Platform for AI (PAI) を使用すると、Elasticsearch を Retrieval-Augmented Generation (RAG) ベースのラージランゲージモデル (LLM) チャットボットと統合できます。これにより、モデルが生成する回答の正確性と多様性が向上します。Elasticsearch は効率的なデータ取得機能を備えており、辞書設定やインデックス管理などの特化機能も提供します。そのため、RAG ベースの LLM チャットボットはユーザーの要件をより正確に把握し、より適切で価値のあるフィードバックを提供できるようになります。本トピックでは、RAG ベースの LLM チャットボットをデプロイする際に Elasticsearch を関連付ける方法、および RAG ベースの LLM チャットボットが提供する基本機能と Elasticsearch が提供する特化機能について説明します。
背景情報
EAS の概要
Elastic Algorithm Service (EAS) は、Platform for AI (PAI) 内のオンラインモデルサービングプラットフォームです。モデルをオンライン推論サービスおよび AI Web アプリケーションとしてデプロイすることをサポートしています。EAS は Auto Scaling やブルー・グリーンデプロイメントなどの機能を提供し、コスト効率が高く、高並列かつ安定したオンラインサービスを実現します。また、リソースグループ管理、バージョン管理、包括的な運用監視システムも提供しています。詳細については、「EAS の概要」をご参照ください。
RAG の概要
生成 AI はテキストおよび画像生成において著しい進展を遂げています。しかし、広く使用されているラージランゲージモデル (LLM) にはいくつかの固有の制限があります。
ドメイン知識の限定性:LLM は幅広い一般的なデータセットで学習しているため、専門的かつ深層的なタスクへの対応が困難です。
情報の遅延:一度学習されたモデルは静的であり、リアルタイムで新しい情報を学習できません。
誤った出力:データの偏りやモデル自体の欠陥により、一見妥当に見えるが実際には誤った出力を生成することがあります。この現象は「モデルの幻覚(hallucination)」と呼ばれます。
Retrieval-Augmented Generation (RAG) は、これらの課題を克服し、大規模モデルの機能性と正確性を強化するために開発されました。外部知識を統合することで、RAG はモデルによる虚偽情報の生成を抑制し、最新情報へのアクセスを改善し、よりパーソナライズされ正確な LLM 応答を可能にします。
Elasticsearch の概要
Alibaba Cloud Elasticsearch は、オープンソースの Elasticsearch を基盤としたフルマネージドクラウドサービスです。オープンソースの機能と 100 % 互換があり、従量課金方式で即時利用可能です。Elasticsearch、Logstash、Kibana、Beats といったすぐに使える Elastic Stack コンポーネントを提供しており、Elastic 社との協業により X-Pack(Platinum Edition の高度機能)商用プラグインを無償で利用できます。これらのプラグインには、セキュリティ、SQL、機械学習、アラート、モニタリングなどの高度機能が統合されています。リアルタイムログ分析、情報検索、多次元データクエリおよび統計分析などに広く利用されています。Alibaba Cloud Elasticsearch の詳細については、「Alibaba Cloud Elasticsearch とは」をご参照ください。
ワークフロー
EAS は柔軟なパラメーター設定を備えた体系的な RAG ソリューションを提供します。WebUI または API 呼び出しを通じて RAG サービスを利用し、チャットボットをカスタマイズできます。RAG のコアアーキテクチャは、取得(retrieval)と生成(generation)で構成されています。
取得:EAS は、オープンソースの Faiss、Elasticsearch、Hologres、OpenSearch、RDS for PostgreSQL など、複数のベクトルデータベースをサポートしています。
生成:EAS は、Qwen、Llama、Mistral、Baichuan などの豊富なオープンソースモデルをサポートしており、ChatGPT の呼び出しにも対応しています。
本トピックでは、Elasticsearch を例として、EAS と Elasticsearch を使用して RAG ベースのチャットボットを構築する手順を示します。プロセスは以下のとおりです。
まず、Elasticsearch インスタンスを作成し、デプロイ時に RAG サービスに接続するために必要な設定を準備します。
EAS プラットフォーム上で RAG サービスをデプロイし、Elasticsearch インスタンスに接続します。
RAG チャットボットから Elasticsearch に接続し、企業のナレッジベースファイルをアップロードして質問に回答できます。
前提条件
Virtual Private Cloud (VPC)、vSwitch、セキュリティグループを作成します。詳細については、「IPv4 CIDR ブロックを使用した VPC の作成」および「セキュリティグループの作成」をご参照ください。
注意事項
本ソリューションは、サーバーリソースのサイズおよび LLM サービスのデフォルトトークン制限によって制約されており、サポートされる会話の長さが限定されます。本ガイドは、RAG チャットボットの基本的な取得機能をテストすることを目的としています。
ベクトルデータベースの準備:Elasticsearch
ステップ 1:Alibaba Cloud Elasticsearch クラスターの作成
Alibaba Cloud Elasticsearch コンソールにログインし、[Elasticsearch クラスター] ページで Alibaba Cloud Elasticsearch インスタンスを作成します。主なパラメーターは以下のとおりです。その他の設定の詳細については、「Alibaba Cloud Elasticsearch クラスターの作成」をご参照ください。
パラメーター | 説明 |
リージョンとゾーン | EAS サービスと同じリージョンを選択します。 |
インスタンスタイプ | クラスターのタイプです。Standard Edition を選択します。 |
パスワード | ログインパスワードを設定し、ローカルに保存します。 |
ステップ 2:設定項目の準備
Elasticsearch クラスターの URL を準備します。
Elasticsearch クラスターページの上部ナビゲーションバーで、インスタンスを作成したリージョンを上部メニューバーから選択します。クラスターリストで、作成した Elasticsearch インスタンスの ID をクリックします。
基本情報セクションで、内部エンドポイントと対応するポート番号を取得し、これらを組み合わせて Elasticsearch URL を作成します。
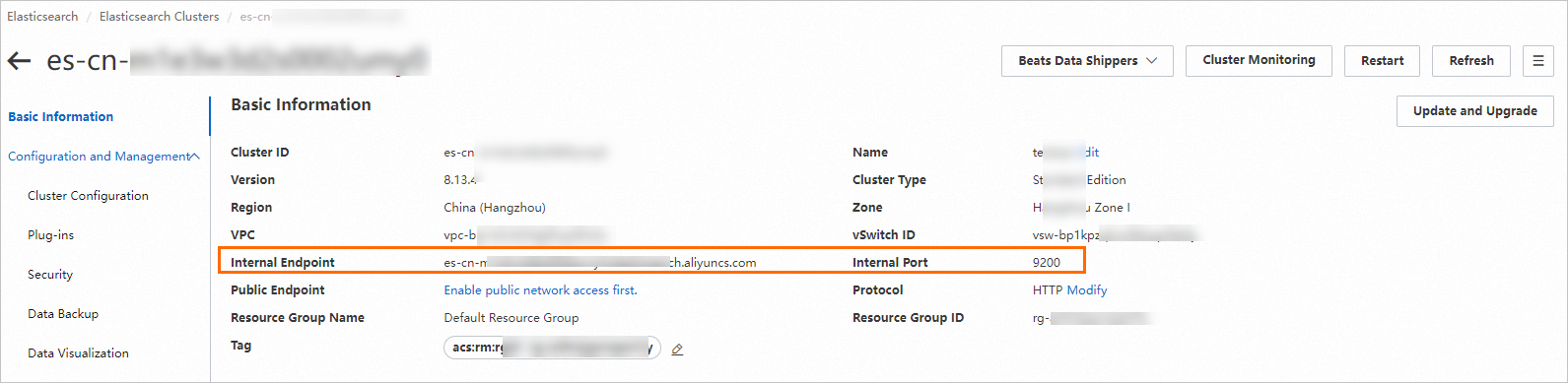
形式は次のとおりです:
http://<Internal endpoint>:<Port number>。重要内部エンドポイントを使用する場合、Elasticsearch インスタンスと PAI-RAG サービスが同一の VPC 内にあることを確認してください。そうでない場合、接続は失敗します。
インデックス名を準備します。
Elasticsearch インスタンスのページで、構成の変更をクリックします。YML ファイル構成セクションの右上隅で、自動インデックス作成を有効に設定します。詳細については、「YML ファイルによる Elasticsearch クラスター設定の構成」をご参照ください。
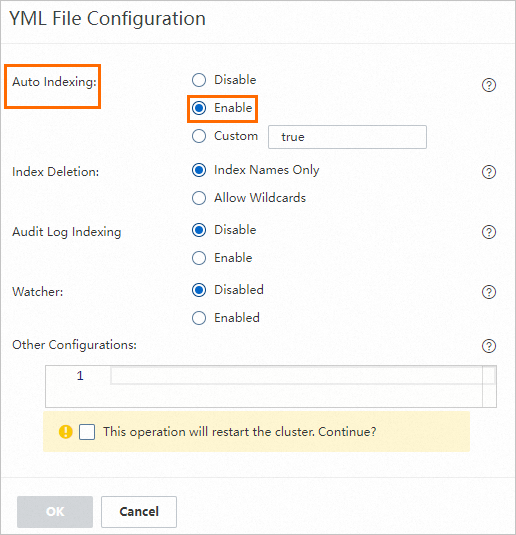
この設定を有効にすると、PAI-RAG サービスをデプロイする際に、
es-testのようなカスタムインデックス名を指定できます。ES ユーザー名とパスワードを準備します。
ES ユーザー名はデフォルトで elastic です。ES パスワードは、ES インスタンス作成時に設定したログインパスワードです。パスワードを忘れた場合は、リセットできます。詳細については、「elastic パスワードのリセット」をご参照ください。
RAG サービスのデプロイと Elasticsearch への接続
PAI コンソールにログインします。ページ上部で、ワークスペースを作成するリージョンを選択します。左側のナビゲーションウィンドウで、[モデルトレーニング] > [Elastic Algorithm Service (EAS)] を選択します。表示されたページで、目的のワークスペースを選択し、Elastic Algorithm Service (EAS) に移動をクリックします。
Elastic Algorithm Service (EAS) ページで、サービスのデプロイをクリックします。シナリオベースのモデルデプロイで、RAG ベースのスマートダイアログデプロイをクリックします。
RAG ベースの LLM チャットボットデプロイページで、以下の主要パラメーターを設定します。その他のパラメーターの詳細については、「ステップ 1:RAG ベースのチャットボットのデプロイ」をご参照ください。
パラメーター
説明
基本情報
バージョン
LLM 統合デプロイ を選択します。
モデルタイプ
Qwen1.5-1.8b を選択します。
リソース情報
デプロイリソース
選択したモデルタイプに基づき、システムが適切なリソース仕様を自動的に推奨します。別の仕様に変更すると、モデルサービスの起動が失敗する可能性があります。
ベクトルデータベース設定
ベクトルデータベースタイプ
Elasticsearch を選択します。
プライベートエンドポイントとポート
ステップ 2 で取得した Elasticsearch URL を、形式
http://<Internal-Endpoint>:<Port-Number>で入力します。インデックス名
新しいインデックス名または既存のインデックス名を入力します。既存のインデックス名を使用する場合、その構造は PAI-RAG の要件に準拠している必要があります。たとえば、以前に EAS を介して RAG サービスをデプロイした際に自動作成されたインデックスを指定できます。
アカウント
elastic を入力します。
パスワード
ステップ 2 で設定したログインパスワードを入力します。
VPC(任意)
VPC
設定する VPC が Elasticsearch インスタンスで使用しているものと同一であることを確認します。
vSwitch
セキュリティグループ名
パラメーターを設定したら、デプロイをクリックします。
RAG ベースの LLM チャットボットの使用
以下では、RAG ベースの LLM チャットボットの使用方法について説明します。詳細については、「LLM 向け RAG チャットボット」をご参照ください。
1. ベクトルデータベース設定の確認
目的の RAG サービスの名前をクリックし、右上隅の Web アプリの表示 をクリックします。
Elasticsearch ベクトルデータベースの設定を確認します。
システムはデフォルトのナレッジベースを自動的に構成し、デプロイ時に指定したベクトルデータベース設定を適用します。ベクトルデータベース設定エリアで、Elasticsearch の設定が正しいかどうかを確認します。必要に応じて設定を変更し、ElasticSearch に接続をクリックできます。
2. 企業ナレッジベースファイルのアップロード
ナレッジベースタブで、ファイル管理タブに移動し、ナレッジベースファイルをアップロードします。
アップロードが完了すると、システムはファイルを自動的にベクトルデータベースにPAI-RAGフォーマットで保存します。同じ名前のファイルをアップロードした場合、FAISSを除くすべてのベクトルデータベースで既存のファイルが上書きされます。サポートされているファイル形式には、.html、.htm、.txt、.pdf、.pptx、.md、Excel(.xlsx または .xls)、.jsonl、.jpeg、.jpg、.png、.csv、およびWord(.docx)が含まれます。例: rag_chatbot_test_doc.txt。
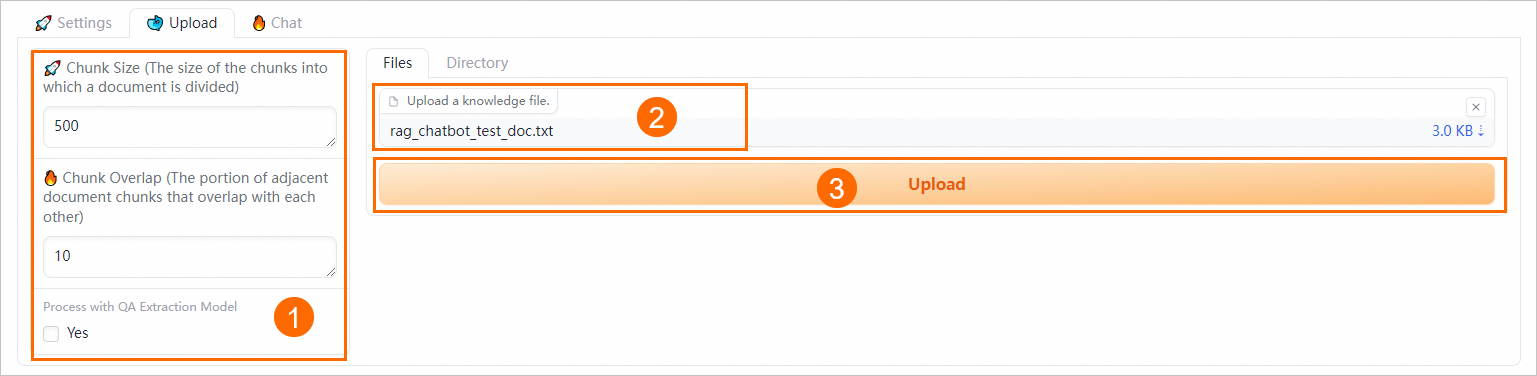
3. ナレッジ Q&A の実行
[チャット] タブで、ナレッジベース名と [検索モード] を選択して、質問を開始します。
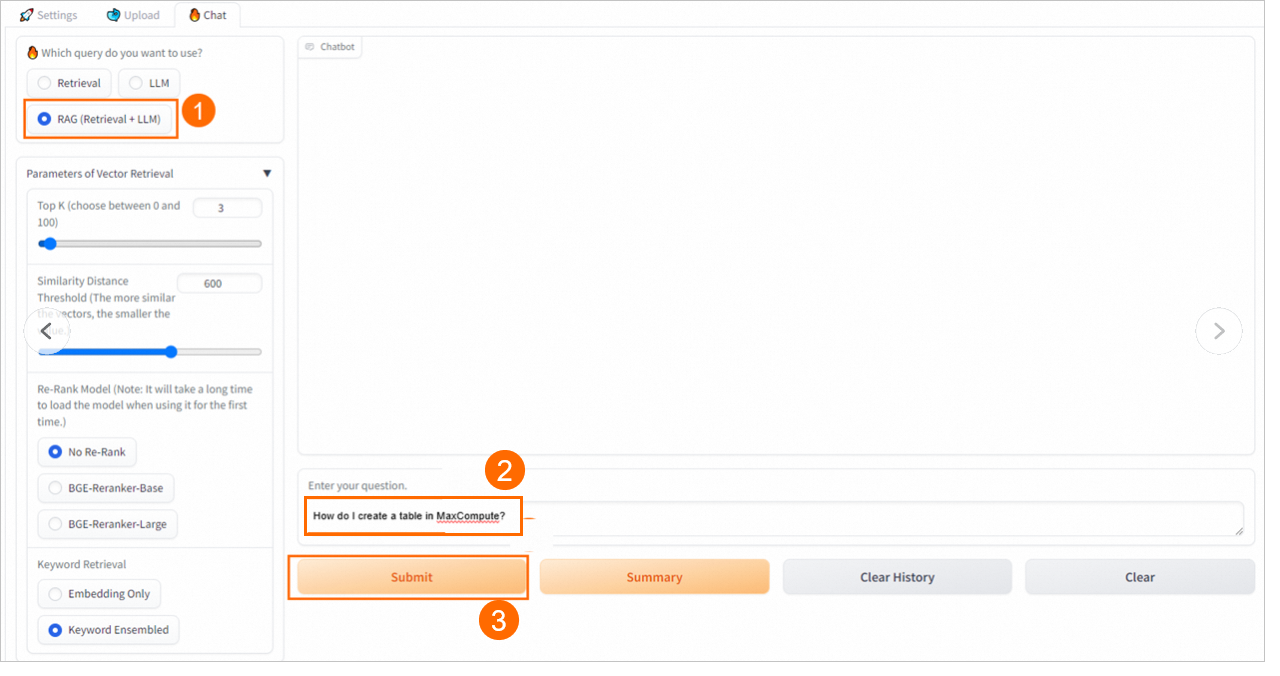
Elasticsearch が提供する特化機能
トークン化およびストップワード辞書のカスタマイズ
Alibaba Cloud Elasticsearch には、組み込みの IK 分析プラグイン (analysis-ik) が搭載されています。IK アナライザは文を文字ではなく単語単位でトークン化します。複雑な中国語テキストのトークン化用のメイン辞書と、一般的で低価値な単語(例:「the」「is」「at」など)をフィルターするストップワード辞書を含んでいます。これらの辞書は取得の効率性と正確性を向上させます。デフォルト辞書は強力ですが、法律や医療などの専門分野には多くの専門用語が存在します。また、ナレッジベースにはデフォルト辞書に含まれていない製品名、企業名、ブランド名が含まれている可能性があります。ビジネスニーズに合わせて検索結果を改善するために、カスタム辞書を作成できます。Elasticsearch IK 分析プラグインの詳細については、「analysis-ik プラグインの使用」をご参照ください。
1. メイン辞書またはストップワード辞書の準備
ローカルでカスタムのメイン辞書またはストップワード辞書を準備します。
ファイル形式:ファイルは
.dicファイルである必要があります。ファイル名には大文字、小文字、数字、アンダースコアを使用でき、30 文字以内である必要があります。たとえば、new_word.dicなどです。内容要件:ファイルに新しい単語またはストップワードを 1 行ずつ追加します。たとえば、組み込みのトークナイザーは「cloud server」を「cloud」と「server」に分割しますが、ビジネス要件でこれを 1 つの用語として扱う必要がある場合、「cloud server」をメイン辞書に追加できます。
new_word.dicファイルの内容は次のようになります。
cloud server custom token
2. 辞書ファイルのアップロード
辞書ファイルを準備したら、指定された場所にアップロードする必要があります。以下の手順は、ローリングアップデートを使用してこれを行う方法を示しています。辞書ファイルを更新する他の方法については、「analysis-ik プラグインの使用」をご参照ください。
Elasticsearch インスタンスの詳細ページに移動します。
Alibaba Cloud Elasticsearch コンソールにログインします。
左側のナビゲーションウィンドウで、Elasticsearch インスタンスをクリックします。
目的のクラスターに移動します。
上部ナビゲーションバーで、クラスターが属するリソースグループとクラスターが配置されているリージョンを選択します。
Elasticsearch インスタンスページで、目的のクラスターを見つけ、その ID をクリックします。
表示されたページの左側ナビゲーションウィンドウで、を選択します。
ビルトインプラグインリストタブで、analysis-ik プラグインを見つけ、操作列のローリングアップグレードをクリックします。
IK 辞書の構成 - ローリングアップデートパネルで、更新する辞書の右側にある編集をクリックし、辞書ファイルをアップロードしてから、保存をクリックします。
辞書ファイルを更新する方法は以下のいずれかです。
オンプレミスファイルのアップロード:アップロード領域をクリックして、ローカルマシンからアップロードするファイルを選択します。または、ローカルマシンからアップロードするファイルをアップロード領域にドラッグします。
OSS ファイルのアップロード:[バケット名] および [ファイル名] パラメーターを設定し、追加をクリックします。
指定するバケットが Elasticsearch クラスターと同じリージョンに配置されていることを確認してください。
指定する辞書ファイルは自動的に更新されません。OSS に保存されている辞書ファイルの内容が変更された場合、変更を反映させるにはローリングアップデートを実行する必要があります。
説明複数の辞書ファイルをアップロードできます。ファイルは
.dic拡張子を持つ必要があります。ファイル名には大文字、小文字、数字、アンダースコアを使用でき、30 文字以内である必要があります。アップロード済み辞書の内容を変更するには、対象辞書ファイルの横にある
 アイコンをクリックしてダウンロード・編集し、コンソールから元のファイルを削除してから修正版を再アップロードします。新しいファイルをアップロードする際に重複ファイル名エラーが発生しないように、元のファイルを削除した後に必ず保存をクリックする必要があります。
アイコンをクリックしてダウンロード・編集し、コンソールから元のファイルを削除してから修正版を再アップロードします。新しいファイルをアップロードする際に重複ファイル名エラーが発生しないように、元のファイルを削除した後に必ず保存をクリックする必要があります。
OK をクリックします。辞書ファイルの更新後、Web UI 上で RAG ベースの LLM チャットボットを Elasticsearch クラスターに再接続します。詳細については、「ベクトルデータベースへの接続」をご参照ください。
再接続後、WebUI で質問できます。取得モードがキーワードのみまたはハイブリッド(ベクトル検索 + キーワード検索)に設定されている場合、Elasticsearch は更新された辞書を使用して全文検索を実行します。
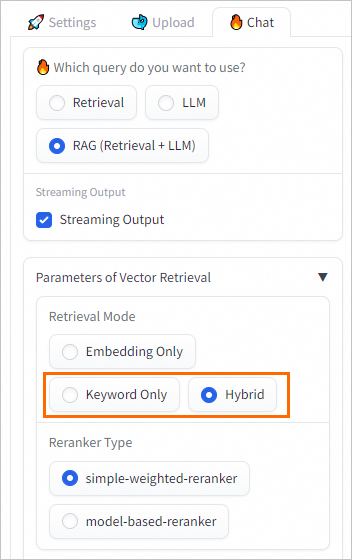
インデックス管理
Elasticsearch はインデックス管理機能を提供しています。効果的なインデックス管理により、RAG ベースの LLM チャットボットは膨大なデータセットから効率的かつ正確に価値ある情報を取得し、高品質な回答を生成できます。インデックスを管理するには、以下の手順を実行します。
Elasticsearch クラスターの詳細ページに移動します。
Alibaba Cloud Elasticsearch コンソールにログインします。
左側のナビゲーションメニューで、Elasticsearch クラスターを選択します。
目的のクラスターに移動します。
上部ナビゲーションバーで、クラスターが属するリソースグループとクラスターが配置されているリージョンを選択します。
Elasticsearch クラスターページで、目的のクラスターを見つけ、その ID をクリックします。
表示されたページの左側ナビゲーションウィンドウで、を選択します。
表示されたページのKibanaセクションで、構成の変更をクリックします。Kibana 構成ページで、Kibana のプライベートまたはパブリック IP アドレスホワイトリストを設定します。
詳細については、「Kibana のパブリックまたはプライベート IP アドレスホワイトリストの設定」をご参照ください。
Kibana コンソールにログインします。
ページ左上隅の戻るアイコンをクリックして、[データ可視化] ページに戻ります。
Kibanaセクションで、インターネット経由でのアクセスまたはイントラネット経由でのアクセスをクリックします。
説明[インターネット経由でのアクセス] または [イントラネット経由でのアクセス] のエントリは、Kibana のパブリックネットワークアクセスまたはプライベートネットワークアクセスのスイッチがオンになっている場合にのみ表示されます。
Kibana ログインページで、ユーザー名とパスワードを入力します。
ユーザー名:Elasticsearch クラスターのデフォルトユーザー名は elastic です。
カスタムユーザー名も設定できます。詳細については、「Elasticsearch X-Pack が提供する RBAC メカニズムを使用したアクセス制御の実装」をご参照ください。
パスワード:elastic ユーザー名に対応するパスワードです。elastic アカウントのパスワードは、Elasticsearch クラスター作成時に指定します。パスワードを忘れた場合は、リセットできます。
パスワードリセットの手順および注意事項の詳細については、「Elasticsearch クラスターのアクセスパスワードのリセット」をご参照ください。
ログインをクリックします。下図のようなページが表示されます。
インデックスの表示および管理を行います。
上部ナビゲーションバーで、
 アイコンをクリックし、を選択します。
アイコンをクリックし、を選択します。左側ナビゲーションウィンドウで、データ > インデックス管理を選択します。
表示されたページの [インデックス] タブで、管理対象のインデックスを表示し、インデックスの無効化、リフレッシュ、クリア、削除などの管理操作を実行します。下図は、es_test という名前のインデックスを管理する例を示しています。
参考資料
EAS は AIGC および LLM シナリオ向けのデプロイを簡素化し、ワンクリックで簡単にサービスを起動できます。詳細については、「シナリオベースのデプロイ」をご参照ください。
RAG サービスの WebUI は幅広い推論パラメーターを提供しています。RAG サービスは API 呼び出しにも対応しています。実装の詳細およびパラメーター設定については、「LLM 向け RAG チャットボット」をご参照ください。
RAG チャットボットは、OpenSearch や RDS for PostgreSQL などの他のベクトルデータベースにも接続できます。詳細については、「EAS と OpenSearch を使用した RAG ベースのチャットボットのデプロイ」または「EAS と RDS PostgreSQL を使用した RAG チャットボットのデプロイ」をご参照ください。