This topic describes how to use Auto Feature Engineering (AutoFE) to generate new features in FeatureStore and provides some suggestions and insights for you. You can use the pipeline model generated by AutoFE to convert features in the training and test datasets. This improves the performance of a machine learning or deep learning model.
AutoFE overview
AutoFE recommends a set of feature engineering operations by analyzing the data that you provide. You can directly use this set of operations to perform feature engineering or customize your feature engineering process based on the recommended operations.
AutoFE provides the following features:
Retrieves statistical features by performing operations such as group by feature_x and group by (feature_x, feature_y). For example, AutoFE can generate the sales feature by city based on the sample data, which is equivalent to mapping cities to a numeric feature.
Analyzes feature combinations to obtain combined features. Example: crosscount(feature_x, feature_y).
Obtains derived features by performing addition, subtraction, multiplication, and division operations. Example: feature_x +-*/ feature_y.
Uses the Gradient Boosting Decision Tree (GBDT) algorithm to sort the generated features based on the information value, importance, and correlation of the features for feature selection.
Flowchart

Preprocessing
AutoFE preprocesses data that is read from data stores, such as MaxCompute projects, Object Storage Service (OSS) buckets, Hadoop Distributed File System (HDFS) file systems, and local files, and samples data based on specific requirements and data volume. AutoFE in FeatureStore supports only MaxCompute projects. The standalone edition of AutoFE supports all data stores.
Feature selection
If the number of features exceeds 800, the performance of subsequent feature analysis and model training steps is affected. We recommend that you use the GBDT algorithm to evaluate and filter the raw features.
Feature analysis
AutoFE performs statistical analysis, combination generation, and scalable automatic feature engineering (SAFE) selection on features to generate a new feature set.
Statistical analysis: AutoFE performs statistical analysis of feature data based on multiple important statistical metrics, such as the average value, standard deviation, maximum value, minimum value, skewness, and kurtosis.
Combination generation: AutoFE trains the GBDT model, combines features based on the tree paths, calculates the information gain ratio to sort features, and then recommends the combination of features.
SAFE selection: AutoFE calculates the information value of each column by using buckets, filters out features with low information values, trains the GBDT model, calculates the importance of features, and then filters out the features with low importance.
For more information, see SAFE: Scalable Automatic Feature Engineering Framework for Industrial Tasks.
Model training
AutoFE generates configurations and data based on feature analysis, trains the pipeline process, and then generates a model that can be used both offline and online.
Feature conversion
AutoFE loads the pipeline model, converts features in the training and test data, and then generates the feature engineering results.
Billing
You can use AutoFE free of charge. However, when AutoFE performs operations such as preprocessing, feature selection, statistical analysis, and model training, data computing and model training tasks are started in subscription or pay-as-you-go MaxCompute projects. Therefore, you are charged fees for using public resources related to MaxCompute. For more information, see Overview.
Prerequisites
Before you perform the operations described in this topic, make sure that the requirements that are described in the following table are met.
Related service | Description |
MaxCompute | |
DataWorks |
|
Platform for AI (PAI) | |
OSS |
Before you begin
Synchronize data from the pai_online_project.finance_record table
To facilitate testing, Alibaba Cloud provides a simulated table in the MaxCompute project pai_online_project. You can execute SQL statements to synchronize data in the table from the MaxCompute project pai_online_project to your MaxCompute project. Perform the following steps:
Log on to the DataWorks console.
In the left-side navigation pane, choose Data Development and O&M > Data Development.
On the DataStudio page, select the DataWorks workspace that you created and click Go to Data Development.
Move the pointer over Create and choose Create Node > MaxCompute > ODPS SQL. In the Create Node dialog box, configure the node parameters that are described in the following table.
Parameter
Description
Engine Instance
Select the MaxCompute engine instance that you created.
Node Type
Select ODPS SQL from the Node Type drop-down list.
Path
Choose Business Flow > Workflow.
Name
Specify a custom name.
Click Confirm.
On the tab of the node that you created, execute the following SQL statements to synchronize data in the finance_record table from the pai_online_project project to your MaxCompute project.
CREATE TABLE IF NOT EXISTS finance_record like pai_online_project.finance_record STORED AS ALIORC LIFECYCLE 90; INSERT OVERWRITE TABLE finance_record SELECT * FROM pai_online_project.finance_record
Procedure
Go to the development environment of a Data Science Workshop (DSW) instance.
Log on to the PAI console.
In the top navigation bar, select the region in which the DSW instance resides.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the default workspace.
In the left-side navigation pane of the default workspace, choose Model Training > Data Science Workshop (DSW).
On the Data Science Workshop (DSW) page, find the DSW instance that you want to open and click Open in the Actions column to go to the development environment of the DSW instance.
On the Launcher tab of the Notebook tab, click DSW Gallery in the Quick Start section to go to the DSW Gallery page.
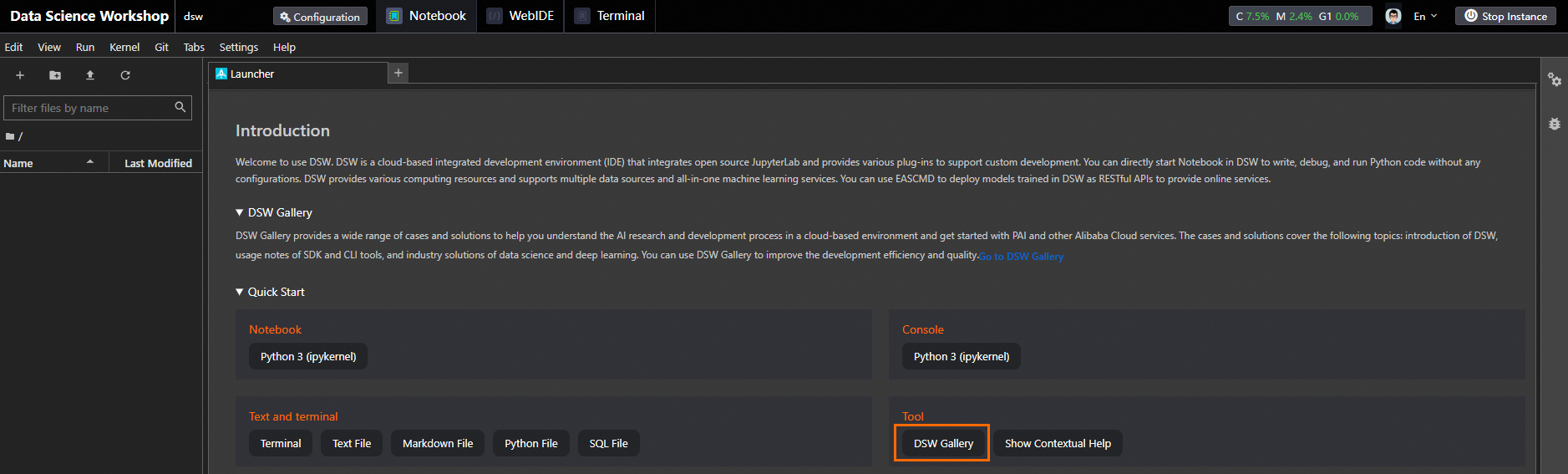
On the DSW Gallery page, search for Feature Store with AutoFE and click Open in DSW. The system starts to download the required resources and tutorial file to the DSW instance. After the download is complete, the tutorial file is automatically opened.
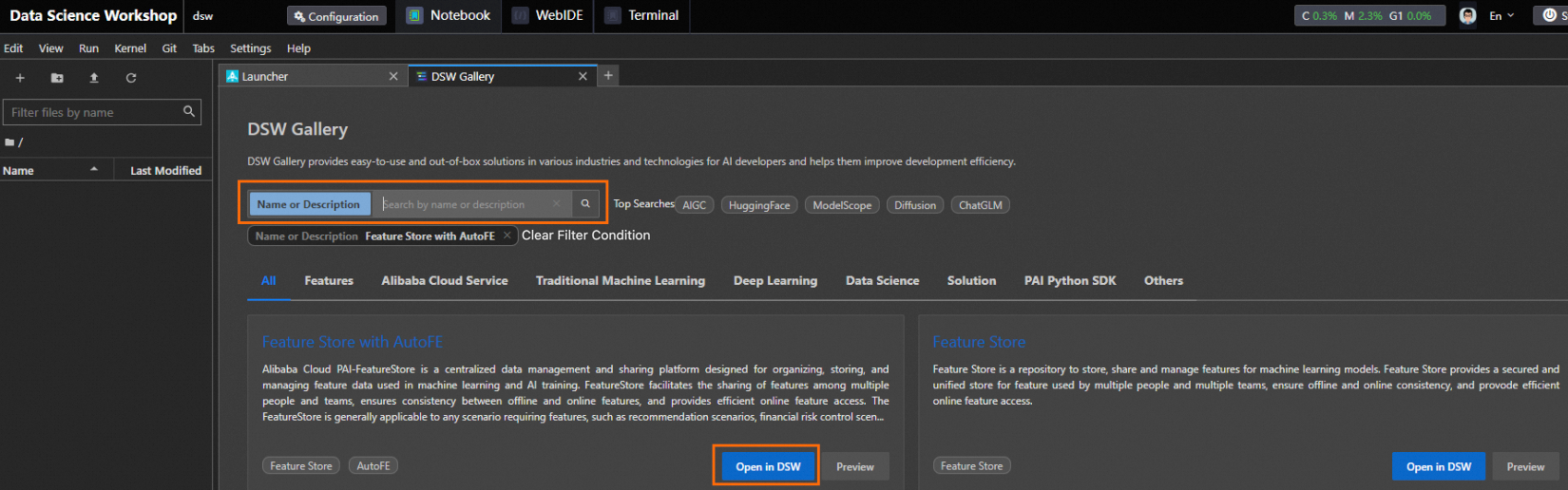
In the tutorial file feature_store_with_autofe.ipynb, view the tutorial content and run the tutorial.
Configure the parameters in the tutorial file and click
 to run the command in a step. Run the command in each step in sequence.
to run the command in a step. Run the command in each step in sequence. 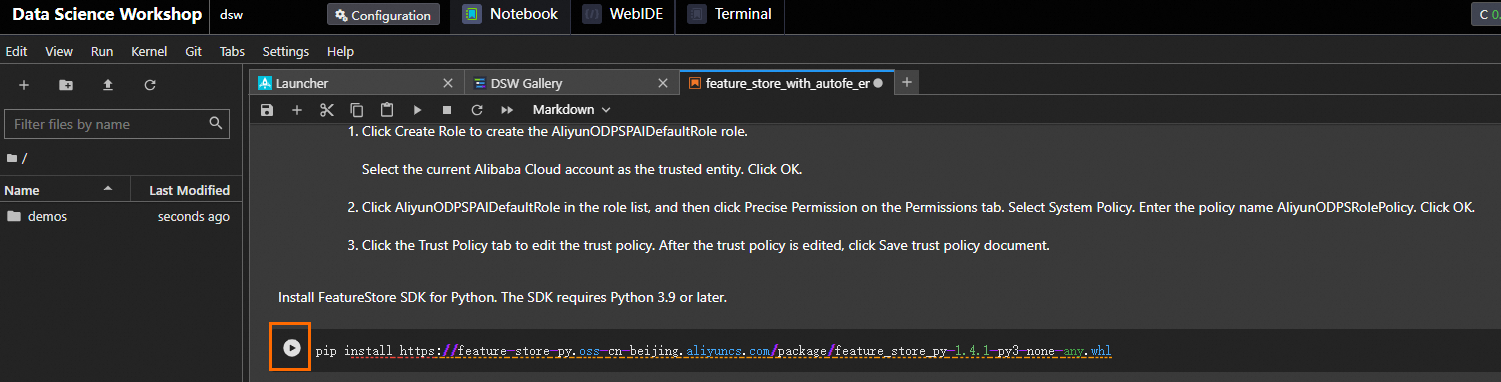
After the commands are run, go to the OSS console to view the test results.
To obtain the path of the OSS bucket, view the value of the
output_config_oss_dirparameter that you configured in Step 4.