機械学習デザイナーでは、事前設定されたロジスティック回帰テンプレートを使用して、家族の背景や学習行動などのさまざまな要因を考慮して学生の試験結果を予測し、学生の学習成果に影響を与える主な要因を特定するモデルを構築できます。 このトピックでは、プリセットロジスティック回帰テンプレートの使用方法について説明します。
背景情報
このトピックで説明している予測モデルを取得したら、データをMaxComputeテーブルにインポートしてオフライン予測を実行できます。
前提条件
ワークスペースが作成済み。 詳細については、「ワークスペースの作成」をご参照ください。
MaxComputeリソースはワークスペースに関連付けられています。 詳細については、「ワークスペースの管理」をご参照ください。
データセット
この例では、データセットに25のフィーチャ列と1つのターゲット列が含まれています。 次の表では、列について説明します。
列 | データ型 | 説明 |
性別 | STRING | 学生の性別。 有効な値: FおよびM Fは学生が女性であることを示し、Mは学生が男性であることを示す。 |
address | STRING | 学生の居住エリア。 有効な値: UおよびR。Uは、学生が都市部に住んでいることを示します。 Rは、学生が地方に住んでいることを示します。 |
famsize | STRING | 家族の数。 有効な値: LE3およびGT3 LE3は、ファミリーメンバーの数が3以下であることを示す。 GT3は、ファミリーメンバーの数が3を超えることを示す。 |
pstatus | STRING | 生徒が親と同居しているかどうかを指定します。 有効な値: TおよびA。Tは、生徒が両親と暮らしていることを示します。 Aは、生徒が親と同居していないことを示します。 |
medu | DOUBLE | 学生の母親の教育レベル。 有効な値: 0〜4。 値が大きいほど、教育レベルが高いことを示します。 |
fedu | DOUBLE | 学生の父親の教育レベル。 有効な値: 0〜4。 値が大きいほど、教育レベルが高いことを示します。 |
mjob | STRING | 学生の母親の雇用部門。 例えば、母親は、教育、健康、またはサービス産業で働くことができる。 |
fjob | STRING | 学生の父親の雇用部門。 例えば、父親は、教育、健康、またはサービス業界で働くことができる。 |
ガーディアン | STRING | 学生の保護者。 有効な値: mother、father、other |
traveltime | DOUBLE | 自宅から学校への移動時間。 単位は分です。 |
studytime | DOUBLE | 週あたりの学習時間。 単位:時間。 |
failures | DOUBLE | 失敗した検査の数。 |
schoolsup | STRING | 学生が追加の教育トレーニングを受けるかどうかを指定します。 有効な値: yesおよびno。 |
fumsup | STRING | 学生にチューターがあるかどうかを指定します。 有効な値: yesおよびno。 |
有料 | STRING | 生徒が試験のために放課後の個別指導を受けるかどうかを指定します。 有効な値: yesおよびno。 |
アクティビティ | STRING | 学生が課外クラスに登録されているかどうかを指定します。 有効な値: yesおよびno。 |
高い | STRING | 学生が高等教育を追求するかどうかを指定します。 有効な値: yesおよびno。 |
internet | STRING | 学生が自宅でインターネットにアクセスできるかどうかを指定します。 有効な値: yesおよびno。 |
famrel | DOUBLE | 学生の家族関係の質。 有効な値: 1 ~ 5。 値が大きいほど、家族関係が良好であることを示す。 |
freetime | DOUBLE | 放課後の学生の自由時間。 有効な値: 1 ~ 5。 値が大きいほど、放課後の空き時間が多いことを示します。 |
グアウト | DOUBLE | 友人との社会活動の頻度。 有効な値: 1 ~ 5。 値が大きいほど、友人とのより頻繁な社会的交流を示す。 |
dalc | DOUBLE | 学生の毎日のアルコール消費量。 有効な値: 1 ~ 5。 より大きな値は、より高い消費を示す。 |
walc | DOUBLE | 学生の毎週のアルコール消費量。 有効な値: 1 ~ 5。 より大きな値は、より高い消費を示す。 |
health | DOUBLE | 学生の健康状態。 有効な値: 1 ~ 5。 値が大きいほど、健康状態が良好であることを示す。 |
欠席 | DOUBLE | 学生の出席。 有効な値: 0 ~ 93。 |
g3 | STRING | 審査結果。 結果は20ポイントまでのスケールで評価されます。 |
次の図は、この例で使用されるデータセットを示しています。 
手順
Machine Learning Designerページに移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ワークスペースページの左側のナビゲーションウィンドウで、機械学習デザイナーページに移動します。
パイプラインを作成します。
Visualized Modeling (Designer) ページで、プリセットテンプレートタブをクリックします。
を検索するFind theオンライン予測-学生試験パフォーマンス予測テンプレートをクリックし、作成.
[パイプラインの作成] ダイアログボックスで、パラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインのランタイム中に生成された一時データおよびモデルのObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
[パイプライン] タブで、ダブルクリックします。オンライン予測-学生試験パフォーマンス予測パイプラインを開きます。
キャンバス上のパイプラインのコンポーネントを表示します。 次の図は、プリセットテンプレートを使用して自動的に作成されるパイプラインを示しています。
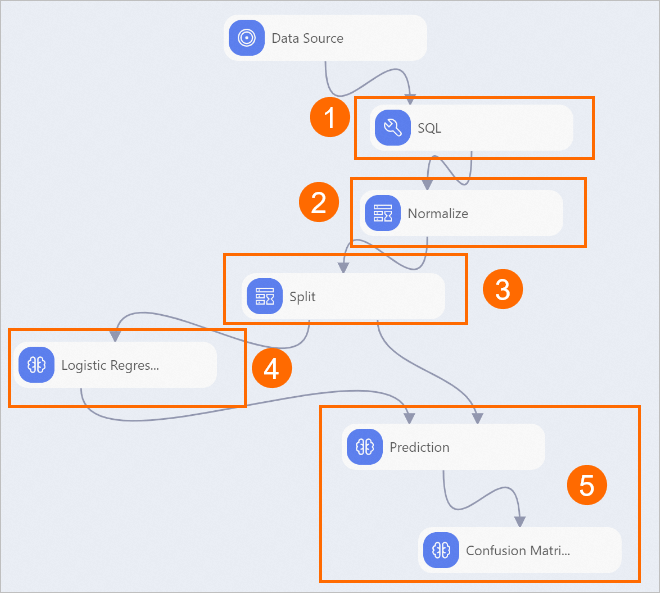
コンポーネント
説明
1
SQLコンポーネントは、次のルールに基づいて、入力データセットのテキストデータを構造化します。
はいを0に、いいえを1に変換します。
ビジネスシナリオに基づいてカテゴリテキストデータを要約します。 たとえば、コンポーネントはmjobフィールドの値教師を1に、その他の値を0に変換します。 抽象化の後、mjobフィールドは、母親が教育業界で働いているかどうかを示します。
ターゲット列g3の18より大きい値を1に変換し、その他の値を0に変換します。
2
正規化コンポーネントは、すべてのフィールドの値を0〜1の範囲にスケールダウンして、フィールド値間の不均衡を相殺します。
3
Splitコンポーネントは、8:2の比率に従って、入力データセットをトレーニングデータセットと予測データセットに分割します。
4
ロジスティック回帰コンポーネントは、ロジスティック回帰アルゴリズムを使用してオフライン予測モデルを生成します。
5
Confusion Matrixコンポーネントは、モデルの精度を評価します。
パイプラインを実行し、予測結果を表示します。
キャンバスの左上隅にある [実行] アイコンをクリックします。
 パイプラインを実行します。
パイプラインを実行します。 パイプラインが完了したら、混乱マトリックスキャンバス上のコンポーネントを選択し、ビジュアル分析ショートカットメニューで。
[混乱マトリックス] ダイアログボックスで、[統計] タブをクリックします。 タブの結果は、モデルの予測精度が80% よりも大きいことを示しています。
関連ドキュメント
アルゴリズムコンポーネントの詳細については、以下のトピックを参照してください。