MaxComputeの組み込み関数がビジネス要件を満たせない場合は、IntelliJ IDEA (Maven) やMaxCompute Studioなどの開発ツールを使用して、このトピックの手順に従ってユーザー定義関数 (UDF) を作成し、MaxComputeでUDFを呼び出します。 このトピックでは、JavaでUDFを記述する方法について説明します。
制限事項
UDFを使用したインターネットへのアクセス
デフォルトでは、MaxComputeではUDFを使用してインターネットにアクセスすることはできません。 UDFを使用してインターネットにアクセスする場合は、ネットワーク接続申請フォームに入力してください。
ビジネス要件に基づいて、アプリケーションを送信します。 申請が承認された後、MaxComputeテクニカルサポートチームがお客様に連絡し、ネットワーク接続の確立を支援します。 ネットワーク接続申請フォームへの記入方法の詳細については、「ネットワーク接続プロセス」をご参照ください。
UDFを使用したVPCへのアクセス
デフォルトでは、MaxComputeではUDFを使用してVPCのリソースにアクセスすることはできません。 UDFを使用してVPC内のリソースにアクセスするには、MaxComputeとVPCの間にネットワーク接続を確立する必要があります。 関連する操作の詳細については、「UDFを使用したVPCのリソースへのアクセス」をご参照ください。
UDF、UDAF、またはUDTFを使用したテーブルデータの読み取り
UDF、UDAF、またはUDTFを使用して、次の種類のテーブルからデータを読み取ることはできません。
スキーマの進化を行うテーブル
複雑なデータ型を含むテーブル
JSONデータ型を含むテーブル
取引テーブル
注意事項
Java UDFを作成する前に、UDFコード構造と、Java UDFで使用されるデータ型とMaxComputeでサポートされるデータ型の間のマッピングを理解する必要があります。 データ型のマッピングの詳細については、「付録: データ型」をご参照ください。
Java UDFを作成する前に、次の点に注意してください。
異なるUDFのJARファイルには、同じ名前で異なるロジックを持つクラスを含まないことをお勧めします。 たとえば、UDF1のJARファイルの名前はudf1.jar、UDF2のJARファイルの名前はudf2.jarです。 どちらのファイルにも
com.aliyun.UserFunction.classという名前のクラスが含まれていますが、ファイル内のロジックが異なります。 UDF1とUDF2が同じSQL文で呼び出された場合、MaxComputeは2つのファイルのいずれかからcom.aliyun.UserFunction.classを読み込みます。 その結果、UDFは期待どおりに実行できず、コンパイルエラーが発生する可能性があります。Java UDFの入力パラメーターまたは戻り値のデータ型はオブジェクトです。 文字列など、これらのデータ型の最初の文字は大文字にする必要があります。
MaxCompute SQLのNULL値は、JavaではNULLで表されます。 MaxCompute SQLでは、Javaのプリミティブデータ型はNULL値を表すことができません。 したがって、これらのデータ型は使用できません。
UDF開発プロセス
UDFを開発するときは、準備を行い、UDFコードを記述し、Pythonプログラムをアップロードし、UDFを作成し、UDFをデバッグする必要があります。 MaxComputeでは、MaxCompute Studio、DataWorks、MaxComputeクライアント (odpscmd) など、複数のツールを使用してUDFを開発できます。 このセクションでは、MaxCompute Studio、DataWorks、およびMaxComputeクライアント (odpscmd) を使用してUDFを開発する方法の例を示します。
MaxCompute Studioの使用
この例では、MaxCompute Studioを使用して、すべての文字を小文字に変換するために使用されるJava UDFを開発して呼び出す方法を示します。
準備をします。
MaxCompute Studioを使用してUDFを開発およびデバッグする前に、MaxCompute Studioをインストールし、MaxCompute StudioをMaxComputeプロジェクトに接続する必要があります。 MaxCompute Studioをインストールし、MaxCompute StudioをMaxComputeプロジェクトに接続する方法の詳細については、以下のトピックを参照してください。
UDFコードを記述します。
[Project] タブの左側のナビゲーションウィンドウで、 を選択し、[java] を右クリックして、 を選択します。
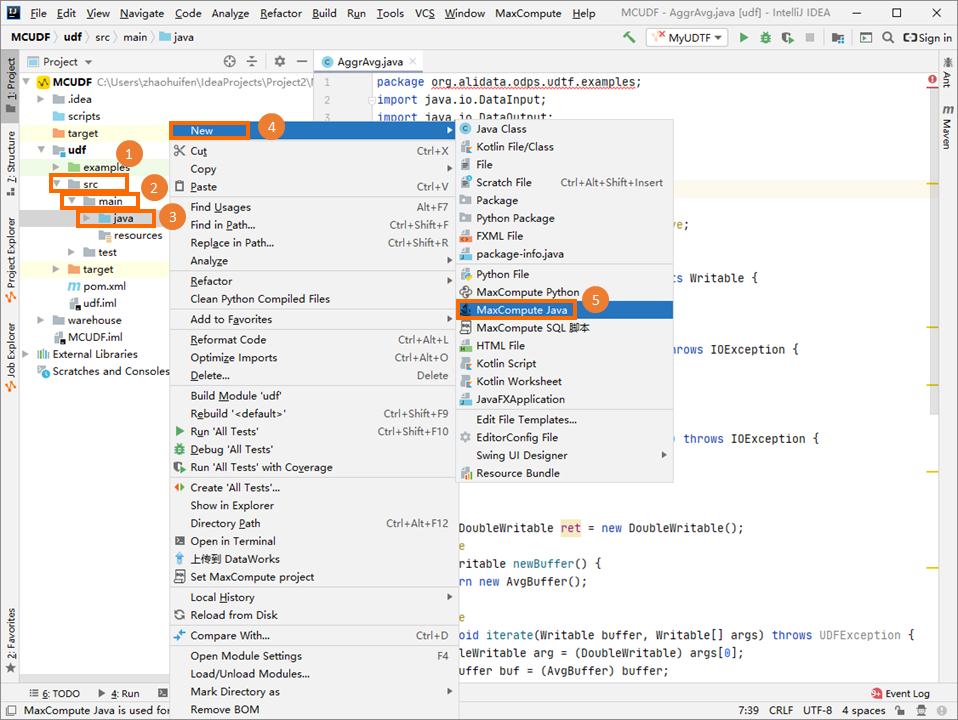
[新しいMaxCompute javaクラスの作成] ダイアログボックスで、[UDF] をクリックし、[名前] フィールドにクラス名を入力して、enterキーを押します。
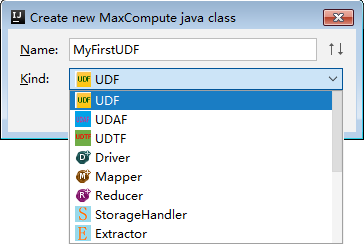
Name: MaxCompute Javaクラスの名前。 パッケージが作成されていない場合は、パッケージ名. クラス名形式で名前を入力します。 システムは、この形式で名前が付けられたパッケージを自動的に作成します。 この例では、クラスの名前はLowerです。
コードエディターでUDFコードを記述します。
 サンプルコード:
サンプルコード: package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }説明必要に応じて、オンプレミスマシンでJava UDFをデバッグできます。 詳細については、「UDFの開発とデバッグ」をご参照ください。
JARファイルをアップロードし、UDFを作成します。
UDFのJARファイルを右クリックし、サーバーにデプロイ.... [jarのパッケージ化、リソースの送信、機能の登録] ダイアログボックスで、パラメーターを設定し、[OK] をクリックします。

MaxComputeプロジェクト: UDFが属するMaxComputeプロジェクトの名前。 デフォルト値を保持します。これは、UDFの書き込み時にMaxComputeプロジェクトへの接続が確立されることを示します。
リソースファイル: UDFが依存するリソースファイルのパス。 デフォルト値を保持します。
リソース名: UDFが依存するリソースの名前。 デフォルト値を保持します。
関数名: 作成するUDFの名前。 この名前は、UDFを呼び出すために使用されるSQL文で使用されます。 例: Lower_test
UDF をデバッグします。
左側のナビゲーションウィンドウで、[プロジェクト調査] タブをクリックします。 UDFが属するMaxComputeプロジェクトを右クリックし、[コンソールを開く] を選択し、UDFの呼び出しに使用するSQL文を入力し、enterキーを押してSQL文を実行します。
 サンプル文:
サンプル文: select lower_test('ABC');次の応答が返されます。
+-----+ | _c0 | +-----+ | abc | +-----+
DataWorksの使用
準備をします。
DataWorksを使用してUDFを開発およびデバッグする前に、DataWorksを有効化し、DataWorksワークスペースをMaxComputeプロジェクトに関連付ける必要があります。 詳細は、「DataWorks」をご参照ください。
UDFコードを記述します。
Java開発ツールを使用してUDFコードを記述し、そのコードをJARファイルとしてパッケージ化することができます。 サンプルUDFコード:
package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }JARファイルをアップロードし、UDFを作成します。
DataWorksコンソールでパッケージ化したコードパッケージをアップロードし、UDFを作成できます。 詳細については、以下のトピックをご参照ください。
UDF をデバッグします。
UDFを作成した後、DataWorksコンソールでODPS SQLノードを作成できます。 ODPS SQLノードでSQL文を記述して作成し、UDFを呼び出してデバッグすることができます。 ODPS SQLノードの作成方法の詳細については、「ODPS SQLノードの作成」をご参照ください。 例:
select lower_test('ABC');
MaxComputeクライアント (odpscmd) の使用
準備をします。
MaxComputeクライアントを使用してUDFを開発およびデバッグする前に、MaxComputeクライアントインストールパッケージ (GitHub) をダウンロードし、MaxComputeクライアントをインストールしてから、MaxComputeプロジェクトに接続するように設定ファイルを設定する必要があります。 詳細については、「MaxComputeクライアント (odpscmd) 」をご参照ください。
UDFコードを記述します。
Java開発ツールを使用してUDFコードを記述し、そのコードをJARファイルとしてパッケージ化することができます。 サンプルUDFコード:
package com.aliyun.odps.udf.example; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }JARファイルをアップロードし、UDFを作成します。
パッケージ化したJARファイルをMaxComputeクライアントにアップロードし、UDFを作成できます。 詳細については、以下のトピックをご参照ください。
UDF をデバッグします。
UDFを作成した後、SQL文を作成してUDFをデバッグできます。 例:
select lower_test('ABC');
使用上の注意
Java UDFを開発したら、MaxCompute SQLを使用してUDFを呼び出すことができます。 Java UDFの開発方法の詳細については、「概要」をご参照ください。 次のいずれかの方法を使用してJava UDFを呼び出すことができます。
MaxComputeプロジェクトでUDFを使用する: この方法は、組み込み関数を使用する方法と似ています。
プロジェクト間でUDFを使用する: プロジェクトaでプロジェクトBのUDFを使用します。次のステートメントは、例を示します。
select B:udf_in_other_project(arg0, arg1) as res from table_t;プロジェクト間共有の詳細については、「パッケージに基づくプロジェクト間リソースアクセス」をご参照ください。
UDF開発例
付録: UDFコード構造
UDFコードはJavaで記述できます。 コードには次の情報が含まれている必要があります。
Javaパッケージ: オプション。
定義されているJavaクラスは、今後使用するためにJARファイルにパッケージ化できます。
基本UDFクラス: 必須。
必要なUDFクラスは
com.aliyun.odps.udf.UDFです。 他のUDFクラスまたは複合データ型を使用する場合は、[概要] の手順に従って必要なクラスを追加します。 たとえば、STRUCTデータ型に対応するUDFクラスは、com.aliyun.odps.data.Structです。@ Resolveアノテーション: オプション。アノテーションは
@ Resolve(<signature>)形式です。signatureパラメーターは、UDFの入力パラメーターと戻り値のデータ型を定義するために使用されます。 UDFでSTRUCTデータ型のデータを使用する場合、com.aliyun.odps.data.Structクラスのリフレクション機能を使用してフィールドの名前と型を取得することはできません。 この場合、com.aliyun.odps.data.Structクラスに@ Resolveアノテーションを追加する必要があります。 このアノテーションは、入力パラメーターまたは戻り値にcom.aliyun.odps.data.Structクラスが含まれるUDFのオーバーロードにのみ影響します。 例:@ Resolve("struct<a:string>,string->string")Java UDFで複雑なデータ型を使用する方法の詳細については、「Java UDFで複雑なデータ型を使用する」をご参照ください。カスタムJavaクラス: 必須。
カスタムJavaクラスは、UDFコードの組織単位です。 このクラスは、ビジネス要件を満たすために使用される変数とメソッドを定義します。
メソッド
を評価する: 必須。evaluateメソッドは非静的パブリックメソッドであり、カスタムJavaクラスに含まれています。
evaluateメソッドの入力パラメーターと戻り値のデータ型は、SQL文のUDFの関数シグネチャとして使用されます。 関数シグネチャは、UDFの入力パラメータおよび戻り値のデータ型を定義する。UDFに複数の
evaluateメソッドを実装できます。 UDFを呼び出すと、MaxComputeはUDFの入力パラメーターのデータ型に基づいてevaluateメソッドを照合します。Java UDFを作成するときは、Javaデータ型またはJava書き込み可能データ型を使用できます。 MaxComputeプロジェクトでサポートされているデータ型、Javaデータ型、およびJava書き込み可能データ型間のマッピングの詳細については、「付録: データ型」をご参照ください。
UDF初期化または終了コード: オプション。
void setup(ExecutionContext ctx)メソッドを使用してUDFを初期化し、void close()メソッドを使用してUDFを終了できます。void setup(ExecutionContext ctx)メソッドは、evaluateメソッドの前に呼び出されます。 void setup(ExecutionContext ctx) メソッドは1回だけ呼び出され、データコンピューティングに必要なリソースを初期化したり、クラスのメンバーを初期化したりするために使用されます。void close()メソッドは、evaluateメソッドの後に呼び出されます。 void close() メソッドは、ファイルを閉じるなど、データをクリーンアップするために使用されます。
サンプルコード:
Javaデータ型の使用
// Package the defined Java classes into a file named org.alidata.odps.udf.examples. package org.alidata.odps.udf.examples; // Inherit the UDF class. import com.aliyun.odps.udf.UDF; // The custom Java class. public final class Lower extends UDF { // The evaluate method. String indicates the data types of the input parameters and return indicates the return value. public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }Java書き込み可能データ型の使用
// Package the defined Java classes into a file named com.aliyun.odps.udf.example. package com.aliyun.odps.udf.example; // Add the class that corresponds to a Java writable data type. import com.aliyun.odps.io.Text; // Inherit the UDF class. import com.aliyun.odps.udf.UDF; // The custom Java class. public class MyConcat extends UDF { private Text ret = new Text(); // The evaluate method. Text indicates the data types of the input parameters and return indicates the return value. public Text evaluate(Text a, Text b) { if (a == null || b == null) { return null; } ret.clear(); ret.append(a.getBytes(), 0, a.getLength()); ret.append(b.getBytes(), 0, b.getLength()); return ret; } }
MaxComputeでは、HiveバージョンがMaxComputeと互換性のあるHive UDFを使用することもできます。 詳細については、「Hive UDF」をご参照ください。
付録: データ型
データ型マッピング
次の表に、MaxComputeプロジェクトでサポートされているデータ型、Javaデータ型、およびJava書き込み可能データ型の間のマッピングを示します。 データ型の一貫性を確保するには、マッピングに基づいてJava UDFを記述する必要があります。 次の表に、データ型のマッピングについて説明します。
MaxComputeでは、異なるデータ型エディションが異なるデータ型をサポートします。 MaxCompute V2.0以降では、ARRAY、MAP、STRUCTなど、より多くのデータ型と複雑なデータ型がサポートされています。 MaxComputeデータ型のエディションの詳細については、「データ型のエディション」をご参照ください。
MaxComputeタイプ | Javaタイプ | Java書き込み可能タイプ |
TINYINT | java.lang.Byte | ByteWritable |
SMALLINT | java.lang.Short | ShortWritable |
INT | java.lang.Integer | IntWritable |
BIGINT | java.lang.Long | LongWritable |
FLOAT | java.lang.Float | FloatWritable |
DOUBLE | java.lang.Double | DoubleWritable |
DECIMAL | java.math.BigDecimal | BigDecimalWritable |
BOOLEAN | java.lang.Boolean | BooleanWritable |
STRING | java.lang.String | Text |
VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
BINARY | com.aliyun.odps.data.Binary | BytesWritable |
DATE | java.sql.Date | DateWritable |
DATETIME | java.util.Date | DatetimeWritable |
TIMESTAMP | java.sql.Timestamp | TimestampWritable |
INTERVAL_YEAR_MONTH | 非該当 | IntervalYearMonthWritable |
INTERVAL_DAY_TIME | 非該当 | IntervalDayTimeWritable |
ARRAY | java.util.List | 非該当 |
MAP | java.util.Map | 非該当 |
STRUCT | com.aliyun.odps.data.Struct | 非該当 |
Hive UDF
MaxComputeプロジェクトがMaxCompute V2.0データ型エディションを使用し、Hive UDFをサポートしている場合は、HiveバージョンがMaxComputeと互換性のあるHive UDFを直接使用できます。
MaxComputeと互換性のあるHiveバージョンは2.1.0で、Hadoop 2.7.2に対応します。 UDFが別のHiveまたはHadoopバージョンで開発されている場合は、Hive 2.1.0またはHadoop 2.7.2を使用してUDFのJARファイルを再コンパイルする必要があります。
MaxComputeでHive UDFを使用する方法の詳細については、「JavaでHive UDFを記述する」をご参照ください。