このトピックでは、Kohyaベースのトレーニングサービスを例として使用し、独立展開方法または統合展開方法を使用してトレーニングサービスをスケーラブルなジョブとして展開する方法について説明します。 このトピックでは、スケーラブルなジョブを使用して、トレーニングの実行、トレーニング結果の取得、タスクの終了、および関連ログのクエリを行う方法についても説明します。
前提条件
トレーニングから取得したモデルファイルと構成ファイルを格納するために、Object Storage Service (OSS) バケットが作成されます。 バケットの作成方法については、「バケットの作成」をご参照ください。
トレーニングジョブをスケーラブルなジョブとして展開
このトピックでは、Platform for AI (PAI) が提供するkohya_ssイメージを例として使用して、Kohyaベースのトレーニングサービスをスケーラブルなジョブとしてデプロイする方法を説明します。
PAI コンソールにログインします。 ページ上部のリージョンを選択します。 次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS) の入力] をクリックします。
トレーニングサービスを展開します。
次の配置方法がサポートされています。
統合デプロイメント
キューサービス、常駐フロントエンドサービス、スケーラブルなジョブなど、Kohyaベースのトレーニングを統合的にデプロイします。 手順:
[サービスのデプロイ] をクリックします。 [カスタムモデルデプロイ] セクションで、[JSONデプロイ] をクリックします。
JSONエディターに設定情報を入力します。
{ "cloud": { "computing": { "instance_type": "ecs.gn6i-c4g1.xlarge" } }, "containers": [ { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "features": { "eas.aliyun.com/extra-ephemeral-storage": "30Gi" }, "front_end": { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:2.2", "port": 8001, "script": "python -u kohya_gui.py --listen 0.0.0.0 --server_port 8001 --data-dir /workspace --headless --just-ui --job-service" }, "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJobService" }, "name": "kohya_job", "storage": [ { "mount_path": "/workspace", "oss": { "path": "oss://examplebucket/kohya/", "readOnly": false }, "properties": { "resource_type": "model" } } ] }次の表に、上記のコードのパラメーターを示します。
パラメーター
説明
メタデータ
name
サービス名。 名前は地域内で一意です。
タイプ
サービスの種類を示します。 値をScalableJobServiceに設定します。これは、統合デプロイメントメソッドを指定します。
_webserviceの有効化
値をtrueに設定して、AIを利用したwebアプリケーションをデプロイします。
front_end
イメージ
フロントエンドインスタンスの実行に使用されるイメージ。 [PAIイメージ] をクリックし、イメージドロップダウンリストから [kohya_ss] を選択し、イメージバージョンドロップダウンリストから [2.2] を選択します。
説明イメージバージョンは頻繁に更新されます。 最新バージョンを選択することを推奨します。
スクリプト
フロントエンドインスタンスを起動するために使用されるコマンド。 値を
python -u kohya_gui.py -- listen 0.0.0.0 -- server_port 8000 -- headless -- just-ui -- job-serviceに設定します。 上記のコードのパラメーターの説明:-- listen: アプリケーションを指定されたローカルIPアドレスに関連付けて、外部要求を受信して処理します。
-- server_port: リスニングに使用されるポート番号。
-- just-ui: 独立したフロントエンドモードを有効にします。 フロントエンドサービスページには、サービスUIのみが表示されます。
-- job-service: トレーニングをスケーラブルなジョブとして実行します。
ポート
ポート番号 値は、containers.scriptのserver_portパラメーターの値と同じである必要があります。
コンテナー
イメージ
スケーラブルなジョブの実行に使用されるイメージ。 このパラメーターを指定しない場合、フロントエンドインスタンスの実行に使用されるイメージが使用されます。
instance_type
スケーラブルなジョブの実行に使用されるインスタンスタイプ。 GPU高速化インスタンスタイプが必要です。 このパラメーターを指定しない場合、cloud.com puting.instance_typeパラメーターで指定されたインスタンスタイプが使用されます。
ストレージ
パス
このトピックでは、Object Storage Service (OSS) を例として使用します。 同じリージョンにOSSパスを指定して、トレーニングで取得したモデルファイルを保存します。 例:
oss:// examplebucket/kohya/readOnly
このパラメーターを false に設定します。 そうしないと、モデルファイルをOSSに保存できません。
mount_path
マウントパス。 カスタムマウントパスを指定できます。 この例では、
/workspaceが使用されます。クラウド
instance_type
フロントエンドサービスの実行に使用されるインスタンスタイプ。 CPUタイプを選択します。
[デプロイ] をクリックします。
独立したデプロイ
スケーラブルなジョブとフロントエンドサービスを別々にデプロイします。 このようにして、スケーラブルなジョブは、複数のフロントエンドサービスからトレーニング要求を受信できます。 手順:
スケーラブルなジョブをデプロイします。
[サービスのデプロイ] をクリックします。 [カスタムモデルデプロイ] セクションで、[JSONデプロイ] をクリックします。
JSONエディターに設定情報を入力します。
{ "cloud": { "computing": { "instance_type": "ecs.gn6i-c4g1.xlarge" } }, "containers": [ { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "features": { "eas.aliyun.com/extra-ephemeral-storage": "30Gi" }, "metadata": { "instance": 1, "name": "kohya_scalable_job", "type": "ScalableJob" }, "storage": [ { "mount_path": "/workspace", "oss": { "path": "oss://examplebucket/kohya/", "readOnly": false }, "properties": { "resource_type": "model" } } ] }次の表に、上記のコードのパラメーターを示します。
パラメーター
説明
メタデータ
name
サービス名。 名前は地域内で一意です。
タイプ
サービスの種類を示します。 値をScalableJobに設定します。これは、Independent deploymentメソッドを指定します。
コンテナー
イメージ
スケーラブルなジョブの実行に使用されるイメージ。 [PAIイメージ] をクリックし、イメージドロップダウンリストから [kohya_ss] を選択し、イメージバージョンドロップダウンリストから [2.2] を選択します。
説明イメージバージョンは頻繁に更新されます。 最新バージョンを選択することを推奨します。
ストレージ
パス
このトピックでは、OSSを例として使用します。 同じリージョンにOSSパスを指定して、トレーニングで取得したモデルファイルを保存します。 例:
oss:// examplebucket/kohya/readOnly
このパラメーターを false に設定します。 そうしないと、モデルファイルをOSSに保存できません。
mount_path
マウントパス。 カスタムマウントパスを指定できます。 この例では。
/workspaceが使用されます。クラウド
instance_type
スケーラブルなジョブの実行に使用されるインスタンスタイプ。 Kohyaベースのトレーニングを実行するには、GPUアクセラレーションインスタンスタイプを選択する必要があります。
[デプロイ] をクリックします。
サービスのデプロイ後、[サービスタイプ] 列の [呼び出し情報] をクリックします。 [パブリックエンドポイント] タブで、サービスのエンドポイントとトークンを取得し、オンプレミスのデバイスに保存します。
必要に応じて、 フロントエンドサービスをデプロイします。
[サービスのデプロイ] をクリックします。 [カスタムモデルデプロイ] セクションで、[JSONデプロイ] をクリックします。
JSONエディターに設定情報を入力します。
{ "cloud": { "computing": { "instance_type": "ecs.g6.large" } }, "containers": [ { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:2.2", "port": 8000, "script": "python kohya_gui.py --listen 0.0.0.0 --server_port 8000 --headless --just-ui --job-service --job-service-endpoint 166233998075****.vpc.cn-hangzhou.pai-eas.aliyuncs.com --job-service-token test-token --job-service-inputname kohya_scalable_job" } ], "metadata": { "enable_webservice": true, "instance": 1, "name": "kohya_scalable_job_front" }, "storage": [ { "mount_path": "/workspace", "oss": { "path": "oss://examplebucket/kohya/", "readOnly": false }, "properties": { "resource_type": "model" } } ] }次の表に、上記のコードのパラメーターを示します。
パラメーター
説明
メタデータ
name
フロントエンドサービスの名前。
_webserviceの有効化
AIを利用したwebアプリケーションをデプロイするには、値をtrueに設定します。
コンテナー
イメージ
フロントエンドサービスの実行に使用されるイメージ。 [PAIイメージ] をクリックし、イメージドロップダウンリストから [kohya_ss] を選択し、イメージバージョンドロップダウンリストから [2.2] を選択します。
説明イメージバージョンは頻繁に更新されます。 最新バージョンを選択することを推奨します。
スクリプト
フロントエンドサービスを開始するために使用されるコマンド。 例:
python kohya_gui.py -- listen 0.0.0.0 -- server_port 8000 -- headless-just-ui -- job-service -- job-service-endpoint 166233998075 **** .vpc.cn-hangzhou.pai-eas.aliyuncs.com -- job-service-token test-token -- job-service-inputname kohya_scaled_job上記のコードのパラメーターの説明:-- listen: アプリケーションを指定されたローカルIPアドレスに関連付けて、外部要求を受信して処理します。
-- server_port: リスニングに使用されるポート番号。
-- just-ui: 独立したフロントエンドモードを有効にします。 フロントエンドサービスページには、サービスUIのみが表示されます。
-- job-service: トレーニングをスケーラブルなジョブとして実行します。
-- job-service-endpoint: スケーラブルなジョブのエンドポイント。
-- job-service-token: スケーラブルなジョブのトークン。
-- job-service-inputname: スケーラブルなジョブのサービス名。
ポート
ポート番号 値は、containers.scriptのserver_portパラメーターの値と同じである必要があります。
ストレージ
パス
このトピックでは、OSSを例として使用します。 同じリージョンにOSSパスを指定して、トレーニングで取得したモデルファイルを保存します。 例:
oss:// examplebucket/kohya/readOnly
このパラメーターを false に設定します。 そうしないと、モデルファイルをOSSに保存できません。
mount_path
マウントパス。 カスタムマウントパスを指定できます。 この例では。
/workspaceが使用されます。クラウド
instance_type
フロントエンドサービスの実行に使用されるインスタンスタイプ。 CPUタイプを選択します。
[デプロイ] をクリックします。
Kohyaベースのトレーニングサービスを呼び出す
webアプリケーションを使用したスケーラブルなジョブサービスの呼び出し
EASのプリセットkohya_ssイメージ (2.2以降) を使用してフロントエンドサービスをデプロイする場合は、サービスをデプロイした後、[サービスタイプ] 列の [Webアプリの表示] をクリックします。 webアプリケーションページで、低ランク適応 (LoRA) トレーニングのパラメーターを設定します。 詳細については、「Kohya_ssを使用したLoRA SDモデルのEASでのデプロイ」をご参照ください。
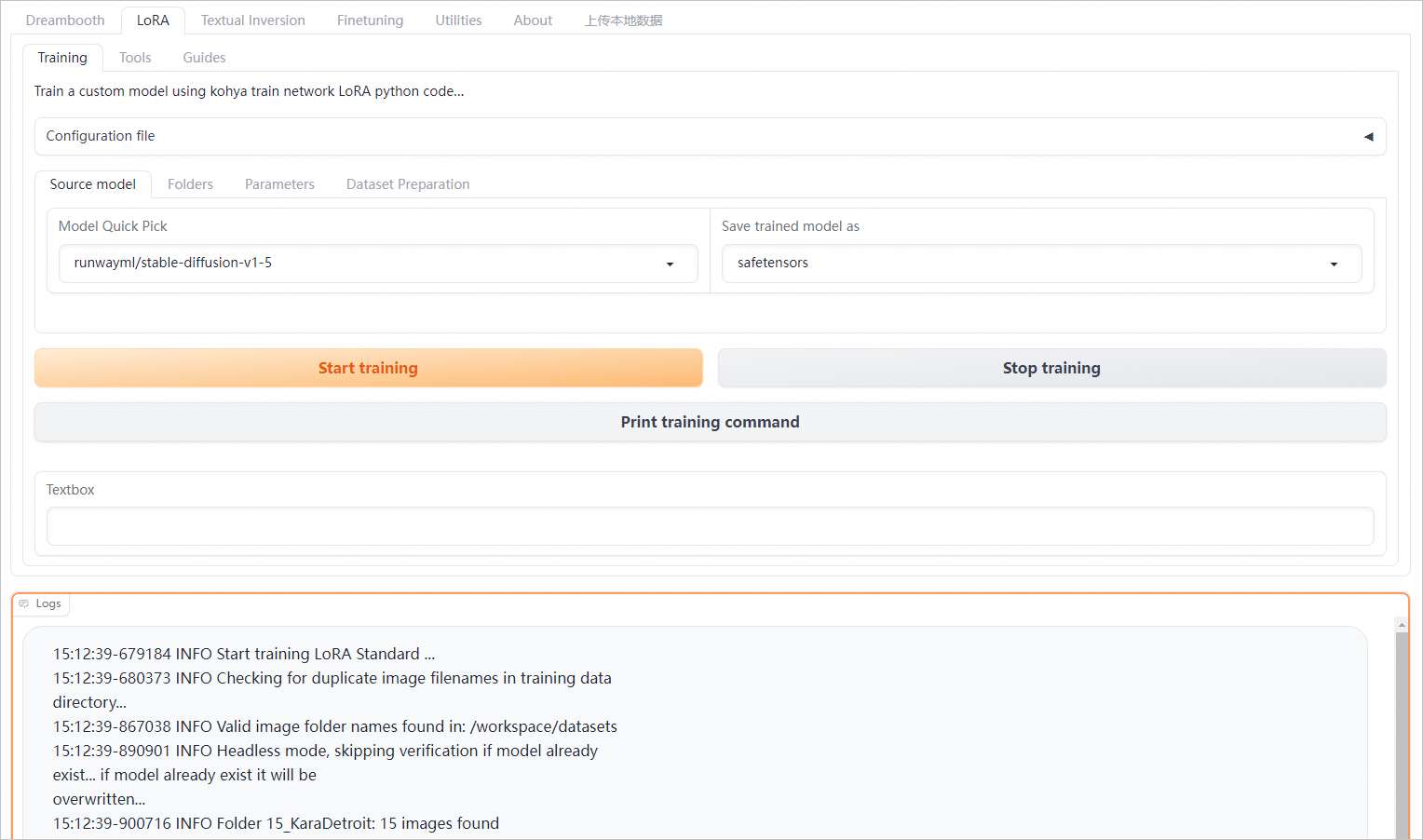
[トレーニングの開始] をクリックして、トレーニングリクエストを送信します。 トレーニングが完了または終了する前に、ボタンを1回だけクリックします。 スケーラブルなジョブは、トレーニングセッションの数に基づいて自動的にスケーリングされます。
[トレーニングの停止] をクリックして、現在のトレーニングタスクを終了します。
カスタムイメージを使用するスケーラブルなジョブサービスの呼び出し
SDK for Pythonを使用して、スケーラブルなジョブを呼び出すことができます。 コマンド要求を送信し、タスク実行ログを取得します。 web UIを使用してサービスを呼び出し、カスタムイメージを使用してフロントエンドサービスをデプロイする場合も、次のインターフェイスを実装する必要があります。 サービスをデプロイした後、web UIを使用してスケーラブルなジョブを呼び出すことができます。 手順:
スケーラブルなジョブサービスのエンドポイントとトークンを取得します。
統合デプロイメント
[Elastic Algorithm Service (EAS)] ページで、サービス名をクリックして [サービスの詳細] ページに移動します。 [基本情報] セクションで、[エンドポイント情報の表示] をクリックします。 [パブリックエンドポイント] タブで、サービスのエンドポイントとトークンを取得し、オンプレミスのデバイスに保存します。 注:
サービスエンドポイントは、
<queue_name>.<service_name>.<uid>.<regio n>.pai-eas.aliyuncs.com形式です。 例:kohya-job-queue-b **** 4f0.kohya-job.175805416243 **** .cn-beijing.pai-eas.aliyuncs.com<queue_name>は、キューサービスのインスタンス名の-0より前の部分です。 インスタンス名は、[サービスの詳細] ページのサービスインスタンスリストで確認できます。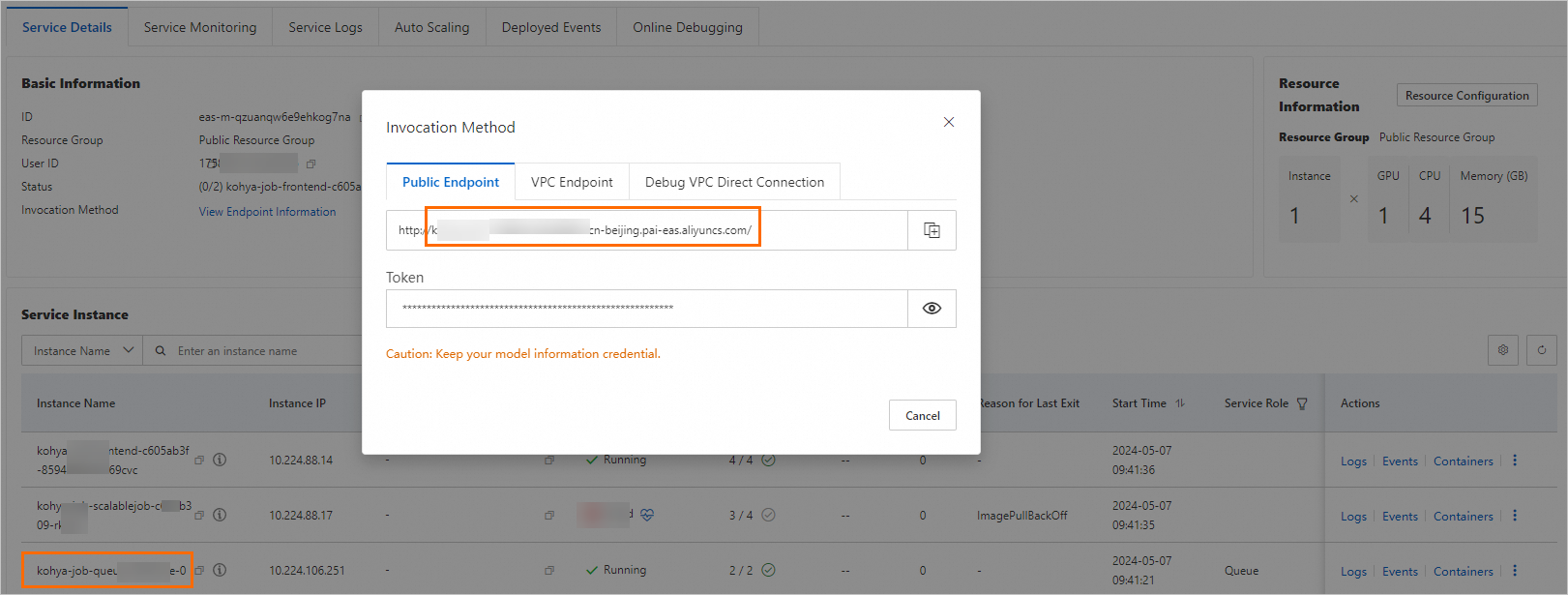
サンプルトークン:
OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT ****==
独立したデプロイ
[Elastic Algorithm Service (EAS)] ページで、サービスの [サービスタイプ] 列の [呼び出し方法] をクリックして、エンドポイントとトークンを取得します。 注:
サンプルサービスエンドポイント:
175805416243 **** .cn-beijing.pai-eas.aliyuncs.comサンプルトークン:
Njk5NDU5MGYzNmRlZWQ3ND **** QyMDIzMGM4MjExNmQ1NjE1NzY5Mw==
SDK for Pythonをインストールします。
pip install -U eas-prediction --userSDK For Pythonの詳細については、「SDK for Python」をご参照ください。
入力キューと出力キューのクライアントを作成します。
統合デプロイメント
from eas_prediction import QueueClient if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # Create an input queue to send training requests and termination requests for command tasks. inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Create an output queue to obtain the execution status and logs of the command tasks. sinkQueue = QueueClient(custom_url = sink_url) sinkQueue.set_token(token) sinkQueue.init()上記のコードのパラメーターの説明:
tokenを前の手順で取得したトークンに置き換えます。
input_urlを、前の手順で取得したサービスエンドポイントに置き換えます。
独立したデプロイ
from eas_prediction import QueueClient if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'YmE3NDkyMzdiMzNmMGM3ZmE4ZmNjZDk0M2NiMDA3OT****c1MTUxNg==' input_name = 'kohya_scalable_job' sink_name = input_name + '/sink' # Create an input queue to send training requests and termination requests for command tasks. inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init() # Create an output queue to obtain the execution status and logs of the command tasks. sinkQueue = QueueClient(endpoint, sink_name) sinkQueue.set_token(token) sinkQueue.init()上記のコードのパラメーターの説明:
endpointを前の手順で取得したサービスエンドポイントに置き換えます。
tokenを前の手順で取得したサービストークンに置き換えます。
input_nameをスケーラブルなジョブサービスの名前に設定します。
トレーニングリクエストを入力キューに送信します。
統合デプロイメント
from eas_prediction import QueueClient import uuid if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # Create an input queue client to send command requests. inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Generate a unique task ID for each task request. task_id = uuid.uuid1().hex # Create a command string. cmd = "for i in {1..10}; do date; sleep 1; done;" # Set the taskType parameter to command and specify the task ID. tags = {"taskType": "command", "taskId": task_id} # Send a training request to the input queue. index, request_id = inputQueue.put(cmd, tags) print(f'send index: {index}, request id: {request_id}')次の表に、上記のコードのパラメーターを示します。
パラメーター
説明
トークン
値を前の手順で取得したトークンに置き換えます。
input_url
値を、前の手順で取得したサービスエンドポイントに置き換えます。
cmd
実行するコマンドを指定します。 Pythonコマンドを使用する場合は、-uパラメーターを追加して、タスク実行ログをリアルタイムで取得する必要があります。
tags
トレーニングリクエストの場合:
taskType: 値をcommandに設定します。
taskId: トレーニングタスクを一意に識別するトレーニングタスクのID。
独立したデプロイ
from eas_prediction import QueueClient import uuid if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'M2EyNWYzNDJmNjQ5ZmUzMmM0OTMyMzgzYj****djN2IyODc1MTM5ZQ==' input_name = 'kohya_scalable_job' # Create an input queue client to send command requests. inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Generate a unique task ID for each task request. task_id = uuid.uuid1().hex # Create a command string. cmd = "for i in {1..10}; do date; sleep 1; done;" # Set the taskType parameter to command and specify the task ID. tags = {"taskType": "command", "taskId": task_id} # Send a training request to the input queue. index, request_id = inputQueue.put(cmd, tags) print(f'send index: {index}, request id: {request_id}')次の表に、上記のコードのパラメーターを示します。
パラメーター
説明
エンドポイント
値を前の手順で取得したエンドポイントに置き換えます。
トークン
値を前の手順で取得したサービストークンに置き換えます。
cmd
実行するコマンドを指定します。 Pythonコマンドを使用する場合は、-uパラメーターを追加して、タスク実行ログをリアルタイムで取得する必要があります。
tags
トレーニングリクエストの場合:
taskType: 値をcommandに設定します。
taskId: トレーニングタスクを一意に識別するトレーニングタスクのID。
リクエストのキューステータスを照会します。
統合デプロイメント
from eas_prediction import QueueClient import uuid if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # Create an input queue client to send command requests. inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Send a command request to the input queue. task_id = uuid.uuid1().hex cmd = "for i in {1..100}; do date; sleep 1; done;" tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) # Query the queuing status of the requests. search_info = inputQueue.search(index) print("index: {}, search info: {}".format(index, search_info))上記のコードのパラメーターの説明:
tokenを前の手順で取得したトークンに置き換えます。
input_urlを、前の手順で取得したサービスエンドポイントに置き換えます。
独立したデプロイ
from eas_prediction import QueueClient import uuid if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'M2EyNWYzNDJmNjQ5ZmUzMmM0OTMyMzgzYjBjOTdjN2I****1MTM5ZQ==' input_name = 'kohya_scalable_job' # Create an input queue client to send command requests. inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Send a command request to the input queue. task_id = uuid.uuid1().hex cmd = "for i in {1..100}; do date; sleep 1; done;" tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) # Query the queuing status of the requests. search_info = inputQueue.search(index) print("index: {}, search info: {}".format(index, search_info))上記のコードのパラメーターの説明:
endpointを前の手順で取得したエンドポイントに置き換えます。
tokenを前の手順で取得したサービストークンに置き換えます。
JSON形式のサンプル応答:
{ 'IsPending': False, 'WaitCount': 0 }次の表に、レスポンスのフィールドを示します。
項目
説明
保留中
リクエストが処理中かどうかを示します。 有効な値:
True: リクエストは処理中です。
False: リクエストはキューにあり、処理待ちです。
ウェイトカウント
キュー内のリクエストのシーケンス。 このパラメーターは、IsPendingパラメーターをFalseに設定した場合にのみ有効です。 IsPendingパラメーターをTrueに設定した場合、値は0になります。
出力キューから実行結果を取得します。
トレーニングタスクの実行ログは、リアルタイムで出力キューに書き込まれます。
queue.get(request_id=request_id, length=1, timeout=0s', tags=tags)メソッドを呼び出して、指定されたタスクIDを持つトレーニングタスクのログを取得できます。 サンプルコード:統合デプロイメント
from eas_prediction import QueueClient import json import uuid if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # Create an input queue client to send command requests. inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Create an output queue client to obtain command execution logs. sinkQueue = QueueClient(custom_url = sink_url) sinkQueue.set_token(token) sinkQueue.init() # Send a command request to the input queue. cmd = "for i in {1..10}; do date; sleep 1; done;" task_id = uuid.uuid1().hex tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) # Obtain the logs of the training task that has the specified task ID from the output queue in real time. running = True while running: dfs = sinkQueue.get(length=1, timeout='0s', tags=tags) if len(dfs) == 0: continue df = dfs[0] data = json.loads(df.data.decode()) state = data["state"] print(data.get("log", "")) if state in {"Exited", "Stopped", "Fatal", "Backoff"}: running = False上記のコードのパラメーターの説明:
tokenを前の手順で取得したトークンに置き換えます。
input_urlを、前の手順で取得したサービスエンドポイントに置き換えます。
独立したデプロイ
from eas_prediction import QueueClient import json import uuid if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'M2EyNWYzNDJmNjQ5ZmUzMmM0OTMyMzgzYjBjOTdjN2IyOD****M5ZQ==' input_name = 'kohya_scalable_job' sink_name = input_name + '/sink' # Create an input queue client to send command requests. inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Create an output queue client to obtain command execution logs. sinkQueue = QueueClient(endpoint, sink_name) sinkQueue.set_token(token) sinkQueue.init() # Send a command request to the input queue. cmd = "for i in {1..10}; do date; sleep 1; done;" task_id = uuid.uuid1().hex tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) # Obtain the logs of the training task that has the specified task ID from the output queue in real time. running = True while running: dfs = sinkQueue.get(length=1, timeout='0s', tags=tags) if len(dfs) == 0: continue df = dfs[0] data = json.loads(df.data.decode()) state = data["state"] print(data.get("log", "")) if state in {"Exited", "Stopped", "Fatal", "Backoff"}: running = False上記のコードのパラメーターの説明:
endpointを前の手順で取得したエンドポイントに置き換えます。
tokenを前の手順で取得したサービストークンに置き換えます。
BYTES形式のサンプル応答:
{ "taskId": "e97409eea4a111ee9cb600163e08****", "command": "python3 -u test.py --args=xxx", "state": "Running", "log": "prepare tokenizer\\n" }次の表に、レスポンスのフィールドを示します。
項目
説明
taskId
タスクのID。
コマンド
タスクによって実行されるコマンド。
state
コマンドの実行状態。 有効な値:
Running: タスクは実行中です。
有効: タスクが終了しました。
Fatal: タスクで例外が発生しました。
Stopping: タスクは停止中です。
Stopped: タスクは停止しています。
ログ
ログ。 ログの取得順に同じタスクIDのログが生成されます。
トレーニングタスクを停止します。
リクエストの送信後にトレーニングタスクを停止する場合は、リクエストのステータスが [キュー] か [実行中] かを確認する必要があります。 queue.search(index) メソッドを使用して、リクエストのステータスを取得します。 例:
統合デプロイメント
from eas_prediction.queue_client import QueueClient import uuid if __name__ == '__main__': token = 'OGZlNzQwM2VlMWUyM2E2ZTAyMGRjOGQ5MWMyOTFjZGExNDgwMT****==' input_url = 'kohya-job-queue-bf****f0.kohya-job.175805416243****.cn-hangzhou.pai-eas.aliyuncs.com' sink_url = input_url + '/sink' # Create an input queue client to send command requests and terminate requests. inputQueue = QueueClient(custom_url = input_url) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Send a command request to the input queue. cmd = "for i in {1..10}; do date; sleep 1; done;" task_id=uuid.uuid1().hex# The task_id of the request. tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) print(f'cmd send, index: {index}, task_id: {task_id}') job_index=index# The index returned after you send the task request. pending_detail = inputQueue.search(job_index) print(f'search info: {pending_detail}') if len(pending_detail) > 0 and pending_detail.get("IsPending", True) == False: # The command task is in the queue and is deleted from the input queue. inputQueue.delete(job_index) print(f'delete task index: {job_index}') else: # The command task is being run. The system sends a stop signal to the input queue. stop_data = "stop" tags = {"_is_symbol_": "true", "taskId": task_id} inputQueue.put(stop_data, tags) print(f'stop task index: {job_index}')次の表に、上記のコードのパラメーターを示します。
パラメーター
説明
トークン
値を前の手順で取得したトークンに置き換えます。
input_url
値を、前の手順で取得したサービスエンドポイントに置き換えます。
stop_data
値をstopに設定します。
tags
_is_symbol_: 値をtrueに設定してタスクを終了します。 This parameter is required.
task_id: 終了するタスクのID。
独立したデプロイ
from eas_prediction.queue_client import QueueClient import uuid if __name__ == '__main__': endpoint = '166233998075****.cn-hangzhou.pai-eas.aliyuncs.com' token = 'M2EyNWYzNDJmNjQ5ZmUzMmM0OTMyMzgzYjBjOTdjN2IyODc1MTM5****' input_name = 'kohya_scalable_job' # Create an input queue client to send command requests and terminate requests. inputQueue = QueueClient(endpoint, input_name) inputQueue.set_token(token) inputQueue.init(gid="superwatcher") # Send a command request to the input queue. cmd = "for i in {1..10}; do date; sleep 1; done;" # The task_id of the request. task_id = uuid.uuid1().hex tags = {"taskType": "command", "taskId": task_id} index, request_id = inputQueue.put(cmd, tags) print(f'cmd send, index: {index}, task_id: {task_id}') job_index=index# The index returned after you send the task request. pending_detail = inputQueue.search(job_index) print(f'search info: {pending_detail}') if len(pending_detail) > 0 and pending_detail.get("IsPending", True) == False: # The command task is in the queue and is deleted from the input queue. inputQueue.delete(job_index) print(f'delete task index: {job_index}') else: # The command task is being run. The system sends a stop signal to the input queue. stop_data = "stop" tags = {"_is_symbol_": "true", "taskId": task_id} inputQueue.put(stop_data, tags) print(f'stop task index: {job_index}')次の表に、上記のコードのパラメーターを示します。
パラメーター
説明
エンドポイント
値を前の手順で取得したエンドポイントに置き換えます。
トークン
値を前の手順で取得したサービストークンに置き換えます。
stop_data
値をstopに設定します。
tags
_is_symbol_: 値をtrueに設定してタスクを終了します。 This parameter is required.
task_id: 終了するタスクのID。
関連ドキュメント
スケーラブルジョブサービスの詳細については、「概要」をご参照ください。
推論サービスをスケーラブルなジョブとして展開する方法については、「オンラインポートレートサービスをスケーラブルなジョブとして展開する」をご参照ください。