収入、土地面積、作物の種類に関する既存データを使用して、融資返済能力を予測するための線形回帰モデルを構築します。
既存の融資データ (年間収入、作物の種類、土地面積) を使用して線形回帰モデルを構築し、申請者が申請された融資額を返済できるかどうかを予測します。
データセットは学習目的のための架空のものです。
前提条件
ワークスペースが作成されました。詳細については、「ワークスペースの作成と管理」をご参照ください。
MaxCompute リソースがワークスペースに関連付けられている必要があります。詳細については、「ワークスペースの作成と管理」をご参照ください。
データセットフィールド
フィールド | タイプ | 説明 |
id | STRING | 各エントリの一意の識別子。 |
name | STRING | 申請者名。 |
region | STRING | 北から南に順序付けられた地理的リージョン。 |
farmsize | DOUBLE | 農地面積 (エーカー)。 |
rainfall | DOUBLE | 年間降水量 (ミリメートル)。 |
landquality | DOUBLE | 土壌品質スコア。値が高いほど品質が良いことを示します。 |
farmincome | DOUBLE | 年間農業収入。 |
maincrop | STRING | 栽培される主要な作物の種類。 |
claimtype | STRING | 申請された融資の種類。 |
claimvalue | DOUBLE | 申請された融資額。 |
ワークフローの構築と実行
-
Machine Learning Designer ページに移動します。
-
PAI コンソールにログインします。
-
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。ワークスペースページで、管理するワークスペースの名前をクリックします。
-
左側のナビゲーションウィンドウで、 を選択します。
-
ワークフローを構築します。
Designer ページで、[プリセットテンプレート] をクリックします。
[農業ローン予測の回帰アルゴリズム実装] で、[作成] をクリックします。
[ワークフローの作成] で、パラメーターを設定するか、デフォルトのままにします。
[ワークフローデータストレージ] は、一時データとモデル用の OSS バケットパスを指定します。
-
「[OK]」をクリックします。
ワークフローは約 10 秒で作成されます。
ワークフロー一覧で、Regression Algorithm for Agricultural Loan Prediction を選択し、[ワークフローに移動] をクリックします。
Designer はワークフローを自動的に構築します。
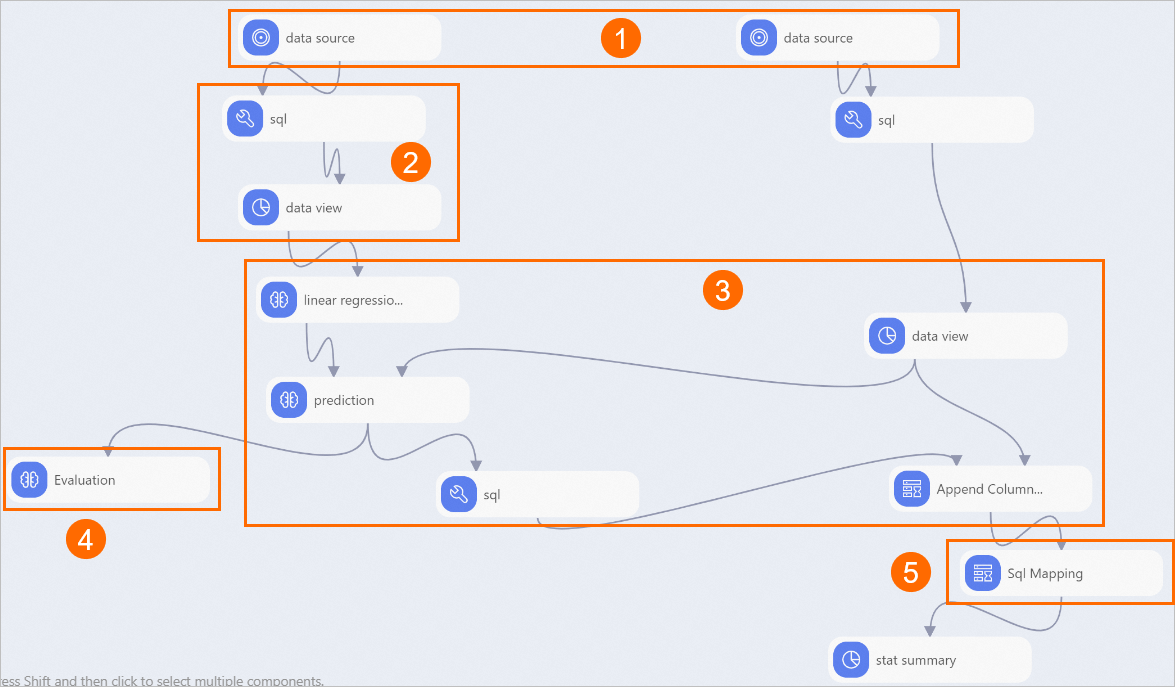
エリア
説明
①
ワークフローデータセットを読み取ります。
トレーニング: モデルをトレーニングするための、農場の規模や降水量などの特徴を持つ過去のローンレコード 100 件。請求額には、回収されたローン額が含まれます。
テスト: 71 人の現在のローン申請者。claimvalue には申請された融資額が含まれています。
既存データを使用して、どの申請者が融資承認を受けるかを予測します。
②
文字列の値を数値にマップします。リージョン の場合、北、中央、および 南 をそれぞれ 0、1、および 2 にマップし、その後 DOUBLE に変換します。
③
[線形回帰] は既存データを使用してモデルをトレーニングして生成します。[予測] はこのモデルを使用して融資の実行を予測します。[列の結合] はユーザー ID、予測値、および申請融資額を結合します。
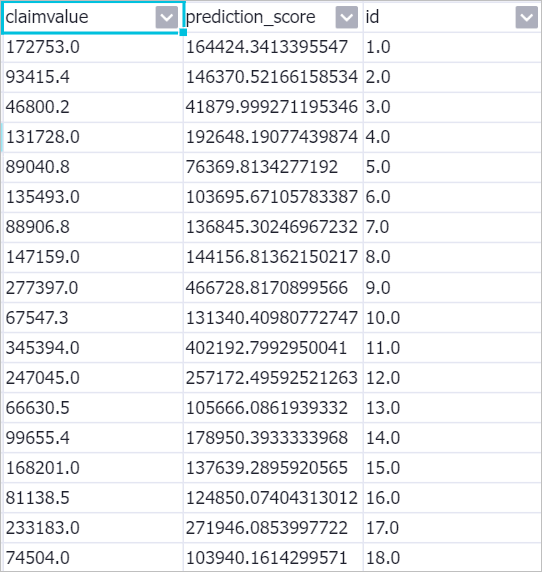 prediction_score には予測返済額が含まれます。
prediction_score には予測返済額が含まれます。④
回帰モデル評価は、モデルの性能を評価します。詳細については、「評価メトリック」をご参照ください。
⑤
[フィルタリングとマッピング] は、予測返済額がリクエストされた融資額を上回る適格な申請者を特定します。
表 1. 評価メトリック
フィールド
説明
MAE
平均絶対誤差。
MAPE
平均絶対パーセンテージ誤差。
MSE
平均二乗誤差。
R
重相関係数。
R2
決定係数。
RMSE
二乗平均平方根誤差。
SAE
絶対誤差の合計。
SSE
誤差平方和。
SSR
回帰による平方和。
SST
総平方和。
count
行数。
predictionMean
予測の平均。
yMean
元の従属変数の平均。
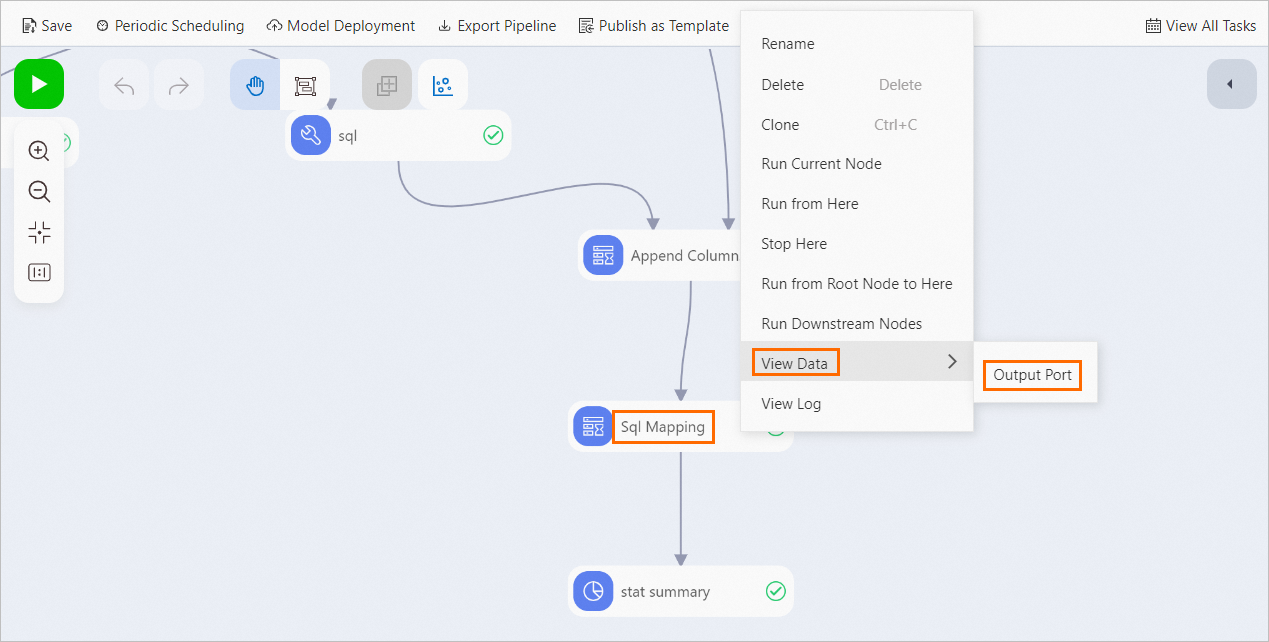
ワークフローを実行し、結果を表示します。
キャンバスの上にある
 をクリックします。
をクリックします。完了後、[フィルタリングとマッピング] を右クリックし、「」を選択して、対象となる応募者を表示できます。
関連情報
アルゴリズムコンポーネントの詳細については、以下をご参照ください。