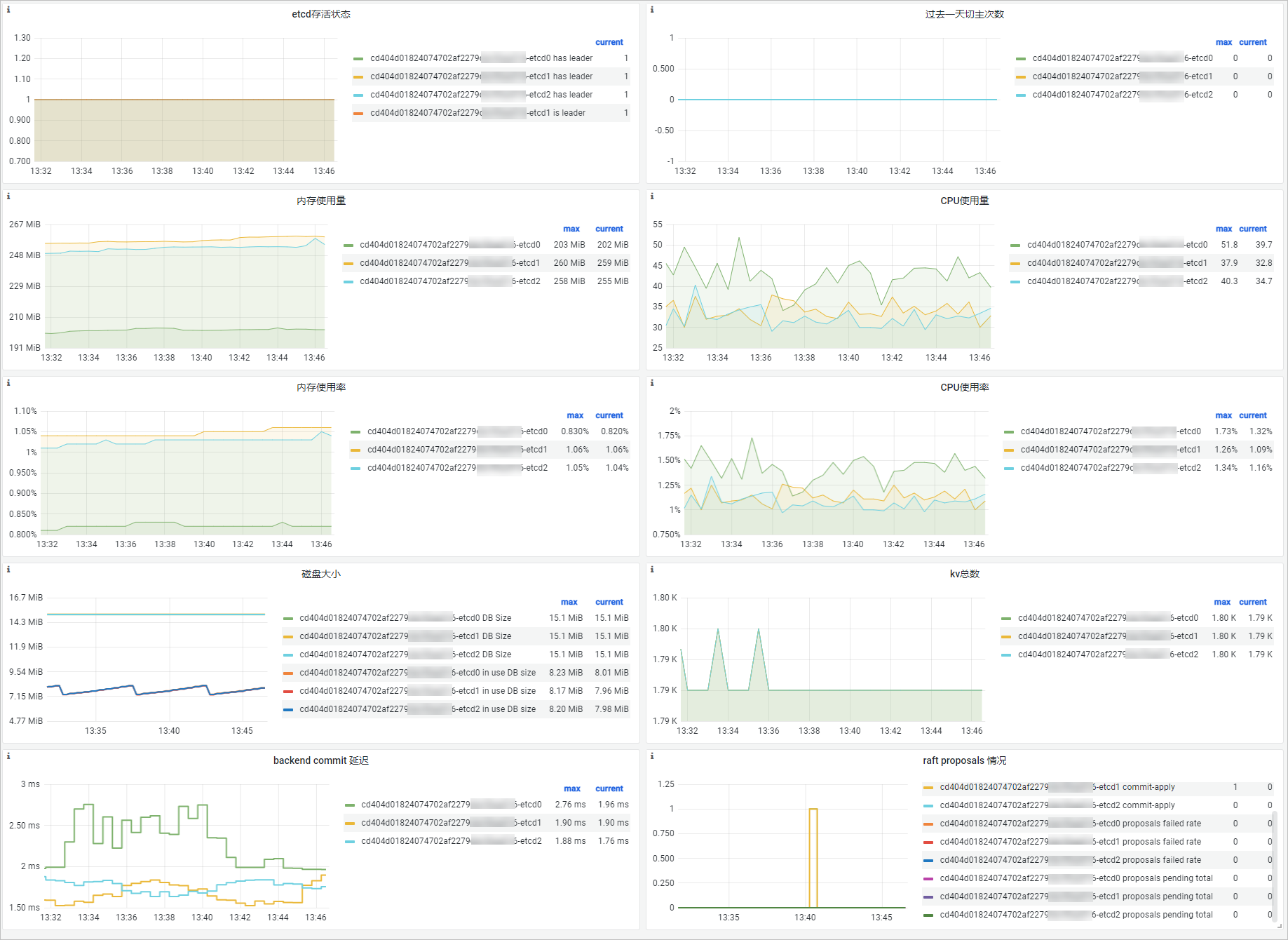
功能解析
名稱 | PromQL | 說明 |
etcd存活狀態 |
|
|
過去一天切主次數 | changes(etcd_server_leader_changes_seen_total{job="etcd"}[1d]) | 過去一天內etcd叢集切主次數,即Leader更換的次數。 |
記憶體使用量量 | memory_utilization_byte{container="etcd"} | 記憶體使用量量。單位:位元組。 |
CPU使用量 | cpu_utilization_core{container="etcd"}*1000 | CPU使用量。單位:毫核。 |
磁碟大小 | etcd_mvcc_db_total_size_in_bytes | etcd Backend DB總大小,即etcd後端資料庫總大小。 |
etcd_mvcc_db_total_size_in_use_in_bytes | etcd Backend DB實際使用大小,即etcd後端資料庫實際使用大小。 | |
kv總數 | etcd_debugging_mvcc_keys_total | etcd叢集KV對(鍵對)總數。 |
backend commit 延遲 | histogram_quantile(0.99, sum(rate(etcd_disk_backend_commit_duration_seconds_bucket{job="etcd"}[5m])) by (instance, le)) | 後端Commit時延,即Proposal在etcd資料庫完成持久化儲存所需要的時間。 |
raft proposal 情況 | rate(etcd_server_proposals_failed_total{job="etcd"}[1m]) | Raft Proposal提交失敗的速率(分鐘)。 |
etcd_server_proposals_pending{job="etcd"} | Pending的Raft Proposal總數。 | |
etcd_server_proposals_committed_total{job="etcd"} - etcd_server_proposals_applied_total{job="etcd"} | Raft Proposal中,Committed和Applied的數量差值,即已提交但尚未執行的Proposal數量。 |
常見指標異常
etcd存活狀態
正常情況 | 異常情況 | 異常說明 |
3個etcd Member都有Leader,且其中之一必須為Leader,即 | 單個Member異常。 | 對應的 |
大於1個Member異常。 | 多個 同時,請觀察是否存在Member的 |
Backend Commit時延
正常情況 | 異常情況 | 異常說明 |
指標處於幾ms到幾十ms。 | 長時間出現幾百ms甚至秒層級的延遲。 | 磁碟讀寫存在異常。 |
Raft Proposal異常
正常情況 | 異常情況 | 異常說明 |
Raft Proposal Failed速率為0。 | raft proposal failed大於0。 | 有Raft Proposal提交失敗。如果此值較大,需進一步排查。 |
Pending的Raft Proposal總數為0。 | Pending的Raft Proposal總數大於0。 | 提交的Raft Proposal有積壓,一般是由於Apply速度較慢,可結合後端Commit時延進行分析。 |
Raft Proposal的Committed和Applied數量差值為0。 | Committed和Applied數量差值大於0。 | 用戶端請求過多,etcd壓力較大。 若此值大於5000,etcd會拒絕接後續的請求,並返回 |
相關文檔
關於其他叢集控制面組件監控的指標詳情、大盤使用指引和常見指標異常說明,請參見kube-apiserver組件監控指標說明、kube-scheduler組件監控指標說明、kube-controller-manager組件監控指標說明、cloud-controller-manager組件監控指標說明。