推奨シナリオでは、Machine Learning Designerが提供するFM-Embeddingソリューションを使用して、各ユーザーとアイテムの特徴ベクトルを取得できます。 次に、リコールモジュールを使用して、特徴ベクトルの積を取得できます。 このようにして、各ユーザーが各アイテムに割り当てる評価を予測できます。 このトピックでは、因数分解マシン (FM) および埋め込みアルゴリズムを使用して、ユーザーとアイテムの特徴ベクトルを生成する方法について説明します。
前提条件
ワークスペースが作成済み。 詳細については、「ワークスペースの作成」をご参照ください。
MaxComputeリソースはワークスペースに関連付けられています。 詳細については、「ワークスペースのコンピューティングリソースの管理」をご参照ください。
背景情報
AIベースの推奨事項は、ソートとリコールの2つのモジュールに分かれています。 リコールモジュールは、特徴ベクトルを使用して、ユーザおよび推奨されるアイテムを表す。 ユーザの特徴ベクトルとアイテムの特徴ベクトルとの積は、アイテムに対するユーザの興味を示す。 このトピックで説明するパイプラインでは、実際の推奨データを使用します。 このパイプラインは、Machine Learning DesignerのプリセットFM-Embedding for Rec-Systemテンプレートから作成できます。 Machine Learning Designerが提供するコンポーネントをドラッグアンドドロップすることで、ユーザーとアイテムの特徴ベクトルをすばやく生成できます。
データセット
次の表に、データセットのフィールドを示します。
パラメーター | データ型 | 説明 |
userid | STRING | ユーザーの ID。 |
age | DOUBLE | ユーザーの年齢。 |
gender | STRING | ユーザーの性別。 |
itemid | STRING | アイテムのID。 |
price | DOUBLE | アイテムの価格。 |
size | DOUBLE | アイテムのサイズ。 |
label | DOUBLE | ユーザーがアイテムを購入したかどうかを示します。 有効な値:
|
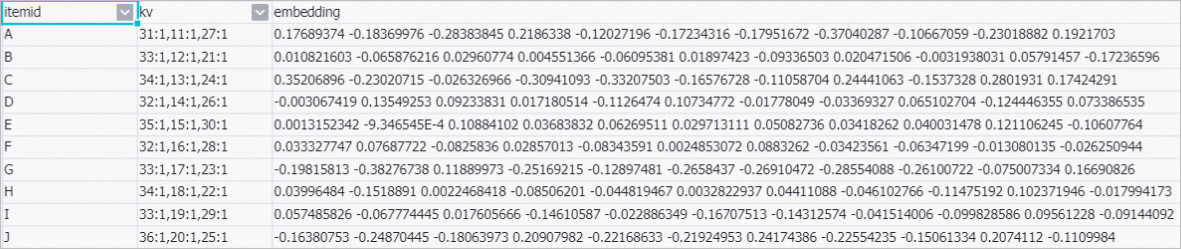
次の図は、パイプラインで使用されるサンプルデータを示しています。 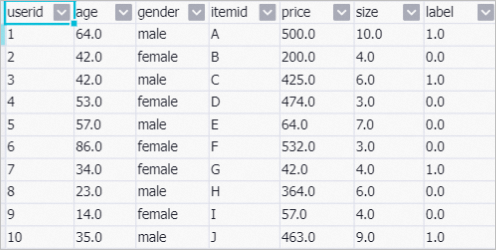
手順
Machine Learning Designerページに移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ワークスペースページの左側のナビゲーションウィンドウで、機械学習デザイナーページに移動します。
パイプラインを作成します。
Visualized Modeling (Designer) ページで、プリセットテンプレートタブをクリックします。
[プリセットテンプレート] タブで、[FM-Embedding for Rec-System] テンプレートを見つけ、[作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、パラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインのランタイム中に生成された一時データおよびモデルのObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
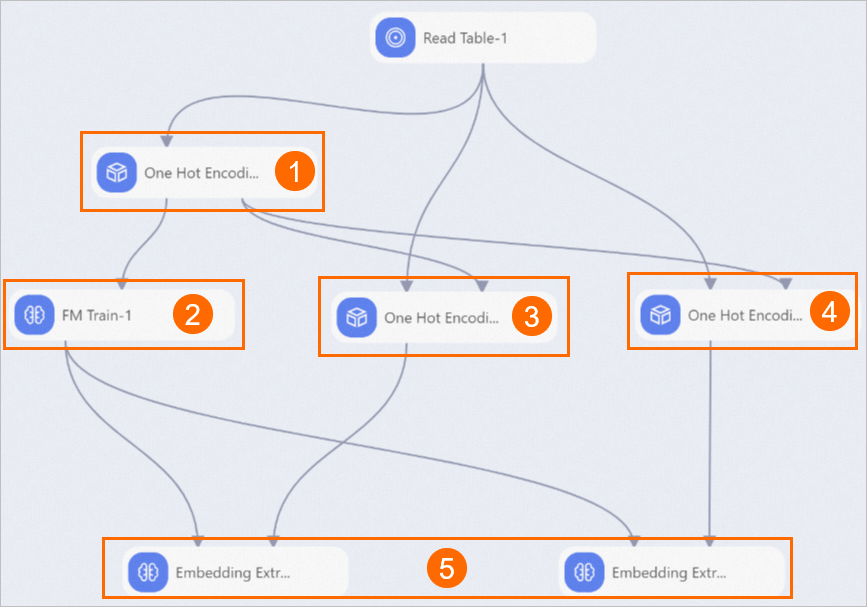
次の図に示すように、キャンバス上のパイプラインのコンポーネントを表示します。 システムは、組み込みテンプレートに基づいてパイプラインを自動的に作成します。
セクション
説明
①
このコンポーネントは、すべての特徴データに対してワンホットエンコーディングを実行します。 ワンホットエンコーディングは、文字型データを数値型データに変換します。 このパイプラインでは、One Hot Encoding-1コンポーネントは、まず、すべての特徴データに対してワンホット符号化を実行し、符号化モデルを生成します。 次いで、One Hot Encoding-1コンポーネントは、符号化モデルをOne Hot encoding-2およびOne Hot Encoding-3コンポーネントにエクスポートする。
②
このコンポーネントは、FMモデルを生成する。 コンポーネントをクリックし、右側のパネルの [パラメータ設定] タブでコンポーネントのデフォルトのパラメータ設定を表示できます。 Dimensionsのデフォルト値は1,1,10です。10は各特徴ベクトルの次元数を示します。
③
このコンポーネントは、ユーザ特徴コードを生成する。 このコンポーネントでは、[バイナリ化列] をuserid、gender、ageに設定し、[追加列] をuseridに設定します。
④
このコンポーネントは、アイテム特徴コードを生成する。 このコンポーネントのBinarization Columnをitemid、price、sizeに設定し、追加されたColumnsをitemidに設定します。
⑤
これらのコンポーネントは、ユーザおよびアイテムの特徴ベクトルを抽出する。 各コンポーネントには、次のパラメータが含まれます。
埋め込みベクトルのID列名: FM Train-1コンポーネントによってトレーニングされるモデルのfeature_idパラメーター。
Embedding vector column name: FM Train-1コンポーネントによってトレーニングされたモデルのfeature_weightsパラメーター。
重みベクトル列名: One Hot Encoding-1コンポーネントによってエクスポートされるスパース列。
出力結果列名: 生成された特徴ベクトルを含む列の名前。
パイプラインを実行し、結果を表示します。
キャンバスの左上隅にある
 アイコンをクリックします。
アイコンをクリックします。 パイプラインの実行後、キャンバス上で [抽出物の埋め込み]-1を右クリックし、 を選択します。 表示されるダイアログボックスで、ユーザーの特徴ベクトルを表示します。
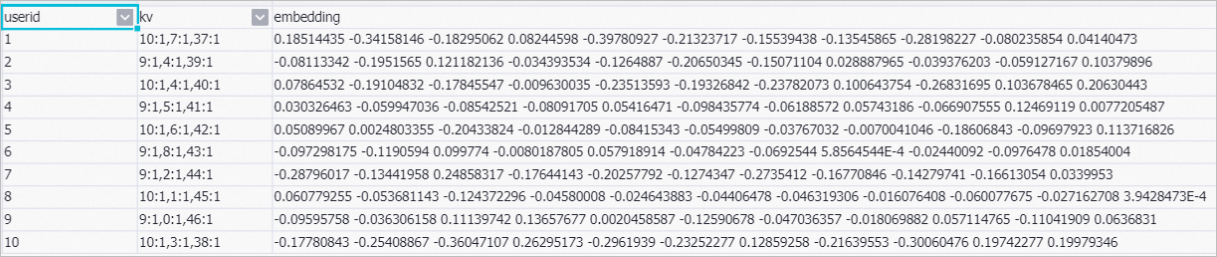
キャンバス上で [Embedding extract-2] を右クリックし、 を選択します。 表示されるダイアログボックスで、アイテムの特徴ベクトルを表示します。