This topic describes how to create a table for an API data source.
Create a table
Log on to the OpenSearch Vector Search Edition console. In the left-side navigation pane, click Instances. On the Instances page, find the instance for which you want to create a table and click the instance name or ID. On the instance details page, click Table Management in the left-side pane. On the page that appears, click Add Table.
In the Basic Table Information step of the Create wizard, configure the following parameters and click Next.
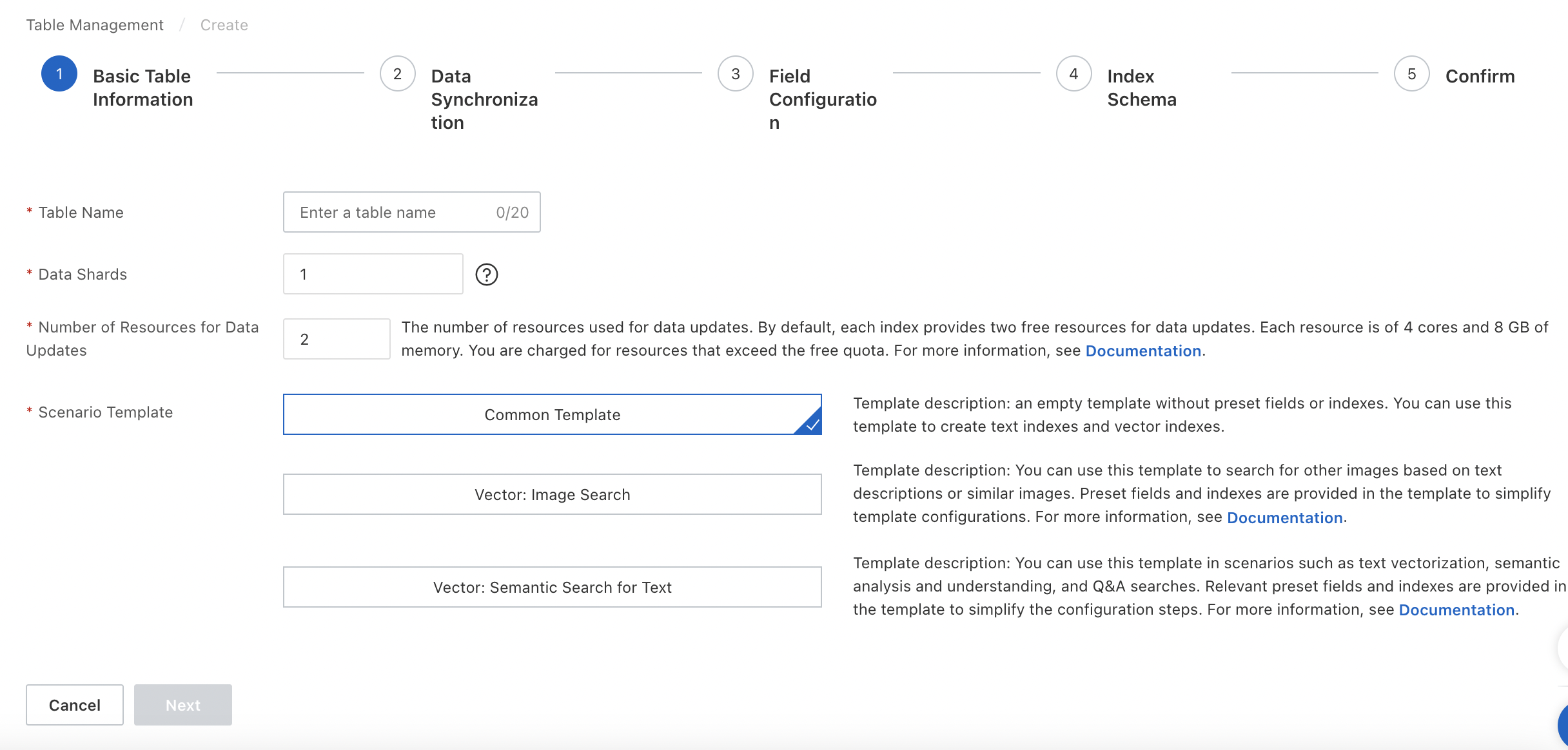
Parameters:
Table Name: the name of the table. You can customize the table name.
Data Shards: the number of data shards contained in the table. If you create multiple index tables in an OpenSearch instance, make sure that the index tables contain the same number of shards. Alternatively, make sure that at least one index table contains one shard and other index tables contain the same number of shards.
Number of Resources for Data Updates: the number of resources used for data updates. By default, OpenSearch provides a free quota of two resources for data updates for each data source in an OpenSearch Vector Search Edition instance. Each resource consists of 4 CPU cores and 8 GB of memory. You are charged for resources that exceed the free quota. For more information, see Billing overview of OpenSearch Vector Search Edition for the international site (alibabacloud.com).
Scenario Template: the template that is used to create the table. Valid values: Common Template, Vector: Image Search, and Vector: Semantic Search for Text.
In the Data Synchronization step, configure a data source and click Next.

Parameters:
Full Data Source: the type of the data source. In this example, API is selected, which indicates that the user data is pushed to the OpenSearch Vector Search Edition instance by using an API.
In the Field Configuration step, configure fields for the table and click Next.
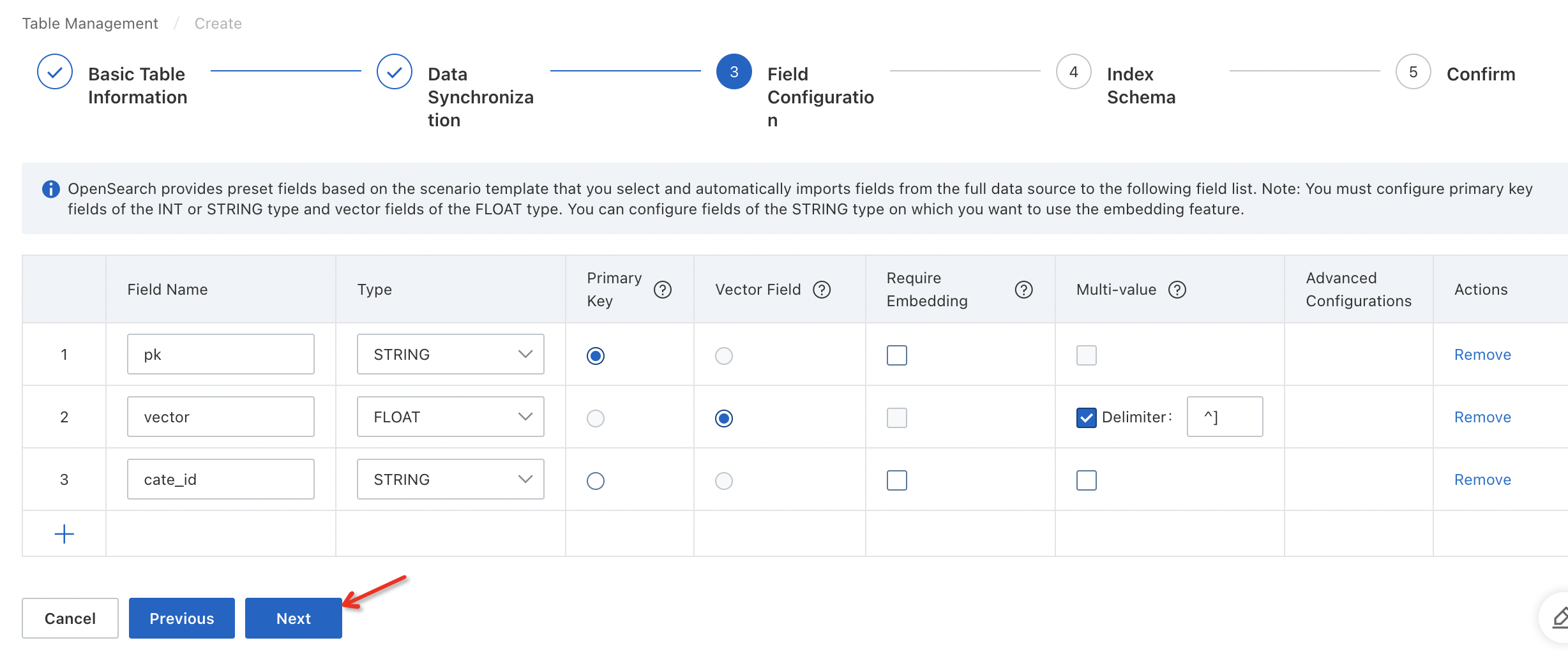
The primary key field and vector field are required. The primary key field must be of the INT or STRING type. The vector field must be of the FLOAT type.
By default, the vector field is a multi-value field of the FLOAT type, and multiple values of the vector field are separated by HA3 delimiters (^]). This delimiter is encoded as \x1D in the UTF format. You can also enter a custom multi-value delimiter.
In the Index Schema step, configure indexes for the table and click Next.
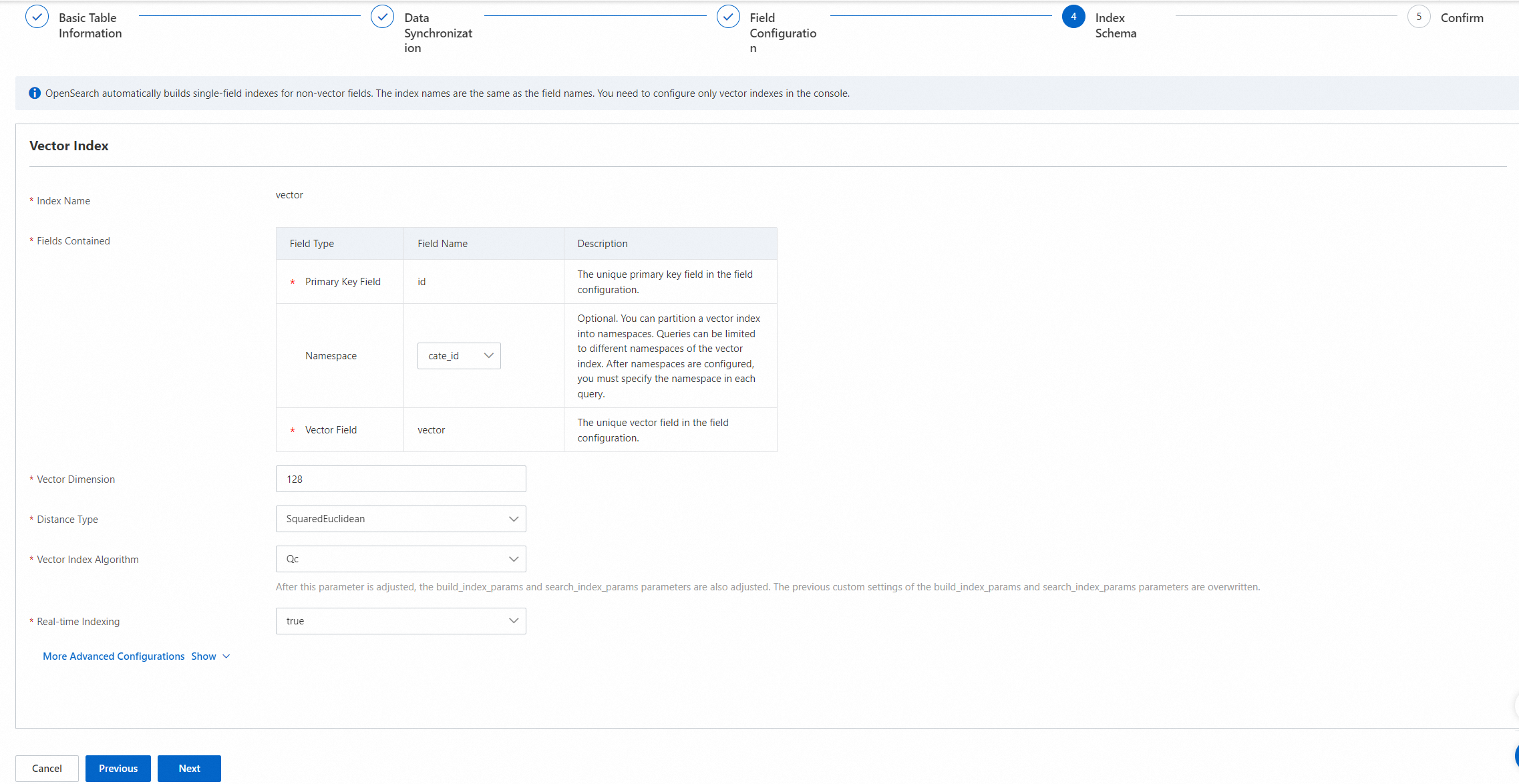
Configure the following parameters in the Vector Index section:
The primary key field and vector field are required. The namespace field is optional and can be left empty.
You can configure only the three fixed fields for the Fields Contained parameter and cannot add fields.
Vector Dimension: the dimension of vectors. Specify a vector dimension based on the vector model that you select.
Distance Type: the type of vector distance. Valid values: SquareEuclidean and InnerProduct. Specify a distance type based on the vector model that you select.
Vector Index Algorithm: the algorithm that is used to create the vector index. Valid values: Qc, Linear, and HNSW. Specify an algorithm based on the vector model that you select.
Real-time Indexing: specifies whether to build real-time indexes for incremental data that is pushed by using API operations. Valid values: true and false. Default value: true.
You can also configure parameters for the advanced configurations of the vector index. For more information, see Common configurations of vector indexes.
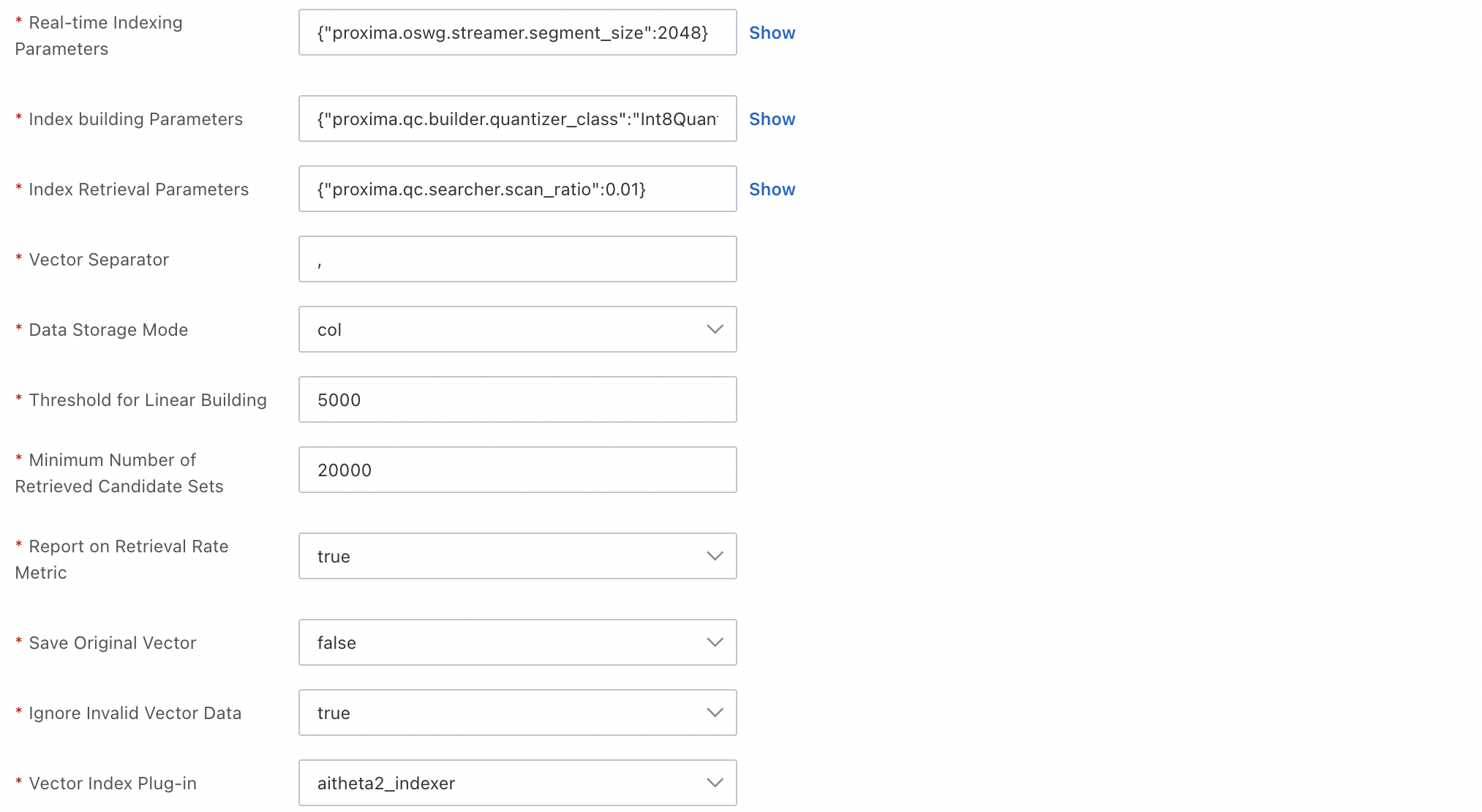
In the Confirm step, click Confirm. The table that you configure is automatically created.
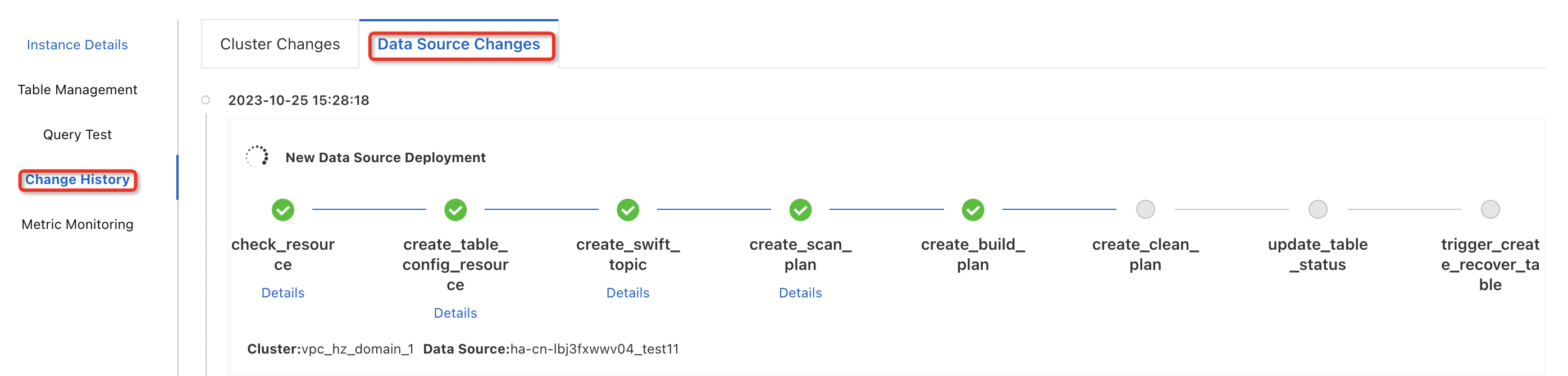
To view the creation progress of the table, click Change History in the left-side pane on the instance details page, and then click the Data Source Changes tab.
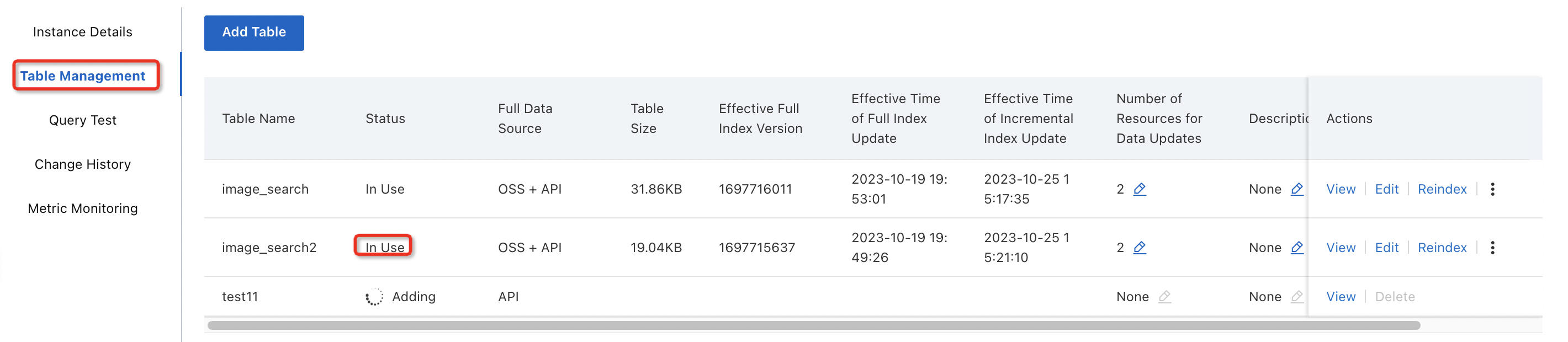
If the table enters the In Use state, you can run query tests on the Query Test page.
Usage notes
When reindexing is performed for an API data source, the system clears the data that is previously synchronized and synchronizes data from the specified timestamp in real time. Proceed with caution.