This topic shows how to train and perform inference on Llama 2 series large language models (LLMs) on the Platform for AI (PAI) with zero code. You can use QuickStart to deploy an online inference service for a Llama 2 model and call it via a web UI or an API. You can also fine-tune a pretrained model with your own dataset to tailor it for specific scenarios and tasks.
Background information
Llama2 is an open-source, English-centric LLM released by Meta. It accepts natural language text as input and produces text as output. Llama 2 models range in size from 7 billion to 70 billion parameters, available in 7b, 13b, and 70b versions. Each version also has a chat-optimized variant called Llama-2-chat. QuickStart supports online inference for Llama 2 series models. You can also use these models as base models for fine-tuning to achieve better results in custom scenarios.
The llama-2-7b-chat model provided in QuickStart is sourced from the Llama-2-7b-chat model on Hugging Face. It is a LLM based on the Transformer architecture, trained on a diverse mix of open-source datasets. This makes it suitable for most general-purpose English-language scenarios.
This topic uses the llama-2-7b-chat model as an example to show how to use QuickStart to deploy the model to Elastic Algorithm Service (EAS) and create and invoke an inference service.
Limitations
Currently, QuickStart is available in the following regions: China (Beijing), China (Shanghai), China (Hangzhou), China (Shenzhen), and China (Ulanqab).
To enable the China (Ulanqab) region, contact your business manager.
Billing
You are charged for using Object Storage Service (OSS) storage. For more information, see OSS Billing overview.
QuickStart itself is free of charge. However, when you use QuickStart for model deployment and training, you incur fees for model deployment (EAS) and training jobs (Deep Learning Containers (DLC)). For more information, see Billing of Elastic Algorithm Service (EAS) and Billing of Deep Learning Containers (DLC).
Prerequisites
You have activated PAI, which includes EAS and DLC, and created a default workspace. A default workspace is created. For more information, see Activate PAI and create a default workspace.
You have activated OSS and created a bucket.
NoteThe bucket must be in the same region as your PAI workspace. You cannot change a bucket's region after it is created.
You have read and agree to the custom commercially available open-source license of the Llama model.
NoteIf you cannot access the link, you may need to use a proxy and try again.
Procedure
The llama-2-7b-chat model is suitable for most non-specialized scenarios. To improve prediction results or apply knowledge from a specific domain, you can fine-tune the model. Fine-tuning helps improve the model's capabilities in your custom domain, making it better suited to your business requirements.
LLMs can learn simple knowledge directly during conversation, so you can choose whether to fine-tune the model. QuickStart uses the LoRA training method. Compared to other methods like Supervised Fine-Tuning (SFT), LoRA significantly reduces training costs and time.
Deploy the model directly
Go to the Model Gallery page.
Log on to the PAI console.
In the left navigation pane, click the workspace list. On the workspace list page, click the name of the workspace that you want to manage.
In the left navigation pane, click QuickStart > Model Gallery.
In the search box, enter llama-2-7b-chat and press Enter.
NoteYou can also select other models based on your business needs. The model requires at least 64 GiB of memory and 24 GiB or more of GPU memory. Ensure your selected resources meet these requirements; otherwise, the deployment may fail.
Click the llama-2-7b-chat model card to open the model details page. In the upper-right corner, click Deploy.

At the bottom of the deployment page, click Deploy.
In the Billing Notification dialog box that appears, click OK.
The page automatically redirects to the Service details page. When the Status of the service changes to In operation, the inference service is successfully deployed.
After the service is deployed, you can call it via the web UI or an API.
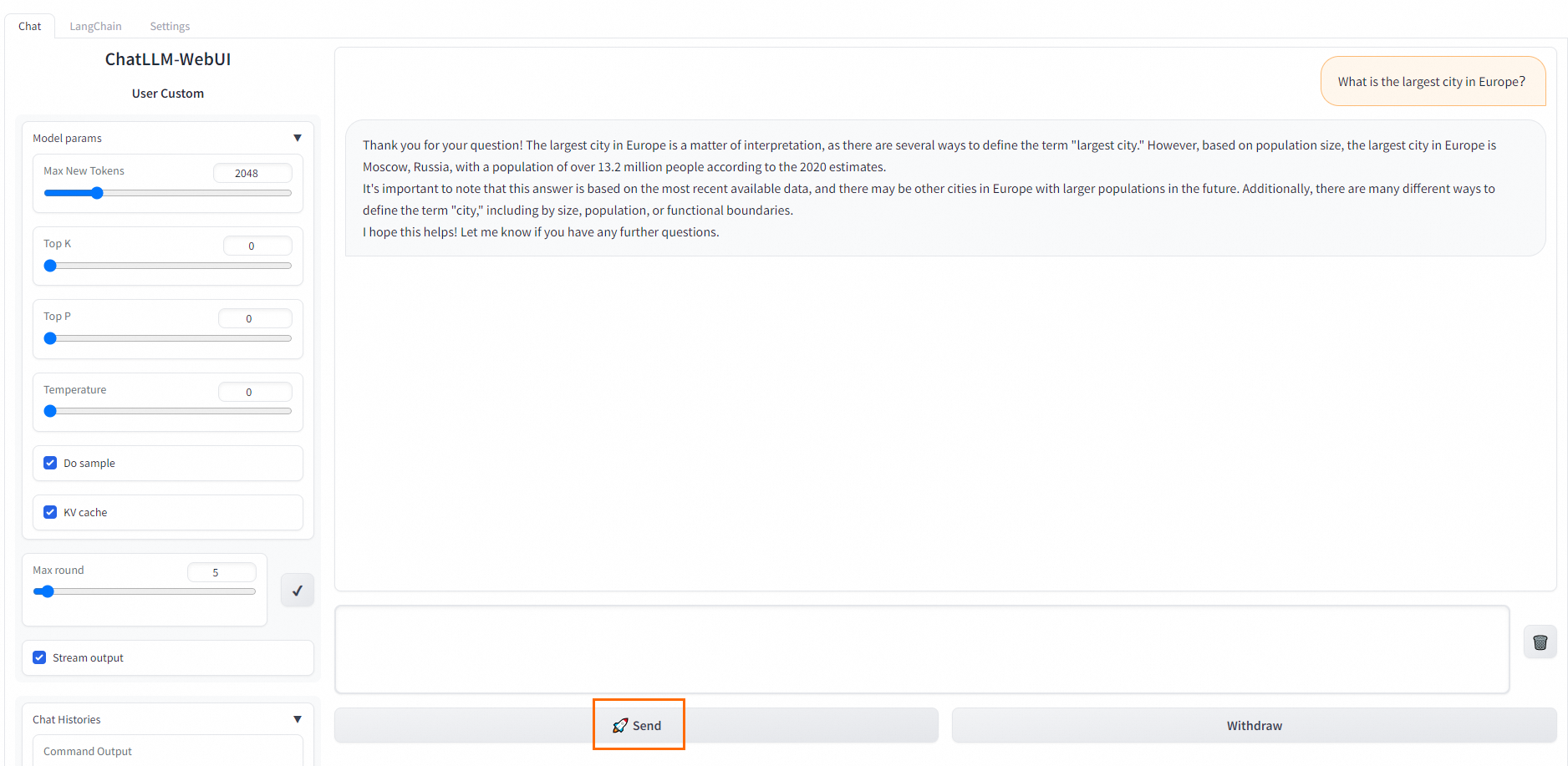
In the upper-right corner of the Service Details page, click View Web App.

call the inference service.
WebUI: On the Chat tab, enter your prompt in the dialog box and click Send to start a multi-turn conversation.
API: At the bottom of the WebUI page, click Use via API to view the API call details.
Fine-tune the model
Go to the Model Gallery page.
Log on to the PAI console.
In the left navigation pane, click the workspace list. On the workspace list page, click the name of the workspace that you want to manage.
In the left navigation pane, click QuickStart > Model Gallery.
In the search box, enter llama-2-7b-chat and press Enter.
NoteYou can also select other models based on your business needs. The model requires at least 64 GiB of memory and 24 GiB or more of GPU memory. Ensure your selected resources meet these requirements; otherwise, the deployment may fail.
Click the llama-2-7b-chat model card to open the model details page, and then click Train.

Configure the model training parameters.
QuickStart provides default configurations for Computing Resources and Hyperparameters that are suitable for most use cases. You can modify them based on your business needs. The following table describes the key parameters for this tutorial.
Parameter
Description
Output Configuration
Model Output Path
Select an OSS bucket path to store the trained model files.
NoteIf you have configured a storage path on the workspace details page, this path is filled in automatically. For more information about how to configure a workspace storage path, see Manage a workspace.
Dataset Configuration
Training Dataset
To help you try out the Llama2 model, QuickStart provides a default training dataset that you can use directly. To use your own training data, prepare it in the format specified in the model documentation and then upload it in one of the following ways:
Dataset Selection: You can use a public or custom dataset. For more information about how to create a custom dataset, see Create and manage datasets.
OSS File or Directory: Upload data through OSS. For more information, see Get started with OSS.
The training data must be in JSON format. Each entry consists of an instruction, an output, and an ID, represented by the
instruction,output, andidfields, respectively.[ { "instruction": "Does the following text belong to the world topic? Why do Americans rarely hold military parades?", "output": "Yes", "id": 0 }, { "instruction": "Does the following text belong to the world topic? Breaking news! The timetable for vehicle reform in public institutions has been released!", "output": "No", "id": 1 } ]To better validate the model's training performance, we recommend that you also prepare a validation dataset. This dataset evaluates the model's performance during training and helps optimize the training parameters.
Click Train to submit the training job.
In the Billing Notification dialog box that appears, click OK.
The page automatically redirects to the Task Details page. When the Job Status changes to Succeeded, the model training is complete.
The trained model is saved to OSS. You can view its specific location in the Output Path field of the Basic Information section.
NoteIf you use the default dataset, hyperparameters, and computing resource configurations, the training job takes approximately 1 hour and 30 minutes. If you use custom data and configurations, the completion time may vary but is typically within a few hours.
Deploy the fine-tuned model.
The procedure for deploying and invoking the fine-tuned model is the same asfor the base model. For more information, see Deploy the model directly.
What to do next
On the QuickStart > Model Gallery page, you can go to the Job Management page and click the Training Jobs and Deployment Jobs tabs to view the details of your jobs.