MaxCompute (旧称ODPS) は、大規模なデータウェアハウジング用の高速で完全マネージド型のコンピューティングプラットフォームです。 MaxComputeはエクサバイト単位のデータを処理できます。 このトピックでは、data Transmission Service (DTS) を使用して、ApsaraDB RDS for MySQLインスタンスからMaxComputeプロジェクトにデータを同期する方法について説明します。
前提条件
以下の操作が実行されます。
制限事項
DTSは、最初の完全データ同期中に、ソースRDSインスタンスとターゲットRDSインスタンスの読み取りおよび書き込みリソースを使用します。 これにより、RDSインスタンスの負荷が増加する可能性があります。 インスタンスのパフォーマンスが悪い場合、仕様が低い場合、またはデータ量が多い場合、データベースサービスが利用できなくなる可能性があります。 たとえば、ソースRDSインスタンスで多数の低速SQLクエリが実行されている場合、テーブルにプライマリキーがない場合、またはターゲットRDSインスタンスでデッドロックが発生する場合、DTSは大量の読み取りおよび書き込みリソースを占有します。 データ同期の前に、ソースRDSインスタンスとターゲットRDSインスタンスのパフォーマンスに対するデータ同期の影響を評価します。 オフピーク時にデータを同期することを推奨します。 たとえば、ソースRDSインスタンスとターゲットRDSインスタンスのCPU使用率が30% 未満の場合にデータを同期できます。
同期するオブジェクトとして選択できるのはテーブルのみです。
データ同期中にオブジェクトに対してDDL操作を実行するために、gh-ostやpt-online-schema-changeなどのツールを使用しないことをお勧めします。 そうしないと、データ同期が失敗する可能性があります。
MaxComputeはPRIMARY KEY制約をサポートしていません。 ネットワークエラーが発生した場合、DTSは重複するデータレコードをMaxComputeに同期する可能性があります。
課金
同期タイプ | タスク設定料金 |
スキーマ同期と完全データ同期 | 無料です。 |
増分データ同期 | 有料。 詳細については、「課金の概要」をご参照ください。 |
サポートされているソースデータベースタイプ
DTSを使用して、次のタイプのMySQLデータベースのデータを同期できます。
Elastic Compute Service (ECS) でホストされる自己管理型データベース
Express Connect、VPN Gateway、またはSmart Access Gatewayを介して接続された自己管理型データベース
database Gateway経由で接続された自己管理型データベース
MaxComputeプロジェクトと同じAlibaba Cloudアカウント、またはMaxComputeプロジェクトとは異なるAlibaba Cloudアカウントが所有するApsaraDB RDS for MySQLインスタンス
この例では、ApsaraDB RDS for MySQLインスタンスを使用して、データ同期タスクの設定方法を説明します。 手順に従って、他のタイプのMySQLデータベースのデータ同期タスクを設定することもできます。
ソースデータベースが自己管理型MySQLデータベースの場合、ソースデータベースのネットワーク環境をデプロイする必要があります。 詳細については、「準備の概要」をご参照ください。
同期可能なSQL操作
DDL操作: ALTER TABLE ADD COLUMN。
DML操作: INSERT、UPDATE、およびDELETE
同期プロセス
初期スキーマ同期。
DTSは、ソースデータベースからMaxComputeに必要なオブジェクトのスキーマを同期します。 初期スキーマ同期中に、DTSはソーステーブル名の末尾に_baseサフィックスを追加します。 たとえば、ソーステーブルの名前がcustomerの場合、MaxComputeのテーブルの名前はcustomer_baseです。
初期の完全データ同期。
DTSは、ソースデータベースのテーブルの履歴データをMaxComputeのターゲットテーブルに同期します。 たとえば、ソースデータベースの顧客テーブルは、MaxComputeのcustomer_baseテーブルに同期されます。 データは、その後の増分同期の基礎となる。
説明_baseで接尾辞が付けられた宛先テーブルは、フルベースラインテーブルと呼ばれます。
増分データ同期。
DTSは、MaxComputeに増分データテーブルを作成します。 増分データテーブルの名前には、customer_logなどの_logが付いています。 次に、DTSは、ソースデータベースで生成された増分データを増分データテーブルに同期します。
説明詳細については、「増分データテーブルのスキーマ」をご参照ください。
手順
同期アカウントを承認できるようにするには、Alibaba Cloudアカウントを使用して次の手順を実行することを推奨します。
データ同期インスタンスを購入します。 詳細については、「DTSインスタンスの購入」をご参照ください。
説明購入ページで、Source InstanceパラメーターをMySQLに設定し、Destination InstanceパラメーターをMaxComputeに設定し、同期トポロジパラメーターを一方向同期に設定します。
DTSコンソールにログインします。
説明Data Management (DMS) コンソールにリダイレクトされている場合は、右下隅にある
 アイコンをクリックして、以前のバージョンのDTSコンソールに移動します。
アイコンをクリックして、以前のバージョンのDTSコンソールに移動します。左側のナビゲーションウィンドウで、[データ同期] をクリックします。
[データ同期タスク] ページの上部で、ターゲットインスタンスが存在するリージョンを選択します。
データ同期インスタンスを見つけ、[操作] 列の [タスクの設定] をクリックします。
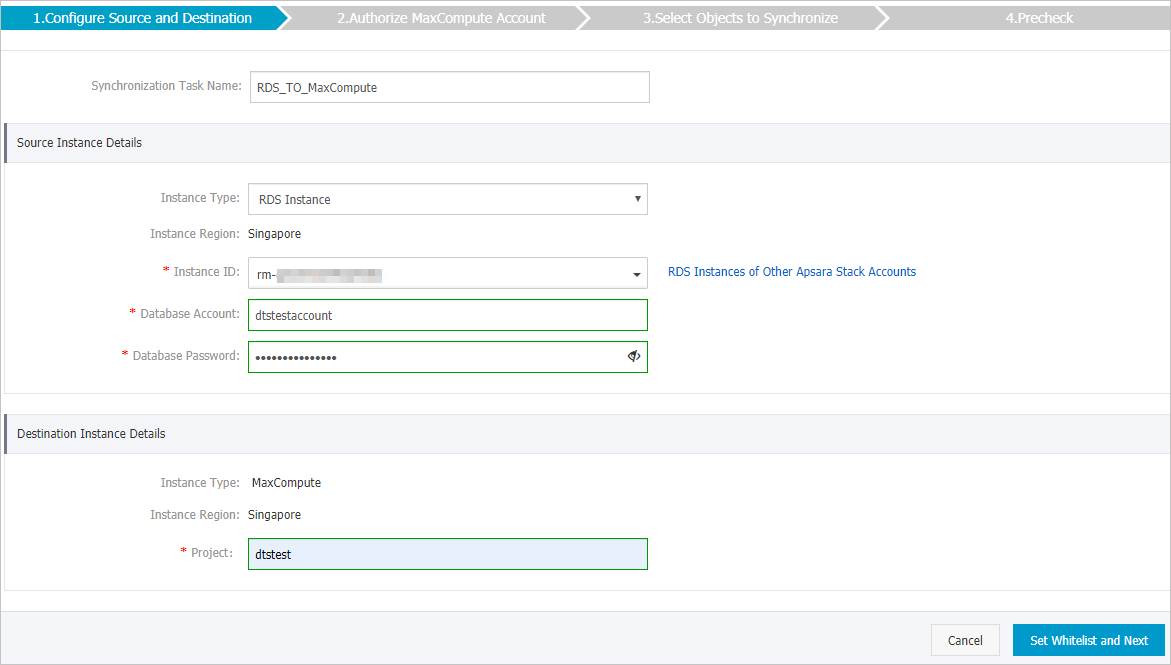
ソースインスタンスとターゲットインスタンスを設定します。
セクション
パラメーター
説明
N/A
同期タスク名
DTSが生成するタスク名。 わかりやすい名前を指定することをお勧めします。 一意のタスク名を使用する必要はありません。
ソースインスタンスの詳細
インスタンスタイプ
ソースインスタンスのインスタンスタイプ。 RDS インスタンスを選択します。
インスタンスリージョン
購入ページで選択したソースリージョン。 このパラメーターの値は変更できません。
Instance ID
ソースApsaraDB RDS for MySQLインスタンスのID。
データベースアカウント
ソースApsaraDB RDS for MySQLインスタンスのデータベースアカウント。
説明ソースApsaraDB RDS for MySQLインスタンスのデータベースエンジンの場合。 MySQL 5.5またはMySQL 5.6の場合、データベースアカウントおよびデータベースパスワードパラメーターを設定する必要はありません。
データベースパスワード
データベースアカウントのパスワードを設定します。
暗号化
ソースインスタンスへの接続を暗号化するかどうかを指定します。 ビジネスとセキュリティの要件に基づいて、[非暗号化] または [SSL暗号化] を選択します。 SSL暗号化を選択した場合、データ同期タスクを設定する前に、ApsaraDB RDS for MySQLインスタンスのSSL暗号化を有効にする必要があります。 詳細については、次をご参照ください:ApsaraDB RDS for MySQLインスタンスのSSL暗号化の設定
重要Encryptionパラメーターは、中国本土および中国 (香港) リージョン内でのみ使用できます。
ターゲットインスタンスの詳細
インスタンスタイプ
ターゲットインスタンスのインスタンスタイプ。 このパラメーターはMaxComputeに設定されており、変更できません。
インスタンスリージョン
購入ページで選択したターゲットリージョン。 このパラメーターの値は変更できません。
プロジェクト
MaxCompute プロジェクトの名前を設定します。 プロジェクトの名前を表示するには、DataWorksコンソールにログインし、左側のナビゲーションウィンドウでCompute Engines > MaxComputeを選択します。 [プロジェクト] ページでプロジェクトの名前を確認できます。

ページの右下隅にある [ホワイトリストと次への設定] をクリックします。
説明ApsaraDBインスタンス (ApsaraDB RDS for MySQLおよびApsaraDB for MongoDBインスタンスなど) およびECSでホストされている自己管理型データベースのセキュリティ設定を変更する必要はありません。 DTSは、DTSサーバーのCIDRブロックをApsaraDBインスタンスのIPホワイトリストまたはECSインスタンスのセキュリティルールに自動的に追加します。 詳細については、「DTSサーバーのCIDRブロックをオンプレミスデータベースのセキュリティ設定に追加する」をご参照ください。
ページの右下隅にある [次へ] をクリックします。 このステップでは、MaxComputeプロジェクトに対する権限が同期アカウントに付与されます。
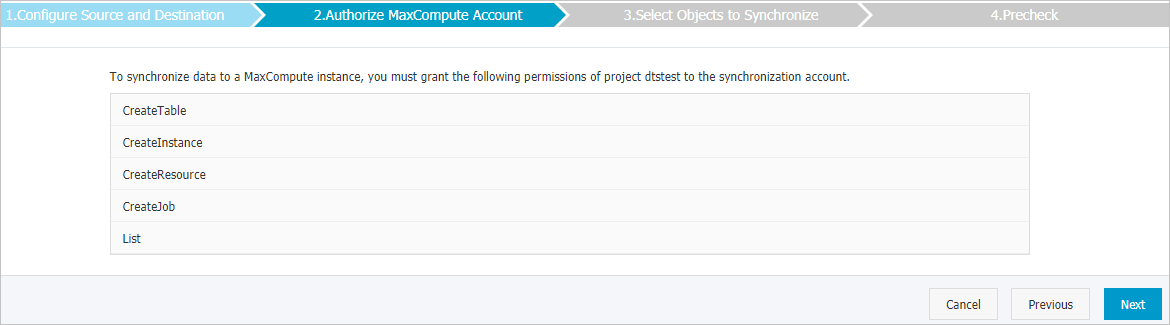
同期ポリシーと同期するオブジェクトを選択します。
パラメータまたは設定
説明
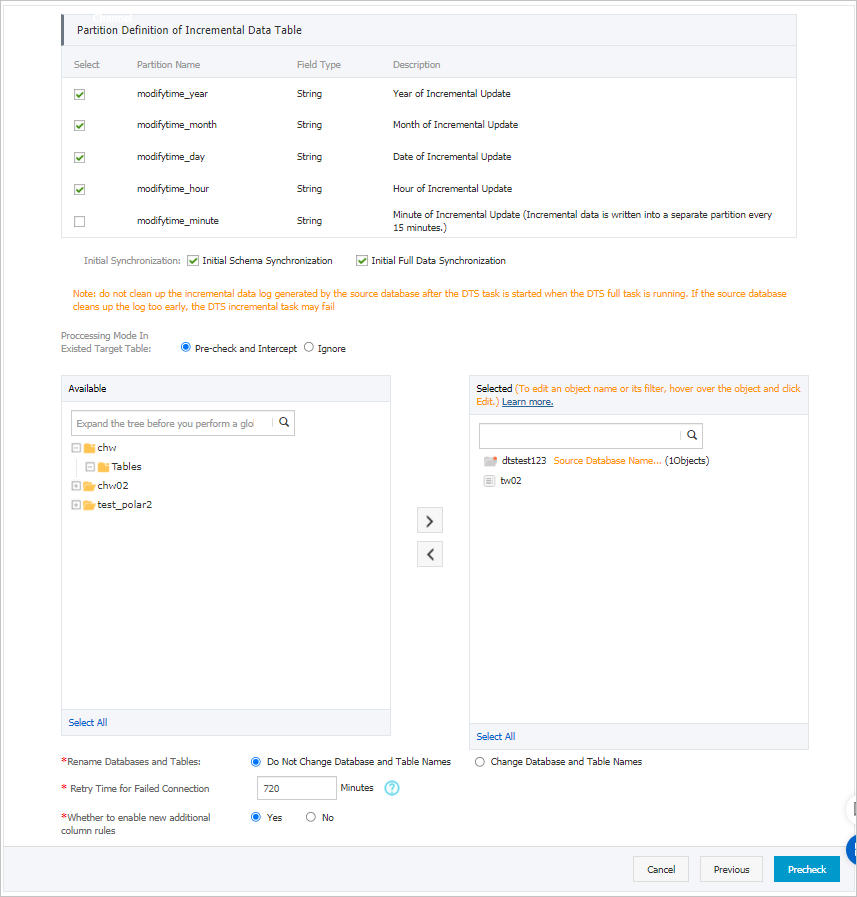
増分データテーブルのパーティション定義
ビジネス要件に基づいてパーティション名を選択します。 パーティションの詳細については、「 パーティション」をご参照ください。
同期の初期化
同期初期化には、スキーマ同期初期化と完全データ同期初期化があります。
[初期スキーマ同期] と [初期フルデータ同期] の両方を選択します。 この場合、DTSは必要なオブジェクトのスキーマと履歴データを同期し、増分データを同期します。
存在するターゲットテーブルの処理モード
事前チェックとインターセプト: ターゲットデータベースに、ソースデータベースのテーブルと同じ名前のテーブルが含まれているかどうかを確認します。 ソースデータベースとターゲットデータベースに同じテーブル名が含まれていない場合は、事前チェックが渡されます。 それ以外の場合、事前チェック中にエラーが返され、データ同期タスクを開始できません。
説明オブジェクト名マッピング機能を使用して、ターゲットデータベースに同期されるテーブルの名前を変更できます。 この機能は、ソースデータベースとターゲットデータベースに同じテーブル名が含まれていて、ターゲットデータベースのテーブルを削除または名前変更できない場合に使用できます。 詳細については、「同期するオブジェクトの名前変更」をご参照ください。
無視: ソースデータベースとターゲットデータベースで同じテーブル名の事前チェックをスキップします。
警告無視を選択すると、データの一貫性が保証されず、ビジネスが潜在的なリスクにさらされる可能性があります。
初期データ同期中、DTSはターゲットデータベースのデータレコードと同じ主キーを持つデータレコードを同期しません。 これは、ソースデータベースとターゲットデータベースが同じスキーマを持つ場合に発生します。 ただし、DTSは増分データ同期中にこれらのデータレコードを同期します。
ソースデータベースとターゲットデータベースのスキーマが異なる場合、初期データ同期が失敗する可能性があります。 この場合、一部の列のみが同期されるか、データ同期タスクが失敗します。
同期するオブジェクトの選択
[使用可能] セクションから1つ以上のテーブルを選択し、
 アイコンをクリックしてテーブルを [選択済み] セクションに移動します。 説明
アイコンをクリックしてテーブルを [選択済み] セクションに移動します。 説明同期するオブジェクトとして、複数のデータベースからテーブルを選択できます。
既定では、オブジェクトがターゲットデータベースに同期された後、オブジェクトの名前は変更されません。 オブジェクト名マッピング機能を使用して、ターゲットデータベースに同期されるオブジェクトの名前を変更できます。 詳細については、「同期するオブジェクトの名前変更」をご参照ください。
追加の列の新しい命名規則を有効にするかどうか
DTSがMaxComputeにデータを同期した後、DTSは宛先テーブルに追加の列を追加します。 追加の列の名前がターゲットテーブルの既存の列の名前と同じである場合、データ同期は失敗します。 [はい] または [いいえ] を選択して、追加の列の新しい命名規則を有効にするかどうかを指定します。
警告このパラメーターを指定する前に、宛先テーブルの追加の列と既存の列に名前の競合があるかどうかを確認してください。 詳細については、「追加列の命名規則」をご参照ください。
データベースとテーブルの名前変更
オブジェクト名マッピング機能を使用して、ターゲットインスタンスに同期されるオブジェクトの名前を変更できます。 詳細は、オブジェクト名のマッピングをご参照ください。
DMSがDDL操作を実行するときの一時テーブルのレプリケート
Data Management (DMS) を使用してソースデータベースでオンラインDDL操作を実行する場合、オンラインDDL操作によって生成された一時テーブルを同期するかどうかを指定できます。
Yes: DTSは、オンラインDDL操作によって生成された一時テーブルのデータを同期します。
説明オンラインDDL操作が大量のデータを生成する場合、データ同期タスクが遅延する可能性があります。
No: DTSは、オンラインDDL操作によって生成された一時テーブルのデータを同期しません。 ソースデータベースの元のDDLデータのみが同期されます。
説明[いいえ] を選択すると、ターゲットデータベースのテーブルがロックされる可能性があります。
失敗した接続の再試行時間
既定では、DTSがソースデータベースまたはターゲットデータベースへの接続に失敗した場合、DTSは次の720分 (12時間) 以内に再試行します。 必要に応じて再試行時間を指定できます。 DTSが指定された時間内にソースデータベースとターゲットデータベースに再接続すると、DTSはデータ同期タスクを再開します。 それ以外の場合、データ同期タスクは失敗します。
説明DTSが接続を再試行すると、DTSインスタンスに対して課金されます。 ビジネスニーズに基づいて再試行時間を指定することを推奨します。 ソースインスタンスとターゲットインスタンスがリリースされた後、できるだけ早くDTSインスタンスをリリースすることもできます。
ページの右下隅にある [事前チェック] をクリックします。
説明データ同期タスクを開始する前に、DTSは事前チェックを実行します。 データ同期タスクは、タスクが事前チェックに合格した後にのみ開始できます。
タスクが事前チェックに合格しなかった場合は、失敗した各項目の横にある
 アイコンをクリックして詳細を表示できます。
アイコンをクリックして詳細を表示できます。 詳細に基づいて問題をトラブルシューティングした後、新しい事前チェックを開始します。
問題をトラブルシューティングする必要がない場合は、失敗した項目を無視して新しい事前チェックを開始してください。
次のメッセージが表示されたら、[事前チェック] ダイアログボックスを閉じます。[事前チェックの合格] その後、データ同期タスクが開始されます。
初期同期が完了し、データ同期タスクが同期状態になるまで待ちます。
データ同期タスクのステータスは、[同期タスク] ページで確認できます。

増分データテーブルのスキーマ
MaxComputeプロジェクトのフルテーブルスキャンを許可するには、MaxComputeでset odps.sql.allow.fullscan=true; コマンドを実行する必要があります。
DTSは、ソースMySQLデータベースで生成された増分データをMaxComputeの増分データテーブルに同期します。 増分データテーブルは、増分データおよび特定のメタデータを格納する。 次の図は、増分データテーブルのスキーマを示しています。

この例では、modifytime_year、modifytime_month、modifytime_day、modifytime_hour、およびmodifytime_minuteフィールドがパーティションキーを形成します。 これらのフィールドは、[同期ポリシーと同期するオブジェクトの選択] ステップで指定します。
増分データテーブルのスキーマ
フィールド | 説明 |
record_id | 増分ログエントリの一意のID。 説明
|
operation_flag | 操作のタイプ。 有効な値:
|
utc_timestamp | 操作のタイムスタンプ (UTC) 。 また、バイナリログファイルのタイムスタンプでもあります。 |
before_flag | 列の値が更新前の値かどうかを示します。 有効値: YとN。 |
after_flag | 列の値が更新後の値であるかどうかを示します。 有効値: YとN。 |
before_flagおよびafter_flagフィールドに関する追加情報
増分ログエントリのbefore_flagフィールドとafter_flagフィールドは、操作の種類に応じて定義されます。
INSERT
INSERT操作の場合、列の値は新しく挿入されたレコードの値 (更新後の値) です。 before_flagフィールドの値はNであり、after_flagフィールドの値はYである。

UPDATE
DTSは、UPDATE操作用に2つの増分ログエントリを生成します。 2つの増分ログエントリは、record_id、operation_flag、およびutc_timestampフィールドに同じ値を持ちます。
第1のログエントリは、更新前の値を記録するので、before_flagフィールドの値はYであり、after_flagフィールドの値はNである。第2のログエントリは、更新後の値を記録するので、before_flagフィールドの値はNであり、after_flagフィールドの値はYである。

DELETE
DELETE操作の場合、列の値は削除されたレコードの値 (更新前の値) です。 before_flagフィールドの値はYであり、after_flagフィールドの値はNである。

完全なベースラインテーブルと増分データテーブルのマージ
データ同期タスクが開始されると、DTSはMaxComputeに完全なベースラインテーブルと増分データテーブルを作成します。 SQL文を使用して、2つのテーブルをマージできます。 これにより、特定の時点で完全なデータを取得できます。
このセクションでは、customerという名前のテーブルのデータをマージする方法について説明します。 次の図は、顧客テーブルのスキーマを示しています。

ソーステーブルのスキーマに基づいて、MaxComputeでテーブルを作成します。 テーブルは、マージされたデータを格納するために使用されます。
たとえば、
1565944878の時点で顧客テーブルの完全なデータを取得できます。 次のSQL文を実行して、必要なテーブルを作成します。CREATE TABLE `customer_1565944878` ( `id` bigint NULL, `register_time` datetime NULL, `address` string);説明アドホッククエリ機能を使用して、SQL文を実行できます。 詳細については、「アドホッククエリ機能を使用したSQL文の実行 (オプション) 」をご参照ください。
MaxComputeでサポートされているデータ型の詳細については、「データ型のエディション」をご参照ください。
MaxComputeで次のSQL文を実行して、完全なベースラインテーブルと増分データテーブルをマージし、特定の時点で完全なデータを取得します。
set odps.sql.allow.fullscan=true; insert overwrite table <result_storage_table> select <col1>, <col2>, <colN> from( select row_number() over(partition by t.<primary_key_column> order by record_id desc, after_flag desc) as row_number, record_id, operation_flag, after_flag, <col1>, <col2>, <colN> from( select incr.record_id, incr.operation_flag, incr.after_flag, incr.<col1>, incr.<col2>,incr.<colN> from <table_log> incr where utc_timestamp< <timestamp> union all select 0 as record_id, 'I' as operation_flag, 'Y' as after_flag, base.<col1>, base.<col2>,base.<colN> from <table_base> base) t) gt where row_number=1 and after_flag='Y'説明<result_storage_table>: マージされたデータを格納するテーブルの名前。
<col1>/<col2>/<colN>: マージするテーブル内の列の名前。
<primary_key_column>: マージするテーブルの主キー列の名前。
<table_log>: 増分データテーブルの名前。
<table_base>: 完全なベースラインテーブルの名前。
<timestamp>: フルデータが取得されたときに生成されるタイムスタンプ。
次のSQL文を実行して、
1565944878の時点で顧客テーブルの完全なデータを取得します。set odps.sql.allow.fullscan=true; insert overwrite table customer_1565944878 select id, register_time, address from( select row_number() over(partition by t.id order by record_id desc, after_flag desc) as row_number, record_id, operation_flag, after_flag, id, register_time, address from( select incr.record_id, incr.operation_flag, incr.after_flag, incr.id, incr.register_time, incr.address from customer_log incr where utc_timestamp< 1565944878 union all select 0 as record_id, 'I' as operation_flag, 'Y' as after_flag, base.id, base.register_time, base.address from customer_base base) t) gt where gt.row_number= 1 and gt.after_flag= 'Y';customer_1565944878テーブルからマージされたデータを照会します。
