Purchase an instance
For more information, see Purchase an OpenSearch Vector Search Edition instance.
Configure the instance
On the details page of the purchased instance, the instance is in the Pending Configuration state. The system automatically deploys an instance that contains no data. The number and specifications of the Query Result Searcher (QRS) workers and Searcher workers are the same as those of the QRS workers and Searcher workers that you purchase. Before you can use the instance for search, perform the following steps. After the reindexing is complete, you can use the instance to perform queries.
1. Configure the basic information about a table
In the left-side pane on the instance details page, click Table Management. On the Table Management page, click Add Table. In the Basic Table Information step of the Create wizard, configure the Table Name, Data Shards, Number of Resources for Data Updates, and Scenario Template parameters. In this topic, the Scenario Template parameter is set to Vector: Semantic Search for Text, and the Data Processing parameter is set to Convert Raw Data to Vector Data. Then, click Next.
Parameters:
Table Name: the name of the table. You can customize the table name.
Data Shards: the number of data shards contained in the table. Enter a positive integer in the range of 1 to 256. You can perform sharding to accelerate the full indexing and improve the performance of a single query. If you create multiple index tables in an existing OpenSearch instance, make sure that the index tables contain the same number of shards. Alternatively, make sure that at least one index table contains one shard and other index tables contain the same number of shards.
Number of Resources for Data Updates: the number of resources used for data updates. By default, OpenSearch provides a free quota of two resources for data updates for each data source in an OpenSearch Vector Search Edition instance. Each resource consists of 4 CPU cores and 8 GB of memory. You are charged for resources that exceed the free quota. For more information, see Billing overview of OpenSearch Vector Search Edition for the international site (alibabacloud.com).
Scenario Template: the template that is used to create the table. Valid values: Common Template, Vector: Image Search, and Vector: Semantic Search for Text.
2. Add a data source
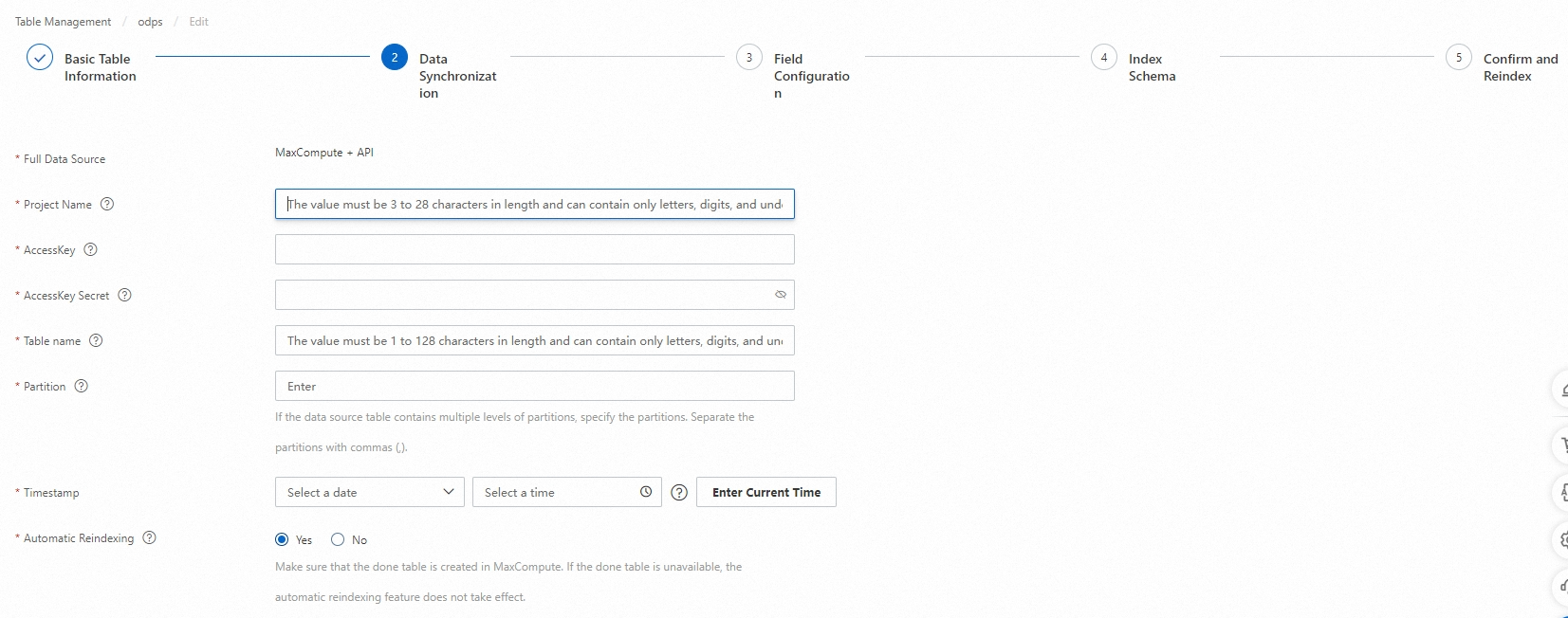
In the Data Synchronization step, add a data source. You can add a MaxCompute data source or an API data source. In this example, MaxCompute + API is selected as Full Data Source. Configure the Project, AccessKey, AccessKey Secret, Table, and Partition Key parameters, set the Automatic Reindexing parameter to Yes or No, and then click Check. If the data source information passes the check, click Next.
For more information about MaxCompute data sources, see Create a table for a MaxCompute data source.
For more information about API data sources, see Create a table for an API data source.
For more information about Object Storage Service (OSS) data sources, see Create a table for an OSS data source.
3. Configure fields
OpenSearch provides relevant preset fields based on the scenario template that you select and automatically imports all fields from the data source to the field list.
In the Field Configuration step, configure fields. If you set the Scenario Template parameter to Vector: Semantic Search for Text in the preceding step, OpenSearch presets id as the primary key field, vector as the vector field, cate_id as the category field, and vector_source_text as the field on which you want to perform word embedding.
Note:
The primary key field and vector field are required. For the primary key field, you must set the Type parameter to INT or STRING and select the Primary Key column. For the vector field, you must set the Type parameter to FLOAT and select the Vector Field column.
By default, the vector field is a multi-value field of the FLOAT type, and multiple values of the vector field are separated by HA3 delimiters (^]). This delimiter is encoded as \x1D in the UTF format. You can also enter a custom multi-value delimiter.
Select Require Embedding for the vector_source_text field on which you want to perform word embedding.
The value of the vector_source_text field can be up to 128 bytes in length. If the length of the value exceeds 128 bytes, only the first 128 bytes are retained for vector prediction.
When you configure a vector index, you must specify the fields in the order of the primary key field, namespace field, and vector field. The namespace field is optional. The preceding figure shows an example.
If a field does not exist or is empty in the source data, the system automatically sets the field to the default value. By default, a field of the numeric type is set to 0 and a field of the STRING type is set to an empty string. You can also specify custom default values.
Advanced configurations of the vector_source_text field
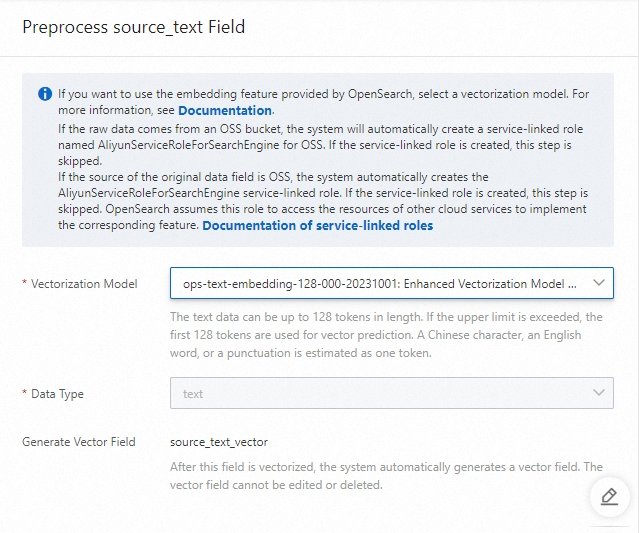
Vectorization Model: the model that converts a short text in Chinese or English. Valid values:
ops-text-embedding-000: a model that converts short Chinese text to vectors. This model uses 768 dimensions.
ops-text-embedding-en-000: a model that converts short English text to vectors. This model uses 768 dimensions.
ops-text-embedding-1024-000-20231001: an enhanced model that converts Chinese text to vectors. This model uses 1,024 dimensions.
ops-text-embedding-512-000-20231001: an enhanced model that converts Chinese text to vectors. This model uses 512 dimensions.
ops-text-embedding-128-000-20231001: an enhanced model that converts Chinese text to vectors. This model uses 128 dimensions.
ops-text-embedding-512-en-000-20231001: an enhanced model that converts English text to vectors. This model uses 512 dimensions.
ops-text-embedding-128-en-000-20231001: an enhanced model that converts English text to vectors. This model uses 128 dimensions.
Data Type: the data type. The default value is text and cannot be modified.
Note: The text can be up to a specific number of tokens in length. If the length of the text exceeds the specified number of tokens, the first specified number of tokens are retained for vector prediction. A Chinese character, an English word, or a punctuation mark is recognized as one token.
4. Configure the index schema
4.1. Vector index
OpenSearch automatically creates indexes for the primary key field and vector field. The index names are the same as the field names. You need to only configure the vector index in the OpenSearch console.
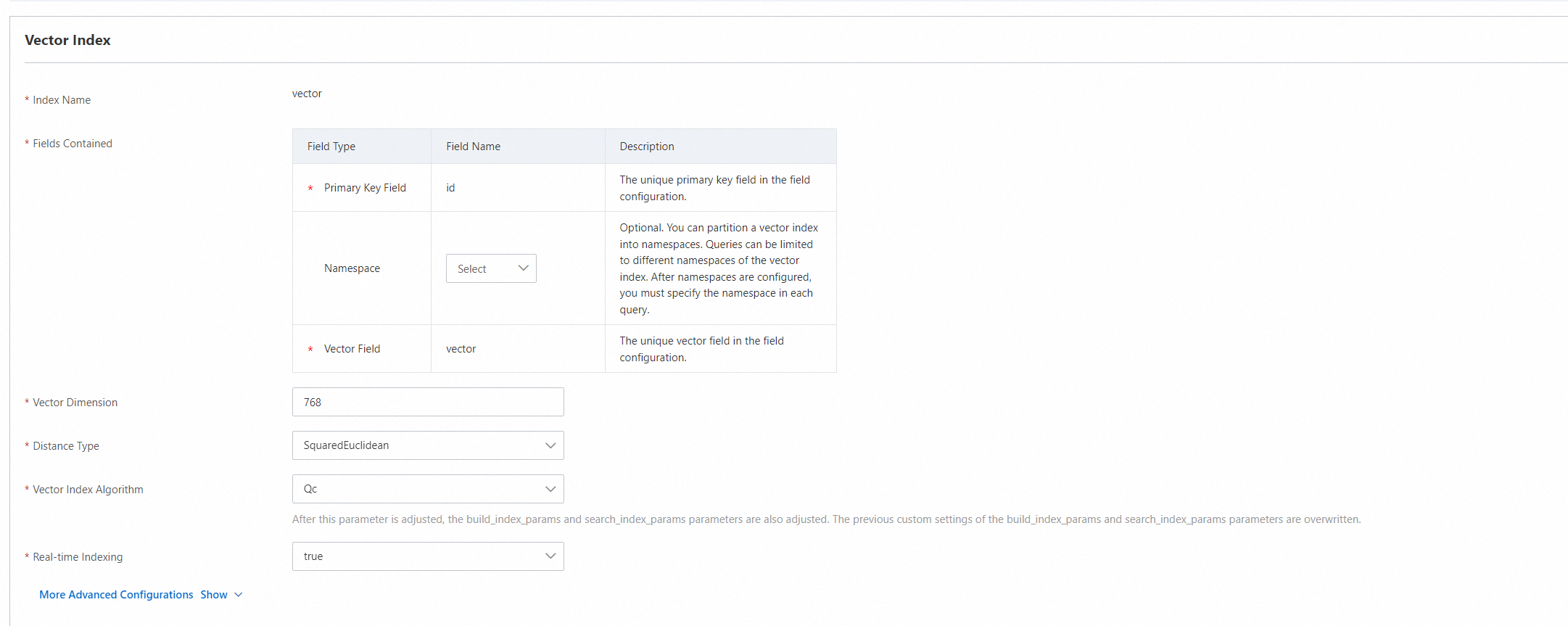
The primary key field and vector field are required. The namespace field is optional and can be left empty.
Namespace field: If the engine version of the instance is vector_service_1.0.2 or earlier, the namespace field cannot be of the STRING type. If the engine version of the instance is vector_service_1.0.2 or later, no limit is imposed on the field type.
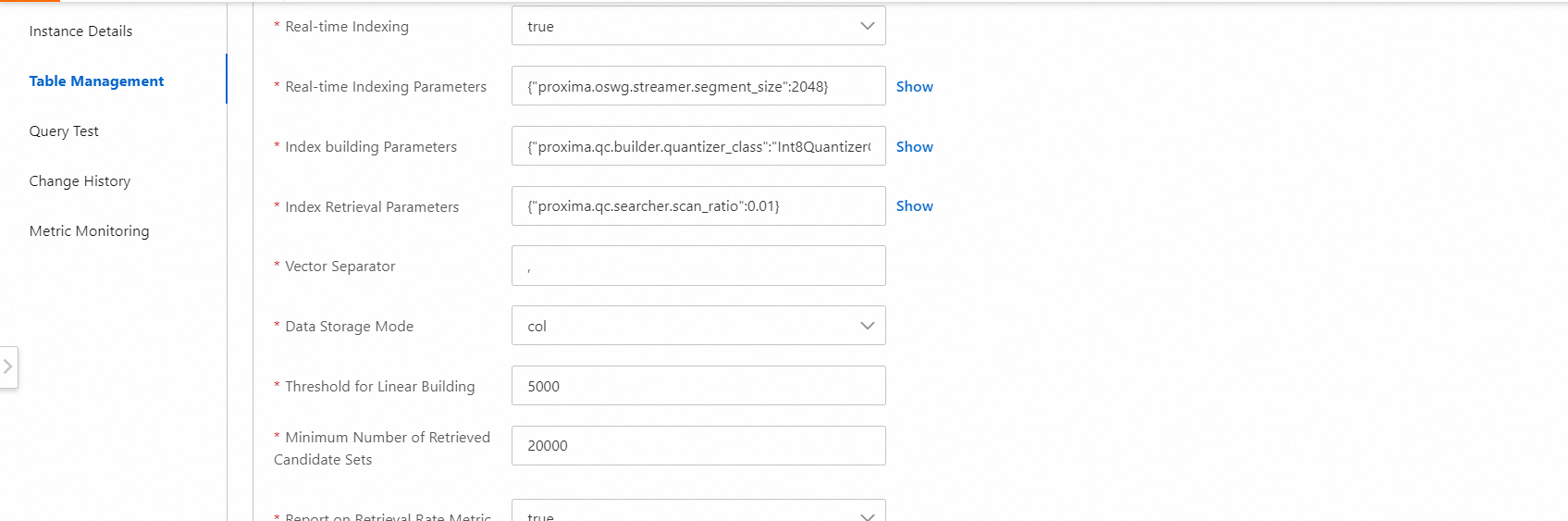
The system automatically configures parameters for the advanced configurations of the vector index. We recommend that you set the Vector Dimension parameter to 768 and do not modify other parameter settings.
5. Confirm the creation
In the Confirm step, click Confirm.
6. View the change history
In the left-side pane on the instance details page, click Change History. On the Data Source Changes tab of the page that appears, you can view all finite-state machines (FSMs) related to the processes of creating a table, creating indexes, and performing reindexing for full data. After the search engine is built, you can run query tests in the instance.
7. Run query tests
Sample query: For more information, see the Prediction-based query section of the "Query data" topic.
Sample results:
{
"totalCount": 5,
"result": [
{
"id": 5,
"score": 1.103209137916565
},
{
"id": 3,
"score": 1.1278988122940064
},
{
"id": 2,
"score": 1.1326735019683838
}
],
"totalTime": 242.615
}result: the returned results.
Syntax
For more information about the syntax for prediction-based queries: Prediction-based query
For more information about the syntax for primary key-based queries: Primary key-based query
For more information about the syntax for filter expressions: Filter expression
Use an SDK to perform vector-based queries
Use an SDK to perform vector-based queries or primary key-based queries. For more information, see Query data.
Use an SDK to add or delete documents. For more information, see Update data.