ビジネスシナリオにおいて、ジョブは意思決定を支援するために、指定された時間内に結果を生成することが求められます。MaxCompute の Logview 機能を利用することで、ジョブのステータスを監視し、実行が遅いジョブを診断できます。本トピックでは、低速ジョブの一般的な原因、分析方法、および解決策について説明します。
失敗したジョブの分析
ジョブが失敗した場合、Logview の [Result] タブでエラーメッセージを確認できます。失敗したジョブの場合、Logview はデフォルトでこのタブを開きます。
ジョブが失敗する一般的な原因は次のとおりです:
SQL 構文エラー。この場合、ジョブは計算クラスターに送信されないため、有向非巡回グラフ (DAG) や Fuxi ジョブは生成されません。
ユーザー定義関数 (UDF) エラー。[Job Details] タブで DAG を確認し、問題のある UDF を特定します。次に、[StdOut] または [StdErr] ログでエラーメッセージを確認します。
その他のエラー。詳細については、「エラーコードとソリューション」をご参照ください。
低速ジョブの分析
コンパイルフェーズ
コンパイルフェーズでは、ジョブには Logview ID がありますが、実行計画はありません。サブステータスの履歴 (SubStatusHistory) には、スケジューリング、最適化、物理実行計画の生成、クラスター間のデータレプリケーションなどのサブフェーズが表示されます。 このフェーズの問題は、通常、ジョブが特定のサブフェーズでスタックする原因となります。以下のセクションでは、各サブフェーズでジョブがスタックする原因と解決策について説明します。
このフェーズの問題は、通常、ジョブが特定のサブフェーズでスタックする原因となります。以下のセクションでは、各サブフェーズでジョブがスタックする原因と解決策について説明します。
スケジューリングフェーズ
現象:サブステータスが
Waiting for cluster resourceであり、ジョブがコンパイルのためにキューに入れられています。原因:計算クラスターのリソースが不足しています。
ソリューション:クラスターのステータスを確認します。リソースが利用可能になるまで待機します。サブスクリプションをご利用のお客様は、リソースのスケールアウトを検討できます。
最適化フェーズ
現象:サブステータスが
SQLTask is optimizing queryであり、オプティマイザーが実行計画を生成していることを示します。原因:実行計画が複雑で、最適化に長い時間がかかります。
ソリューション:プロセスが完了するまで待機します。通常、この処理には 10 分もかかりません。
物理実行計画の生成フェーズ
現象:サブステータスが
SQLTask is generating execution planです。原因 1:読み取られるパーティションが多すぎます。
ソリューション:SQL クエリを最適化して、読み取るパーティションの数を減らします。パーティションプルーニングを使用するか、不要なパーティションをフィルターするか、大きなジョブを小さなジョブに分割します。詳細については、「パーティションプルーニングの有効性の評価」をご参照ください。
原因 2:小規模ファイルが多すぎます。これは、多くの場合、次の原因で発生します:
不適切な Tunnel アップロード操作。たとえば、アップロードされるファイルごとに新しい
upload sessionを作成するなどです。詳細については、「Tunnel コマンドに関するよくある質問」をご参照ください。INSERT INTO操作により、パーティションテーブルの [partition] ディレクトリに新しいファイルが生成されます。
ソリューション:
TunnelBufferedWriter インターフェイスを使用してファイルをアップロードします。これにより、過剰な小規模ファイルの作成を回避できます。
小規模ファイルを手動でマージします。詳細については、「小規模ファイルのマージ」をご参照ください。
説明小規模ファイルの数が 10,000 を超える場合は、マージできます。システムは毎日小規模ファイルのマージを試みますが、自動マージが失敗した場合は手動でのマージが必要になることがあります。
クラスター間のデータレプリケーションフェーズ
現象:サブステータスリストに複数の
Task rerunエントリが表示され、[Result] タブにエラーFAILED: ODPS-0110141:Data version exceptionが表示されます。ジョブのステータスは Running です。これは、クラスター間のデータレプリケーションがアクティブであることを示します。原因 1:プロジェクトが最近新しいクラスターに移行されました。移行後の最初の数日間は、クラスター間のレプリケーションが一般的です。
ソリューション:これは想定内の動作です。レプリケーションが完了するまで待機します。
原因 2:プロジェクトは移行されましたが、パーティションのフィルターが正しく処理されず、古いパーティションが読み取られています。
ソリューション:読み取る必要のない古いパーティションをフィルターで除外します。
実行フェーズ
実行フェーズでは、[Job Details] ページに実行計画が表示されますが、ジョブのステータスは Running のままです。遅延の一般的な原因には、リソースの待機、データスキュー、非効率な UDF、データ膨張などがあります。
リソースの待機
特徴:インスタンスが Ready ステータスであるか、一部が Running で他が Ready です。注:インスタンスが Ready であっても [Debug] 履歴がある場合、リソースを待機しているのではなく、失敗後にリトライしている可能性があります。

ソリューション:
キューイングが正常かどうかを確認します。Logview で
Queue Lengthを確認します。 または、MaxCompute コンソールでクォータグループのリソース使用量を確認します。 使用率が高い場合、キューイングは想定内の動作です。
または、MaxCompute コンソールでクォータグループのリソース使用量を確認します。 使用率が高い場合、キューイングは想定内の動作です。クォータグループで実行中のジョブを確認します。
優先度の低い大規模なジョブ (または多数の小規模なジョブ) がリソースを消費している可能性があります。必要に応じて、ジョブのオーナーに連絡してジョブを一時停止します。
別のクォータグループのプロジェクトを使用します。
リソースをスケールアウトします (サブスクリプションをご利用のお客様向け)。
データスキュー
特徴:ほとんどのインスタンスは終了していますが、いくつかの「ロングテール」インスタンスはまだ実行中です。図では、ほとんどが完了していますが、21 個がまだ Running であり、より多くのデータを処理している可能性があります。

ソリューション:原因と解決策については、「データスキューの最適化」をご参照ください。
非効率な UDF の実行
これには、UDF、UDAF、UDTF、UDJ、UDT が含まれます。
特徴:タスクが非効率で、ユーザー定義の拡張が含まれています。
Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeoutのようなエラーが発生することがあります。トラブルシューティング:[Job Details] タブの DAG で UDF を確認します。たとえば、図のタスク [R4_3] は Java UDF を使用しています。
 Operator ビューを展開して UDF 名を確認します。
Operator ビューを展開して UDF 名を確認します。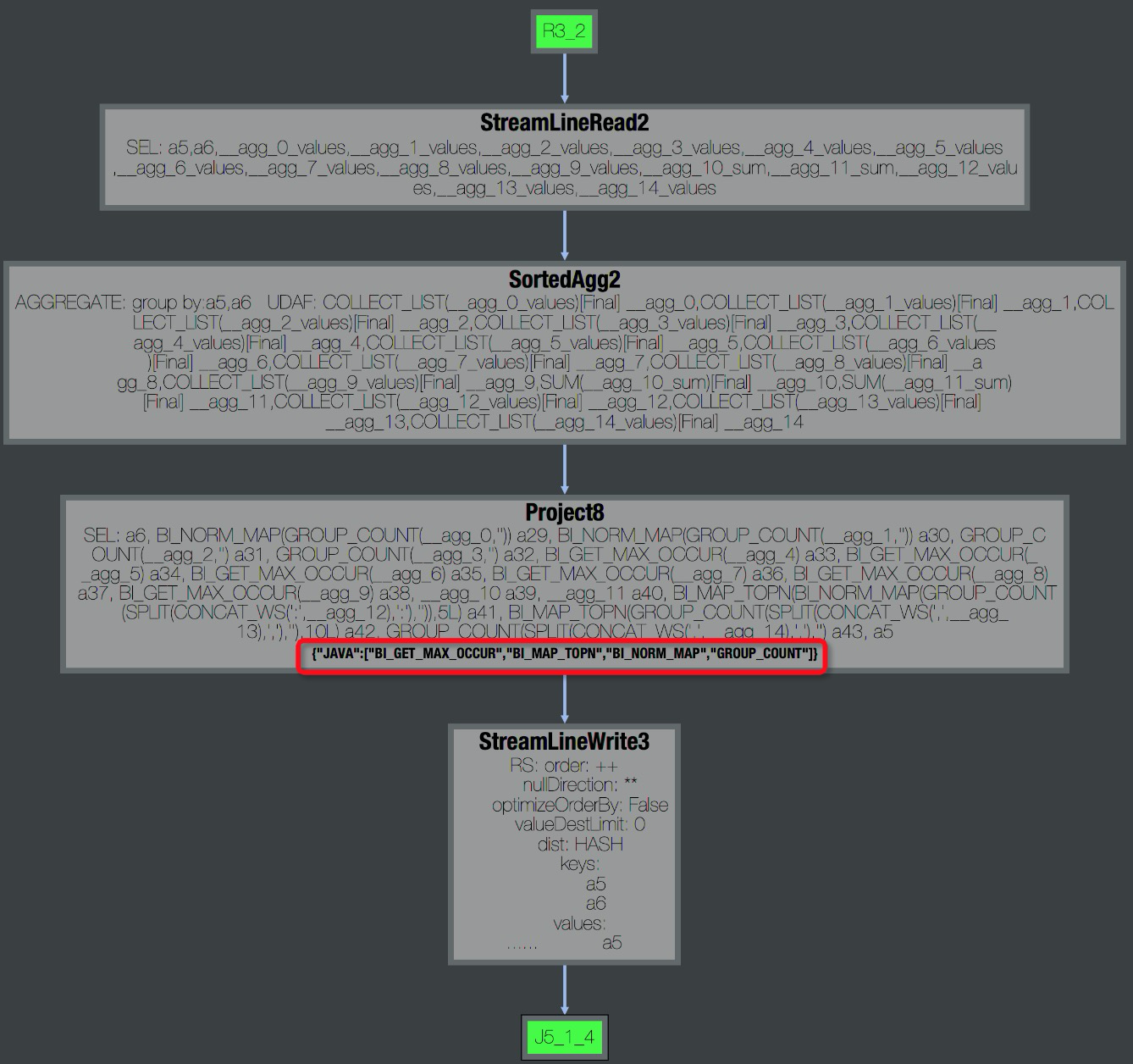 [StdOut] で処理速度を確認します。速度が数万レコード/秒未満の場合、多くはパフォーマンスの問題を示しています。
[StdOut] で処理速度を確認します。速度が数万レコード/秒未満の場合、多くはパフォーマンスの問題を示しています。
ソリューション:
UDF にエラーがないか確認します。
エラーはデータに依存する場合があります (例:無限ループ)。MaxCompute Studio を介してサンプルデータをダウンロードし、ローカルでデバッグします。詳細については、「Java UDF」および「Python UDF」をご参照ください。
ビルトイン関数との名前の競合を確認します。
UDF が意図せずビルトイン関数をオーバーライドしていないことを確認してください。
ビルトイン関数を使用します。
ビルトイン関数はより効率的で最適化されています。詳細については、「ビルトイン関数」をご参照ください。
UDF を分割します。サポートされている部分にはビルトイン関数を使用し、必要な場合にのみ UDF を使用します。
UDF の `evaluate` メソッドを最適化します。
繰り返しを避けるために、`evaluate` メソッドの外部で一度だけの初期化を実行します。
UDF の実行時間を見積もります。
ローカルでシミュレーションして実行時間を見積もります。デフォルトの制限は 30 分です。UDF はこの時間内にデータを返すか、`context.progress()` をレポートする必要があります。必要に応じて、タイムアウトを延長できます:
-- UDF のタイムアウトを秒単位で設定 (デフォルト 600、有効値 0-3600) set odps.sql.udf.timeout = 1800;メモリパラメーターを調整します。
非効率性はメモリの問題 (例:メモリ内での大規模データのソート、頻繁な GC) に起因する可能性があります。
必要に応じて JVM メモリを調整しますが、ビジネスロジックの根本原因に対処してください。
-- JVM の最大ヒープメモリを MB 単位で設定 (デフォルト 1024、有効値 256-12288) set odps.sql.udf.jvm.memory = 2048;説明UDF でパーティションプルーニングを許可するには、
UdfPropertyアノテーションを使用して、関数が決定論的であることをマークします:@com.aliyun.odps.udf.annotation.UdfProperty(isDeterministic = true) public class AnnotatedUdf extends com.aliyun.odps.udf.UDF { public String evaluate(String x) { return x; } }パーティションフィルタリングで UDF を使用するように SQL を書き換えます:
-- オリジナル SELECT * FROM t WHERE pt = udf('foo'); -- 書き換え後 SELECT * FROM t WHERE pt = (SELECT udf('foo'));
データ膨張
特徴:出力ボリュームが入力ボリュームよりも大幅に大きい (例:1 GB が 1 TB になる)。[I/O Records] を確認します。Join フェーズでスタックしている場合は、[StdOut] で Merge Join ログを確認します。過剰な出力レコードはデータ膨張を示します。


ソリューション:
コードエラーを確認します:不適切な JOIN 条件、デカルト積、または UDTF エラー。
集約によって引き起こされる膨張を確認します:
問題は次の場合に発生します:
異なるディメンションでの集約で `DISTINCT` を使用する場合。
GROUPING SETS、CUBE、または ROLLUP、あるいは COLLECT_LIST や MEDIAN のような中間データを保持する関数を使用する場合。
結合による膨張を回避します。
行の拡張を避けるために、結合する前にディメンションテーブルを集約します。
Grouping Set による膨張を管理します。ダウンストリームタスクの並列処理を手動で設定します:
set odps.stage.reducer.num = xxx; set odps.stage.joiner.num = xxx;
最終フェーズ
Fuxi ジョブが Terminated になった後でも、ジョブのステータスが Running のままになることがあります。 これは一般的に次の場合に発生します:
これは一般的に次の場合に発生します:
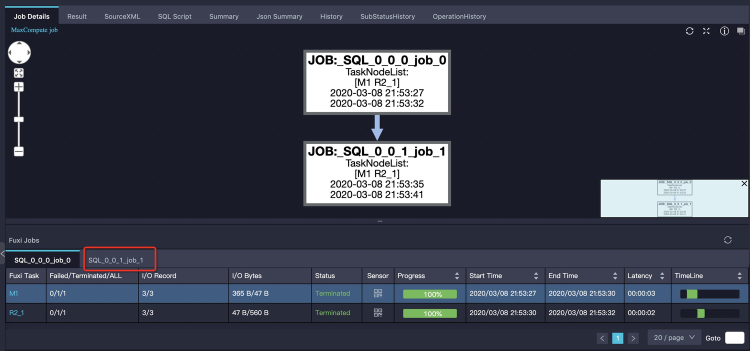
SQL ジョブに複数の Fuxi ジョブ (例:サブクエリ、自動マージジョブ) が含まれている。
メタデータの更新やその他のコントロールクラスターの操作に時間がかかっている。
サブクエリの多段階実行
一部のサブクエリ (例えば、
IN句内のSELECT DISTINCTなど) は、最初に個別に実行されます。SELECT product, sum(price) FROM sales WHERE ds in (SELECT DISTINCT ds FROM t_ds_set) GROUP BY product;Logview のタブを確認します。最初のタブが完了している間に、2 番目のタブが実行中である可能性があります。

小規模ファイルが多すぎる
過剰な小規模ファイルは、ストレージ (Pangu への負荷) と計算 (低効率) に影響を与えます。
ソリューション:Logview に個別の Merge Task タブがあるか確認します。このタスクは、ダウンストリームのパフォーマンスを向上させるために小規模ファイルをマージします。

多数の小規模ファイルを出力する
SELECT文の使用を避けてください。代わりに Tunnel コマンドを使用します。小規模ファイルのマージしきい値が正しく設定されていることを確認してください。詳細については、「小規模ファイルのマージ」をご参照ください。動的パーティションのメタデータ更新
現象:多数の動的パーティションのメタデータ更新が遅くなることがあります。Logview には
SQLTask is updating meta informationと表示されます。
出力ファイルサイズの増加
現象:レコード数が似ているにもかかわらず、出力ファイルサイズが入力よりもはるかに大きい。

ソリューション:データの分散が圧縮に影響します。データをソートすると圧縮率が向上します。JOIN では、ソート列 (Join Key) が類似のデータをグループ化するようにします。たとえば、次のように変更します:
on t1.query = t2.query and t1.item_id = t2.item_id宛先:
on t1.item_id = t2.item_id and t1.query = t2.query`item_id` の方がグループ化の特性が優れている場合。
あるいは、Z オーダーソートまたは
DISTRIBUTE BY ... SORT BYを使用して圧縮を改善することもできますが、これにより計算コストが増加します。