This topic describes how to use the financial components that are provided by Platform for AI (PAI) to create a scorecard model based on credit card billing statements.
Background information
Scorecard is a modeling method that is commonly used in the credit risk assessment and Internet finance fields. It is not only a machine learning algorithm, but also a generic modeling framework. The scorecard modeling process includes the following steps: bin the raw data, perform feature engineering on the data in each bin, and then use the processed data to train a linear model.
Scorecard modeling is commonly used in credit assessment, such as assessment of risks in credit card repayment and credit assessment for loan disbursements. It is also used in other fields for scoring, such as customer service scoring and Alipay credit scoring.
Prerequisites
A workspace is created. For more information, see Create and manage a workspace.
MaxCompute resources are associated with the workspace. For more information, see Manage workspaces.
Datasets
The pipeline described in this topic is based on an open source dataset from Default of Credit Card Clients Dataset. This dataset contains 30,000 data records. Each record includes the gender, education, marital status, age, credit card payment history, and credit card billing statements of a user.
The payment_next_month field indicates the probability of a user paying off the credit card debt. In the field:
The value 1 indicates that the user pays off the debt.
The value 0 indicates that the user does not pay off the debt.
Procedure
Go to the Machine Learning Designer page.
Log on to the PAI console.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
In the left-side navigation pane, choose .
Create a pipeline.
On the Visualized Modeling (Designer) page, click the Preset Templates tab.
On the Preset Templates tab, click Create below Predict Credit Scores by Using a Scorecard Model.
In the Create Pipeline dialog box, configure the parameters. You can use their default values.
The value specified for the Data Storage parameter is the Object Storage Service (OSS) bucket path of the temporary data and models generated during the runtime of the pipeline.
Click OK.
It requires about 10 seconds to create the pipeline.
On the Pipelines tab, double-click Predict Credit Scores by Using a Scorecard Model to open the pipeline.
View the components of the pipeline on the canvas as shown in the following figure. The system automatically creates the pipeline based on the preset template.
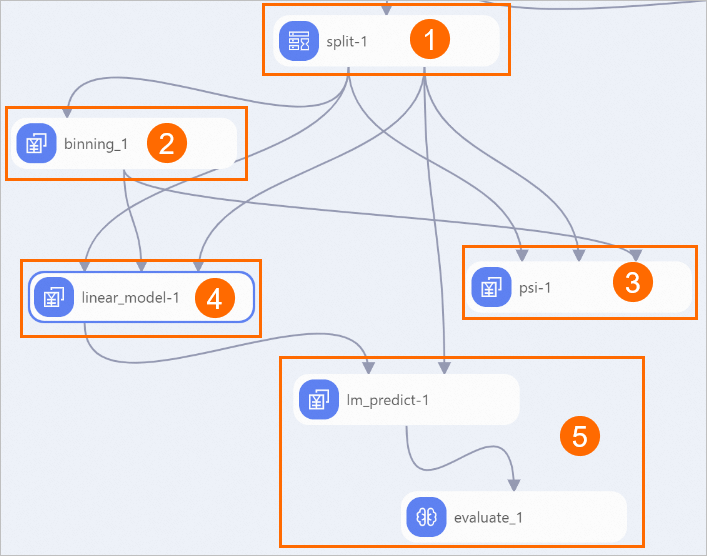
Area
Description
①
The Split-1 component splits the source dataset into a training dataset and a prediction dataset.
②
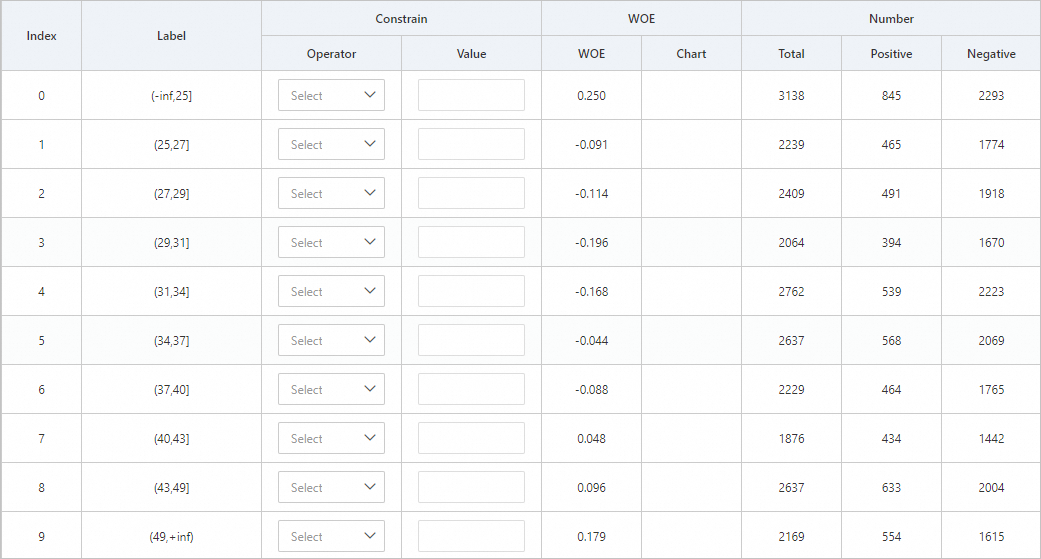
The Binning-1 component provides a feature that is similar to one-hot encoding. The component groups the input data into data classes (bins). The data values in each bin are replaced by a value, which is representative of the bin. For example, the Binning-1 component groups the values of age into a number of age intervals. After the pipeline is run, right-click Binning-1 on the canvas and click Binning. In the Binning -1 panel, click the age tab. The following figure shows the results.
 After the pipeline is run, right-click Binning-1 on the canvas and choose . In the dialog box that appears, view the binning result. In this example, each field falls into multiple intervals after data binning, as shown in the following figure.
After the pipeline is run, right-click Binning-1 on the canvas and choose . In the dialog box that appears, view the binning result. In this example, each field falls into multiple intervals after data binning, as shown in the following figure. 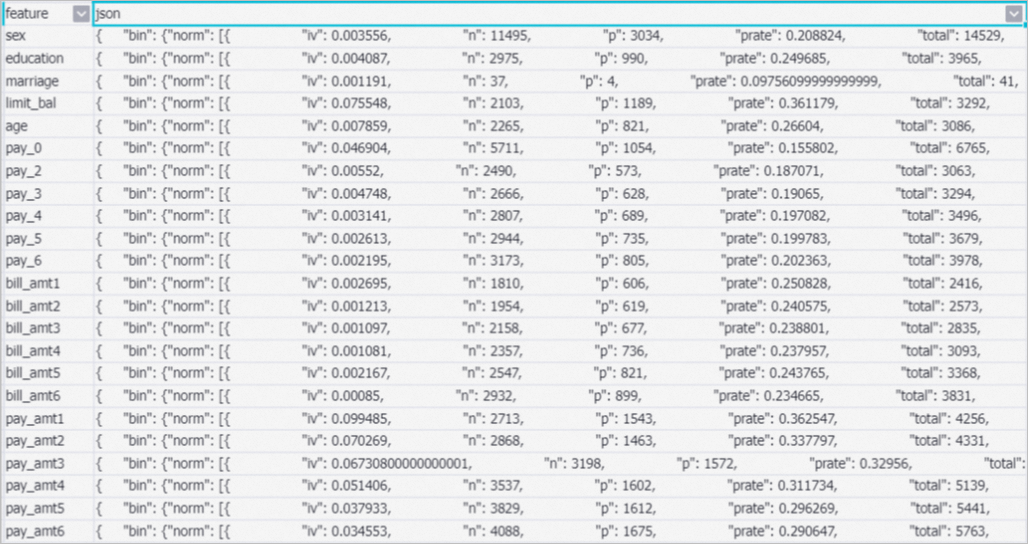
③
The PSI-1 component compares the stability of the population before and after data splitting, and the stability of the population after data binning. Then, the component calculates and returns population stability index (PSI) values for all features, as shown in the following figure. After the pipeline is run, right-click PSI-1 on the canvas and choose to view the data. The following figure shows the results.
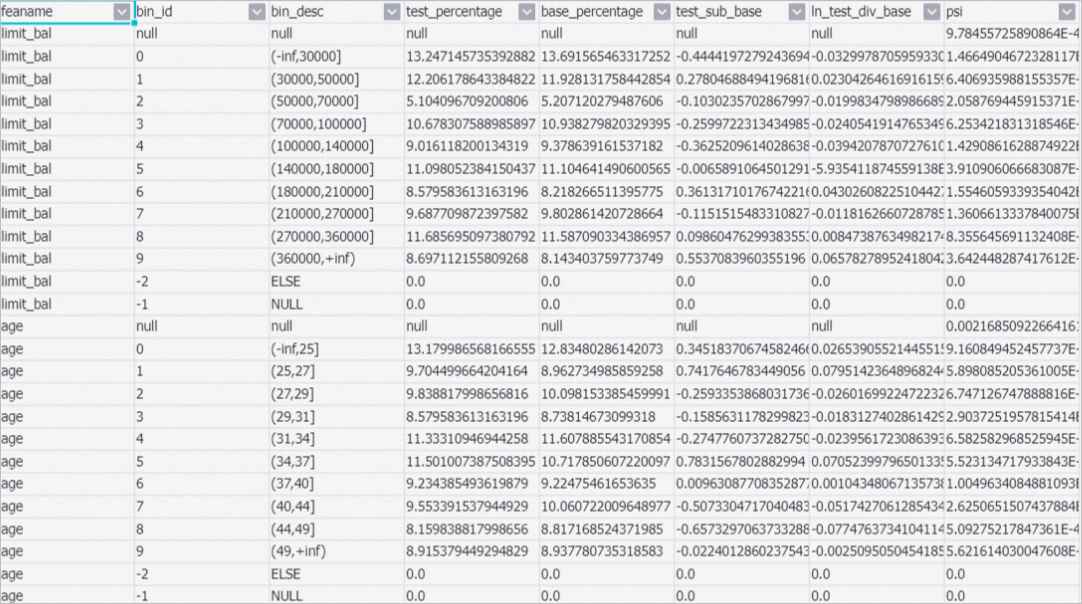
PSI, which indicates the stability of the population, is an important metric to help identify a shift in the population over a period of time. The total PSI value of a feature is the sum of the PSI values of the feature in all rows. A PSI value that is smaller than 0.1 indicates insignificant changes. A PSI value between 0.1 and 0.25 indicates minor changes. A PSI value that is greater than 0.25 indicates major changes and you must pay close attention.
④
The Linear_model-1 component trains a scorecard model. After the pipeline is run, you can right-click the Linear_model-1 component and choose to view the training results. The following figure shows the results.
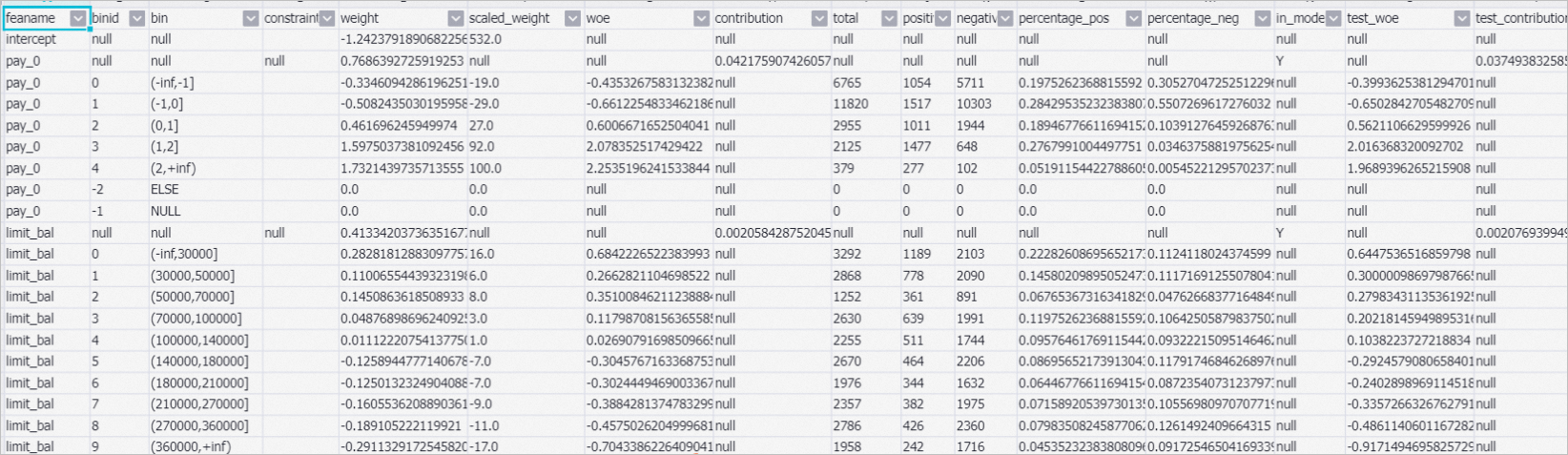 The purpose of using a scorecard model is to use normalized scores to indicate the weights of the involved features. The following key parameters are involved in the model training result:
The purpose of using a scorecard model is to use normalized scores to indicate the weights of the involved features. The following key parameters are involved in the model training result:weight: the initial weight.
Scaled_weight: the scaled weight. For example, if the pay_0 feature falls into the (-1,0] bin, 29 points are lost. If the pay_0 feature falls into the (0,1] bin, 27 points are gained.
contribution: the impact of each feature on the result. A higher value indicates greater impact.
⑤
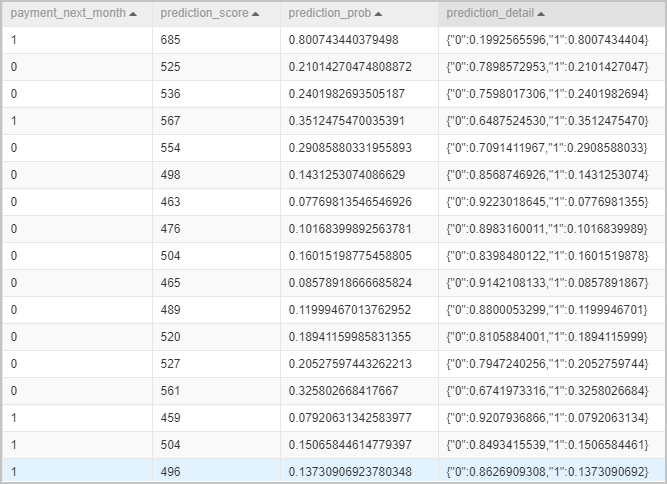
The Lm_predict-1 component uses the scorecard model to predict the credit score of each user. The Evaluate-1 component evaluates the quality of the model.
Run the pipeline and view the results.
In the upper-left corner of the canvas, click the
 icon.
icon. After the pipeline is run, right-click the Lm_predict-1 component and choose to view the credit score of each user.
References
For more information about algorithm components, see the following topics: