Platform for AI (PAI) のElastic Algorithm Service (EAS) は、モデルトレーニングと推論のためのスケーラブルジョブサービスを提供します。 このサービスは、再利用性と自動スケーリングをサポートします。 複数のジョブが同時に実行されるモデルトレーニングシナリオでは、Scalable Jobサービスを使用すると、インスタンスの頻繁な作成とリリースによるリソースの無駄を減らすことができます。 Scalable Jobサービスは、推論シナリオで各要求の実行進行状況を追跡して、タスクスケジューリングをより効率的に実装することもできます。 このトピックでは、Scalable Jobサービスの使用方法について説明します。
シナリオ
モデルトレーニング
実装
このシステムは、フロントエンドとバックエンドのサービスを分離するアーキテクチャを使用して、常駐のフロントエンドサービスとバックエンドのスケーラブルなジョブサービスをサポートします。
アーキテクチャのメリット
ほとんどの場合、フロントエンドサービスは少ないリソースと低コストでデプロイできます。 常駐フロントエンドサービスをデプロイして、フロントエンドサービスの頻繁な作成を回避し、待ち時間を短縮できます。 バックエンドのScalable Jobサービスを使用すると、1つのインスタンスでトレーニングタスクを複数回実行できます。 これにより、複数の実行中にインスタンスが繰り返し起動およびリリースされるのを防ぎ、サービススループットを向上させます。 Scalable Jobサービスは、キューの長さに基づいて自動的にスケーリングして、リソースを効率的に使用することもできます。
モデル推論
モデル推論シナリオでは、Scalable Job serviceが各リクエストの実行の進捗状況を追跡して、タスクスケジューリングをより効率的に実装します。
ほとんどの場合、EASで非同期推論サービスとして応答するのに時間がかかる推論サービスを展開することをお勧めします。 ただし、非同期サービスには次の問題があります。
キューサービスがアイドル状態のインスタンスにリクエストを優先的に送信できないため、リソースの使用量が不足する可能性があります。
サービスのスケールイン中に、キューサービスは、要求をまだ処理しているインスタンスを除去することができ、これは、要求が中断され、再び実行のために別のインスタンスにスケジュールされることにつながる。
上記の問題を解決するために、Scalable Jobサービスは次の最適化を実装します。
サブスクリプションロジックの最適化: リクエストがアイドルインスタンスに優先的に送信されるようにします。 スケーラブルジョブインスタンスが停止またはリリースされる前に、インスタンスは一定期間ブロックされ、インスタンスでのリクエストの実行が確実に完了します。
スケーリングロジックの最適化: 一般的なモニタリングサービスの通常のレポートメカニズムとは異なり、Scalable Jobサービスはキューサービスの組み込みモニタリングサービスを使用して、専用のモニタリングリンクを実装します。 これにより、キューの長さがしきい値を超えたり下回ったりすると、スケールアウトとスケールインが迅速にトリガーされます。 スケーリングの応答時間は数分から約10秒に短縮されます。
アーキテクチャ
このアーキテクチャは、キューサービス、水平ポッドオートスケーリング (HPA) コントローラ、およびスケーラブルジョブのセクションで構成されています。 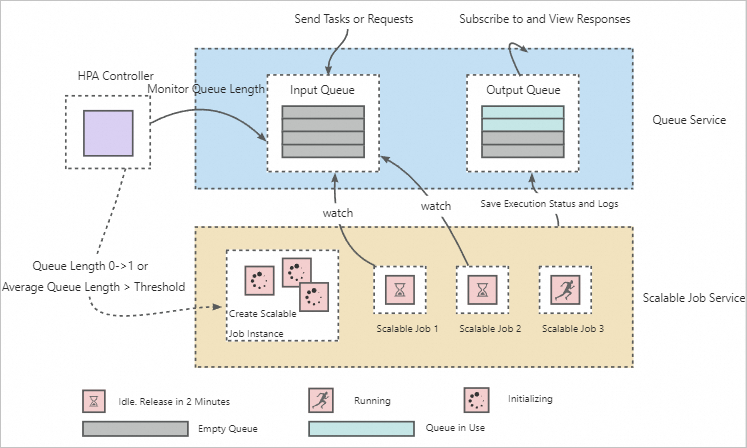
それがいかに働くか:
キューサービスは、要求またはタスクの送信と実行を切り離すために使用されます。 これにより、単一のScalable Jobサービスで複数のリクエストまたはタスクを実行できます。
HPAコントローラは、キューサービス内の保留中のトレーニングタスクとリクエストの数を常に監視して、スケーラブルジョブインスタンスの自動スケーリングをトリガーするために使用されます。 次のセクションでは、Scalable Jobサービスのデフォルトの自動スケーリング設定について説明します。 パラメーターの詳細については、「自動スケーリング」をご参照ください。
{ "behavior":{ "onZero":{ "scaleDownGracePeriodSeconds":60 # The duration from the time when the scale-in is triggered to the time when all instances are removed. Unit: seconds. }, "scaleDown":{ "stabilizationWindowSeconds":1 # The duration from the time when the scale-in is triggered to the time when the scale-in starts. Unit: seconds. } }, "max":10, # The maximum number of scalable job instances. "min":1, # The minimum number of scalable job instances. "strategies":{ "avg_waiting_length":2 # The average queue length of each scalable job instance. } }
サービスのデプロイ
推論サービスのデプロイ
このプロセスは、非同期推論サービスを作成するプロセスに似ています。 次の例に基づいて、サービス構成ファイルを準備します。
{
"containers": [
{
"image": "registry-vpc.cn-shanghai.aliyuncs.com/eas/eas-container-deploy-test:202010091755",
"command": "/data/eas/ENV/bin/python /data/eas/app.py"
"port": 8000,
}
],
"metadata": {
"name": "scalablejob",
"type": "ScalableJob",
"rpc.worker_threads": 4,
"instance": 1,
}
}推論サービスをスケーラブルなジョブとして展開するには、typeをScalableJobに設定します。 その他のパラメーターについては、「モデルサービスのパラメーター」をご参照ください。 推論サービスの展開方法については、「オンラインポートレートサービスをスケーラブルなジョブとして展開する」をご参照ください。
サービスをデプロイすると、システムは自動的にキューサービスとスケーラブルなジョブを作成し、自動スケーリングを有効にします。
トレーニングサービスのデプロイ
統合デプロイメントと独立デプロイメントがサポートされています。 次のセクションでは、デプロイの仕組みと構成の詳細について説明します。 デプロイ方法の詳細については、「自動スケーリングKohyaトレーニングをスケーラブルなジョブとしてデプロイする」をご参照ください。
デプロイの仕組み
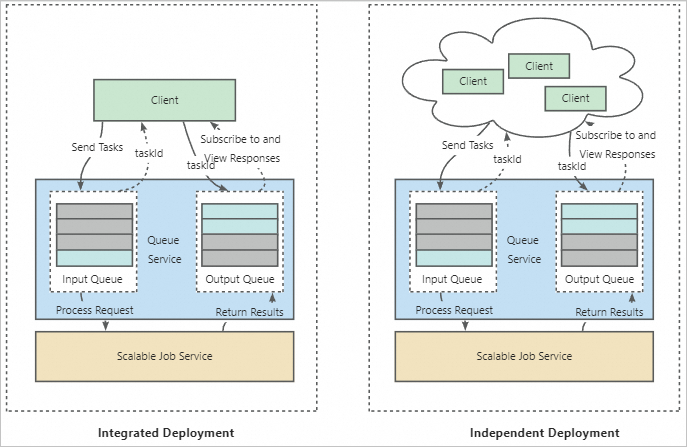
統合展開: EASは、キューサービスとスケーラブルジョブサービスに加えて、フロントエンドサービスを作成します。 フロントエンドサービスは、要求を受信し、要求をキューサービスに転送するために使用される。 フロントエンドサービスは、スケーラブルジョブサービスのクライアントとして機能します。 スケーラブルジョブサービスは、一意のフロントエンドサービスに関連付けられています。 この場合、Scalable Jobサービスは、関連付けられたフロントエンドサービスによって転送されたトレーニングタスクのみを実行できます。
独立配置: 独立配置は、マルチユーザーシナリオに適しています。 このモードでは、Scalable Jobサービスは共通のバックエンドサービスとして使用され、複数のフロントエンドサービスに関連付けることができます。 各ユーザーは、フロントエンドサービスからトレーニングタスクを送信できます。 バックエンドのスケーラブルジョブサービスは、対応するスケーラブルジョブインスタンスを作成してトレーニングタスクを実行し、各ジョブインスタンスは、送信されたシーケンスに基づいて複数のトレーニングタスクを実行できます。 これにより、複数のユーザ間のリソース共有が可能になる。 トレーニングタスクを複数回作成する必要がないため、コストが効果的に削減されます。
設定
スケーラブルなジョブサービスをデプロイするときは、カスタムイメージを提供する必要があります。 Kohyaベースのサービスをデプロイする場合は、EASでプリセットされているKohya_ssイメージを使用できます。 イメージには、トレーニングタスクのすべての依存関係が含まれている必要があります。 イメージは、トレーニングタスクの実行環境として使用されます。 起動コマンドまたはポート番号を設定する必要はありません。 トレーニングタスクの前に初期化タスクを実行する必要がある場合は、初期化コマンドを設定できます。 EASは、初期化タスクを実行するためにScalable Jobインスタンスに別のプロセスを作成します。 カスタムイメージの準備方法については、「カスタムイメージを使用したモデルサービスのデプロイ」をご参照ください。 EASのプリセット画像の例:
"containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ]統合デプロイメント
サービス設定ファイルを準備します。 次のセクションでは、EASでプリセットKohya_ssイメージを使用したサンプル構成ファイルを示します。
{ "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJobService" }, "front_end": { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2", "port": 8001, "script": "python -u kohya_gui.py --listen 0.0.0.0 --server_port 8001 --data-dir /workspace --headless --just-ui --job-service" } }次のセクションでは、主要なパラメーターについて説明します。 その他のパラメーターの設定方法については、「モデルサービスのパラメーター」をご参照ください。
typeをScalableJobServiceに設定します。
既定では、フロントエンドサービスで使用されるリソースグループは、スケーラブルジョブサービスで使用されるリソースグループと同じです。 システムは、フロントエンドサービスに2 vCPUと8 GBメモリを割り当てます。
次のサンプルコードに基づいて、リソースグループをカスタマイズします。
{ "front_end": { "resource": "", # Modify the dedicated resource group that the frontend service uses. "cpu": 4, "memory": 8000 } }次のサンプルコードに基づいて、デプロイに使用されるインスタンスタイプをカスタマイズします。
{ "front_end": { "instance_type": "ecs.c6.large" } }
独立したデプロイ
サービス設定ファイルを準備します。 次のセクションでは、EASでプリセットKohya_ssイメージを使用したサンプル構成ファイルを示します。
{ "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJob" } }typeをScalableJobServiceに設定します。 その他のパラメーターの設定方法については、「モデルサービスのパラメーター」をご参照ください。
このモードでは、フロントエンドサービスをデプロイし、受信したリクエストをScalable Jobサービスのキューに転送するプロキシをフロントエンドサービスに実装する必要があります。 このようにして、フロントエンドサービスとバックエンドScalable Jobサービスが関連付けられます。 詳細については、「アクセスキューサービス」トピックの「キューサービスにデータを送信する」セクションをご参照ください。
コールサービス
トレーニングサービスと推論サービスを区別するには、スケーラブルジョブサービスを呼び出すときにtaskType:command/queryフィールドを設定する必要があります。 パラメーター:
command: トレーニングサービスを識別するために使用されます。
query: 推論サービスを識別するために使用されます。
HTTPまたはSDKを使用してサービスを呼び出す場合、taskTypeを明示的に指定する必要があります。 例:
HTTPリクエストを送信するときにtskTypeをクエリに設定します。
curl http://166233998075****.cn-shanghai.pai-eas.aliyuncs.com/api/predict/scalablejob?taskType={Wanted_TaskType} -H 'Authorization: xxx' -D 'xxx'SDKを呼び出すときにtaskTypeを指定するには、tagsパラメーターを使用します。
# Create an input queue to send tasks or requests. queue_client = QueueClient('166233998075****.cn-shanghai.pai-eas.aliyuncs.com', 'scalabejob') queue_client.set_token('xxx') queue_client.init() tags = {"taskType": "wanted_task_type"} # Send a task or request to the input queue. index, request_id = inputQueue.put(cmd, tags)
応答を受け取る:
推論サービス: EASキューサービスのSDKを使用して、出力キューの結果を取得できます。 詳細については、「アクセスキューサービス」トピックの「キューサービスへのサブスクライブ」をご参照ください。
トレーニングサービス: サービスをデプロイするときは、OSSバケットをマウントして、トレーニング結果を永続ストレージ用のOSSバケットに保存することを推奨します。 詳細については、「Kohyaベースのトレーニングをスケーラブルなジョブとしてデプロイする」をご参照ください。
ログ収集の設定
enable_write_log_to_queueを設定して、リアルタイムログを取得できます。
{
"scalable_job": {
"enable_write_log_to_queue": true
}
}トレーニングシナリオでは、この設定はデフォルトで有効になっています。 システムはリアルタイムログを出力キューに書き戻します。 EASキューサービスのSDKを使用して、トレーニングログをリアルタイムで取得できます。 詳細については、「自動スケーリングKohyaトレーニングをスケーラブルなジョブとしてデプロイする」をご参照ください。
推論シナリオでは、この設定はデフォルトで無効になっています。 システムはstdoutを使用してログを出力します。
関連ドキュメント
スケーラブルなジョブサービスのシナリオの詳細については、以下のトピックを参照してください。