線形モデル特徴重要性コンポーネントは、線形回帰やバイナリ分類のロジスティック回帰など、線形モデルの特徴重要性を計算するために使用されます。 疎データ形式と密データ形式の両方がサポートされています。 このトピックでは、線形モデルフィーチャの重要性コンポーネントを設定する方法について説明します。
制限事項
MaxComputeのコンピューティングリソースのみに基づいて、線形モデル機能の重要性コンポーネントを使用できます。
コンポーネントの設定
次のいずれかの方法を使用してコンポーネントを設定できます。
方法1: Platform for AI (PAI) コンソールでコンポーネントを構成する
Machine Learning Designerでコンポーネントパラメーターを設定します。 下表に、各パラメーターを説明します。
タブ | パラメーター | 説明 |
フィールド設定 | フィーチャー列 | 入力テーブルからトレーニング用のフィーチャ列を選択します。 オプションです。 デフォルトでは、ラベル列以外のすべての列が選択されます。 |
ターゲット列 | 必須。 ラベル列。 [フィールドの選択] をクリックします。 [フィールドの選択] ダイアログボックスで、検索する列のキーワードを入力します。 列を選択して [OK] をクリックします。 | |
入力スパース形式データ | オプションです。 入力テーブルのデータがスパースかどうかを指定します。 | |
チューニング | コア | オプションです。 コンピューティングで使用されるコアの数。 |
コアあたりのメモリサイズ | オプションです。 各コアのメモリサイズ。 単位:MB。 |
方法2: PAIコマンドを使用する
PAIコマンドを使用してコンポーネントパラメータを設定します。 次のセクションでは、パラメーターについて説明します。 SQLスクリプトコンポーネントを使用してPAIコマンドを呼び出すことができます。 詳細については、「SQLスクリプト」をご参照ください。
PAI -name regression_feature_importance -project algo_public
-DmodelName=xlab_m_logisticregressi_20317_v0
-DoutputTableName=pai_temp_2252_20321_1
-DlabelColName=y
-DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign
-DenableSparse=false -DinputTableName=pai_dense_10_9;パラメーター | 必須 | 説明 | デフォルト値 |
inputTableName | 可 | 入力テーブルの名前。 | なし |
outputTableName | 可 | 出力テーブルの名前。 | なし |
labelColName | 可 | 入力テーブルから選択されたラベル列。 | なし |
modelName | 可 | 入力モデルの名前。 | なし |
featureColNames | 不可 | 入力テーブルから選択されたフィーチャ列。 | ラベル列以外のすべての列 |
inputTablePartitions | 不可 | 入力テーブルから選択されたパーティション。 | フルテーブル |
enableSparse | 不可 | 入力テーブルのデータがスパースかどうかを指定します。 | false |
itemDelimiter | 不可 | 入力テーブルのデータがスパースの場合にキーと値のペアを分離するために使用される区切り文字。 | バックスペース |
kvDelimiter | 不可 | 入力テーブルのデータがスパースの場合にキーと値を区切るために使用される区切り文字。 | コロン (:) |
ライフサイクル | 不可 | 出力テーブルのライフサイクル。 | 指定なし |
coreNum | 不可 | コアの数。 | システムによって決定される |
memSizePerCore | 不可 | 各コアのメモリサイズ。 | システムによって決定される |
例:
bank_dataという名前のテーブルを作成し、テーブルにデータをインポートします。 詳細については、「テーブルの作成」および「テーブルへのデータのインポート」をご参照ください。
次のSQL文を実行してトレーニングデータを生成します。
存在しない場合にテーブルを作成する
create table if not exists pai_dense_10_9 as select age,campaign,pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, fixed_deposit from bank_data limit 10;次の図に示すパイプラインを作成し、コンポーネントを実行します。 詳細については、「アルゴリズムモデリング」をご参照ください。
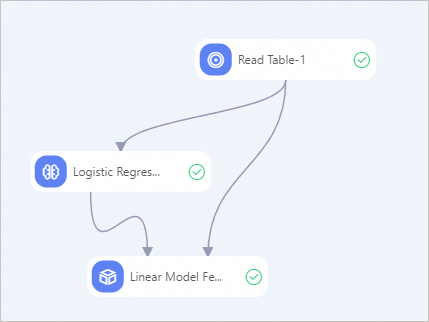
Machine Learning Designerの左側のコンポーネントリストで、Read Table、Logistic Regression for Multiclass Classification、およびLinear Model Feature Importanceコンポーネントを個別に検索し、コンポーネントを右側のキャンバスにドラッグします。
ラインを描画してノードを接続し、前の図に基づいてアップストリームとダウンストリームの関係を含むパイプラインにノードを編成します。
コンポーネントパラメーターを設定します。
キャンバスで、[Read Table-1] コンポーネントをクリックします。 右側のウィンドウの [テーブルの選択] タブで、[テーブル名] をbank_dataに設定します。
キャンバスで、[マルチクラス分類のロジスティック回帰-1] コンポーネントをクリックします。 [フィールド設定] タブで、[トレーニング機能列] パラメーターに、年齢、キャンペーン、pdays、previous、emp_var_rate、cons_price_idx、cons_conf_idx、euribor3m、およびnr_installedを選択します。 ターゲット列パラメーターをfixed_depositに設定します。 残りのパラメーターのデフォルト値を保持します。
キャンバスで、Linear Model Feature Importance-1コンポーネントをクリックします。 [フィールドの設定] タブで、[対象列] パラメーターをfixed_depositに設定します。 残りのパラメーターのデフォルト値を保持します。
パラメーターの設定が完了したら、ボタンをクリックし
 てパイプラインを実行します。
てパイプラインを実行します。
パイプラインの実行後、[Linear Model Feature Importance-1] コンポーネントを右クリックし、 を選択します。
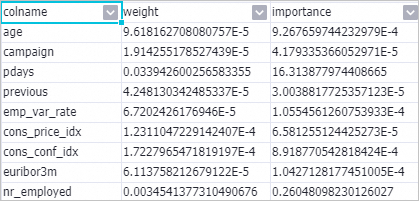
次の表に、メトリックの計算式を示します。
列名
計算式
重み
abs(w_)
重要度
abs(w_j) * STD(f_i)
説明abs(w_j) は、特徴係数の絶対値を示す。 STD(f_i) は、トレーニングデータの標準偏差を示す。
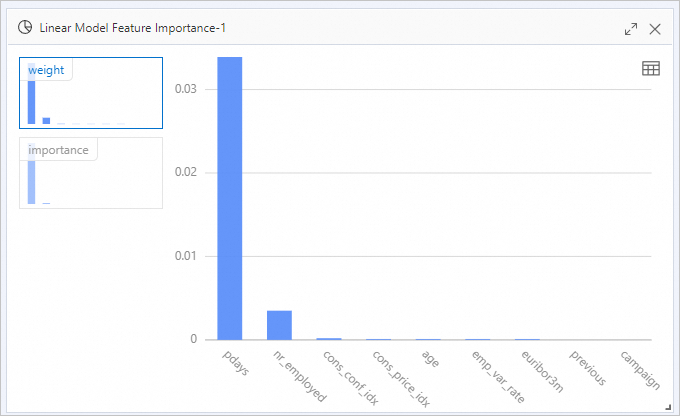
[Linear Model Feature Importance-1] コンポーネントを右クリックし、[分析レポートの表示] を選択して、視覚化されたデータ分析用のレポートを表示します。
関連ドキュメント
Machine Learning Designerが提供するコンポーネントの詳細については、「Machine Learning Designerの概要」をご参照ください。
Machine Learning Designerは、さまざまなプリセットアルゴリズムコンポーネントを提供します。 コンポーネントを使用して、ビジネス要件に基づいてデータを処理できます。 詳細については、「コンポーネントリファレンス: すべてのコンポーネントの概要」をご参照ください。