ナイーブベイズは、ベイズの定理に基づく確率的分類アルゴリズムです。 このアルゴリズムは、入力データにおける全ての特徴が互いに独立していると仮定する。 Machine Learning DesignerのNaive Bayesコンポーネントを使用して、さまざまな分類問題を効果的に処理できます。 このトピックでは、Naive Bayesコンポーネントを設定する方法について説明します。
使用上の注意
Naive Bayesコンポーネントには、MaxComputeコンピューティングリソースが必要です。
コンポーネントの設定
次のいずれかの方法を使用して、Naive Bayesコンポーネントを設定できます。
方法1: Platform for AI (PAI) コンソールを使用する
PAIコンソールでNaive Bayesコンポーネントを設定するには、次の手順を実行します。PAIコンソールにログインし、[Visualized Modeling (Designer)] ページに移動して、パイプラインを開きます。 パイプラインページで、Naive Bayesコンポーネントをキャンバスにドラッグし、右側のペインでパラメーターを設定します。 下表に、各パラメーターを説明します。
タブ | パラメーター | 説明 |
フィールド設定 | フィーチャー列 | フィーチャー列。 デフォルト値: Label columnパラメーターで指定された列を除く、入力テーブルのすべての列。 DOUBLE、STRING、BIGINTタイプの列がサポートされています。 |
除外列 | トレーニングのために除外される列。 このパラメーターと [機能列] パラメーターを同時に設定することはできません。 | |
強制変換列 | 強制データ型変換が必要な列。 このパラメーターを空のままにすると、次の変換ルールが適用されます。
説明 BIGINT型の列をCATEGORICAL型の列に変換する場合は、このパラメーターを設定する必要があります。 | |
ラベル列 | ラベル列。 ラベル列をフィーチャ列として使用することはできません。 label列は、DOUBLE、STRING、またはBIGINTタイプである必要があります。 | |
入力スパース形式データ | 入力データがスパースかどうかを指定します。 スパースデータは、キーと値のペア形式です。 | |
K:V入力がスパースの場合のセパレータ | キーと値のペアを区切るために使用される区切り文字。 デフォルトでは、コンマ (,) が使用されます。 | |
入力がスパースの場合のキーと値のセパレータ | キーと値のペアでキーと値を区切るために使用される区切り文字。 デフォルトでは、コロン (:) が使用されます。 | |
PMMLを生成するかどうか | PMML (Predictive Model Markup Language) モデルを生成するかどうかを指定します。 パイプラインのストレージパスを設定しておらず、このパラメーターのチェックボックスを選択した場合は、[今すぐ作成] をクリックしてパイプラインのストレージパスを設定します。 | |
チューニング | コア数 | デフォルトでは、システムはこのパラメータを自動的に設定します。 |
コアのメモリサイズ (MB) | デフォルトでは、システムはこのパラメータを自動的に設定します。 |
方法2: PAIコマンドを使用する
PAIコマンドを使用してNaive Bayesコンポーネントを設定するには、SQLスクリプトコンポーネントでコマンドを実行します。 詳細については、「SQLスクリプト」をご参照ください。
PAI -name NaiveBayes -project algo_public
-DinputTablePartitions="pt=20150501"
-DmodelName="xlab_m_NaiveBayes_23772"
-DlabelColName="poutcome"
-DfeatureColNames="age,previous,cons_conf_idx,euribor3m"
-DinputTableName="bank_data_partition";パラメーター | 必須 | 説明 | デフォルト値 |
inputTableName | 可 | 入力テーブルの名前。 | デフォルト値なし |
inputTablePartitions | 不可 | トレーニング用に入力テーブルから選択されたパーティション。 | すべてのパーティション |
modelName | 可 | 出力モデルの名前。 | デフォルト値なし |
labelColName | 可 | ラベル列の名前。 | デフォルト値なし |
featureColNames | 不可 | トレーニング用に入力テーブルから選択されたフィーチャ列の名前。 | ラベル列を除くすべての列 |
excludedColNames | 不可 | トレーニングのために除外される列の名前。 このパラメーターとfeatureColNamesパラメーターを同時に設定することはできません。 | デフォルト値なし |
forceCategorical | 不可 | 強制データ型変換が必要な列。 このパラメーターを空のままにすると、次の変換ルールが適用されます。
説明 BIGINT型の列をCATEGORICAL型の列に変換する場合は、このパラメーターを設定する必要があります。 | INTは連続型です。 |
coreNum | 不可 | コンピューティングに使用されるCPUコアの数。 | システムによって自動的に設定される |
memSizePerCore | 不可 | 各CPUコアのメモリサイズ。 有効な値: 1 ~ 65536 単位:MB。 | システムによって自動的に設定される |
例:
トレーニングデータとテストデータを準備します。
MaxComputeクライアントを使用して、train_dataおよびtest_dataという名前のテーブルを作成します。 train_dataテーブルはトレーニングデータの保存に使用され、test_dataテーブルはテストデータの保存に使用されます。 テーブルで、列名とタイプを
id bigint, y bigint, f0 double, f1 double, f2 double, f3 double, f4 double, f5 double, f6 double, f7 doubleに設定します。 MaxComputeクライアントのインストール方法と設定方法については、「MaxComputeクライアント (odpscmd) 」をご参照ください。 テーブルの作成方法については、「テーブルの作成」をご参照ください。次のトレーニングデータをtrain_dataテーブルに、テストデータをtest_dataテーブルにインポートします。 データをインポートする方法については、「データをテーブルにインポートする」をご参照ください。
トレーニングデータ
id
y
f0
f1
f2
f3
f4
f5
f6
f7
1
-1
-0.294118
0.487437
0.180328
-0.292929
-1
0.00149028
-0.53117
-0.0333333
2
+ 1
-0.882353
-0.145729
0.0819672
-0.414141
-1
-0.207153
-0.766866
-0.666667
3
-1
-0.0588235
0.839196
0.0491803
-1
-1
-0.305514
-0.492741
-0.633333
4
+ 1
-0.882353
-0.105528
0.0819672
-0.535354
-0.777778
-0.162444
-0.923997
-1
5
-1
-1
0.376884
-0.344262
-0.292929
-0.602837
0.28465
0.887276
-0.6
6
+ 1
-0.411765
0.165829
0.213115
-1
-1
-0.23696
-0.894962
-0.7
7
-1
-0.647059
-0.21608
-0.180328
-0.353535
-0.791962
-0.0760059
-0.854825
-0.833333
8
+ 1
0.176471
0.155779
-1
-1
-1
0.052161
-0.952178
-0.733333
9
-1
-0.764706
0.979899
0.147541
-0.0909091
0.283688
-0.0909091
-0.931682
0.0666667
10
-1
-0.0588235
0.256281
0.57377
-1
-1
-1
-0.868488
0.1
テストデータ
id
y
f0
f1
f2
f3
f4
f5
f6
f7
1
+ 1
-0.882353
0.0854271
0.442623
-0.616162
-1
-0.19225
-0.725021
-0.9
2
+ 1
-0.294118
-0.0351759
-1
-1
-1
-0.293592
-0.904355
-0.766667
3
+ 1
-0.882353
0.246231
0.213115
-0.272727
-1
-0.171386
-0.981213
-0.7
4
-1
-0.176471
0.507538
0.278689
-0.414141
-0.702128
0.0491804
-0.475662
0.1
5
-1
-0.529412
0.839196
-1
-1
-1
-0.153502
-0.885568
-0.5
6
+ 1
-0.882353
0.246231
-0.0163934
-0.353535
-1
0.0670641
-0.627669
-1
7
-1
-0.882353
0.819095
0.278689
-0.151515
-0.307329
0.19225
0.00768574
-0.966667
8
+ 1
-0.882353
-0.0753769
0.0163934
-0.494949
-0.903073
-0.418778
-0.654996
-0.866667
9
+ 1
-1
0.527638
0.344262
-0.212121
-0.356974
0.23696
-0.836038
-0.8
10
+ 1
-0.882353
0.115578
0.0163934
-0.737374
-0.56974
-0.28465
-0.948762
-0.933333
次の図に示すようにパイプラインを作成し、パイプラインを実行します。 パイプラインの作成方法については、「アルゴリズムモデリング」をご参照ください。
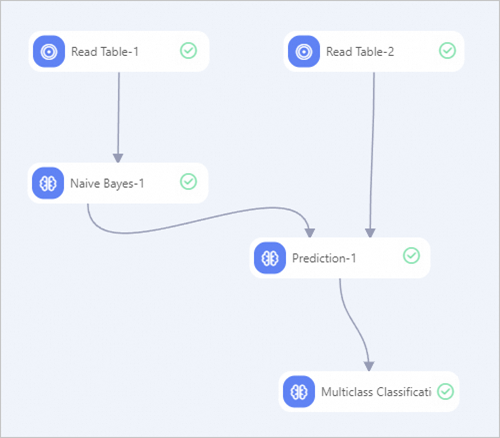
パイプラインページの左側のウィンドウで、2つのRead Tableコンポーネント、1つのNaive Bayesコンポーネント、1つのPredictionコンポーネント、および1つのMulticlass Classification Evaluationコンポーネントを検索してキャンバスにドラッグします。
前の図に基づいて、コンポーネントをパイプラインに接続します。
コンポーネントパラメーターを設定します。
キャンバス上の [Read Table-1] コンポーネントをクリックします。 右側のウィンドウの [テーブルの選択] タブで、[テーブル名] パラメーターをtrain_dataに設定します。
キャンバス上の [Read Table-2] コンポーネントをクリックします。 右側のウィンドウの [テーブルの選択] タブで、[テーブル名] パラメーターをtest_dataに設定します。
キャンバス上のナイーブBayes-1コンポーネントをクリックし、右側のウィンドウでパラメーターを設定します。 次の表に、設定する必要があるパラメーターを示します。 他のパラメーターのデフォルト値を保持します。
タブ
パラメーター
説明
フィールド設定
フィーチャー列
トレーニングテーブルからf0、f1、f2、f3、f4、f5、f6、f7列を選択します。
ラベル列
トレーニングテーブルからy列を選択します。
キャンバスで [予測-1] コンポーネントをクリックします。 右側のウィンドウの [フィールドの設定] タブで、[予約列] パラメーターをidおよびyに設定します。 他のパラメーターのデフォルト値を保持します。
キャンバス上の [マルチクラス分類評価-1] コンポーネントをクリックします。 右側のペインの [フィールド設定] タブで、[元の分類結果列] パラメーターをyに設定します。 他のパラメーターのデフォルト値を保持します。
ボタンをクリックして
 パイプラインを実行します。
パイプラインを実行します。
パイプラインの実行が完了したら、[予測-1] コンポーネントを右クリックし、 を選択して予測結果を表示します。
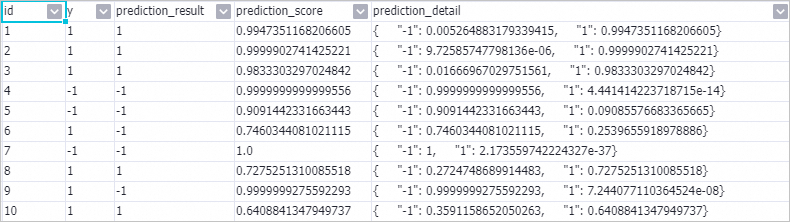
関連ドキュメント
Naive Bayesコンポーネントを実行してPMMLモデルを生成した後、モデルをオンラインサービスとしてデプロイできます。 詳細については、「オンラインサービスとしてのモデルのデプロイ」をご参照ください。
Machine Learning Designerの詳細については、「Machine Learning Designerの概要」をご参照ください。
Machine Learning Designerは、複数のプリセットアルゴリズムコンポーネントを提供します。 ビジネス要件に基づいてコンポーネントを選択できます。 詳細については、「コンポーネントリファレンス: すべてのコンポーネントの概要」をご参照ください。