Simple Log Service (SLS) を使用すると、コンシューマーがログデータを受信する前に、Simple Log Service Processing Language (SPL) でデータを前処理できます。 ルールベースのデータ消費は、リアルタイムでログデータをフィルタリング、変換、構造化することで、インターネットトラフィックコストを削減し、ローカルマシンの計算負荷を軽減し、アプリケーションが必要とするデータのみを配信します。
仕組み
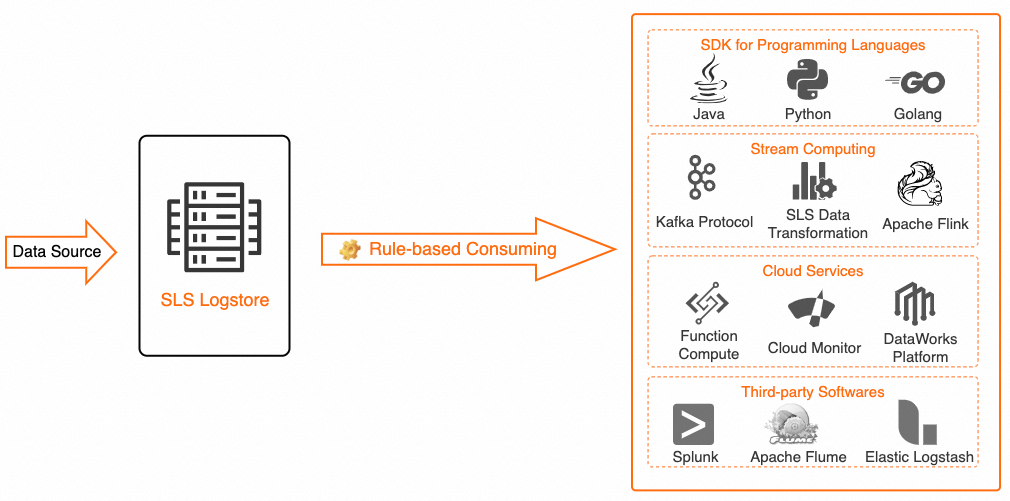
ルールベースのデータ消費は、データがコンシューマーに到達する前に、SLS からログデータを読み取る際に SPL 文を適用します。 消費エンティティには以下が含まれます:
サードパーティソフトウェア
さまざまなプログラミング言語のアプリケーション
クラウドサービス
ストリームコンピューティングフレームワーク
SPL は、半構造化ログデータ向けに設計されたパフォーマンス専有型の処理言語です。 コンシューマーが Logstore からデータを読み取ると、SLS は SPL を使用してデータを前処理およびクレンジングします。 その後、コンシューマーは構造化されたデータを出力として受信します。
| 操作 | 説明 | SPL の例 |
|---|---|---|
| 行によるデータフィルタリング | 条件に一致する行のみを保持します | * | where status = 200 |
| 列によるデータプルーニング | 指定されたフィールドのみを返します | * | project method, url, status |
| 正規表現によるデータ抽出 | 非構造化テキストを解析してフィールドに分割します | * | parse-regexp content, '(\S+) (\S+)' as method, url |
| JSON フィールドの抽出 | 第一階層の JSON キーと値のペアを個別のフィールドに抽出します | * | parse-json content |
完全な SPL 構文リファレンスについては、「SPL 構文」をご参照ください。
ルールベースのデータ消費とクエリと分析はどちらもデータの読み取りに使用されますが、目的が異なります。 詳細については、「LogHub と LogSearch の違い」をご参照ください。
利用シーン
ルールベースのデータ消費は、データを消費する前に前処理が必要なストリームコンピューティングやリアルタイムコンピューティングの利用シーン向けに設計されています。 一般的なユースケースは次のとおりです:
行フィルタリング -- ソースで無関係なログエントリを破棄し、コンシューマーが必要なデータのみを処理するようにします。
列プルーニング -- 不要なフィールドを削除して、コンシューマーに転送されるデータ量を削減します。
正規表現抽出 -- 半構造化されたログ行を、消費前に構造化されたフィールドに解析します。
JSON フィールド抽出 -- 第一階層の JSON キーと値のペアを、後続の処理のために個別のフィールドに抽出します。
この機能は時間に敏感であり、数秒以内にコンシューマーにデータを配信します。 ご利用の Logstore には、カスタムのデータ保持期間を設定できます。
メリット
インターネットトラフィックコストの削減
ルールベースの消費がない場合、コンシューマーはすべての生ログデータをインターネット経由でプルし、ローカルでフィルタリングします。 ルールベースの消費では、データが外部に出る前に SPL が SLS 内部でデータをフィルタリングするため、必要なデータのみがネットワークを通過します。
例: ログデータを SLS に書き込み、インターネット経由で消費します。 * | where level = 'ERROR' のような SPL 文を適用することで、一致する行のみがコンシューマーに送信されます。 これにより、インターネット経由で転送されるデータ量が削減され、トラフィックコストが低減します。
ローカル CPU 消費量の削減
ルールベースの消費がない場合、オンプレミスマシンはすべての生データをダウンロードして計算する必要があります。 ルールベースの消費では、SPL が SLS 内部で計算を実行するため、ご利用のマシンは前処理された結果を受け取ります。
例: ログデータを SLS に書き込み、オンプレミスマシンで消費します。 SPL を使用して SLS でログデータを計算することで、ローカルマシンの処理負荷を軽減し、パイプライン全体を高速化します。
サポートされるコンシューマー
| タイプ | コンシューマー | 説明 |
|---|---|---|
| さまざまなプログラミング言語のアプリケーション | Java、Python、Go などのさまざまなプログラミング言語のアプリケーション | アプリケーションは、コンシューマーグループとして SLS のデータを消費します。 「Simple Log Service SDK を使用したログデータの消費」および「コンシューマーグループを使用したログの消費」をご参照ください。 ベストプラクティス:「Simple Log Service SDK を使用した SPL ベースの消費の実行」 |
| クラウドサービス | Realtime Compute for Apache Flink | SLS からリアルタイムでデータを消費します。 「Simple Log Service コネクタ」をご参照ください。 ベストプラクティス:「SPL 文を使用した Flink SQL による行フィルタリングと列プルーニングの実装」および「Flink SQL における SPL に基づく半構造化分析」 |
| ストリームコンピューティングフレームワーク | Apache Kafka | サポートをリクエストするには、チケットを起票してください。 |
課金
ルールベースのデータ消費の課金方法は、ご利用の Logstore の課金モードによって異なります。
| 課金モード | ルールベースのデータ消費料金 | インターネットトラフィック料金 | 詳細 |
|---|---|---|---|
| データ量課金 | 課金されません | パブリックな SLS エンドポイント経由でデータがプルされる場合、インターネット経由の読み取りトラフィックに対して課金されます。 トラフィックは圧縮後のデータサイズに基づいて計算されます。 | データ量課金の課金項目 |
| 機能課金 | Simple Log Service におけるコンピューティングの課金 | パブリックな SLS エンドポイントにアクセスする場合、インターネットトラフィック料金が課金されることがあります。 | 機能課金の課金項目 |
制限事項と制約
ルールベースのデータ消費には、SLS での複雑な計算が伴います。 SPL ベースの計算の複雑さとデータ特性の違いは、レイテンシーとスループットに影響します。
| 項目 | 制限 |
|---|---|
| SPL 文の最大サイズ | 4 KB |
| シャードの読み取り制限 | 通常のリアルタイムデータ消費と同じです。 「データの読み書き」をご参照ください。 |
| 読み取りトラフィックの計算 | フィルタリングされた出力ではなく、SPL ベースのデータ処理前の生データのサイズに基づきます。 |
| レイテンシーへの影響 | 5 MB のデータを読み取ると、SPL 処理により約 10〜100 ミリ秒のレイテンシーが追加されます。 SPL ベースの計算の複雑さとデータ特性の違いが、実際のレイテンシーに影響します。 |
SPL 処理はわずかな読み取りレイテンシーを追加しますが、ほとんどの場合、コンシューマーが受け取るデータ量が少なくなり、ローカルでの計算も少なくなるため、SLS によるデータ読み取りからオンプレミスマシンでのデータ計算までの合計時間は短縮されます。
エラー処理: SPL 文に無効な構文が含まれていたり、存在しないソースフィールドを参照していたりすると、データが失われたり、データ消費が失敗したりする可能性があります。 詳細については、「エラー処理」をご参照ください。
よくある質問
ShardReadQuotaExceed エラーが発生した場合の対処法
このエラーは、データの読み取りトラフィックがシャードの読み取り容量を超えた場合に発生します。 解決するには:
待機してリトライする。 コンシューマーに待機させてから再試行させます。
シャードを分割する。 シャードが分割されると、新しいデータは複数のシャードにまたがって消費されるため、各シャードの読み取り速度が低下します。
ルールベースのデータ消費のスロットリングポリシー
ルールベースのデータ消費のスロットリングポリシーは、通常のデータ消費のスロットリングポリシーと同じです。 詳細については、「データの読み書き」をご参照ください。
スロットリングに使用されるトラフィックは、SPL ベースのデータ処理前の生データのサイズに基づいて計算されます。 例:
圧縮された生データのサイズ: 100 MB
SPL 文:
* | where method = 'POST'コンシューマーに返される圧縮データ: 20 MB
スロットリングでカウントされる読み取りトラフィック: 100 MB (フィルタリングされた出力ではなく、生データのサイズ)
ルールベースのデータ消費を有効にした後、Traffic/min チャートのアウトフロートラフィックが低い理由
プロジェクトモニタリングタブの Traffic/min チャートのアウトフロートラフィックは、SPL ベースのデータ処理後のデータサイズを表します。 SPL 文に行フィルタリングや列プルーニングなど、データサイズを削減する操作が含まれている場合、アウトフロートラフィックはインフロートラフィックよりも低くなります。 詳細については、「プロジェクトモニタリング」をご参照ください。
次のステップ
SPL 構文を学ぶ: SPL 構文
SDK を使用したログ消費を開始する: Simple Log Service SDK を使用して SPL によるログ消費を行う
Flink 統合を設定する: Simple Log Service コネクタ
データモデルを理解する: LogHub と LogSearch の違いは何ですか?
読み取り/書き込み制限の確認: データの読み取りと書き込み