You can use Model Gallery to directly deploy a pre-trained open source model for image classification, or use your own dataset to fine-tune a pre-trained model for specific scenarios. Then, you can use the fine-tuned model to classify images into custom categories. This topic describes how to deploy the cv_vit-base_image-classification_ImageNet-labels model in Model Gallery to classify images.
Prerequisites
An Object Storage Service (OSS) bucket is created. For more information, see Create buckets.
Go to the details page of the model
Go to the Model Gallery page.
Log on to the PAI console.
In the left-side navigation pane, click Workspaces. On the Workspaces page, find the workspace that you want to manage and click the name of the workspace. The Workspace Details page appears.
In the left-side navigation pane of the Workspace Details page, click Model Gallery.
On the Model Gallery page, click image-classification in the CV section. Then, find and click the cv_vit-base_image-classification_ImageNet-labels model to go to the details page of the model.
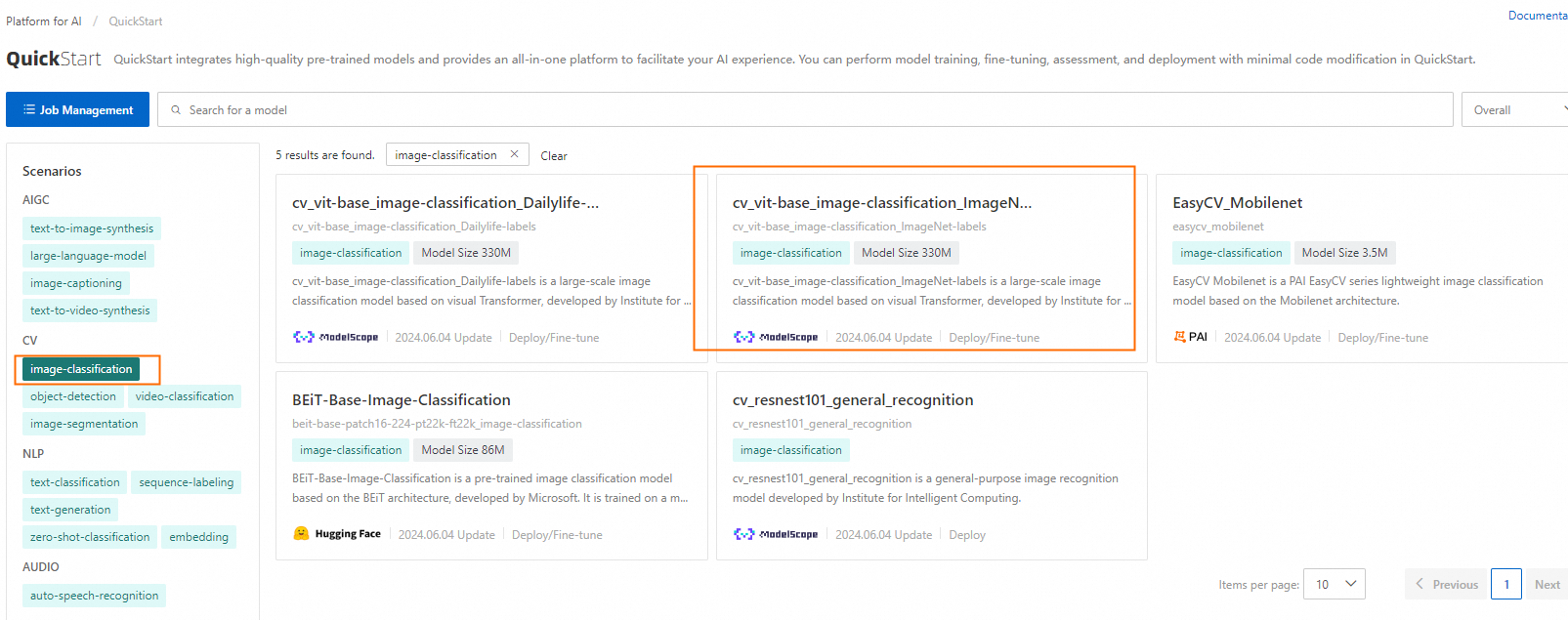
Model Gallery provides multiple mainstream models from different open source communities. You can select a model that meets your business requirements.
In general, a model with a larger number of parameters performs better, but the fees charged for using the model service and the volume of data required to fine-tune the model are higher.
Most models provide information about the pre-training datasets. The more relevant a pre-training dataset is to your scenario, the better the results of direct deployment and fine-tuning are. You can obtain more information about the pre-training dataset on the details page of a model.
Directly deploy the model
The cv_vit-base_image-classification_ImageNet-labels model provided by Model Gallery is a general Vision Transformer (ViT) model for image classification that is available on ModelScope. The model is an image classification model based on the ViT architecture. The model is trained by using the ImageNet-1K dataset and can be used to classify images whose categories are covered by the ImageNet-1K dataset. You can directly deploy the model to Elastic Algorithm Service (EAS) as a model service for image classification. To do so, perform the following steps:
Deploy the model as a model service.
On the details page of the model, click Deploy in the upper-right corner.
Verify the parameter settings in the Model Service Information and Resource Deployment Information sections.
Model Gallery specifies a service name and presets the computing resources that are required to deploy a model based on characteristics of the model. In this example, the default parameter settings are used. You can also modify the parameter settings based on your business requirements. For more information about how to configure the parameters, see the Deploy and debug a model section of the "Deploy and train models" topic.
Click Deploy. In the Billing Notification message, click OK.
The details page of the service appears. On the Service details tab, you can view the deployment status of the model service in the Basic Information section. If the value of the Status parameter changes to In operation, the model service is deployed.
Call the model service.
After the model service is deployed, you can call the model service by sending API requests over HTTP for prediction. The model service accepts Base64-encoded images and returns the prediction results in the JSON format. To call the model service, perform the following steps:
In the Resource Information section of the Service details tab, click View Call Information.
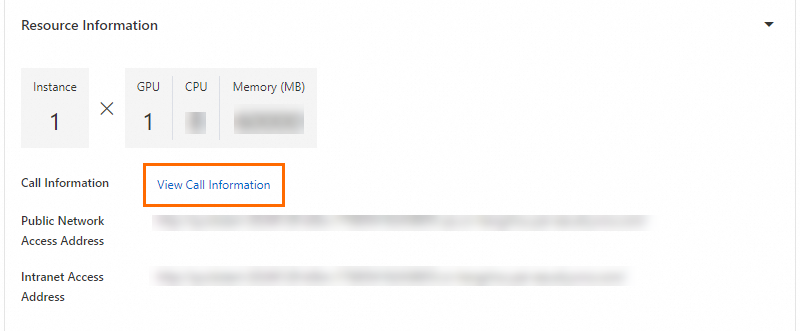
In the Call Information dialog box, view the Access address and Token parameters on the Public network address call tab, and record the values of the parameters.
Use the requests library of Python to call the model service. The following sample code provides an example:
import requests import base64 image_path = "<PathToLocalImage>" url = "<PredictionServiceURL>" token = "<PredictionServiceAccessToken>" def encode_file_to_base64(f): with open(f, "rb") as file: encoded_string = base64.b64encode(file.read()) base64_str = str(encoded_string, "utf-8") return base64_str base64_string = encode_file_to_base64(image_path) request_body = { "image": base64_string } headers = {"Authorization": token} resp = requests.post(url=url, headers=headers, json=request_body) print(resp.content.decode()) print("status code:", resp.status_code)Replace
tokenandurlin the preceding code with the values of the Token and Access address parameters that you obtained in the preceding step. Replace image_path with the local path of the image in the PNG or JPG format.If the call is successful, the model service returns the five most possible categories of the image and the score of each category. The following sample code provides an example.
{ "scores": [ 0.4078965485095978, 0.24673610925674438, 0.1930493414402008, 0.0026617543771862984, 0.0009246605914086103 ], "labels": [ "tiger cat", "tabby, tabby cat", "Egyptian cat", "lynx, catamount", "tiger, Panthera tigris" ] }
Fine-tune the model
The cv_vit-base_image-classification_ImageNet-labels model is suitable for classifying images whose categories are covered by the ImageNet-1K dataset. If the categories of the images to be classified are not contained in the ImageNet-1K dataset, you can use a dataset that contains a small number of images and their categories to fine-tune the model. Then, you can obtain an image classification model that covers the required categories. To fine-tune the model and deploy the fine-tuned model, perform the following steps:
Prepare a dataset.
Prepare a dataset based on the following directory structure.
The model can be trained by using image data that is stored in OSS. You must organize the data in the following directory structure: Each directory indicates a category, and images of the category are stored in the root path of the directory. For example, the path of the training dataset is
oss://{YourOssBucket}.{OssEndpoint}/{PathToTrainData}/and images in the dataset are organized in the following the directory structure:├── category-1 │ ├── image1.jpeg │ └── image2.jpeg ├── category-2 │ ├── image3.jpeg │ └── image4.jpeg |... |... └── category-n ├── imagexxx.jpeg └── imageyyy.jpegTo obtain a model with better performance, we recommend that you prepare a validation dataset that uses the same directory structure. You can use the validation dataset to evaluate the model performance and adjust the model parameters based on the evaluation results.
Upload the dataset to an OSS bucket based on the preceding directory structure. For more information about how to upload data to an OSS bucket, see Upload objects.
Submit a training job.
After you prepare the dataset, click Fine-tune on the details page of the model. In the Fine-tune panel, configure the Training dataset, Validate dataset, and Output Path parameters.
Model Gallery presets parameters in the sections such as Computing resources and Hyper-parameters based on the characteristics of the model. You can use the default parameter settings or modify the parameter settings based on your business requirements. For more information about how to configure parameters, see the Deploy and train models section of the "Deploy and train models" topic.
NoteBy default, the cv_vit-base_image-classification_ImageNet-labels model uses the MiniImageNet-100 dataset for fine-tuning.
Click Fine-tune.

The details page of the job appears. On the details page of the job, you can view the progress, logs, and evaluation results of the training job. After the training job is complete, the model generated by the training job is saved to the output path that is specified by the Output Path parameter in the preceding step.
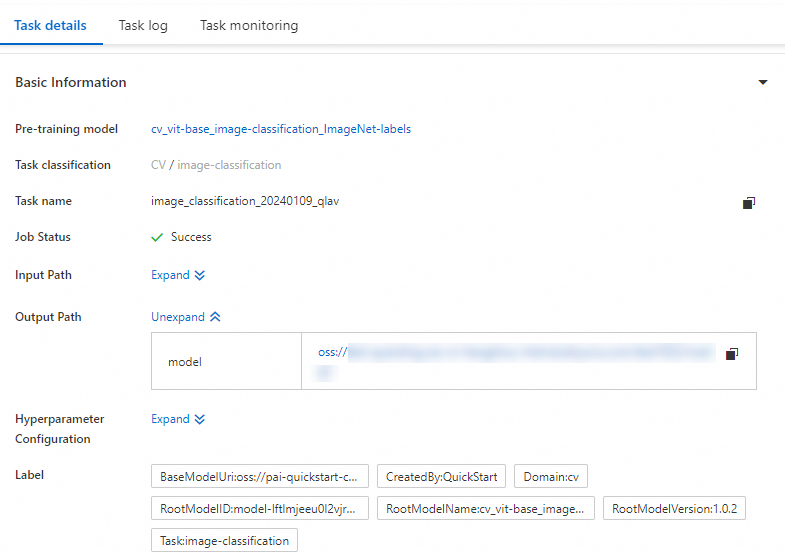
Deploy the fine-tuned model.
The trained model is automatically registered in . You can view or deploy the models. For more information, see Register and manage models.