Machine Learning Designer は、パイプラインを使用してモデルを構築およびデバッグします。ビジネス要件に基づいて、パイプラインを作成し、パイプラインにさまざまなコンポーネントを追加する必要があります。このトピックでは、心臓病予測の二項分類モデルを構築するために、空のパイプラインが作成されます。
前提条件
ワークスペースを MaxCompute リソースに 関連付けました。
ステップ 1: パイプラインを作成する
ビジュアル モデリング (Designer) に移動し、ワークスペースを選択して、ビジュアル モデリング (Designer) ページに入ります。表示されるページで、パイプラインを作成して開きます。
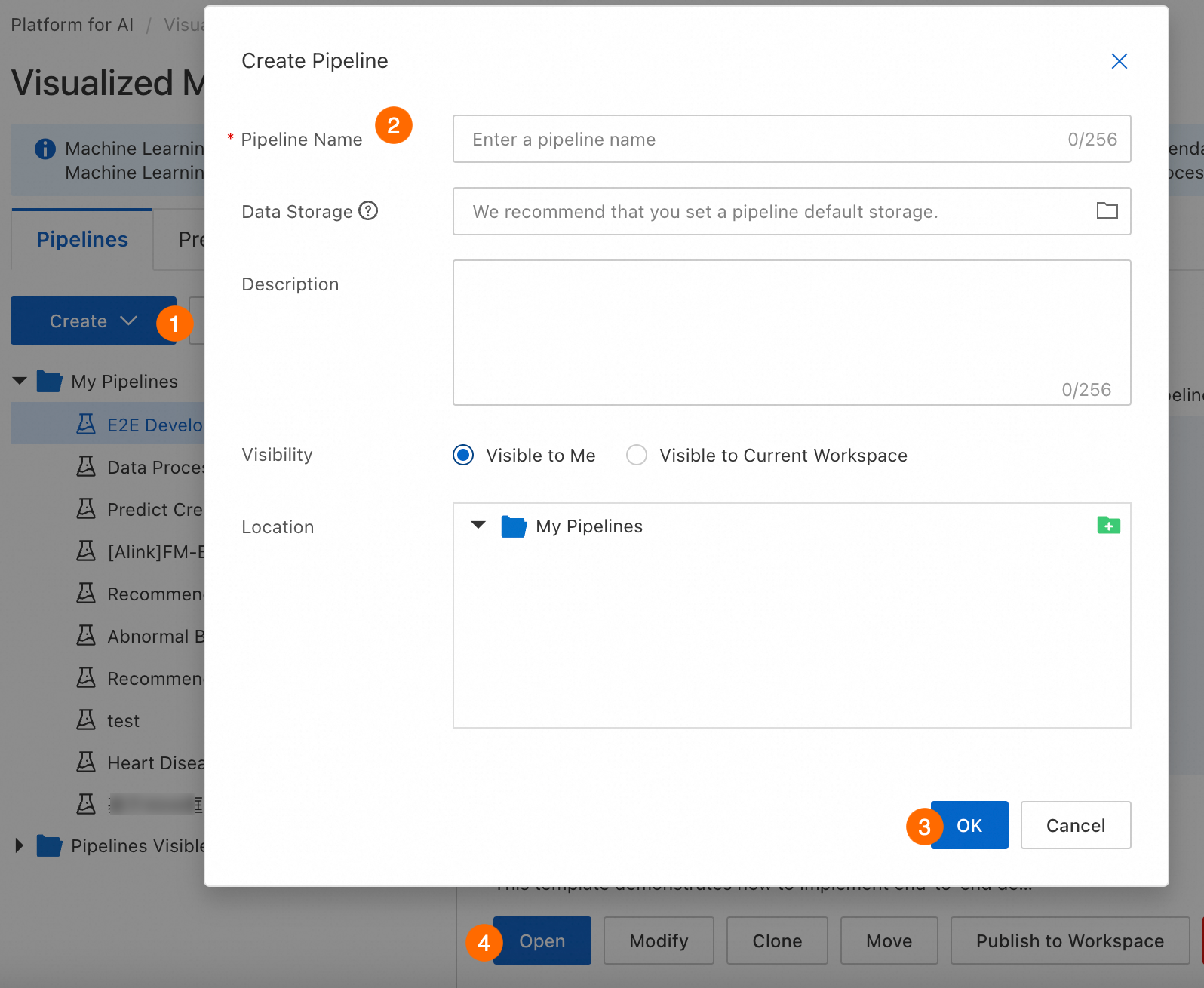
パラメーター | 説明 |
パイプライン名 | カスタム名を入力します。 |
データ ストレージ | 実行中に一時データとモデルを保存するために、このパラメーターを OSS バケット パスに設定することをお勧めします。指定しない場合は、ワークスペースのデフォルト ストレージが使用されます。 システムは、実行ごとに |
可視性 |
|
ステップ 2: データを準備および前処理する
モデルを構築する前に、データ ソースを準備し、データの前処理を完了します。これは、ビジネス要件に基づいた後続のモデル トレーニングに役立ちます。
データを準備する
作成したパイプラインで、[データ ソース/ターゲット] カテゴリのコンポーネントを追加して、MaxCompute や Object Storage Service (OSS) などのデータ ソースからデータを読み取ります。詳細については、コンポーネント リファレンス: データ ソースまたはデスティネーション の下の特定のコンポーネント ドキュメントをご参照ください。このトピックでは、[テーブルの読み取り] コンポーネントを使用して、PAI によって提供される心臓病症例に関連する公開データを読み取ります。データセットの詳細については、心臓病データセット をご参照ください。
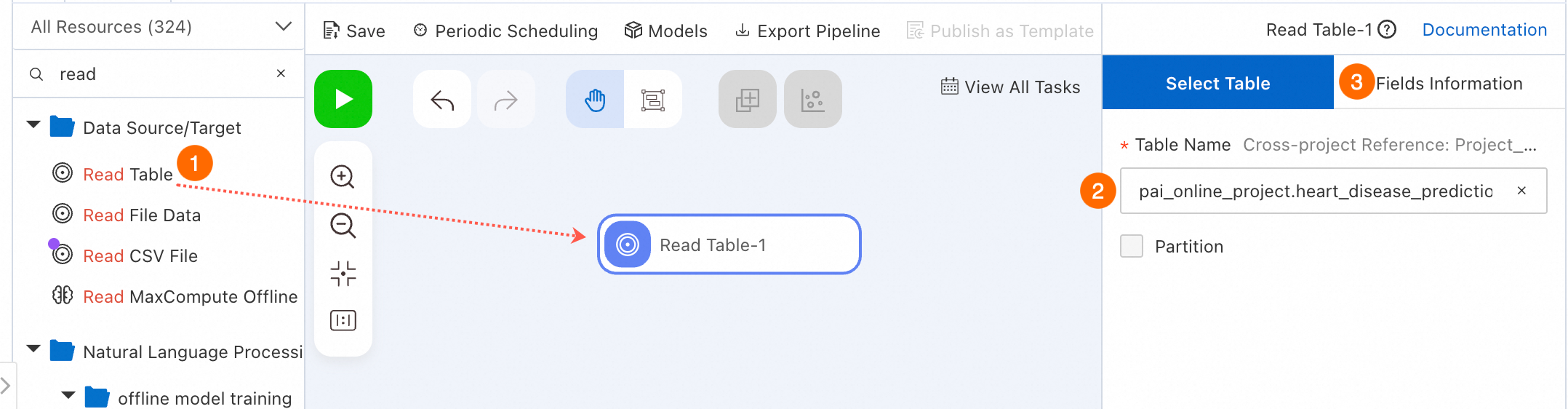
[データ ソース/ターゲット] カテゴリの データソース/ターゲット コンポーネントに適切なテーブルを選択して、データを読み取ります。
左側のコンポーネント リストで、[データ ソース/ターゲット] をクリックし、[テーブルの読み取り] コンポーネントを右側のキャンバスにドラッグして、MaxCompute テーブル データを読み取ります。[テーブルの読み取り-1] という名前のパイプライン ノードがキャンバスに自動的に生成されます。
ノード設定ページでソース データ テーブルを構成します。
キャンバス上の [テーブルの読み取り-1] ノードをクリックし、右側のノード設定セクションの [テーブル名] フィールドに MaxCompute テーブル名を入力します。このトピックでは、
pai_online_project.heart_disease_predictionテーブルを使用して、PAI によって提供される心臓病症例に関連する公開データを読み取ります。ノード設定セクションの [フィールド情報] タブに切り替えて、公開データのフィールドの詳細を表示します。
データを前処理する
このトピックで説明する心臓病予測は、二項分類問題です。ロジスティック回帰モデル コンポーネントには、DOUBLE または BIGINT タイプの入力データが必要です。このセクションでは、モデル トレーニングのために心臓病症例に関連するデータに対して、データ型変換などの前処理操作を実行する方法について説明します。
データの前処理: 数値以外のフィールドを数値フィールドに変換します。
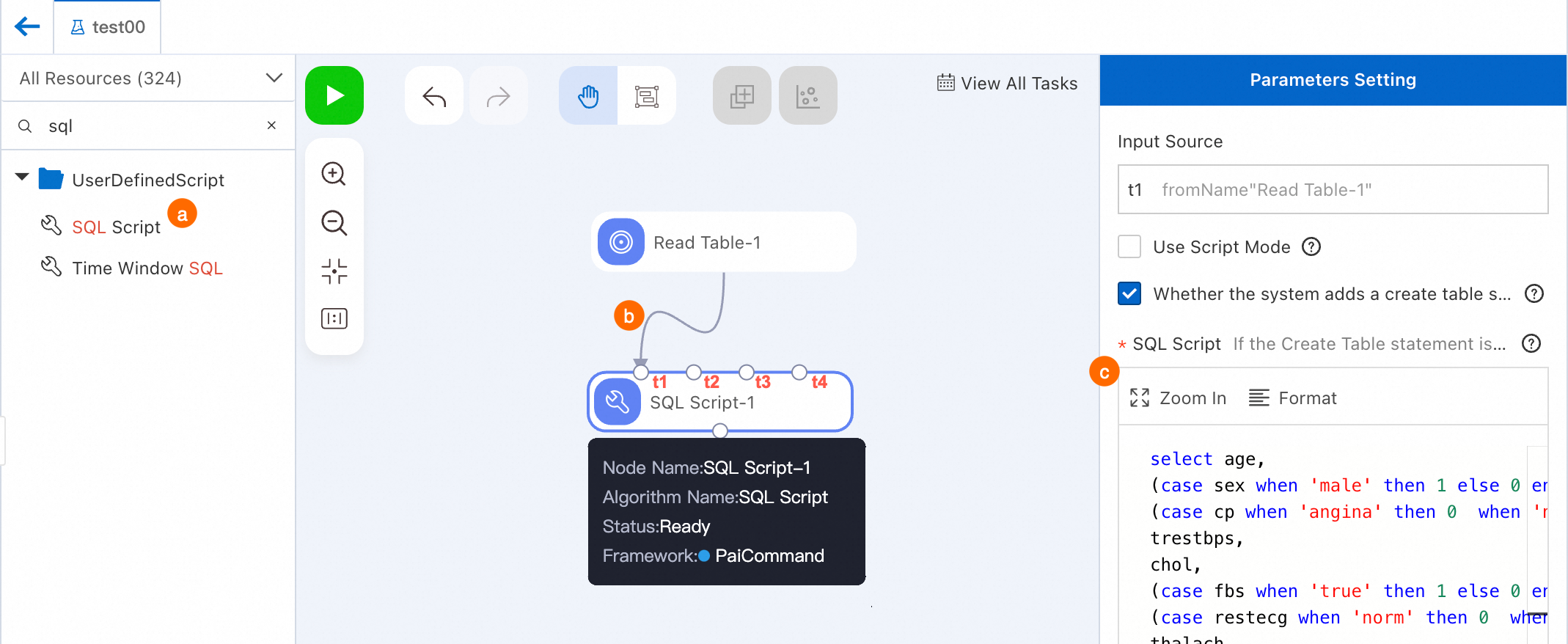
[SQL スクリプト] コンポーネントを検索してキャンバスにドラッグします。[SQL スクリプト-1] という名前のパイプライン ノードが生成されます。
[テーブルの読み取り-1] ノードから [SQL スクリプト-1] ノードの [t1] 入力ポートに線を引きます。このようにして、[テーブルの読み取り-1] ノードは [SQL スクリプト-1] ノードのデータ ソースになります。
[SQL スクリプト-1] ノードを構成します。
[SQL スクリプト-1] ノードをクリックし、右側の SQL スクリプト エディターに次のコードを入力します。[パラメーター設定] タブで、[入力ソース] フィールドに t1 が表示されます。
select age, (case sex when 'male' then 1 else 0 end) as sex, (case cp when 'angina' then 0 when 'notang' then 1 else 2 end) as cp, trestbps, chol, (case fbs when 'true' then 1 else 0 end) as fbs, (case restecg when 'norm' then 0 when 'abn' then 1 else 2 end) as restecg, thalach, (case exang when 'true' then 1 else 0 end) as exang, oldpeak, (case slop when 'up' then 0 when 'flat' then 1 else 2 end) as slop, ca, (case thal when 'norm' then 0 when 'fix' then 1 else 2 end) as thal, (case status when 'sick' then 1 else 0 end) as ifHealth from ${t1};キャンバスの左上隅にある [保存] をクリックして、パイプライン設定を保存します。
[SQL スクリプト-1] コンポーネントを右クリックし、[ルート ノードからここまで実行] をクリックして、パイプラインをデバッグおよび実行します。
パイプラインの各ノードは順番に実行されます。ノードが期待どおりに実行されると、ノードの右上隅に表示されるノード ボックスに
 アイコンが表示されます。説明
アイコンが表示されます。説明キャンバスの左隅にある
 (実行) アイコンをクリックして、パイプライン全体を実行することもできます。パイプラインが複雑な場合は、コンポーネントに基づいて特定のノードまたは一部のノードを実行することをお勧めします。これは、パイプラインのデバッグに役立ちます。ノードが実行に失敗した場合は、ノードを右クリックして [ログの表示] を選択し、障害を診断します。
(実行) アイコンをクリックして、パイプライン全体を実行することもできます。パイプラインが複雑な場合は、コンポーネントに基づいて特定のノードまたは一部のノードを実行することをお勧めします。これは、パイプラインのデバッグに役立ちます。ノードが実行に失敗した場合は、ノードを右クリックして [ログの表示] を選択し、障害を診断します。パイプラインの実行後、[SQL スクリプト-1] などのノードを右クリックし、 を選択して、ノードの出力データが正しいかどうかを確認します。
データの前処理: ロジスティック回帰モデルの入力データ要件を満たすために、フィールドを DOUBLE データ型に変換します。
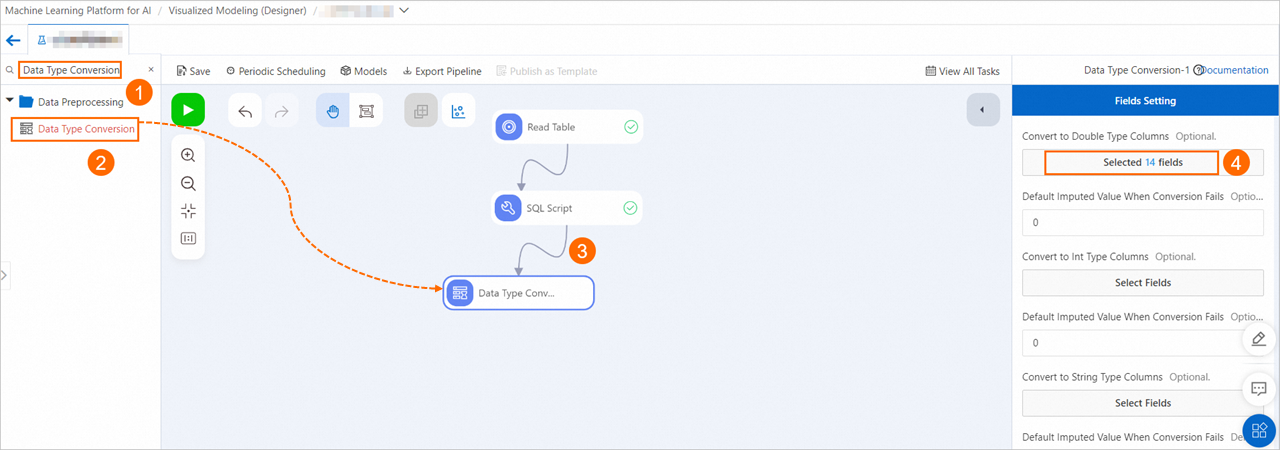
[データ型変換] コンポーネントをキャンバスにドラッグし、前の手順を参照して [SQL Script-1] ノードを [データ型変換-1] ノードに接続します。このようにして、[データ型変換-1] ノードは [SQL Script-1] ノードの下流ノードになります。 [データ型変換-1] ノードをクリックします。 [フィールド設定] タブで、[倍精度型列に変換] フィールドの [フィールドの選択] をクリックし、すべてのフィールドを選択して、フィールドを DOUBLE データ型に変換します。
データの前処理: 各特徴の値を 0 から 1 までの値に変換するために、データを正規化します。これにより、予測結果に対する次元の影響がなくなります。
[正規化] コンポーネントをキャンバスにドラッグし、前の手順を参照して [データ型変換 - 1] ノードを正規化 - 1 ノードに接続します。このようにして、正規化 - 1 ノードはデータ型変換 - 1 ノードの下流ノードになります。 正規化 - 1 ノードをクリックします。 [フィールド設定] タブで、すべてのフィールドを選択します。
データの前処理: 後続のモデル トレーニングと予測のために、データをトレーニング データセットと予測データセットに分割します。
[分割] コンポーネントをキャンバスにドラッグし、[正規化 - 1] ノードを [分割 - 1] ノードに接続します。このようにして、[分割 - 1] ノードは [正規化 - 1] ノードの下流ノードになります。 [分割 - 1] ノードが実行されると、2 つのデータテーブルが生成されます。
デフォルトでは、[分割] コンポーネントは、データをモデル トレーニング セットとモデル予測セットに 4:1 の比率で分割します。[分割-1] ノードをクリックします。右側の [パラメーター設定] タブで、[分割率] パラメーターを指定します。その他のパラメーターの詳細については、分割 をご参照ください。
[データ型変換-1] ノードを右クリックし、[ここから実行] をクリックして、[データ型変換-1] ノードからパイプライン内のノードを実行します。
ステップ 3: モデルをトレーニングする
各サンプルでは、各患者は病気であるか健康です。したがって、心臓病予測は二項分類問題です。このセクションでは、二項分類のロジスティック回帰コンポーネントを使用して心臓病予測モデルを構築する方法について説明します。
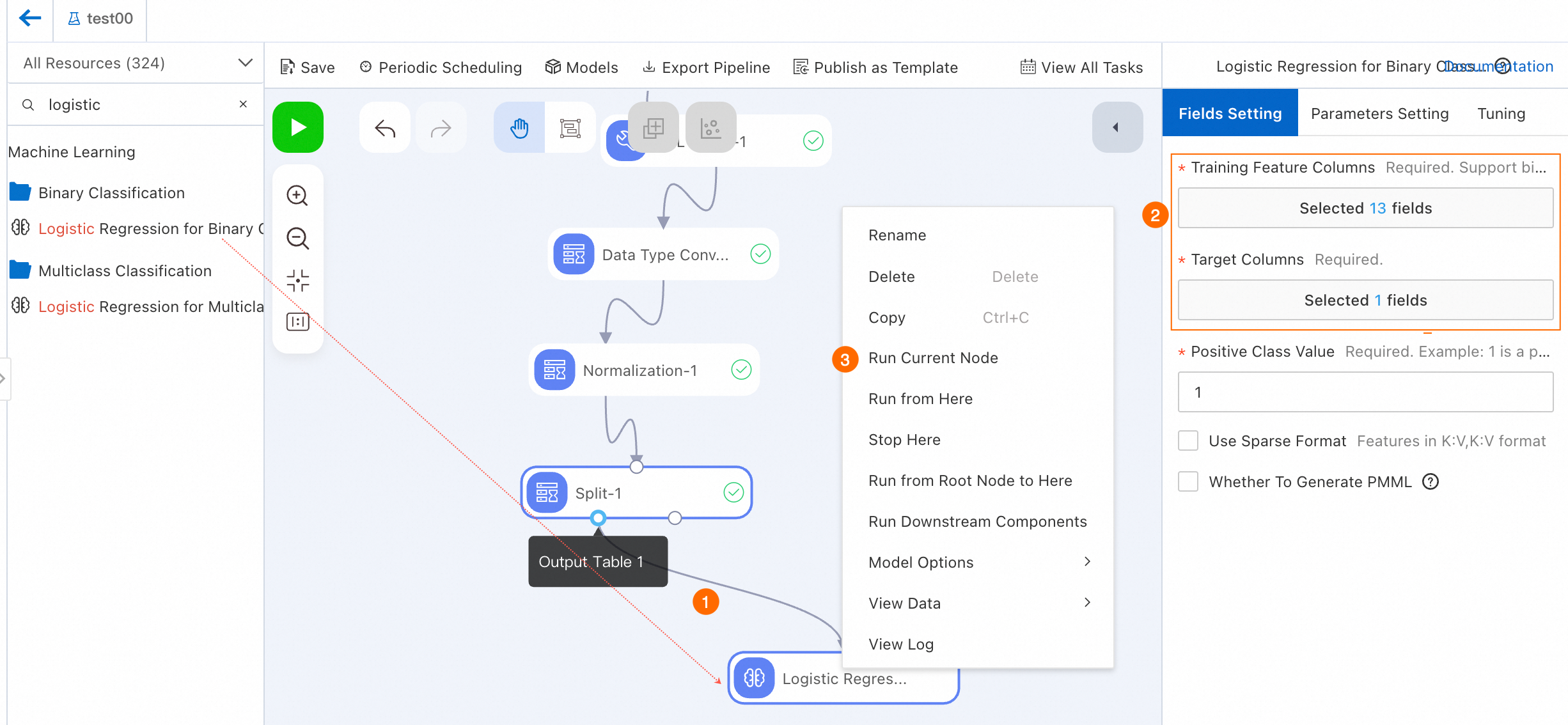
[ロジスティック回帰 (二項分類)] コンポーネントをキャンバスにドラッグし、Split-1 ノードの Output Table 1 を Logistic Regression for Binary Classification-1 ノードに接続します。このようにして、Logistic Regression for Binary Classification-1 ノードは Split-1 ノードの Output Table 1 のダウンストリームノードになります。
[二項分類のロジスティック回帰-1] ノードを構成します。
[二項分類のロジスティック回帰-1] ノードをクリックします。右側の [フィールド設定] タブで、[ターゲット列] パラメーターの [ifhealth] フィールドを選択し、[トレーニング特徴列] パラメーターの [ターゲット列] パラメーターの値を除くすべてのフィールドを選択します。その他のパラメーターの詳細については、二項分類のロジスティック回帰 をご参照ください。
説明(オプション) ステップ 6: モデルをデプロイする の手順に従ってモデルをデプロイする必要がある場合は、[二項分類のロジスティック回帰-1] コンポーネントをクリックします。[フィールド設定] タブで、[PMML を生成するかどうか] を選択します。
[二項分類のロジスティック回帰] ノードを実行します。
ステップ 4: モデルを使用して予測する
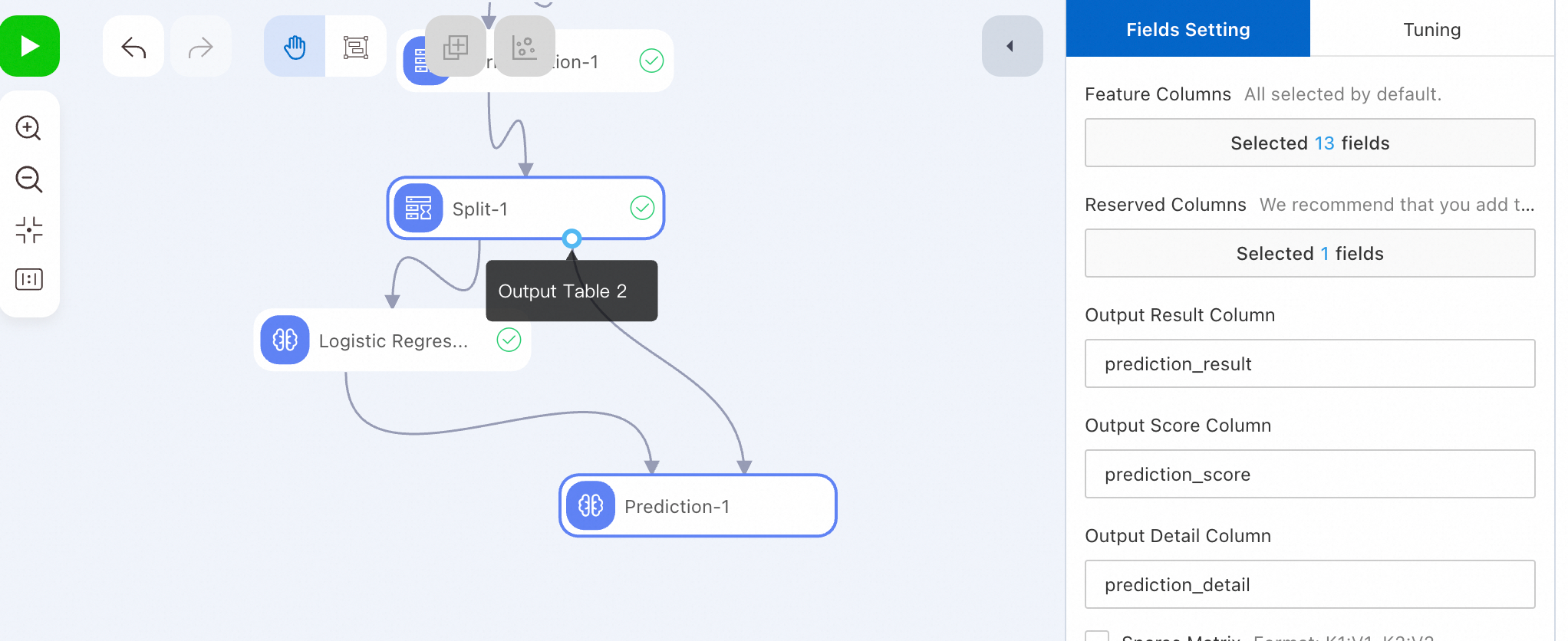
[予測-1] ノードを実行し、予測結果を表示します。
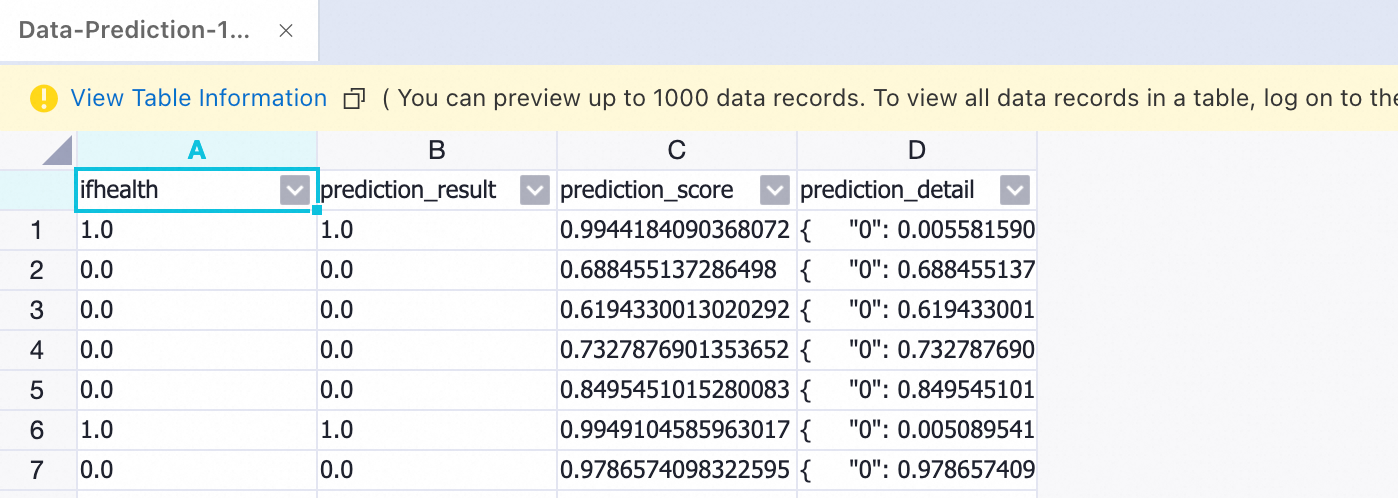
[予測-1] ノードの実行後、 [予測-1] ノードを右クリックし、 を選択して、予測データを表示します。
ステップ 5: モデルを評価する
[二項分類評価] コンポーネントをキャンバスにドラッグし、Prediction-1 ノードを Binary Classification Evaluation-1 ノードに接続します。このようにして、Binary Classification Evaluation-1 ノードは Prediction-1 ノードの下流ノードになります。
バイナリ分類の評価-1サーバーレス関数注:元のラベル列 ノードをクリックします。右側の タブで、 パラメーターの フィールドを選択します。
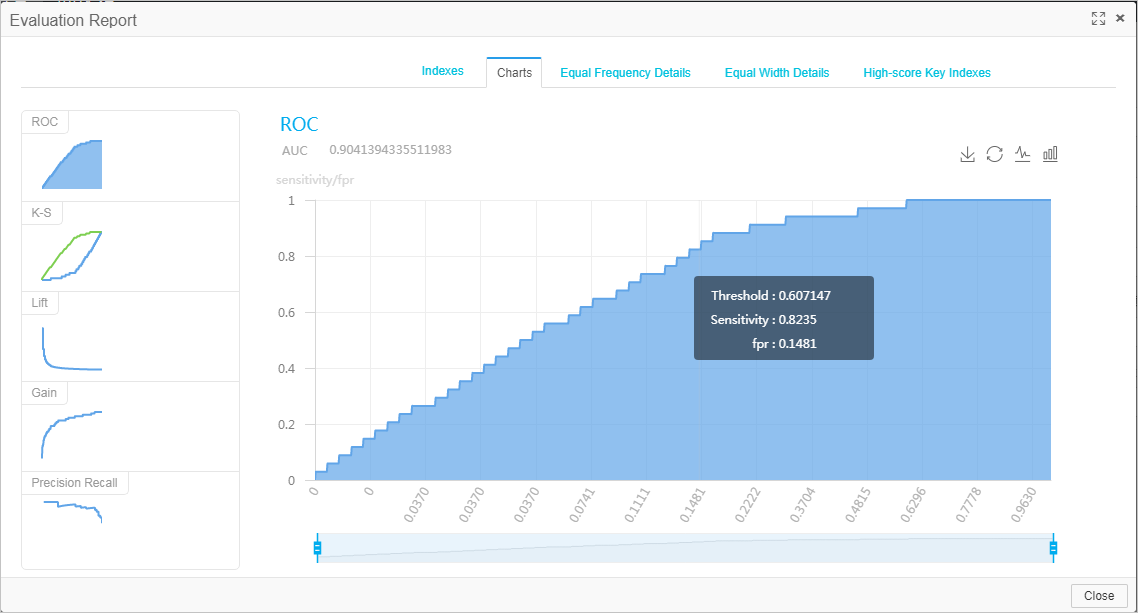
[二項分類評価-1] ノードを実行し、モデル評価結果を表示します。
[二項分類評価-1] ノードの実行後、コスト効率:ビジュアル分析 ノードを右クリックし、 を選択して、さまざまな評価メトリックを視覚的に表示します。
(オプション) ステップ 6: モデルをデプロイする
Machine Learning Designer は、Elastic Algorithm Service (EAS) とシームレスに統合できます。モデルをオフラインでトレーニングし、モデル予測を完了し、モデルを評価した後、モデルをオンライン モデル サービスとして EAS にデプロイできます。
パイプラインの実行後、キャンバスの左上隅にある [モデル] をクリックします。[モデル] ダイアログ ボックスで、目的のモデルを選択し、[EAS にデプロイ] をクリックします。

パラメーターの構成を確認します。詳細については、モデルをオンライン サービスとしてデプロイする をご参照ください。
サービスの作成ページで、[モデル ファイル] および [プロセッサ タイプ] パラメーターが自動的に構成されます。ビジネス要件に基づいて、その他のパラメーターを構成する必要があります。
[デプロイ] をクリックします。
[サービスステータス] パラメーターの値が [作成中] から [実行中] に変わると、モデルがデプロイされます。
重要デプロイ済みのモデルサービスを使用しなくなった場合は、モデルサービスの [アクション] 列の [停止] をクリックします。これにより、不要なコストを回避できます。
参考資料
Machine Learning Designer は、モデル構築に使用できるさまざまなテンプレートを提供しています。詳細については、「テンプレートを使用したパイプラインの作成のデモ」をご参照ください。
パイプラインは、DataWorks タスクを使用して Machine Learning Designer でスケジュールできます。詳細については、「DataWorks タスクを使用して Machine Learning Designer でパイプラインをスケジュールする」をご参照ください。
パイプラインでグローバル変数を設定できます。この機能は、オンライン パイプラインの管理と、DataWorks タスクを使用したパイプラインのスケジュールに役立ちます。これにより、パイプラインの柔軟性と効率が向上します。詳細については、「グローバル変数」をご参照ください。