変更を保存します。
前提条件
GPU アクセラレーテッドノードを含む ACK マネージドクラスターが作成されていること。詳細については、「GPU アクセラレーテッドノードを含む ACK クラスタを作成する」をご参照ください。
AHPA がインストールされ、メトリックを収集するためのデータソースが構成されていること。詳細については、「AHPA の概要」をご参照ください。
Managed Service for Prometheus が有効になっており、Managed Service for Prometheus によって少なくとも 7 日間のアプリケーション統計情報が収集されていること。統計情報には、アプリケーションで使用される GPU リソースの詳細が含まれます。詳細については、「Managed Service for Prometheus」をご参照ください。
仕組み
ハイパフォーマンスコンピューティング分野、特にディープ ラーニングにおけるモデルのトレーニングやモデルの推論などのシナリオでは、GPU リソース割り当ての詳細な管理と動的な調整により、リソース使用率を向上させ、コストを削減できます。Container Service for Kubernetes (ACK) は、GPU メトリックに基づく自動スケーリングをサポートしています。Managed Service for Prometheus を使用して、リアルタイムの GPU 使用率やメモリ使用量などの主要なメトリックを収集できます。次に、Prometheus Adapter を使用して、これらのメトリックを Kubernetes が認識できるメトリックに変換し、AHPA と統合できます。AHPA は、これらのデータ、過去の負荷傾向、および予測アルゴリズムに基づいて GPU リソース要求を予測できます。AHPA は、複製されたポッドの数または GPU リソースの割り当てを自動的に調整して、リソースが不足する前にスケールアウト操作が完了するようにします。また、アイドル状態のリソースが存在する場合にスケールイン操作を実行して、コストを削減し、クラスタの効率を向上させます。
手順 1:Metrics Adapter をデプロイする
クラスタで使用されている Prometheus インスタンスの内部 HTTP API エンドポイントを取得します。
ARMS コンソール にログインします。
左側のナビゲーションウィンドウで、 を選択します。
[インスタンス] ページの上部で、ACK クラスタが配置されているリージョンを選択します。
Managed Service for Prometheus インスタンスの名前をクリックします。インスタンスの詳細ページの左側のナビゲーションウィンドウで、[設定] をクリックし、[HTTP API URL] セクションの内部エンドポイントを記録します。
ack-alibaba-cloud-metrics-adapter をデプロイします。
ACK コンソール にログインします。左側のナビゲーションウィンドウで、 を選択します。
[マーケットプレイス] ページで、[アプリカタログ] タブをクリックします。ack-alibaba-cloud-metrics-adapter を見つけてクリックします。
[ack-alibaba-cloud-metrics-adapter] ページの右上隅にある [デプロイ] をクリックします。
[基本情報] ウィザードページで、[クラスタ] と [名前空間] を指定し、[次へ] をクリックします。
[パラメーター] ウィザードページで、[チャートバージョン] パラメーターを設定し、手順 1 で取得した内部 HTTP API エンドポイントを [パラメーター] セクションの
prometheus.urlパラメーターの値として指定します。次に、パラメーター[OK] をクリックします。
手順 2:AHPA を使用して GPU メトリックに基づく予測スケーリングを実行する
この例では、推論サービスがデプロイされています。次に、推論サービスにリクエストを送信して、AHPA が GPU メトリックに基づいて予測スケーリングを実行できるかどうかを確認します。
推論サービスをデプロイします。
次のコマンドを実行して、推論サービスをデプロイします。
次のコマンドを実行して、ポッドのステータスをクエリします。
kubectl get pods -o wide予期される出力:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES bert-intent-detection-7b486f6bf-f**** 1/1 Running 0 3m24s 10.15.1.17 cn-beijing.192.168.94.107 <none> <none>次のコマンドを実行して、推論サービスにリクエストを送信し、サービスがデプロイされているかどうかを確認します。
kubectl get svc bert-intent-detection-svcコマンドを実行して、推論サービスがデプロイされている GPU アクセラレーテッドノードの IP アドレスをクエリできます。次に、次のコマンドの47.95.XX.XXを取得した IP アドレスに置き換えます。curl -v "http://47.95.XX.XX/predict?query=Music"予期される出力:
* Trying 47.95.XX.XX... * TCP_NODELAY set * Connected to 47.95.XX.XX (47.95.XX.XX) port 80 (#0) > GET /predict?query=Music HTTP/1.1 > Host: 47.95.XX.XX > User-Agent: curl/7.64.1 > Accept: */* > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < Content-Type: text/html; charset=utf-8 < Content-Length: 9 < Server: Werkzeug/1.0.1 Python/3.6.9 < Date: Wed, 16 Feb 2022 03:52:11 GMT < * Closing connection 0 PlayMusic # The query result.HTTP ステータスコード
200とクエリ結果が返された場合、推論サービスはデプロイされています。
AHPA を構成します。
この例では、ポッドの GPU 使用率が 20% を超えたときにポッドをスケーリングするように AHPA が構成されています。
AHPA のメトリックを収集するようにデータソースを構成します。
application-intelligence.yaml という名前のファイルを作成し、次のコンテンツをファイルにコピーします。
prometheusUrlパラメーターを、手順 1 で取得した Prometheus インスタンスの内部エンドポイントに設定します。apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-shanghai-intranet.arms.aliyuncs.com:9090/api/v1/prometheus/da9d7dece901db4c9fc7f5b*******/1581204543170*****/c54417d182c6d430fb062ec364e****/cn-shanghai"次のコマンドを実行して、application-intelligence をデプロイします。
kubectl apply -f application-intelligence.yaml
AHPA をデプロイする
fib-gpu.yaml という名前のファイルを作成し、次のコンテンツをファイルにコピーします。
この例では、
observerモードが使用されています。AHPA 関連のパラメーターの詳細については、「パラメーター」をご参照ください。次のコマンドを実行して、AHPA をデプロイします。
kubectl apply -f fib-gpu.yaml次のコマンドを実行して、AHPA のステータスをクエリします。
kubectl get ahpa予期される出力:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 0 0 1 10 50 6d19h出力では、
CURRENT(%)列に0が返され、TARGET(%)列に20が返されます。これは、現在の GPU 使用率が 0% であり、GPU 使用率が 20% を超えるとポッドのスケーリングがトリガーされることを示しています。
推論サービスの自動スケーリングをテストします。
次のコマンドを実行して、推論サービスにアクセスします。
次のコマンドを実行して、AHPA のステータスをクエリします。
kubectl get ahpa予期される出力:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 189 10 4 10 50 6d19h出力は、現在の GPU 使用率 (
CURRENT(%)) がスケーリングのしきい値 (TARGET(%)) よりも高いことを示しています。したがって、ポッドのスケーリングがトリガーされ、予想されるポッドの数はDESIREDPODS列に返される値である10になります。次のコマンドを実行して、予測結果をクエリします。
kubectl get --raw '/apis/metrics.alibabacloud.com/v1beta1/namespaces/default/predictionsobserver/fib-gpu'|jq -r '.content' |base64 -d > observer.html次の図は、過去 7 日間の既存データに基づく GPU 使用率の予測結果を示しています。
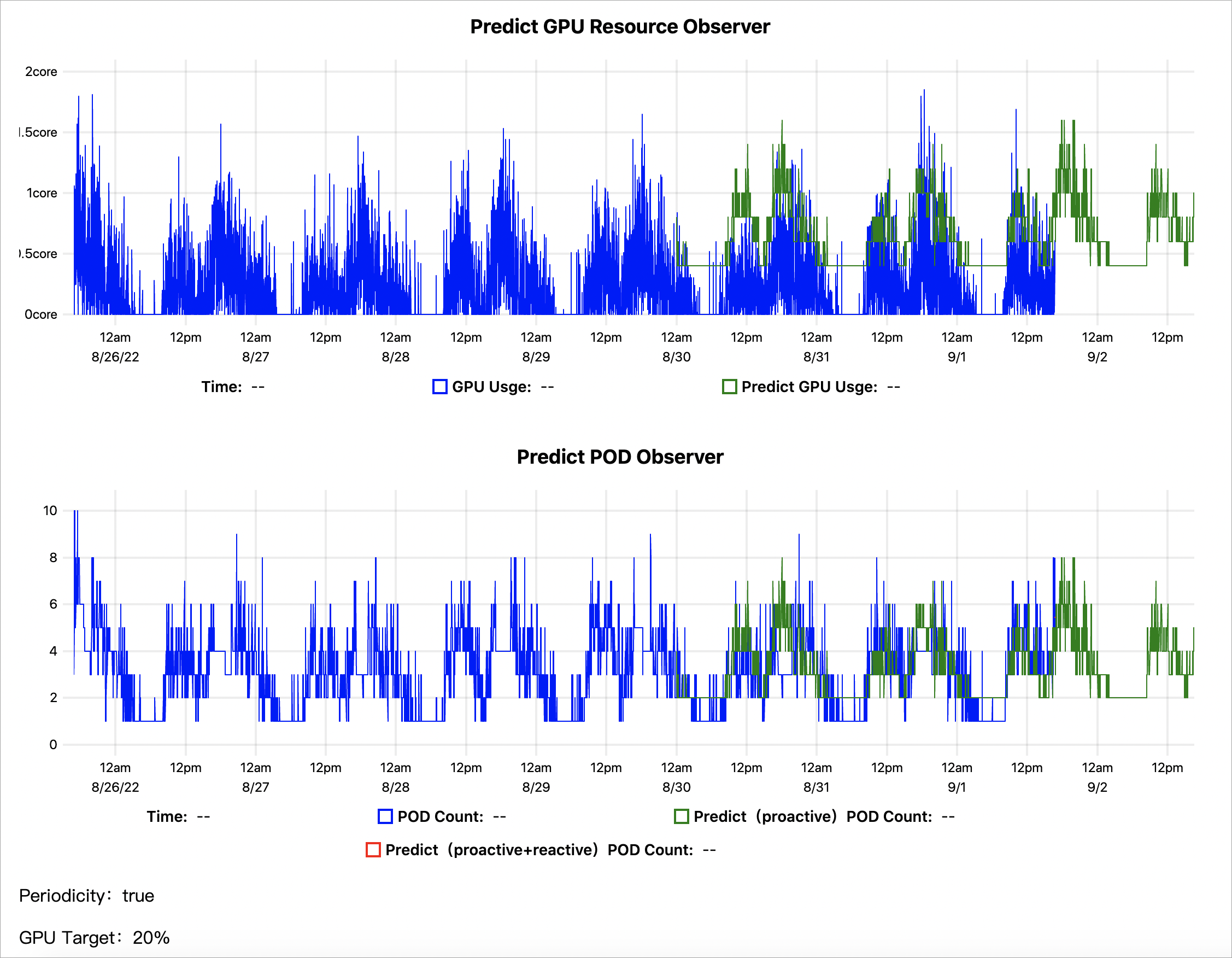
GPU リソースオブザーバーの予測:実際の GPU 使用率は青い線で表されます。AHPA によって予測された GPU 使用率は緑色の線で表されます。予測された GPU 使用率は実際の GPU 使用率よりも高いことがわかります。
POD オブザーバーの予測:スケーリングイベントで追加または削除されたポッドの実際の数は青い線で表されます。AHPA がスケーリングイベントで追加または削除されると予測するポッドの数は緑色の線で表されます。予測されたポッドの数は、実際のポッドの数よりも少ないことがわかります。スケーリングモードを
autoに設定し、予測されたポッドの数に基づいて他の設定を構成できます。このようにして、AHPA はポッドリソースを節約できます。
結果は、AHPA が予測スケーリングを使用して変動するワークロードを期待どおりに処理できることを示しています。予測結果を確認した後、スケーリングモードを
autoに設定できます。これにより、AHPA はポッドを自動的にスケーリングできます。
関連情報
Knative を使用すると、serverless Kubernetes (ASK) クラスタで AHPA を使用できます。アプリケーションが定期的なパターンでリソースをリクエストする場合、AHPA を使用してリソースリクエストの変更を予測し、スケーリングアクティビティのリソースをプリフェッチできます。これにより、アプリケーションのスケーリング時のコールドスタートの影響が軽減されます。詳細については、「AHPAを使用したスケジュール自動スケーリングの実装」をご参照ください。
シナリオによっては、HTTP リクエストの QPS やメッセージキューの長さなど、カスタムメトリックに基づいてアプリケーションをスケーリングする必要がある場合があります。AHPA は、alibaba-cloud-metrics-adapter コンポーネントと連携できる External Metrics メカニズムを提供し、カスタムメトリックに基づいてアプリケーションをスケーリングできるようにします。詳細については、「AHPA を使用してアプリケーションスケーリングのカスタムメトリックを構成する」をご参照ください。