変動するトラフィックに対応するために手動でレプリカを管理することは非効率であり、応答時間の遅延、サービスの過負荷、またはリソースの無駄につながる可能性があります。Elastic Algorithm Service (EAS) の水平オートスケーリング機能は、リアルタイムのサービス負荷に基づいてレプリカ数を自動的に調整します。これにより、サービスの安定性を確保し、リソース使用率を最大化し、コストとパフォーマンスの最適なバランスを実現します。
仕組み
水平オートスケーリングは、設定されたメトリックのしきい値に基づいてレプリカ数を動的に調整します。
目標レプリカ数の計算: システムは、現在のレプリカ数 (currentReplicas) に、現在のメトリック値 (currentMetricValue) と目標のメトリック値 (desiredMetricValue) の比率を乗じることで、目標レプリカ数 (desiredReplicas) を計算します。
数式:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]例: 2 つのレプリカがあり、QPS Threshold of Individual Instance が 10 に設定されているとします。レプリカあたりの平均 QPS が 23 に上昇した場合、目標レプリカ数は
5 = ceil[2 * (23/10)]となります。その後、平均 QPS が 2 に低下した場合、目標レプリカ数は1 = ceil[5 * (2/10)]となります。リクエストの変動による異常なスケーリングを防ぐため、スケールインのプロセスは段階的に行われます。複数のメトリックを設定した場合、システムは各メトリックの目標レプリカ数を計算し、これらの値の最大値を最終的な目標レプリカ数として使用します。
トリガーロジック: 計算された目標レプリカ数が現在の数より大きい場合、システムはスケールアウトをトリガーします。目標が現在の数より小さい場合、スケールインをトリガーします。
重要メトリックの変動による頻繁なスケーリングを防ぐため、システムはしきい値に 10% の許容範囲を適用します。たとえば、クエリ/秒 (QPS) のしきい値が 10 に設定されている場合、スケールアウト操作は QPS が一貫して 11 (10 × 1.1) を超えた場合にのみトリガーされます。これは、以下のことを意味します:
QPS が 10 から 11 の間で短時間変動した場合、システムはすぐにスケールアウトしない可能性があります。
スケールアウト操作は、QPS が 11 から 12 以上で安定した場合にのみトリガーされます。
このメカニズムは、不要なリソースの変更を減らし、システムの安定性とコスト効率を向上させるのに役立ちます。
遅延実行: スケーリング操作は、短時間のトラフィック変動による頻繁な調整を防ぐための遅延メカニズムをサポートしています。
ユーザーガイド
PAI コンソールまたは eascmd クライアントを使用して、水平オートスケーリングポリシーを設定できます。
水平オートスケーリングの有効化または更新
コンソールの使用
PAI (Platform of Artificial Intelligence) コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
サービスリストで、対象サービスのサービス名をクリックして詳細ページに移動します。
Auto Scaling タブの Auto Scaling セクションで、Enable Auto Scaling または Update をクリックします。
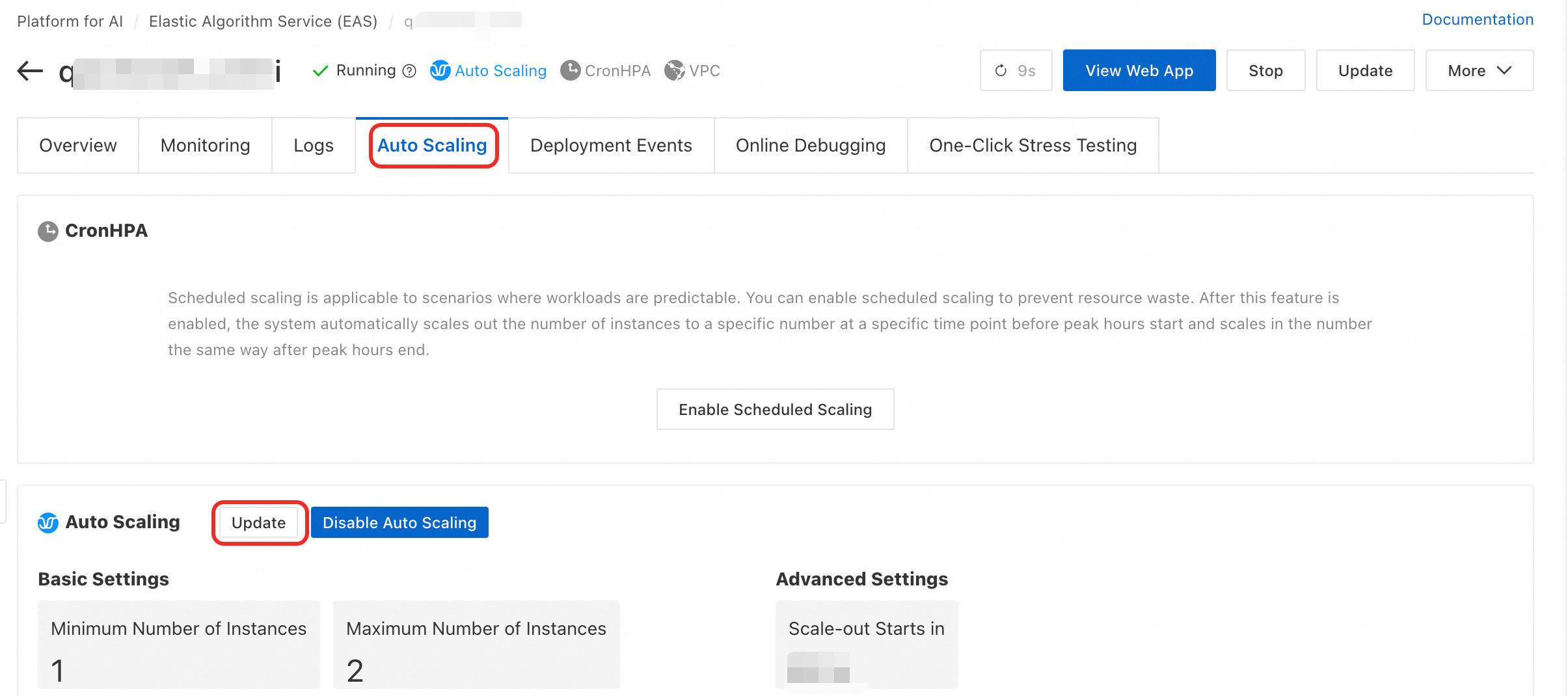
Auto Scaling Settings ダイアログボックスで、以下のパラメーターを設定できます。
パラメーターの説明
基本設定
パラメーター
説明
推奨事項とリスク警告
Minimum Replicas
サービスがスケールインできるレプリカの最小数。最小値は 0 です。
本番環境の推奨事項: 継続的な可用性が必要なサービスの場合、この値を
1以上に設定することを強く推奨します。重要これを
0に設定すると、トラフィックがない場合にすべてのサービスレプリカが削除されます。新しいリクエストは完全なコールドスタートの遅延を経験し、これは数十秒から数分かかることがあります。この間、サービスは利用できません。さらに、専用ゲートウェイを使用するサービスは、この値を0に設定することをサポートしていません。Maximum Replicas
サービスがスケールアウトできるレプリカの最大数。最大値は 1000 です。
予期しないトラフィックスパイクによるコスト超過を防ぐため、推定されるピークトラフィックとアカウントのリソースクォータに基づいてこの値を設定します。
General Scaling Metrics
スケーリングをトリガーするために使用される組み込みのパフォーマンスメトリック。
QPS Threshold of Individual Instance: 値はストレステストによって決定され、通常は単一レプリカの最適パフォーマンスの 70% から 80% に設定されます。
重要単一レプリカの QPS しきい値を小数値に設定するには、クライアント (eascmd) を使用し、
qps1kフィールドを設定します。CPU Utilization Threshold: しきい値が低いとリソースの無駄になり、高いとリクエストのレイテンシーが増加する可能性があります。応答時間 (RT) メトリックに基づいてこの値を設定します。
GPU utilization threshold: 応答時間 (RT) メトリックに基づいてしきい値を設定します。
Asynchronous Queue Length: このパラメーターは非同期サービスにのみ適用されます。平均タスク処理時間と許容レイテンシーに基づいてこのパラメーターを設定できます。詳細については、「非同期推論サービスの水平オートスケーリングの設定」をご参照ください。
Custom Scaling Metric
カスタムメトリックをレポートし、オートスケーリングに使用できます。詳細については、「カスタムモニタリングとスケーリングメトリック」をご参照ください。
組み込みメトリックがビジネス要件を満たさない複雑なシナリオに適しています。
高度な設定
パラメーター
説明
推奨事項とリスク警告
Scale-out Starts in
スケールアウト決定のための観測ウィンドウ。スケールアウトがトリガーされた後、システムはこの期間中にメトリックを観測します。メトリック値がしきい値を下回った場合、スケールアウトはキャンセルされます。単位は秒です。
デフォルトは
0秒で、即座にスケールアウトが発生します。一時的なトラフィックの異常による不要なスケーリングを防ぐために、この値を例えば 60 秒に増やすことができます。Scale-in Starts in
スケールイン決定のための観測ウィンドウ。これは、サービスのジッターを防ぐための重要なパラメーターです。スケールインは、メトリックがこの期間全体でしきい値を下回り続けた後にのみ発生します。単位は秒です。
デフォルトは
300秒です。この値は、トラフィックの変動による頻繁なスケールインイベントに対する中心的な保護策です。サービスの安定性に影響を与える可能性があるため、この値を低く設定しすぎないでください。Scale-in to 0 Instance Starts in
Minimum Replicas が
0に設定されている場合、このパラメーターはスケールイン条件が満たされてからレプリカ数が0に減少するまでの遅延を指定します。サービスの完全なシャットダウンを遅延させます。これにより、潜在的なトラフィック回復のためのバッファーが提供されます。
Scale-from-Zero Replica Count
コールドスタート中にサービスが
0レプリカからスケールアウトする際に一度に追加するレプリカの数。初期のトラフィックバーストを処理できる妥当な値に設定します。これにより、コールドスタート中のサービスの利用不可時間を短縮します。
クライアント経由
コマンドを実行する前に、「クライアントのダウンロードと認証」が完了していることを確認してください。有効化と更新の両方で、同じ autoscale コマンドを使用します。-D パラメーターまたは JSON 設定ファイルを使用してポリシーを設定できます。
パラメーター形式:
# 形式: eascmd autoscale [region]/[service_name] -D[attr_name]=[attr_value] # 例: 最小レプリカ数を 2、最大を 5、QPS しきい値を 10 に設定します。 eascmd autoscale cn-shanghai/test_autoscaler -Dmin=2 -Dmax=5 -Dstrategies.qps=10 # 例: スケールインの遅延を 100 秒に設定します。 eascmd autoscale cn-shanghai/test_autoscaler -Dbehavior.scaleDown.stabilizationWindowSeconds=100設定ファイル形式:
# ステップ 1: 設定ファイル (例: scaler.json) を作成します。 # ステップ 2: コマンドを実行します: eascmd autoscale [region]/[service_name] -s [desc_json] # 例 eascmd autoscale cn-shanghai/test_autoscaler -s scaler.json
設定例
以下の scaler.json の例には、一般的な設定項目が含まれています:
パラメーターの説明
パラメーター | 説明 |
| レプリカの最小数。 |
| レプリカの最大数。 |
| スケーリングメトリックとしきい値。
|
| コンソールのスケールアウト遅延に対応します。 |
| コンソールのスケールイン遅延に対応します。 |
水平オートスケーリングの無効化
クライアント経由
コマンド形式
eascmd autoscale rm [region]/[service_name]例
eascmd autoscale rm cn-shanghai/test_autoscaler
本番環境でのベストプラクティス
シナリオ別の設定ガイド
CPU 負荷の高いオンライン推論サービス: CPU 使用率のしきい値とレプリカあたりの QPS しきい値の両方を設定します。CPU 使用率はリソース消費を反映し、QPS はサービス負荷を反映します。これらのメトリックを組み合わせることで、より正確なスケーリングが可能になります。
GPU 負荷の高いオンライン推論サービス: 主に GPU 使用率に焦点を当てます。GPU コンピューティングユニットが飽和状態になった場合、迅速にスケールアウトして、サービスがより多くの同時タスクを処理できるようにします。
非同期タスク処理サービス: 中核となるメトリックはAsynchronous Queue Lengthです。キュー内のバックログタスク数がしきい値を超えた場合、レプリカをスケールアウトすることで処理能力を向上させ、タスクの待機時間を短縮します。
安定性のためのベストプラクティス
ゼロへのスケールインを避ける: 本番環境の同期サービスでは、継続的な可用性と低レイテンシーを確保するために、常にMinimum Replicas を
1以上に設定してください。適切な遅延を設定する: スケールイン遅延を使用して、通常のトラフィック変動によるサービスのジッターを防ぎます。デフォルト値の
300秒は、ほとんどのシナリオに適しています。
よくある質問
しきい値に達してもサービスがスケールアウトしないのはなぜですか?
考えられる理由は次のとおりです:
クォータ不足: ご利用のアカウントで、現在のリージョンにおける vCPU や GPU などの利用可能なリソースクォータが枯渇しています。
スケールアウト遅延がアクティブ: スケールアウト遅延を設定した場合、システムはこの期間が終了するのを待って、トラフィックの増加が持続的であることを確認しています。
レプリカのヘルスチェック失敗: 新しくスケールアウトされたレプリカがヘルスチェックに失敗し、操作が失敗しました。
最大レプリカ数に到達: レプリカ数がMaximum Replicas で設定された上限に達しています。
サービスが頻繁にスケールイン/アウト (ジッター) するのはなぜですか?
これは通常、スケーリングポリシーが不適切に設定されていることが原因です:
しきい値が敏感すぎる: しきい値が通常の負荷レベルに近すぎると、わずかな変動でもスケーリングイベントがトリガーされます。
スケールイン遅延が短すぎる: 遅延期間が短いと、システムは一時的なトラフィックの減少に過剰反応します。これにより、不要なスケールインが発生します。トラフィックが回復すると、すぐに別のスケールアウトがトリガーされます。スケールイン遅延を増やすことができます。
関連ドキュメント
スケジュールされた時間にレプリカ数を自動的にスケーリングするには、「スケジュールされたオートスケーリング」をご参照ください。
変化する要求に応じてリソースを柔軟に割り当てるには、「弾性リソースプール」をご参照ください。
カスタムモニタリングメトリックを使用してオートスケーリングの効果を監視するには、「カスタムモニタリングとスケーリングメトリック」をご参照ください。