Alibaba Cloud Elasticsearch は、オープンソースの Elasticsearch およびその商用機能 (Security、Machine Learning、Graph、Application Performance Management (APM) など) と完全な互換性があります。データ分析やデータ検索のシナリオ向けのサービスを提供し、エンタープライズレベルのアクセス制御、セキュリティ監視とアラート、自動レポート生成などの機能をサポートします。Data Transmission Service (DTS) を使用して、PolarDB for MySQL クラスターから Elasticsearch クラスターにデータを同期し、データ分析および検索アプリケーションを迅速に構築できます。
前提条件
バージョン 5.5、5.6、6.3、6.7、または 7.x の宛先 Elasticsearch インスタンスを作成済みであること。 詳細については、「Alibaba Cloud Elasticsearch インスタンスの作成」をご参照ください。
PolarDB for MySQL クラスターでバイナリログを有効にしていること。 詳細については、「バイナリログの有効化」をご参照ください。
注意事項
DTS は、初期完全データ同期中にソースおよび宛先 RDS インスタンスの読み取りおよび書き込みリソースを使用します。これにより、RDS インスタンスの負荷が増加する可能性があります。インスタンスのパフォーマンスが好ましくない場合、仕様が低い場合、またはデータ量が多い場合、データベースサービスが利用できなくなる可能性があります。たとえば、ソース RDS インスタンスで多数の低速 SQL クエリが実行されたり、テーブルにプライマリキーがなかったり、宛先 RDS インスタンスでデッドロックが発生したりする場合など、DTS は大量の読み取りおよび書き込みリソースを占有します。データ同期の前に、データ同期がソースおよび宛先 RDS インスタンスのパフォーマンスに与える影響を評価してください。オフピーク時にデータを同期することをお勧めします。たとえば、ソースおよび宛先 RDS インスタンスの CPU 使用率が 30% 未満の場合にデータを同期できます。
DTS は、データ定義言語 (DDL) 操作を同期しません。データ同期中にソースデータベースのテーブルで DDL 操作が実行された場合、同期オブジェクトからテーブルを削除し、Elasticsearch インスタンスからテーブルのインデックスを削除してから、テーブルを同期オブジェクトに再度追加する必要があります。詳細については、「同期オブジェクトの削除」および「同期オブジェクトの追加」をご参照ください。
同期するテーブルに列を追加するには、まず Elasticsearch インスタンスでテーブルのマッピングを変更する必要があります。次に、PolarDB for MySQL クラスターで対応する DDL 操作を実行します。最後に、DTS 同期インスタンスを一時停止してから再開します。
課金
| 同期タイプ | タスク構成料金 |
| スキーマ同期と完全データ同期 | 無料です。 |
| 増分データ同期 | 有料です。 詳細については、「課金の概要」をご参照ください。 |
サポートされる SQL 操作
INSERT、DELETE、UPDATE
データ型マッピング
ソースデータベースと Elasticsearch インスタンスがサポートする型が異なるため、データ型の直接マッピングが常に可能とは限りません。初期スキーマ同期中、DTS は Elasticsearch インスタンスでサポートされている型に基づいてデータ型をマッピングします。詳細については、「初期スキーマ同期のデータ型マッピング」をご参照ください。
説明DTS は、スキーマ移行中に
mappingパラメーターのdynamicを設定しません。パラメーターの動作は、Elasticsearch インスタンスの設定によって異なります。ソースデータが JSON 形式の場合、テーブル内のすべての行で同じキーの値が同じデータ型であることを確認してください。そうしないと、DTS で同期エラーが発生する可能性があります。詳細については、「dynamic」をご参照ください。次の表に、Elasticsearch とリレーショナルデータベースのマッピングを示します。
Elasticsearch
リレーショナルデータベース
インデックス
データベース
タイプ
テーブル
ドキュメント
行
フィールド
列
マッピング
スキーマ
手順
データ同期ジョブを購入します。 詳細については、「DTS 同期インスタンスの購入」をご参照ください。
説明インスタンスを購入する際、ソースインスタンスとして [PolarDB]、宛先インスタンスとして [Elasticsearch]、同期トポロジとして [一方向同期] を選択します。
DTS コンソールにログインします。
説明Data Management (DMS) コンソールにリダイレクトされた場合は、
 アイコン(
アイコン( にあります)をクリックすると、DTS コンソールの旧バージョンに移動できます。
にあります)をクリックすると、DTS コンソールの旧バージョンに移動できます。左側のナビゲーションウィンドウで、[データ同期] をクリックします。
[同期タスク] ページの上部で、宛先インスタンスが存在するリージョンを選択します。
データ同期インスタンスを見つけ、[アクション] 列の [タスクの設定] をクリックします。
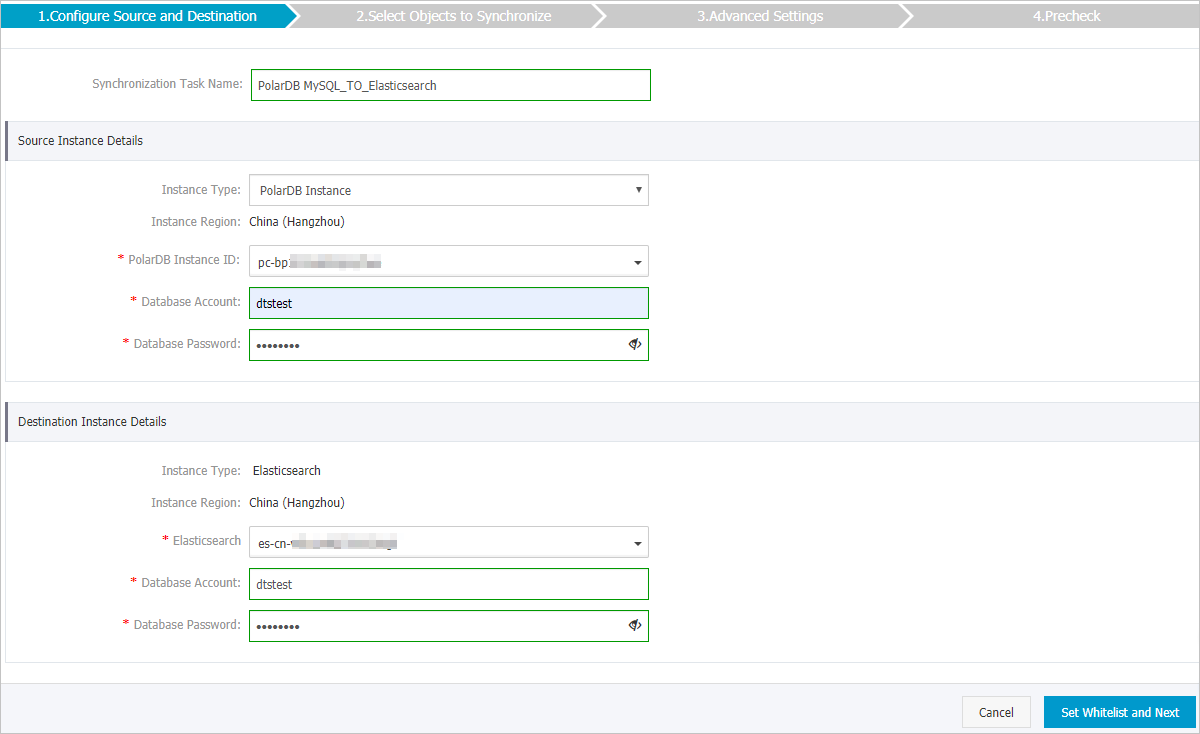
同期ジョブのソースインスタンスと宛先インスタンスを設定します。
セクション
設定
説明
N/A
同期ジョブ名
DTS は同期ジョブの名前を自動的に生成します。わかりやすいように、説明的な名前を指定することをお勧めします。名前は一意である必要はありません。
ソースインスタンス情報
インスタンスタイプ
値は PolarDB インスタンス に固定されており、変更できません。
インスタンスリージョン
データ同期インスタンスの購入時に選択したソースインスタンスのリージョン。このパラメーターは変更できません。
PolarDB インスタンス ID
ソース PolarDB for MySQL クラスターのクラスター ID を選択します。
データベースアカウント
PolarDB for MySQL クラスターのデータベースアカウントを入力します。
説明アカウントには、同期するオブジェクトを含むデータベースに対する読み取り権限が必要です。
データベースパスワード
データベースアカウントに対応するパスワードを入力します。
宛先インスタンス情報
インスタンスタイプ
値は Elasticsearch に固定されており、変更できません。
インスタンスリージョン
データ同期インスタンスの購入時に選択した宛先インスタンスのリージョン。このパラメーターは変更できません。
Elasticsearch
宛先 Elasticsearch インスタンスの ID を選択します。
データベースアカウント
Elasticsearch インスタンスへの接続に使用するアカウントを入力します。デフォルトのアカウントは elastic です。
データベースパスワード
アカウントに対応するパスワードを入力します。
ページの右下隅にある [ホワイトリストと次への設定] をクリックします。
ソースまたは宛先データベースが ApsaraDB RDS for MySQL や ApsaraDB for MongoDB インスタンスなどの Alibaba Cloud データベースインスタンスである場合、DTS は DTS サーバーの CIDR ブロックをインスタンスの IP アドレスホワイトリストに自動的に追加します。ソースまたは宛先データベースが Elastic Compute Service (ECS) インスタンスでホストされている自己管理データベースである場合、DTS は DTS サーバーの CIDR ブロックを ECS インスタンスのセキュリティグループルールに自動的に追加します。データベースにアクセスできることを確認する必要があります。自己管理データベースが複数の ECS インスタンスでホストされている場合は、DTS サーバーの CIDR ブロックを各 ECS インスタンスのセキュリティグループルールに手動で追加する必要があります。ソースまたは宛先データベースがデータセンターでホストされているか、サードパーティのクラウドサービスプロバイダーによって提供されている自己管理データベースである場合は、DTS がデータベースにアクセスできるように、DTS サーバーの CIDR ブロックをデータベースの IP アドレスホワイトリストに手動で追加する必要があります。詳細については、「DTS サーバーの IP アドレスをホワイトリストに追加する」をご参照ください。
警告DTS サーバーの CIDR ブロックがデータベースまたはインスタンスのホワイトリスト、あるいは ECS セキュリティグループルールに自動または手動で追加されると、セキュリティリスクが発生する可能性があります。したがって、DTS を使用してデータを同期する前に、潜在的なリスクを理解して認め、ユーザー名とパスワードのセキュリティ強化、公開されるポートの制限、API 呼び出しの認証、ホワイトリストまたは ECS セキュリティグループルールの定期的な確認と不正な CIDR ブロックの禁止、Express Connect、VPN Gateway、または Smart Access Gateway を使用したデータベースの DTS への接続など、予防措置を講じる必要があります。
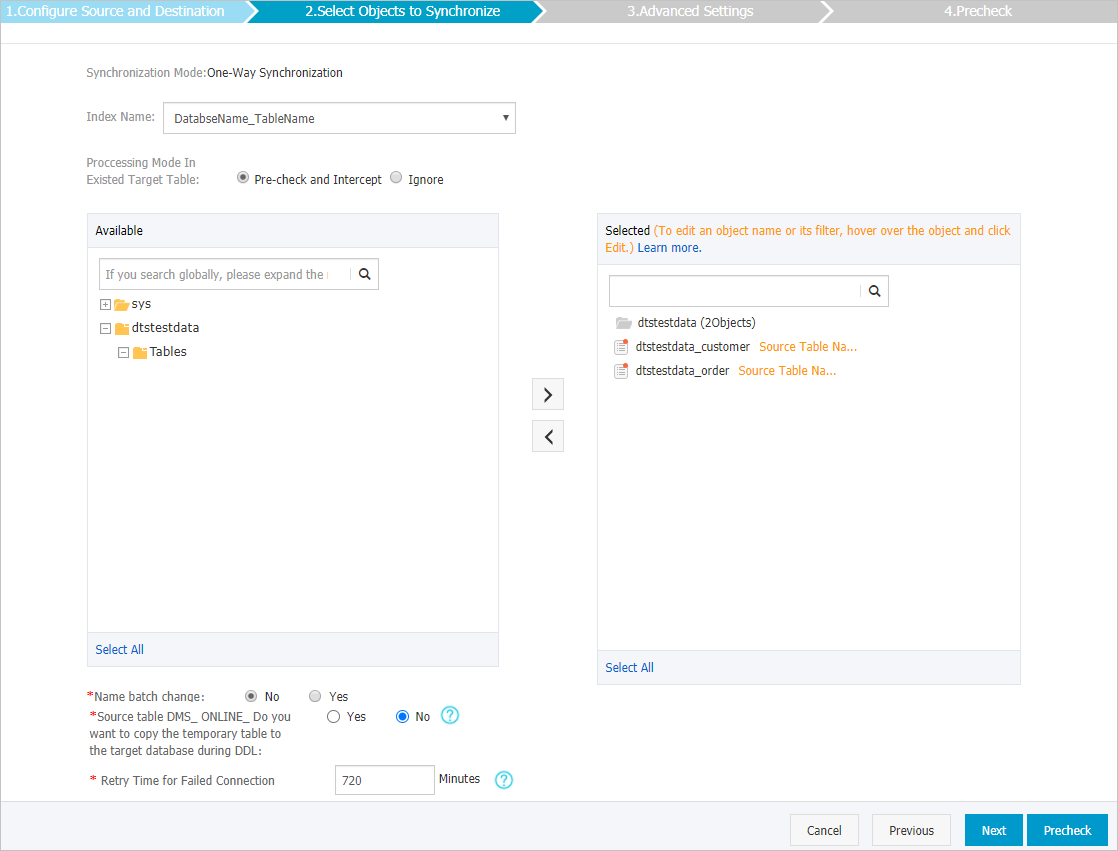
インデックス名、既存のテーブルの処理モード、および同期オブジェクトを設定します。
設定
説明
インデックス名
テーブル名
[テーブル名] を選択した場合、宛先 Elasticsearch インスタンスに作成されるインデックスの名前はテーブル名と同じになります。この例では、インデックス名は customer です。
DatabaseName_TableName
[DatabaseName_TableName] を選択した場合、宛先 Elasticsearch インスタンスに作成されるインデックスの名前は DatabaseName_TableName 形式になります。この例では、インデックス名は dtstestdata_customer です。
既存のテーブルの処理モード
事前チェックしてエラーを報告: 宛先データベースに同じ名前のインデックスが含まれているかどうかを確認します。同じ名前のインデックスが存在しない場合、チェック項目は合格します。同じ名前のインデックスが存在する場合、事前チェック中にエラーが報告され、データ同期タスクは開始されません。
説明宛先データベースで同じ名前のインデックスを削除または名前変更できない場合は、宛先インスタンスで同期オブジェクトの新しい名前を指定して、名前の競合を回避できます。
無視して続行: 宛先データベースで同じ名前のインデックスのチェックをスキップします。
警告[無視して続行] を選択すると、データの不整合が発生し、ビジネスにリスクが及ぶ可能性があります。例:
マッピングが一致し、宛先データベースのレコードがソースデータベースのレコードと同じプライマリキー値を持つ場合、宛先データベースのレコードは初期データ同期中に保持されます。増分データ同期中、レコードは上書きされます。
マッピングが一致しない場合、初期データ同期が失敗したり、一部の列のデータしか同期できなかったり、同期が失敗したりする可能性があります。
同期オブジェクトの選択
[ソースオブジェクト] ボックスで、同期するオブジェクトをクリックし、
 アイコンをクリックして [選択したオブジェクト] ボックスに移動します。
アイコンをクリックして [選択したオブジェクト] ボックスに移動します。データベースとテーブルを同期オブジェクトとして選択できます。
マッピング名の変更
オブジェクト名マッピング機能を使用して、宛先インスタンスに同期されるオブジェクトの名前を変更できます。詳細については、「オブジェクト名マッピング」をご参照ください。
DMS オンライン DDL 中に一時テーブルをレプリケート
DMS を使用してソースデータベースでオンライン DDL 操作を実行する場合、オンライン DDL 操作によって生成された一時テーブルを同期するかどうかを指定できます。
はい: DTS は、オンライン DDL 操作によって生成された一時テーブルのデータを同期します。
説明オンライン DDL 操作で大量のデータが生成されると、データ同期タスクが遅延する可能性があります。
いいえ: DTS は、オンライン DDL 操作によって生成された一時テーブルのデータを同期しません。ソースデータベースの元の DDL データのみが同期されます。
説明[いいえ] を選択すると、宛先データベースのテーブルがロックされる可能性があります。
ネットワーク不安定時のリトライ期間
デフォルトでは、DTS がソースまたは宛先データベースへの接続に失敗した場合、DTS は次の 720 分 (12 時間) 以内にリトライします。必要に応じてリトライ時間を指定できます。DTS が指定された時間内にソースおよび宛先データベースに再接続すると、DTS はデータ同期タスクを再開します。そうでない場合、データ同期タスクは失敗します。
説明DTS が接続をリトライすると、DTS インスタンスに対して課金されます。ビジネスニーズに基づいてリトライ時間を指定することをお勧めします。ソースインスタンスと宛先インスタンスがリリースされた後、できるだけ早く DTS インスタンスをリリースすることもできます。
[選択したオブジェクト] ボックスで、同期するテーブルにポインターを合わせ、[編集] をクリックします。宛先 Elasticsearch インスタンスのテーブルのインデックス名、タイプ名、およびその他の情報を設定します。

設定
説明
インデックス名
詳細については、「用語」をご参照ください。
警告インデックス名とタイプ名には、特殊文字としてアンダースコア (_) のみを含めることができます。
同じ構造を持つ複数のソーステーブルを単一の宛先オブジェクトに同期するには、このステップを繰り返して、これらのテーブルに同じインデックス名とタイプ名を設定する必要があります。そうしないと、タスクが失敗したり、データが失われたりする可能性があります。
タイプ名
フィルター条件
SQL フィルター条件を設定して、同期するデータをフィルターできます。フィルター条件を満たすデータのみが宛先インスタンスに同期されます。詳細については、「SQL 条件を使用したデータのフィルター」をご参照ください。
パーティション
パーティションを設定するかどうかを選択します。[はい] を選択した場合は、[パーティションキー列] と [パーティション数] も設定する必要があります。
_routing の設定
_routing 設定は、ドキュメントを宛先 Elasticsearch インスタンスの特定のシャードにルーティングして保存できます。詳細については、「_routing」をご参照ください。
カスタム列をルーティングに使用するには、[はい] を選択します。
_id をルーティングに使用するには、[いいえ] を選択します。
説明宛先 Elasticsearch インスタンスのバージョンが 7.x の場合は、[いいえ] を選択する必要があります。
_id 値
テーブルのプライマリキー列
複合プライマリキーは単一の列にマージされます。
ビジネスキー
[ビジネスキー] を選択した場合は、対応する [ビジネスキー列] も設定する必要があります。
パラメーターの追加
必要な [フィールドパラメーター] と [フィールドパラメーター値] を選択します。フィールドパラメーターとその値の詳細については、Elasticsearch の公式ドキュメントをご参照ください。
説明DTS は、選択可能なパラメーターのみをサポートします。
ページの右下隅にある [事前チェック] をクリックします。
説明データ同期タスクを開始する前に、DTS は事前チェックを実行します。タスクが事前チェックに合格した後にのみ、データ同期タスクを開始できます。
タスクが事前チェックに合格しなかった場合は、失敗した各項目の横にある
 アイコンをクリックして詳細を表示できます。
アイコンをクリックして詳細を表示できます。詳細に基づいて問題をトラブルシューティングした後、新しい事前チェックを開始します。
問題をトラブルシューティングする必要がない場合は、[失敗した項目を無視] して [新しい事前チェックを開始] します。
[事前チェック] ダイアログボックスに [事前チェックに合格しました] というメッセージが表示されたら、ダイアログボックスを閉じます。その後、データ同期タスクが開始されます。
初期同期が完了し、データ同期タスクが [同期中] 状態になるまで待ちます。
[同期タスク] ページでデータ同期タスクのステータスを表示できます。

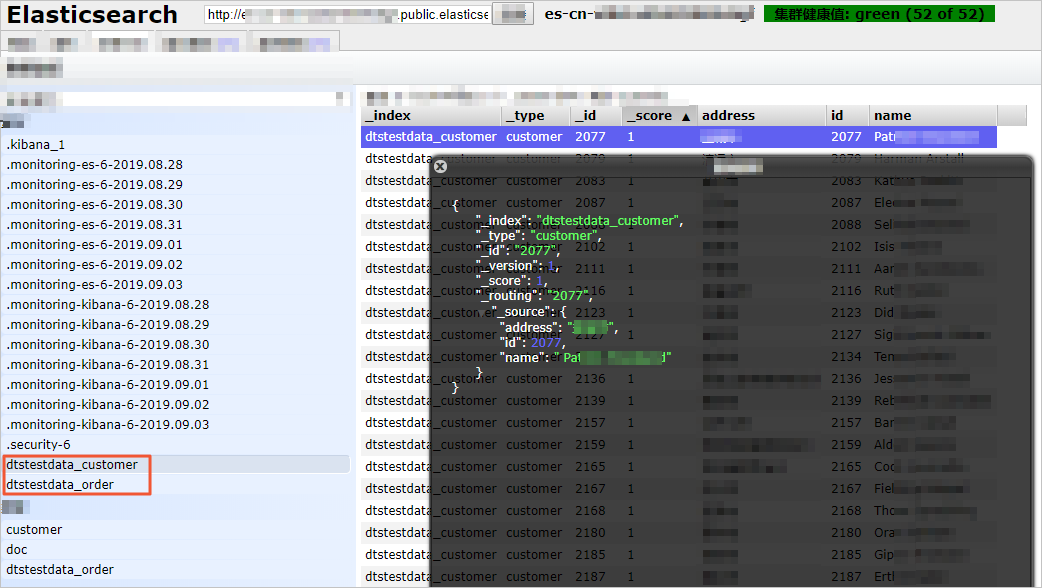
同期されたインデックスとデータの表示
データ同期タスクが [同期中] 状態になったら、Elasticsearch インスタンスに接続します。この例では、Elasticsearch-Head プラグイン が使用されます。次に、作成されたインデックスと同期されたデータが要件を満たしていることを確認します。
結果が要件を満たさない場合は、インデックスとそのデータを削除し、データ同期タスクを再設定できます。