Prerequisites
You are familiar with MaxCompute that is formerly known as ODPS. For more information about MaxCompute, see What is OpenSearch?
The account that you use to log on to the OpenSearch console is granted the following permissions on the MaxCompute table that you want to configure: the DESCRIBE, SELECT, and DOWNLOAD permissions on the table and the LABEL permission on the fields of the table.
You can execute the following statements to grant the required permissions to an account:
-- Add an account.
add user ****@aliyun.com;
-- Grant the required permissions to the account.
GRANT describe,select,download ON TABLE table_xxx TO USER ****@aliyun.com
GRANT describe,select,download ON TABLE table_xxx_done TO USER ****@aliyun.com
-- If you enable field permission verification for your MaxCompute table, the system prevents you from accessing highly privileged fields when you pull data, and indexes cannot be created for the table. In this case, you must grant your account the permissions to access fields.
-- Grant permissions on the entire project.
SET LABEL 3 to USER ****@aliyun.com
-- Grant permissions on a single table.
GRANT LABEL 3 ON TABLE table_xxx(col1, col2) TO ****@aliyun.comFields contained in your MaxCompute table are of the following data types: STRING, BOOLEAN, DOUBLE, BIGINT, and DATETIME.
For more information about the table creation statement and the parameters for adding a MaxCompute data source, see CREATE TABLE statement for creating a table in a MaxCompute data source.
Configure a MaxCompute data source
1. Log on to the OpenSearch console. In the upper-left corner, select OpenSearch Vector Search Edition. On the Instance Management page, find the instance that you want to manage and click Manage in the Actions column.

In the left-side navigation pane, choose Configuration Center > Data Source. Click Add Data Source. In the panel that appears, select MaxCompute as the data source type and configure the parameters such as Data Source Name, Project, AccessKey ID, AccessKey Secret, Table, Partition Key, and Automatic Reindexing.
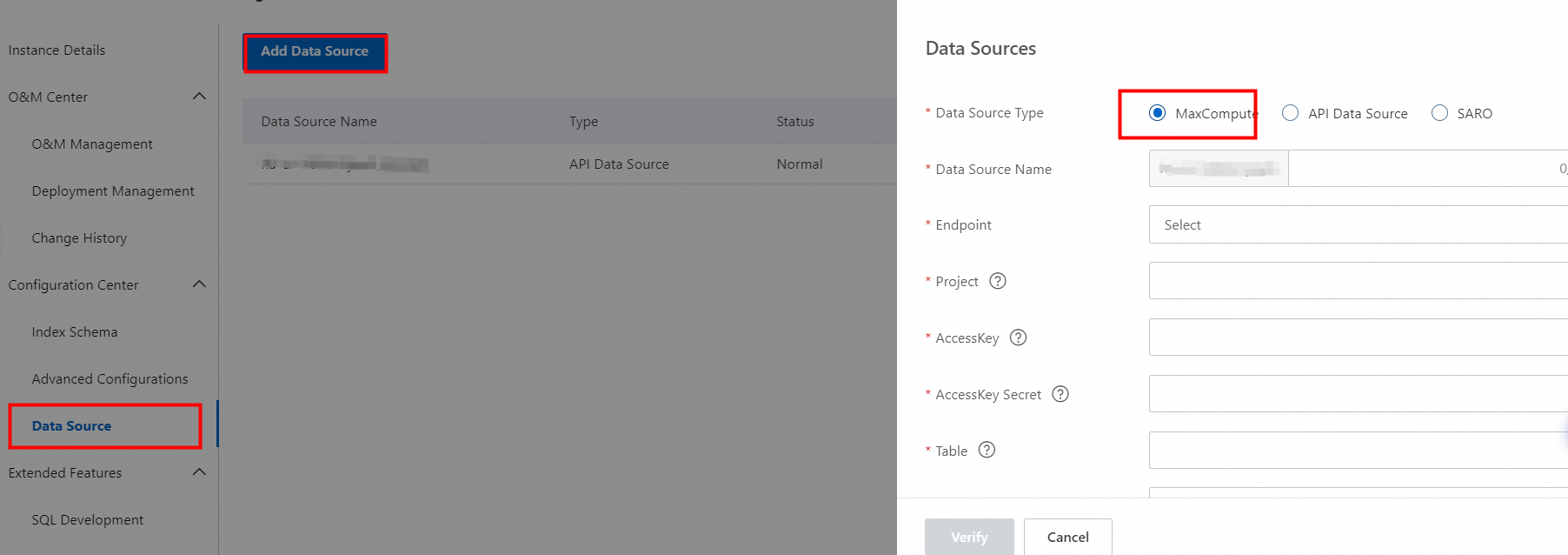
3. After the parameters are configured, click Check. After the configurations pass the check, click OK.
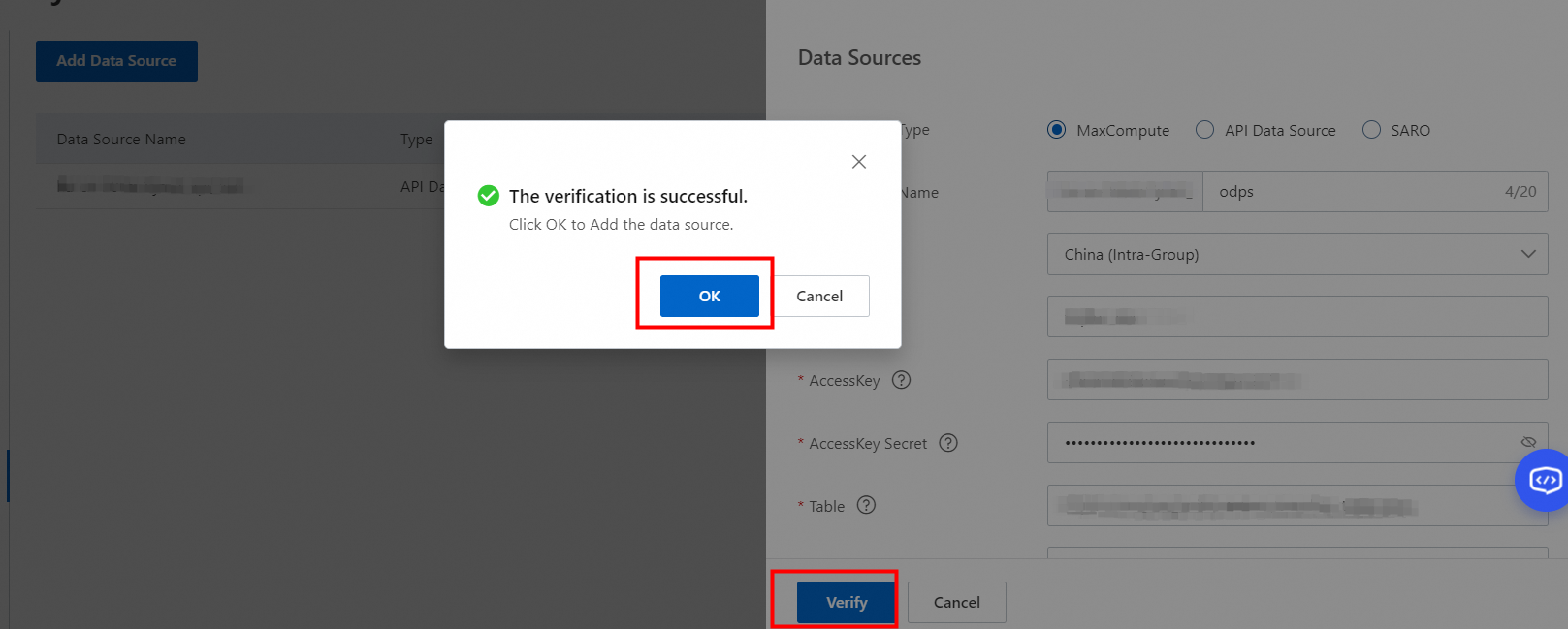
4. After the data source is created, configure an index schema to create an index table for the data source. For more information, see the "Add an index table" section in Index schema.
5. After the index table is configured, update the configurations of the data source and trigger reindexing to ensure that the data source can be used by online clusters. For more information, see Update configurations.
Parameter description
Data Source Name: the name of the data source. Specify the name in the InstanceName_CustomName format.
Project, AccessKey ID, AccessKey Secret, Table, and Partition Key: the parameters that are required to connect to the MaxCompute data source.
Automatic Reindexing: specifies whether to enable the automatic reindexing feature. If the automatic reindexing feature is enabled, the system automatically rebuilds indexes for the index table that references the data source each time the system detects a data change in the data source.
If you enable automatic reindexing, you must create a done table. For more information, see the Configure automatic reindexing section.
Configure automatic reindexing
Description of a done table: If you enable automatic reindexing when you configure a data source, OpenSearch Vector Search Edition automatically rebuilds indexes based on the changes in the done table.
Example: When you configure a MaxCompute data source, you specify mytable as the MaxCompute table and ds=20220113 as the partition. After you configure reindexing for the data source for the first time, the system generates a new partition on a daily basis. Each new partition contains the full data of the table. Each time a new partition is generated, OpenSearch Vector Search Edition is required to scan the new partition and automatically rebuild the indexes based on the data in the new partition. To meet this requirement, you can use the automatic reindexing feature and done table.
Procedure
1. Enable automatic reindexing when you create a data source.

2. Configure the corresponding done table in MaxCompute. If the name of the data table is mytable and the name of the partition key of the data table is ds, the name of the done table is mytable_done and the name of the partition key of the done table is ds. The following code block shows how the two tables are displayed in MaxCompute:
odps:sql:xxx> show tables;
InstanceId: xxx
SQL: .
ALIYUN$****@aliyun.com:mytable # The table that stores the full data of the data source.
ALIYUN$****@aliyun.com:mytable_done # The done table to which full data of the source table is automatically synchronized.The following figure shows the done table.

You can execute the following statement to create the done table:
create table mytable_done (attribute string) partitioned by (ds string);3. When the ds=20220114 partition of the mytable table is generated, configure the done table to trigger OpenSearch Vector Search Edition to rebuild indexes.
-- Add a partition.
alter table mytable_done add if not exists partition (ds="20220114");
-- Insert a semaphore to enable automatic full data synchronization.
insert into table mytable_done partition (ds="20220114") select '{"swift_start_timestamp":1642003200}';The done table contains the following content:
odps:sql:xxx> select * from mytable_done where ds=20220114 limit 1;
InstanceId: xxx
SQL: .
+-----------+----+
| attribute | ds |
+-----------+----+
| {"swift_start_timestamp":1642003200} | 20220114 |
+-----------+----+After the semaphore for automatic full data synchronization is inserted into the done table, OpenSearch Vector Search Edition scans the semaphore of the done table and automatically triggers a reindexing task.
Make sure that you specify at least one partition key for the done table. The name of the partition key of the done table must be the same as the name of the partition key of the data table. If the partition key of the data table is ds, the partition key of the done table must be set to ds.
The done table contains only one field of the STRING data type. The field name must be attribute.
The partition that you add to the done table must exist in the data table. For example, if the data table contains the ds=20220114, ds=20220115, and ds=20220116 partitions, you must select a partition to be added to the done table from the three partitions.
When you insert data into the done table, the value of the attribute field must be a JSON string, such as
{"swift_start_timestamp":1642003200}. The timestamp specifies the start offset for real-time incremental synchronization.
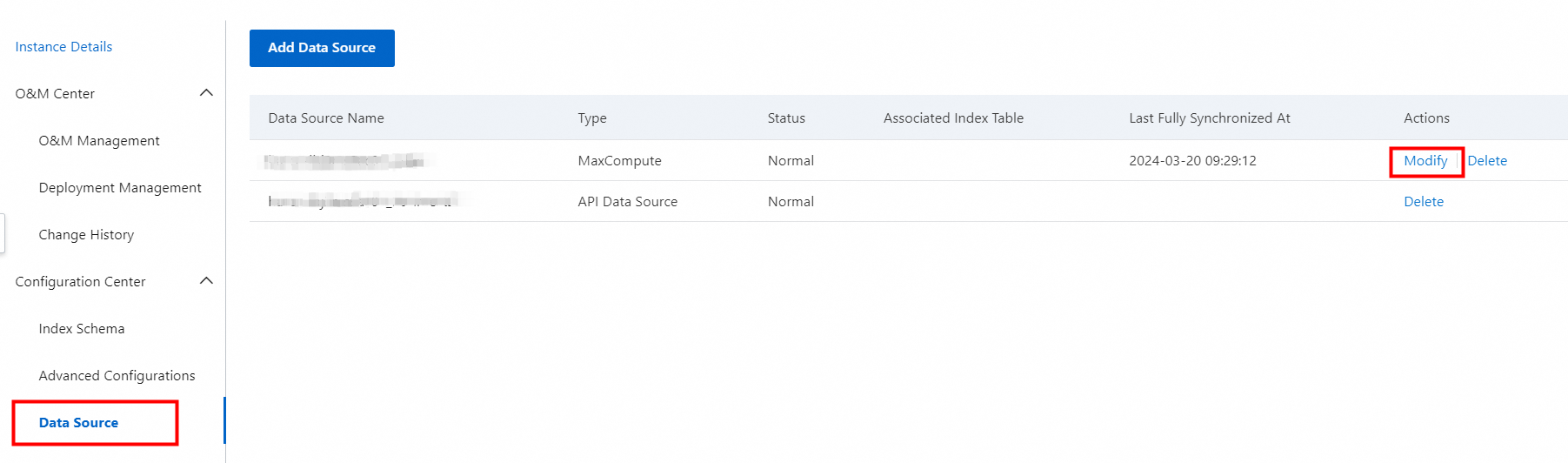
Modify a MaxCompute data source
On the Data Source page, find the data source that you want to modify and click Modify in the Actions column.
In the Modify Data Source panel, modify the parameters such as Project, AccessKey ID, AccessKey Secret, Table, and Partition Key.
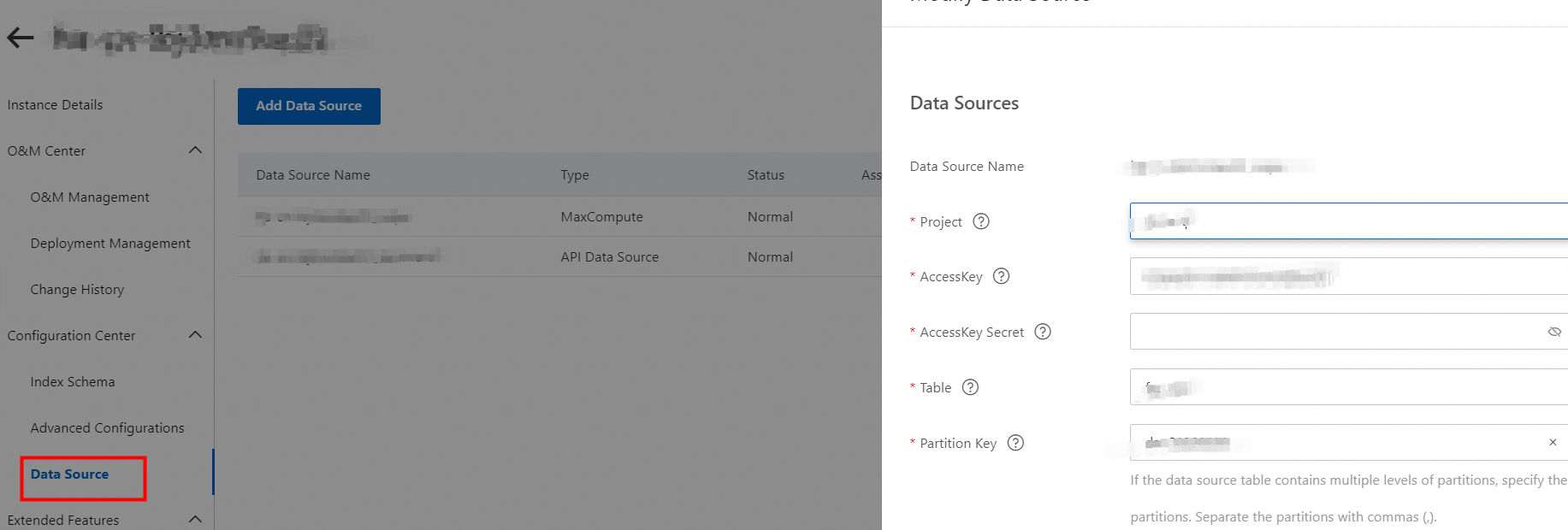
Click Check. After the modified configurations pass the check, click OK to save the modifications.
After the data source is modified, update the configurations of the data source and trigger reindexing to ensure that the data source can be used by online clusters. For more information, see Update configurations.
We recommend that you specify an hourly partition in the format of yyyymmddhh, such as 2022011314. This way, multiple full indexing tasks can be triggered for the data source every day.
Delete a MaxCompute data source
On the Data Source page, find the data source that you want to delete and click Delete in the Actions column.

After you click Delete, the system checks whether the data source is referenced by an index table.
If the data source is not referenced by an index table, click OK to delete the data source. Then, update the configurations of the data source and rebuild the indexes to ensure that the data source is deleted.
If the data source is referenced by an index table, the system returns the following error after you click Delete.

You must delete the index table that references the data source before you delete the data source. For more information, see the "Delete an index table" section in Index schema.
Usage notes
When you modify a data source, you cannot change the name of the data source.
MaxCompute data sources do not support external tables. You must create an internal table.
The table that you specify when you create a MaxCompute data source must be a partitioned table.
You can use the full data of MaxCompute tables as data sources to build indexes in OpenSearch Vector Search Edition and use API data sources to synchronize incremental data in real time.