このトピックでは、Tunnelコマンドに関するよくある質問に対する回答を提供します。
Tunnel Uploadコマンドはワイルドカードまたは正規表現をサポートしていますか?
いいえ、Tunnel Uploadコマンドはワイルドカードまたは正規表現をサポートしていません。
Tunnel Uploadコマンドを使用してファイルをアップロードすると、ファイルサイズが制限されますか? データレコードのサイズは制限されていますか? アップロードされたファイルは圧縮されていますか?
いいえ、Tunnel Uploadコマンドを使用してファイルをアップロードする場合、ファイルサイズは制限されません。 ただし、アップロード時間は2時間を超えることはできません。 アップロード速度と期間に基づいて、アップロードできるデータの最大サイズを見積もることができます。
データレコードのサイズは200 MBを超えることはできません。
既定では、Tunnel Uploadコマンドは、データが圧縮された後にデータをアップロードします。 アップロード帯域幅が十分な場合は、-cpパラメーターをfalseに設定して、データ圧縮を無効にできます。
Tunnel Uploadコマンドを実行して、複数のデータファイルを同じテーブルまたはパーティションに同時にアップロードできますか?
はい。Tunnel Uploadコマンドを実行して、複数のデータファイルを同じテーブルまたはパーティションに同時にアップロードできます。
Tunnel uploadコマンドを使用して、複数のクライアントが同時に同じテーブルにデータをアップロードできますか。
はい。Tunnel uploadコマンドを使用して、複数のクライアントが同時に同じテーブルにデータをアップロードできます。
データをアップロードするとき、Tunnel uploadコマンドで指定された宛先パーティションがすでに存在することを確認する必要がありますか?
はい、宛先パーティションがすでに存在することを確認する必要があります。 Tunnel Uploadコマンドで -acpパラメーターを指定して、指定されたパーティションが存在しない場合にシステムが自動的に宛先パーティションを作成できるようにすることもできます。 このパラメーターのデフォルト値はFalseです。 詳細については、「Tunnelコマンド」をご参照ください。
Tunnel Uploadコマンドを使用してデータをアップロードすると、圧縮データのサイズに基づいて課金されますか?
はい。Tunnel Uploadコマンドを使用してデータをアップロードすると、圧縮データのサイズに基づいて課金されます。
Tunnel uploadコマンドを使用してデータをアップロードするときにアップロード速度を制御できますか?
いいえ、Tunnel uploadコマンドを使用してデータをアップロードする場合、アップロード速度を制御できません。
Tunnel Uploadコマンドを使用してデータをアップロードすると、データのアップロードを高速化できますか?
データのアップロードに時間がかかる場合は、データをアップロードする前に、-threadsパラメーターを設定して、データを複数のパーツ (10パーツなど) にスライスできます。 サンプルコマンド:
tunnel upload C:\userlog.txt userlog1 -threads 10 -s false -fd "\u0000" -rd "\n";Tunnel Uploadコマンドを使用してデータをアップロードするときは、クラウド製品相互接続ネットワークのTunnelエンドポイントをMaxComputeプロジェクトに設定しますが、プロジェクトはパブリックトンネルエンドポイントに接続されています。 これはなぜですか。
MaxComputeのエンドポイントに加えて、MaxComputeクライアントのodps_config.iniファイルでTunnelエンドポイントを設定する必要があります。 トンネルエンドポイントの設定方法の詳細については、「エンドポイント」をご参照ください。 中国 (上海) リージョンのMaxComputeプロジェクトにTunnelエンドポイントを設定する必要はありません。
Tunnel Uploadコマンドを使用してDataStudioのパーティションにデータをアップロードするときにエラーが返された場合はどうすればよいですか?
問題の説明
Tunnel Uploadコマンドを使用してDataStudioのパーティションにデータをアップロードすると、次のエラーメッセージが表示されます。
FAILED: error occurred while running tunnel command.原因
DataStudioはTunnel Uploadコマンドをサポートしていません。
解決策
DataWorksが提供する視覚化されたデータインポート機能を使用して、データをアップロードします。 詳細については、「MaxComputeテーブルへのデータのインポート」をご参照ください。
Tunnel uploadコマンドを使用して改行またはスペースを含むデータをアップロードすると、アップロードが失敗するのはなぜですか。
データに改行またはスペースが含まれている場合は、データ内の改行およびスペースを他の区切り文字に置き換え、-rdおよび -fdパラメーターを使用して、Tunnel Uploadコマンドで新しい区切り文字を指定できます。 データの行または列の区切り文字を変更できない場合は、データを1行としてアップロードし、ユーザー定義関数 (UDF) を使用してデータを解析できます。
次の例では、データに改行が含まれています。 データをアップロードするには、-rdパラメーターを使用して列の区切り文字としてコンマ (,) を指定し、-fdパラメーターを使用して行の区切り文字としてアットサイン (@) を指定します。
shopx,x_id,100@
shopy,y_id,200@
shopz,z_id,300@サンプルコマンド:
tunnel upload d:\data.txt sale_detail/sale_date=201312,region=hangzhou -s false -rd "," -fd "@";次の応答が返されます。
+-----------+-------------+-------------+-----------+--------+
| shop_name | customer_id | total_price | sale_date | region |
+-----------+-------------+-------------+-----------+--------+
| shopx | x_id | 100.0 | 201312 | hangzhou |
| shopy | y_id | 200.0 | 201312 | hangzhou |
| shopz | z_id | 300.0 | 201312 | hangzhou |
+-----------+-------------+-------------+-----------+--------+Tunnel Uploadコマンドを使用してデータをアップロードするときにOOMエラーが発生した場合はどうすればよいですか?
Tunnel Uploadコマンドを使用すると、大量のデータをアップロードできます。 ただし、設定した行区切り文字または列区切り文字が無効な場合、すべてのデータは単一の行と見なされ、メモリにキャッシュされます。 その結果、メモリ不足 (OOM) エラーが発生する。
OOMエラーが発生した場合は、少量のデータをアップロードしてテストを実行できます。 -tdおよび -fdパラメーターで指定された区切り文字に基づいてテストが成功した場合、Tunnel Uploadコマンドを使用してすべてのデータをアップロードできます。
Tunnel uploadコマンドを使用して、フォルダ内のすべてのデータファイルを一度にテーブルにアップロードするにはどうすればよいですか?
Tunnel Uploadコマンドを使用して、単一のファイルまたは単一のレベル1ディレクトリ内のすべてのファイルを一度にアップロードできます。 詳細については、「使用状況のメモ」をご参照ください。
たとえば、d:\dataディレクトリ内のすべてのファイルを一度にアップロードする場合は、次のコマンドを実行します。
tunnel upload d:\data sale_detail/sale_date=201312,region=hangzhou -s false;Tunnel Uploadコマンドを使用して、ディレクトリ内の複数のファイルを一度にテーブル内の異なるパーティションにアップロードするにはどうすればよいですか?
この操作は、シェルスクリプトを使用して実行できます。 次の例では、MaxComputeクライアントでシェルスクリプトを使用して、Windowsでファイルをアップロードします。 Linuxでの操作も同様です。 シェルスクリプトには次の内容が含まれています。
#!/bin/sh
C:/odpscmd_public/bin/odpscmd.bat -e "create table user(data string) partitioned by (dt int);" // Create a partitioned table named user that contains the partition keyword dt. In this example, the MaxCompute client file odpscmd.bat is stored in the C:/odpscmd_public/bin directory. You can change the directory based on your business requirements.
dir=$(ls C:/userlog) // Define the dir variable. This variable specifies the directory in which all files are saved.
pt=0 // The pt variable specifies the value of a partition key column. The initial value of this variable is 0, and the value increases by one each time a file is uploaded. This way, the files are saved to different partitions.
for i in $dir // Define a loop to traverse all files in the C:/userlog directory.
do
let pt=pt+1 // The value of the pt variable increases by one each time a loop ends.
echo $i // Display the file name.
echo $pt // Display the partition name.
C:/odpscmd_public/bin/odpscmd.bat -e "alter table user add partition (dt=$pt);tunnel upload C:/userlog/$i user/dt=$pt -s false -fd "%" -rd "@";" // Use the MaxCompute client odpscmd to create partitions and upload files to the partitions.
done 次の図は、userlog1およびuserlog2ファイルのアップロードに使用されるシェルスクリプトの出力を示しています。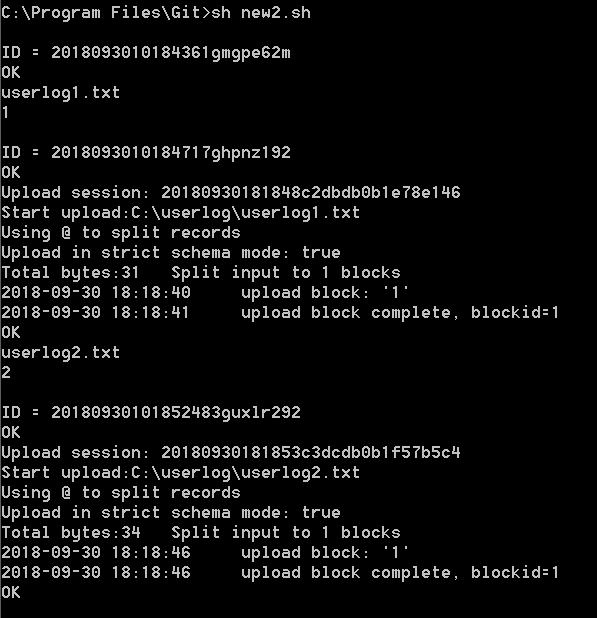
ファイルをアップロードした後、MaxComputeクライアント上のテーブルのデータを照会できます。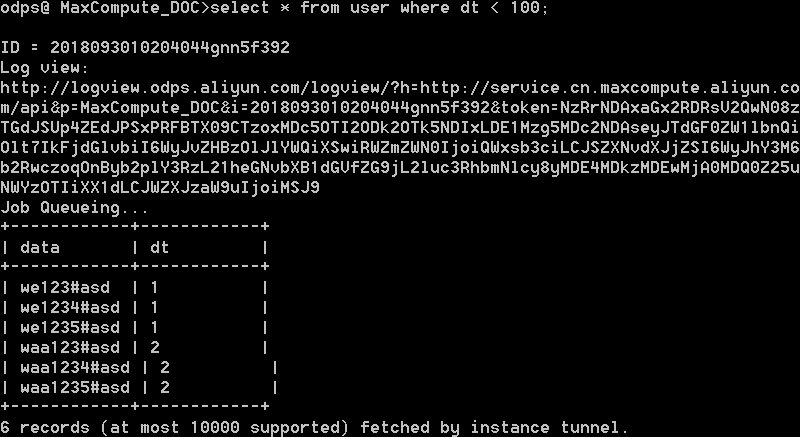
Tunnel Uploadコマンドを使用してデータをアップロードすると、エラーが返されます。 Tunnel Uploadコマンドは、ダーティデータをスキップしてデータをアップロードし続けるために、MySQLの-fパラメーターと同様のパラメーターを提供しますか?
Tunnel Uploadコマンドで -dbrパラメーターをtrueに設定すると、ダーティデータをスキップできます。 ダーティデータは、余分な列が存在する場合、複数の列が欠落している場合、または列のデータ型が一致しない場合に生成されます。 -dbrパラメーターのデフォルト値はfalseです。 この値は、ダーティデータがスキップされないことを示します。 -dbrパラメーターがtrueに設定されている場合、テーブル定義に準拠していないデータはすべてスキップされます。 詳細については、「アップロード」をご参照ください。
Tunnel uploadコマンドを使用してデータをアップロードするときに、「現在のアップロードまたはダウンロードステータスで指定された操作を完了できません」というエラーメッセージが表示された場合はどうすればよいですか?
問題の説明
Tunnel Uploadコマンドを使用してデータをアップロードすると、次のエラーメッセージが表示されます。
java.io.IOException: RequestId=XXXXXXXXXXXXXXXXXXXXXXXXX, ErrorCode=StatusConflict, ErrorMessage=You cannot complete the specified operation under the current upload or download status. at com.aliyun.odps.tunnel.io.TunnelRecordWriter.close(TunnelRecordWriter.java:93) at com.xgoods.utils.aliyun.maxcompute.OdpsTunnel.upload(OdpsTunnel.java:92) at com.xgoods.utils.aliyun.maxcompute.OdpsTunnel.upload(OdpsTunnel.java:45) at com.xeshop.task.SaleStatFeedTask.doWork(SaleStatFeedTask.java:119) at com.xgoods.main.AbstractTool.excute(AbstractTool.java:90) at com.xeshop.task.SaleStatFeedTask.main(SaleStatFeedTask.java:305)java.io.IOException: RequestId=XXXXXXXXXXXXXXXXXXXXXXXXX, ErrorCode=StatusConflict, ErrorMessage=You cannot complete the specified operation under the current upload or download status.原因
ファイルはアップロード中です。 アップロード操作を繰り返し実行することはできません。
解決策
アップロード操作を繰り返す必要はありません。 既存のアップロードタスクが完了するまで待ちます。
Tunnel Uploadコマンドを使用してデータをアップロードするときに、「サーバーへのリクエスト本文の書き込みエラー」というエラーメッセージが表示された場合はどうすればよいですか?
問題の説明
Tunnel Uploadコマンドを使用してデータをアップロードすると、次のエラーメッセージが表示されます。
java.io.IOException: Error writing request body to server原因
この問題は、データがサーバーにアップロードされるときに発生します。 ほとんどの場合、この問題は、データのアップロード中のネットワークの切断またはタイムアウトによって発生します。
データソースがローカルファイルではなく、データベースなどのデータストアから取得する必要がある場合、システムはデータを書き込む前にデータソースからデータを読み取ります。 600秒以内にデータをアップロードしない場合、アップロードはタイムアウトします。
パブリックエンドポイントを使用してデータをアップロードすると、インターネットのネットワークパフォーマンスが不安定なため、アップロードがタイムアウトすることがあります。
解決策
データを取得し、Tunnel SDKを呼び出してデータをアップロードします。
1ブロックに64 MBから100 GBのデータをアップロードできます。 アップロードの再試行によるタイムアウトを防ぐため、最大10,000個のデータレコードをブロックにアップロードすることを推奨します。 セッションは最大20,000ブロックをサポートします。 Elastic Compute Service (ECS) インスタンスからデータをアップロードする場合は、エンドポイントを使用してデータをアップロードする必要があります。 エンドポイントの詳細については、「エンドポイント」をご参照ください。
Tunnel Uploadコマンドを使用してデータをアップロードしたときに「指定されたパーティションが存在しません」というエラーメッセージが表示された場合はどうすればよいですか?
問題の説明
Tunnel Uploadコマンドを使用してデータをアップロードすると、次のエラーメッセージが表示されます。
ErrorCode=NoSuchPartition, ErrorMessage=The specified partition does not exist原因
データをアップロードするパーティションが存在しません。
解決策
show partitions table_name;ステートメントを実行して、データのアップロード先のパーティションが存在するかどうかを確認できます。 パーティションが存在しない場合は、alter table table_name add [If not exists] partition_specステートメントを実行してパーティションを作成します。
Tunnel Uploadコマンドを使用してデータをアップロードしたときに「列の不一致」エラーメッセージが表示された場合はどうすればよいですか?
ほとんどの場合、この問題は、データソースファイルの行区切り文字が無効なために発生します。 その結果、複数のデータレコードが1つのデータレコードとみなされる。 この問題に対処するには、データソースファイルの行区切り文字が有効かどうかを確認する必要があります。 行区切り文字が無効な場合は、-rdパラメーターの値を変更します。
マルチスレッドアップロードシナリオでODPS-0110061エラーが返された場合はどうすればよいですか?
問題の説明
マルチスレッドデータのアップロードシナリオでは、次のエラーメッセージが表示されます。
FAILED: ODPS-0110061: Failed to run ddltask - Modify DDL meta encounter exception : ODPS-0010000:System internal error - OTS transaction exception - Start of transaction failed. Reached maximum retry times because of OTSStorageTxnLockKeyFail(Inner exception: Transaction timeout because cannot acquire exclusive lock.)原因
データをアップロードすると、多数の書き込み操作が同じテーブルに対して同時に実行されます。
解決策
並列書き込み操作の数を減らします。 リクエスト間のレイテンシを設定し、エラーが発生したときに再試行を許可します。
Tunnel Uploadコマンドを使用してCSVファイルをアップロードするときに、CSVファイルのテーブルヘッダーをスキップするにはどうすればよいですか?
Tunnel Uploadコマンドで -hパラメーターをtrueに設定します。
Tunnel Uploadコマンドを使用してCSVファイルをアップロードすると、アップロード後にファイル内のデータの大部分が失われます。 これはなぜですか。
この問題は、データのエンコード形式が無効であるか、データの区切り文字が無効であるために発生します。 データをアップロードする前に、無効なエンコード形式または区切り文字を変更することを推奨します。
シェルスクリプトを使用してTXTファイルのデータをMaxComputeテーブルにアップロードするにはどうすればよいですか?
MaxComputeクライアントのコマンドラインインターフェイス (CLI) では、Tunnel Uploadコマンドでパラメーターを指定してデータをアップロードできます。 次のコマンドの例を示します。
...\odpscmd\bin>odpscmd -e "tunnel upload "$FILE" project.table"MaxComputeクライアントの起動パラメーターの詳細については、「MaxComputeクライアント (odpscmd) 」をご参照ください。
Tunnel Uploadコマンドを使用してフォルダ内のファイルを一度にアップロードすると、"Column Mismatch" というエラーメッセージが表示されますが、ファイルは個別にアップロードできます。 どうすればよいですか。
Tunnel Uploadコマンドで、-dbr=false -s trueを設定してデータ形式を確認します。
ほとんどの場合、アップロードするデータの列数が、データをアップロードするテーブルまたはパーティションの列数と一致しないため、「列の不一致」というエラーメッセージが表示されます。 たとえば、設定した列区切り文字が無効であるか、ファイルが改行で終わる場合、アップロードするデータの列数は、データをアップロードするテーブルまたはパーティションの列数と同じではありません。
Tunnel Uploadコマンドを使用して2つのファイルをアップロードすると、2番目のファイルはアップロードされませんが、最初のファイルがアップロードされた後にエラーメッセージは表示されません。 これはなぜですか。
MaxComputeクライアントで設定されているアップロードパラメーターに -- scanが含まれている場合、再実行モードでのパラメーター転送中にエラーが発生します。 Tunnel Uploadコマンドから -- scan=trueを削除し、アップロードを再試行できます。
Tunnel Uploadコマンドを使用してデータをアップロードすると、データは50ブロックに分割されます。 22番目のブロックのデータがアップロードされると、「アップロード失敗」というエラーメッセージが表示されます。 アップロード操作を再試行すると、23番目のブロックからアップロードが開始されます。 どうすればよいですか。
1つのブロックが1つのHTTPリクエストに対応します。 複数のブロックを同時にアップロードできます。 並列アップロード操作はアトミックです。 ブロックのデータアップロードは、他のブロックの同期要求が成功したかどうかにかかわらず、影響を受けません。
アップロードの再試行回数は限られています。 ブロック内のデータのアップロードの再試行回数が制限を超えた場合、システムは次のブロックをアップロードします。 データがアップロードされたら、select count(*) from table; ステートメントを実行して、データがないかどうかを確認できます。
ローカルサーバーによって1日に収集されるWebサイトログのサイズは10 GBです。 Tunnel Uploadコマンドを使用してこれらのログをMaxComputeにアップロードすると、アップロード速度は約300 KB/sです。 アップロード速度を上げるにはどうすればよいですか?
Tunnel uploadコマンドのアップロード速度は制限されていません。 アップロード速度は、ネットワーク帯域幅とサーバーのパフォーマンスによって異なります。 サーバーのパフォーマンスを向上させるために、パーティションまたはテーブルごとにデータをアップロードできます。 複数のECSインスタンスを使用してデータをアップロードすることもできます。
アップロードセッションのライフサイクルは1日です。 特大のテーブルをアップロードすると、セッションのタイムアウトによりアップロードタスクが失敗します。 どうすればよいですか。
アップロードタスクを2つのサブタスクに分割することを推奨します。
多数のアップロードセッションが存在するときにアップロードに時間がかかる場合はどうすればよいですか?
ビジネス要件に基づいて各ブロックのサイズを設定できます。 最大ブロックIDは20000である。 ビジネス要件に基づいてセッションライフサイクルを設定できます。 データは、セッションを送信した後にのみ表示できます。 セッションを5分以上の間隔で作成し、セッション内の各ブロックのサイズを64 MBを超える値に設定することを推奨します。
アップロードしたデータの最後の行に余分な \r記号が存在するのはなぜですか?
Windowsのラインフィードは \r\nで表され、macOSおよびLinuxのラインフィードは \nで表されます。 Tunnelコマンドは、オペレーティングシステムの改行をデフォルトの列区切り文字として使用します。 そのため、アップロードするファイルをWindowsで編集して保存する場合、macOSまたはLinuxでファイルをアップロードするときに、ファイルがアップロードされたテーブルに \rの記号が書き込まれます。
Tunnel uploadコマンドを使用してデータをアップロードするときに、列の区切り文字としてコンマ (,) が使用され、アップロードするフィールド値にコンマ (,) が含まれている場合はどうすればよいですか?
フィールド値にコンマ (,) が含まれている場合は、最初にデータファイルの区切り文字を変更し、-fdパラメーターを使用してTunnel Uploadコマンドで新しい区切り文字を指定できます。
アップロードするデータの列区切り文字としてスペースが使用されている場合、またはTunnel uploadコマンドを使用してデータをアップロードするときに正規表現に基づいてデータをフィルタリングする必要がある場合はどうすればよいですか?
Tunnel Uploadコマンドは正規表現をサポートしていません。 アップロードするデータの列区切り文字としてスペースが使用されている場合、または正規表現に基づいてデータをフィルタリングする必要がある場合は、MaxCompute UDFを使用できます。
次のサンプルソースデータでは、スペースが列区切り文字として使用され、ラインフィードが行区切り文字として使用されます。 取得するデータの一部は二重引用符 (") で囲まれており、ハイフン (-) などの一部のデータは除外する必要があります。 正規表現を使用してデータをアップロードできます。
10.21.17.2 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73477.html" 200 0 81615 81615 "-" "iphone" - HIT - - 0_0_0 001 - - - -
10.17.5.23 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73478.html" 206 0 49369 49369 "-" "huawei" - HIT - - 0_0_0 002 - - - -
10.24.7.16 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73479.html" 206 0 83821 83821 "-" "vivo" - HIT - - 0_0_0 003 - - - -手順:
アップロードするデータを格納する列を1つだけ含むテーブルを作成します。 サンプルコマンド:
create table userlog1(data string);ソースデータの列区切り文字として
\u0000を使用し、データをアップロードします。 このようにして、ソースデータは単一の行としてアップロードされます。 サンプルコマンド:tunnel upload C:\userlog.txt userlog1 -s false -fd "\u0000" -rd "\n";ソースデータをアップロードした後、MaxCompute Studioを使用してPython UDFまたはJava UDFを作成します。 Java UDFまたはPython UDFの作成方法と作成方法の詳細については、「UDFの開発」または「Python UDFの開発」をご参照ください。
次のサンプルUDFコードは、ParseAccessLogという名前のUDFが作成されることを示しています。
from odps.udf import annotate from odps.udf import BaseUDTF import re # The code of the regular expression function. regex = '([(\d\.)]+) \[(.*?)\] - "(.*?)" (\d+) (\d+) (\d+) (\d+) "-" "(.*?)" - (.*?) - - (.*?) (.*?) - - - -' # The regular expression that you want to use. # line -> ip,date,request,code,c1,c2,c3,ua,q1,q2,q3 @annotate('string -> string,string,string,string,string,string,string,string,string,string,string') # In this example, 11 strings are used. The number of strings must be the same as the columns of the source data. class ParseAccessLog(BaseUDTF): def process(self, line): try: t = re.match(regex, line).groups() self.forward(t[0], t[1], t[2], t[3], t[4], t[5], t[6], t[7], t[8], t[9], t[10]) except: passUDFを作成した後、UDFを使用して、userlog1テーブルにアップロードしたソースデータを処理できます。 列名が有効であることを確認する必要があります。 この例では、列名はデータです。 標準のSQL構文を使用して、処理されたデータを格納するテーブルを作成できます。 この例では、userlog2という名前のテーブルが作成されます。 サンプルコマンド:
create table userlog2 as select ParseAccessLog(data) as (ip,date,request,code,c1,c2,c3,ua,q1,q2,q3) from userlog1;データが処理された後、userlog2テーブルのデータを照会して、データが列に分割されているかどうかを確認できます。
select * from userlog2; -- The following result is returned: +----+------+---------+------+----+----+----+----+----+----+----+ | ip | date | request | code | c1 | c2 | c3 | ua | q1 | q2 | q3 | +----+------+---------+------+----+----+----+----+----+----+----+ | 10.21.17.2 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73477.html | 200 | 0 | 81615 | 81615 | iphone | HIT | 0_0_0 | 001 | | 10.17.5.23 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73478.html | 206 | 0 | 4936 | 4936 | huawei | HIT | 0_0_0 | 002 | | 10.24.7.16 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73479.html | 206 | 0 | 83821 | 83821 | vivo | HIT | 0_0_0 | 003 | +----+------+---------+------+----+----+----+----+----+----+----+
Tunnel Uploadコマンドを使用してデータをアップロードした後、ダーティデータが存在する場合はどうすればよいですか?
すべてのデータを一度に非パーティションテーブルまたはパーティションに書き込むことをお勧めします。 同じパーティションに複数回データを書き込むと、ダーティデータが生成される可能性があります。 tunnel show bad <sessionid>; コマンドをMaxComputeクライアントで実行して、ダーティデータを照会できます。 ダーティデータが見つかった場合は、次のいずれかの方法でダーティデータを削除できます。
を実行します。Execute the
ドロップテーブル...;ステートメントを使用して、テーブル全体を削除するか、alter table... 仕切りを落として下さい;文でパーティションを削除し、データを再度アップロードします。WHERE句を使用してダーティデータを除外できる場合は、INSERTステートメントをWHERE句とともに使用して、新しいテーブルにデータを挿入するか、データを挿入して、ソースパーティションまたはテーブルと同じ名前のターゲットパーティションまたはテーブルの既存のデータを上書きします。
GEOMETRY型のデータをMaxComputeに同期するにはどうすればよいですか?
MaxComputeは、GEOMETRYデータ型をサポートしていません。 GEOMETRY型のデータをMaxComputeに同期する場合は、GEOMETRY型のデータをSTRING型に変換する必要があります。
GEOMETRYは特殊なデータ型で、SQLの標準データ型とは異なります。 GEOMETRYは、Java Database Connectivity (JDBC) の一般的なフレームワークではサポートされていません。 したがって、GEOMETRYタイプのデータをインポートおよびエクスポートするために特別な処理が必要です。
Tunnel Downloadコマンドを使用してエクスポートできるファイルの形式はどれですか?
Tunnel Downloadコマンドを使用して、TXTまたはCSV形式のファイルのみをエクスポートできます。
Tunnel Downloadコマンドを使用してMaxComputeプロジェクトのリージョンでデータをダウンロードすると、課金されるのはなぜですか。
Tunnel Downloadコマンドを使用してMaxComputeプロジェクトのリージョンでデータをダウンロードする場合は、クラウド製品相互接続ネットワークのTunnelエンドポイントまたは仮想プライベートクラウド (VPC) のTunnelエンドポイントを設定する必要があります。 そうでなければ、データは他の領域にルーティングされ得る。 インターネット経由でデータをダウンロードすると課金されます。
Tunnel Downloadコマンドを使用してデータをダウンロードしたときにタイムアウトメッセージが表示された場合はどうすればよいですか?
ほとんどの場合、この問題は、設定したトンネルエンドポイントが無効なために発生します。 Tunnelエンドポイントが有効かどうかを確認するには、Telnetを使用してネットワーク接続をテストします。
Tunnel Downloadコマンドを使用してデータをダウンロードしたときに「You have NO privilege」というエラーメッセージが表示された場合はどうすればよいですか?
問題の説明
Tunnel Downloadコマンドを使用してデータをダウンロードすると、次のエラーメッセージが表示されます。
You have NO privilege 'odps:Select' on {acs:odps:*:projects/XXX/tables/XXX}. project 'XXX' is protected.原因
MaxComputeプロジェクトのデータ保護機能が有効になっています。
解決策
プロジェクトの所有者のみが、プロジェクトから別のプロジェクトにデータをエクスポートできます。
Tunnelを使用して指定されたデータをダウンロードする方法?
Tunnelは、データコンピューティングまたはフィルタリングをサポートしていません。 データを計算またはフィルタリングするには、次のいずれかの方法を使用できます。
SQLジョブを実行して、ダウンロードするデータを一時テーブルとして保存します。 データをダウンロードした後、一時テーブルを削除します。
少量のデータをダウンロードする場合は、データをダウンロードする必要なく、SQL文を実行して必要なデータを照会できます。
過去のTunnelコマンドに関する情報はどのくらい保存できますか?
情報ストレージは、ストレージ期間とは関係ありません。 デフォルトでは、最大500のデータレコードを保存できます。
Tunnelを使用してデータをアップロードする方法?
Tunnelを使用してデータをアップロードするには、次の手順を実行します。
ソースファイルやソーステーブルなどのソースデータを準備します。
テーブルスキーマを設計し、パーティション定義を指定し、データ型を変換してから、MaxComputeクライアントでテーブルを作成します。
MaxComputeテーブルにパーティションを追加します。 テーブルがパーティション分割されていないテーブルの場合は、この手順をスキップします。
指定したパーティションまたはテーブルにデータをアップロードします。
Tunnelディレクトリの名前には漢字を含めることができますか?
はい、Tunnelディレクトリの名前には漢字を使用できます。
Tunnelコマンドで区切り文字を使用するときに注意する必要があるポイントは何ですか?
Tunnelコマンドで区切り文字を使用する場合は、次の点に注意してください。
-rdパラメーターは行の区切り文字を指定し、-fdパラメーターは列の区切り文字を指定します。-fdパラメーターで指定された列の区切り文字には、-rdパラメーターで指定された行の区切り文字を含めることはできません。Windowsでは、Tunnelコマンドのデフォルトの区切り文字は
\r\nです。 Linuxでは、Tunnelコマンドのデフォルトの区切り文字は\nです。データのアップロードを開始すると、アップロード操作で使用される行区切り文字を表示および確認できます。 この機能は、MaxComputeクライアントV0.21.0以降でサポートされています。
Tunnelファイルパスにスペースを含めることができますか?
はい、Tunnelファイルパスにはスペースを含めることができます。 Tunnelファイルパスにスペースが含まれている場合は、Tunnelコマンドでパスを二重引用符 (") で囲む必要があります。
トンネルは非暗号化データベースファイルをサポートします。dbf拡張子?
Tunnelはテキストファイルのみをサポートします。 バイナリファイルはサポートされていません。
Tunnelのアップロードとダウンロードに有効な速度範囲は?
トンネルのアップロードとダウンロードは、ネットワークステータスの影響を受けます。 ネットワークステータスが正常の場合、アップロード速度は1メガバイト/秒から20メガバイト/秒です。
パブリックトンネルエンドポイントを取得する方法?
パブリックトンネルエンドポイントは、リージョンとネットワークによって異なります。 パブリックトンネルエンドポイントの詳細については、「エンドポイント」をご参照ください。
Tunnelコマンドを使用してデータのアップロードまたはダウンロードに失敗した場合はどうすればよいですか?
のodps_config.iniファイルからTunnelエンドポイントを取得します。. .\odpscmd_public\confディレクトリに移動します。 MaxComputeクライアントのCLIで、curl -iコマンドなどのcurl -i Endpoint http://dt.odps.aliyun.com を実行して、ネットワーク接続をテストします。 ネットワーク接続が異常な場合は、ネットワークの状態を確認するか、有効なトンネルエンドポイントを使用してください。
Tunnelコマンドを実行したときに「JavaヒープスペースFAILED」エラーメッセージが表示された場合はどうすればよいですか?
問題の説明
Tunnelコマンドを使用してデータをアップロードまたはダウンロードすると、次のエラーメッセージが表示されます。
Java heap space FAILED: error occurred while running tunnel command原因
原因1: アップロードする1行のデータのサイズが大きすぎます。
原因2: ダウンロードするデータの量が多すぎて、MaxComputeクライアントのメモリが不足しています。
解決策
原因1の解決策:
使用した区切り文字が有効かどうかを確認します。 区切り文字が無効な場合、すべてのデータレコードが単一の行としてアップロードされ、行のサイズが大きくなりすぎます。
使用した区切り文字が有効で、1行のサイズが大きい場合、クライアントのメモリが不足しています。 MaxComputeクライアントプロセスの起動パラメーターを調整する必要があります。 クライアントインストールディレクトリ
binのodpscmdスクリプトファイルで、java -Xms64m -Xmx512m -classpath "${clt_dir}/lib/* :${ clt_dir}/conf/" com.aliyun.openservices.odps.console "@ based" コンソールの "$.
原因2の解決策: クライアントのインストールディレクトリにあるodpscmdスクリプトファイル
ビンの値を増やします。-Xms64mおよび-Xmx512mでjava -Xms64m -Xmx512m -classpath "${clt_dir}/lib/* :${ clt_dir}/conf/" com.aliyun.openservices.odps.console.ODPSConsole "$@"ビジネス要件に基づいて。
セッションにはライフサイクルがありますか? セッションのライフサイクルがタイムアウトした場合はどうすればよいですか?
はい。サーバー上の各セッションのライフサイクルは24時間です。 セッションの作成後にライフサイクルが開始されます。 セッションのライフサイクルがタイムアウトすると、セッションは使用できません。 この場合、データを書き換えるためにセッションを再作成する必要があります。
複数のプロセスまたはスレッドが同じセッションを共有できますか?
はい、複数のプロセスまたはスレッドが同じセッションを共有できます。 ただし、各ブロックIDが一意であることを確認する必要があります。
トンネルのルーティング機能は何ですか?
Tunnelエンドポイントを設定しない場合、トラフィックはMaxComputeが存在するネットワークのTunnelエンドポイントに自動的にルーティングされます。 Tunnelエンドポイントを設定すると、トラフィックは指定されたエンドポイントにルーティングされ、自動ルーティングは実行されません。
Tunnelは並列アップロードとダウンロード操作をサポートしていますか?
はい、トンネルは並行アップロードおよびダウンロード操作をサポートします。 次のコマンドの例を示します。
tunnel upload E:/1.txt tmp_table_0713 --threads 5;