MaxCompute provides an integrated architecture for near real-time full and incremental data storage and processing based on Delta tables. This architecture can store huge amounts of data, batch process data in an efficient manner, and provide near real-time performance. This architecture is suitable for increasingly complex, near real-time business scenarios. This topic describes how this architecture works and its benefits.
Background information
In less time-sensitive business scenarios, if you need to process a large amount of data at a time, you can directly use MaxCompute to meet business requirements. However, the requirements for near real-time full and incremental data processing in MaxCompute are increasing along with the increasing amounts of data and a broader range of business scenarios. The following figure shows the evolving requirements.
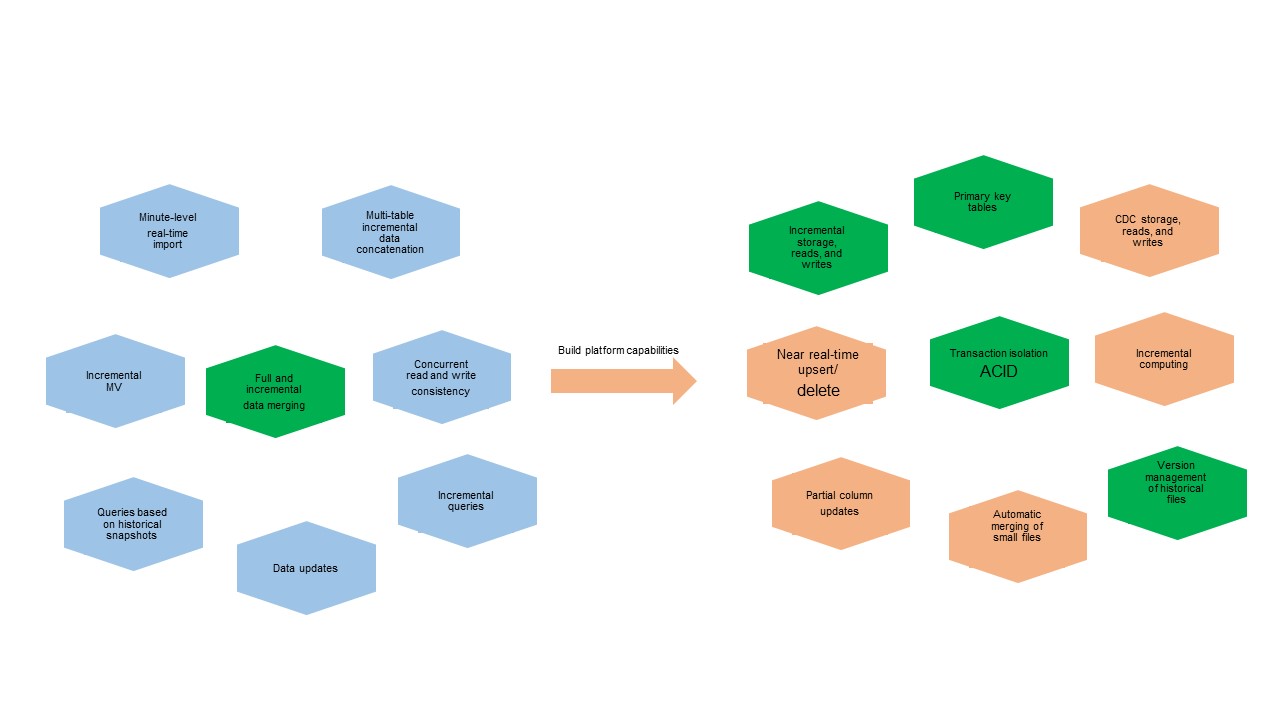
For example, the near real-time data import process requires that the platform engine has capabilities such as transaction isolation and automatic merging of small files. The full and incremental data merging process requires the capabilities to store, read, and write incremental data and use primary keys. Before the integrated architecture is introduced in MaxCompute, the three solutions in the following figure are used in these complex business scenarios. These solutions have their respective disadvantages in terms of cost, ease of use, latency, and throughput, as shown in the following figure.
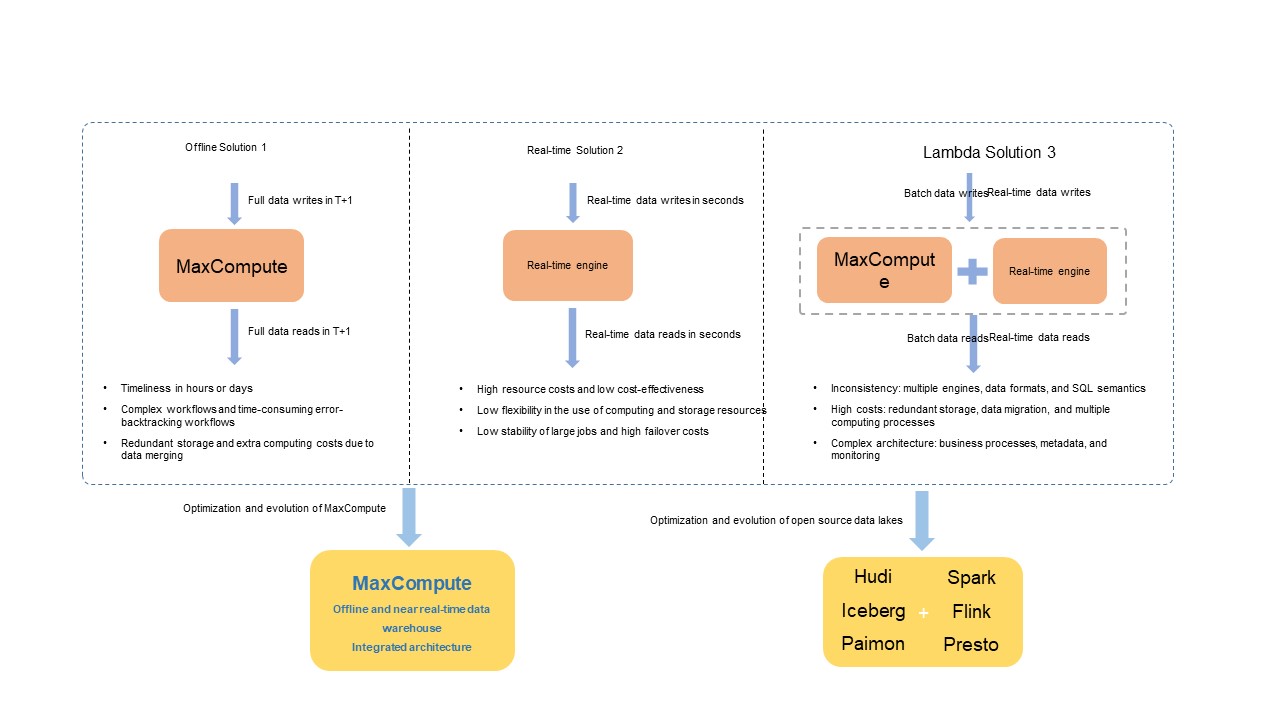
In the big data open source ecosystem, typical solutions such as open source data processing engines are used to resolve the preceding issues. These engines include Spark, Flink, and Trino, and they are deeply integrated with open source data lake formats such as Apache Hudi, Delta Lake, Apache Iceberg, and Apache Paimon. The engines are built on top of open and unified compute engines and data stores to resolve the issues in the Lambda architecture.
Integrated architecture for near real-time full and incremental data storage and processing
To address the preceding issues, MaxCompute provides an integrated architecture for near real-time full and incremental data storage and processing. This architecture supports a wide range of data sources and allows you to import full and incremental data to a specific storage service by using custom development tools. In this architecture, the backend data management service automatically optimizes and orchestrates the data storage structure. Unified compute engines are used for near real-time incremental data processing and batch data processing. A unified metadata service is also provided to manage the metadata of transactions and files. The following figure shows the integrated architecture.
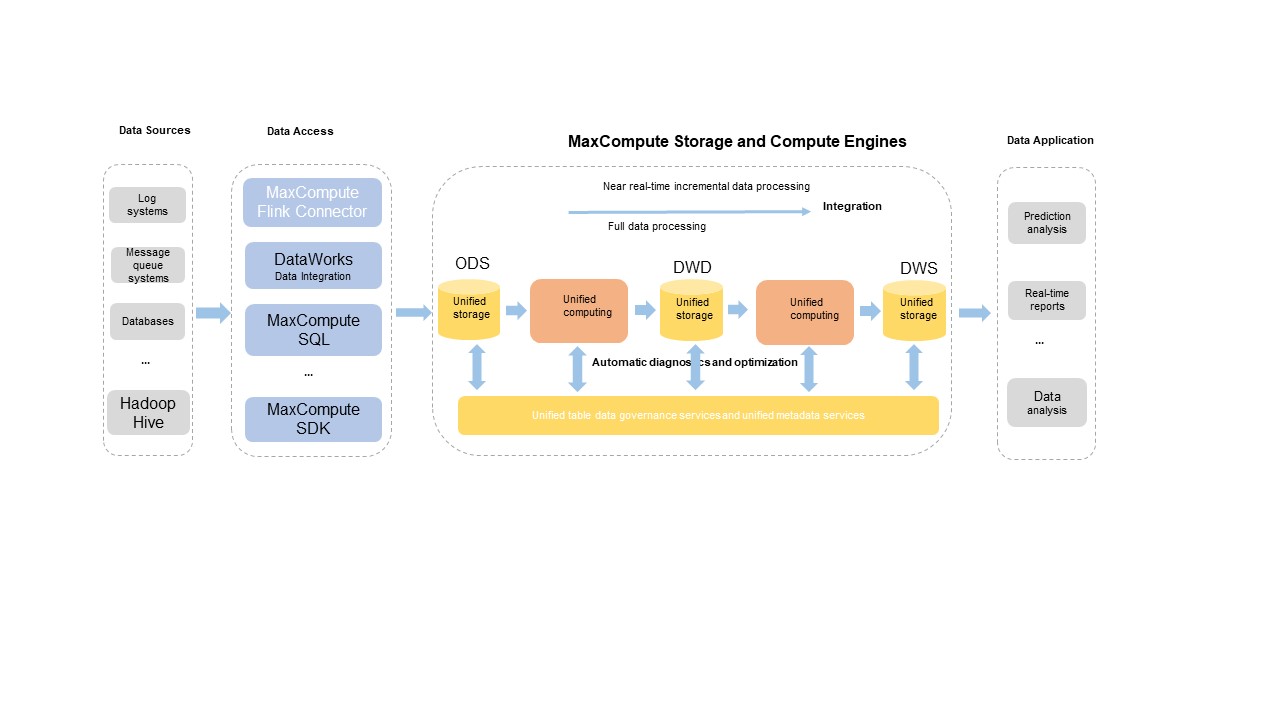
The current integrated architecture supports specific core capabilities, including primary key tables, real-time upserts, time travel queries, incremental queries, SQL data manipulation language (DML) operations, and automatic governance and optimization of table data. For more information about how the integrated architecture works and related operations, see Delta Table overview and Basic operations.
Architecture benefits
The integrated architecture for near real-time full and incremental data storage and processing supports main common features of open source data lake formats such as Apache Hudi and Apache Iceberg to facilitate migration between related business processes. As a new architecture developed by Alibaba Cloud, the integrated architecture also provides distinctive advantages in terms of functionality, performance, stability, and integration:
Uses the unified storage services, metadata services, and compute engines for deep and efficient integration. The integrated architecture provides cost-effective storage, efficient data file management, high query efficiency, and time travel queries on incremental data.
Offers a general-purpose and complete SQL syntax system that is designed to support all core features.
Provides deeply customized and optimized tools for data import in various complex business scenarios.
Seamlessly integrates with existing business scenarios of MaxCompute. This helps reduce the complexity and risks of data migration and the costs of data storage and computing.
Achieves fully automated file management to ensure higher stability and performance of read and write operations. This architecture also automatically optimizes storage efficiency and reduces costs.
Provides a fully managed service based on MaxCompute. This integrated architecture can be used out-of-the-box without additional access costs. You need to only create a Delta table to make the architecture take effect.
Adopts an autonomous and controllable development schedule.
Business scenarios
Table formats and data governance
Table creation

To support the integrated architecture for near real-time full and incremental data storage and processing, MaxCompute introduces Delta tables and uses unified table data formats. The integrated architecture supports all features of existing batch processing workflows and new workflows such as near real-time incremental data storage and processing. The following sample statements show the syntax for creating a table.
CREATE TABLE tt2 (pk BIGINT NOT NULL PRIMARY KEY, val STRING) tblproperties ("transactional"="true");
CREATE TABLE par_tt2 (pk BIGINT NOT NULL PRIMARY KEY, val STRING) PARTITIONED BY (pt STRING) tblproperties ("transactional"="true");When you execute the CREATE TABLE statement to create a Delta table, you need to only specify primary keys and add the configuration "transactional"="true". Primary keys are used to ensure the uniqueness of data rows, and the transactional property is used to configure the atomicity, consistency, isolation, and durability (ACID) transaction mechanism for snapshot isolation of read and write operations. For more information about how to create a table, see Table operations.
Key parameters for Delta tables
For more information about the parameters for Delta tables, see the "Parameters for Delta tables" section in Table operations. Key parameters for Delta tables:
write.bucket.num: The default value is 16. Valid values:
(0, 4096]. This parameter specifies the number of buckets for each partitioned table or non-partitioned table. This parameter also specifies the number of concurrent nodes to which data is written. You can change the value of this parameter for a partitioned table. If partitions are added to a partitioned table, the configuration of this parameter automatically takes effect on the new partitions. You cannot change the value of this parameter for a non-partitioned table.NoteYou can increase the parallelism of data writes and queries by increasing the number of buckets. However, the bucket increase also has a negative impact. Each data file belongs to a bucket. More buckets result in more small files. This further increases storage costs and workloads and decreases the reading efficiency. We recommend that you comply with the following principles to configure the number of buckets:
Conmmon scenarios include non-partitioned tables and partitioned tables: if the data amount is less than 1 GB, we recommend setting the number of buckets between 4 and 16. If the data amount is greater than 1 GB, we recommend keeping the size of data per bucket between 128 MB and 256 MB. If the data amount exceeds 1 TB, we recommend adjusting the data range of each bucket to between 500 MB and 1 GB.
Partitioned recommendations for large partitions incremental tables:
If a table has a large number of partitions (more than 500) but a small amount of data, such as a few dozen megabytes, is stored in each partition, we recommend that you configure one or two buckets in each partition to prevent excessive small files from being generated.
acid.data.retain.hours: The default value is 24. Valid values: [0, 168]. This parameter specifies the time range of historical data that you can query by using the time travel query feature. Unit: hours. If you do not need to use the time travel query feature to query historical data, we recommend that you set this parameter to 0. This value indicates that the time travel query feature is disabled. This can significantly reduce the storage costs of historical data. If you need to use the time travel query feature to query historical data older than 168 hours (7 days), you can contact MaxCompute technical support.
We recommend that you set a reasonable time period based on your business scenario. If you set this parameter to a large value, a large amount of historical data is stored, high storage costs are incurred, and queries slow down.
NoteAfter the configured time period elapses, the system automatically reclaims and clears the historical data. After all historical data is cleared, you cannot query the historical data by using the time travel query feature. The reclaimed data includes operation logs and data files.
In special cases, you can run the
purgecommand to forcefully clear historical data.
Schema evolution
Delta tables support complete schema evolution operations, including the addition and deletion of columns. When you query historical data by using the time travel query feature, the system reads data based on the schema of the historical data. Take note that you cannot modify primary keys. The following sample statement shows a schema evolution operation. For more information about the DDL syntax, see Table operations.
ALTER TABLE tt2 ADD columns (val2 string);Table data formats
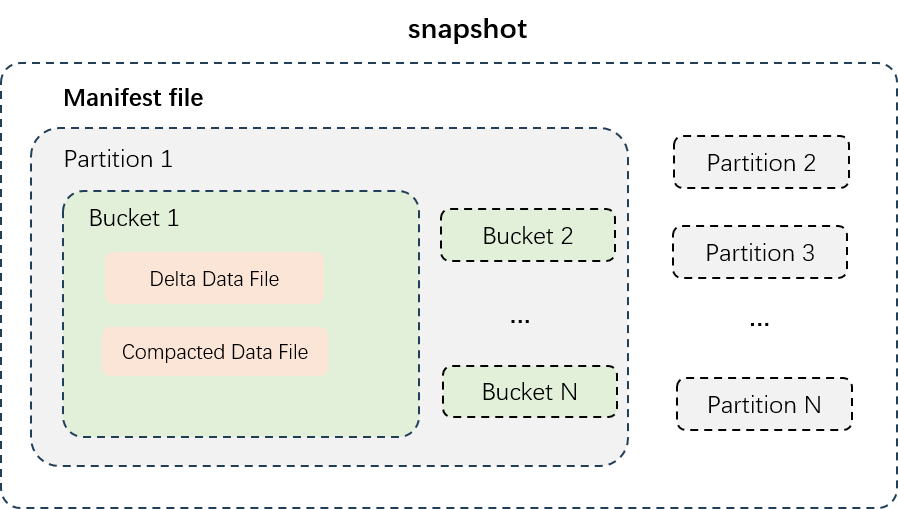
The preceding figure shows the data structure of a partitioned table. Data files are physically isolated by partition, and the data in different partitions is stored in different directories. The data in each partition is split into buckets based on the number of buckets. The data files in each bucket are separately stored. Data files are classified into delta data files and compacted data files.
Delta data files: the incremental data files that are generated after data of each transaction is written or small files are merged. The intermediate historical data of all rows is stored in the Delta data files to meet the requirements for near real-time reads and writes of incremental data.
Compacted data files: the data files that are generated after delta data files are compacted. Compacted data files do not contain the intermediate historical data of all rows. If multiple rows of records have the same primary key, only one row is retained. Compacted data files use column-oriented storage and compression for faster data queries.
Automatic data governance and optimization
Existing issues - Small file bloat
Delta tables support near real-time incremental data import in minutes. In high-traffic real-time write scenarios, the number of small files for incremental data may increase, especially when a large number of buckets exist. This may cause issues such as excessive access requests, high costs, and low I/O efficiency for data reads and writes. If a large amount of data is involved in UPDATE and DELETE operations, a large number of redundant intermediate historical records are generated. This further increases storage and computing costs and decreases query efficiency.
Solutions - Automatic governance and optimization
The MaxCompute storage engine supports reasonable and efficient table data services. The services automatically govern and optimize stored data, reduce storage and computing costs, and improve data processing and analysis performance.
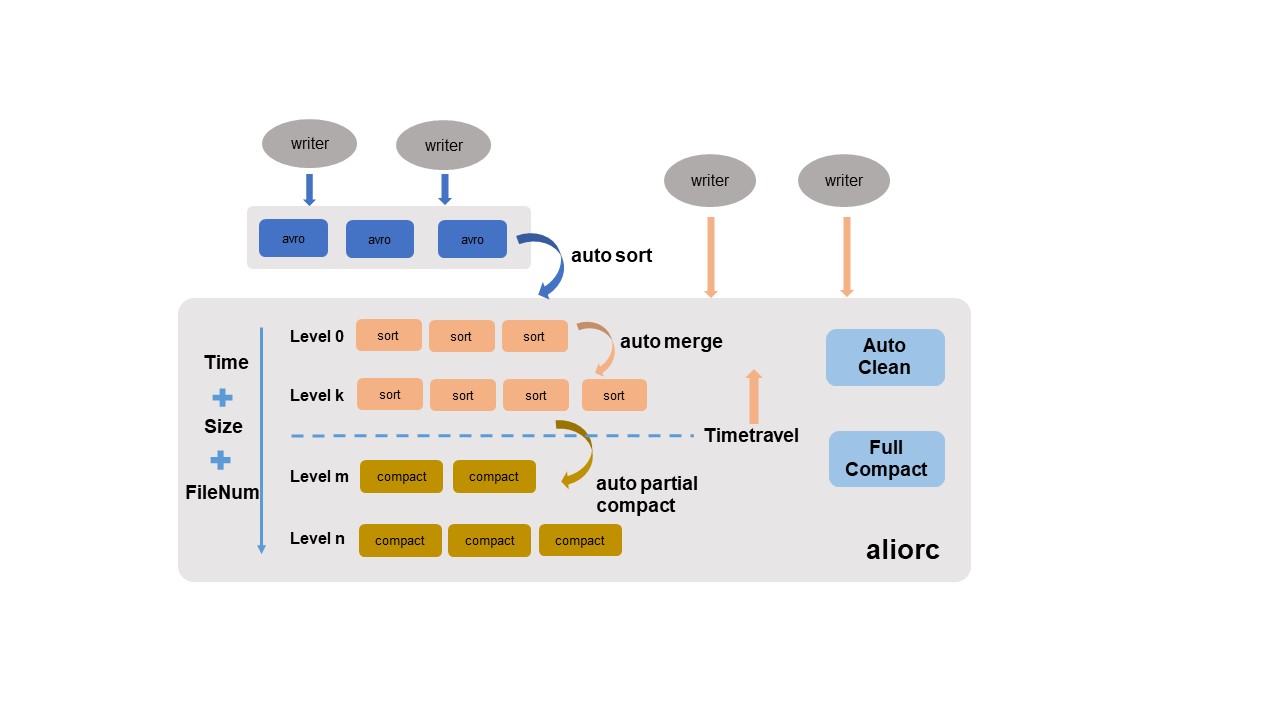
The preceding figure shows the table data services of Delta tables. The services include auto sort, auto merge, auto partial compact, and auto clean. You do not need to manually configure the services. The storage engine service intelligently identifies and automatically collects data from each dimension, and allows you to configure policies for automatic execution.
Auto sort: Converts row-oriented Avro files that are written in real time into column-oriented AliORC files. This significantly reduces storage costs and improves data read performance.
Auto merge: Automatically merges small files to resolve the issues caused by an increase of the number of small files.
The main policy is to periodically perform comprehensive analysis from multiple aspects such as the size, quantity, and write time series of files, and then merge the files based on their levels. The intermediate historical data of all records are not cleared in this process. This ensures the integrity and traceability of time travel queries.
Auto partial compact: Automatically merges files and clears the historical data of records. This helps reduce additional storage costs caused by excessive UPDATE and DELETE operations on records and improves read efficiency.
The main policy is to periodically perform comprehensive analysis from multiple aspects such as the incremental data size, write time series, and time of time travel queries, and then perform compact operations.
NoteThis operation compacts only the historical records whose creation time is beyond the time range of time travel queries.
Auto clean: Automatically clears invalid files to reduce storage costs. After the auto sort, auto merge, and auto partial compact operations are performed and new data files are generated, the original data files become invalid. The system starts to automatically delete the original files in real time. This helps save storage space and reduce storage costs in a timely manner.
In scenarios that require high query performance, you can manually trigger the major compact operation for full data. For more information, see COMPACTION.
SET odps.merge.task.mode=service; ALTER TABLE tt2 compact major;NoteThis operation consolidates all information in each bucket, completely clears all historical data, and generates column-oriented AliORC files. However, this operation generates additional execution overheads and increases the storage costs of new files. We recommend that you perform the operation only when necessary.
Data writes
Near real-time upserts in minutes
In terms of batch data processing, MaxCompute allows you to import incremental data to a new table or partition in minutes or days. Then, you can configure an offline extract, transform, and load (ETL) process, and perform join and merge operations on incremental data and existing table data to generate new full data. This offline process has a long latency and consumes resources and storage space.
In the integrated architecture for near real-time full and incremental data storage and processing, the real-time upsert process can maintain a latency of 5 to 10 minutes from data writes to queries. This meets the requirements for near real-time data processing in minutes. In addition, complex ETL processes for merge operations are not required. This helps reduce computing and storage costs. In actual business data processing scenarios, a variety of data sources are involved, such as databases, log systems, or message queue systems. To facilitate data writes to Delta tables, MaxCompute provides the open source Flink connector plug-in that can work with DataWorks Data Integration and other data import tools to apply custom design and development optimization for scenarios such as high concurrency, fault tolerance, and transaction submission. This can achieve low latency and high accuracy.
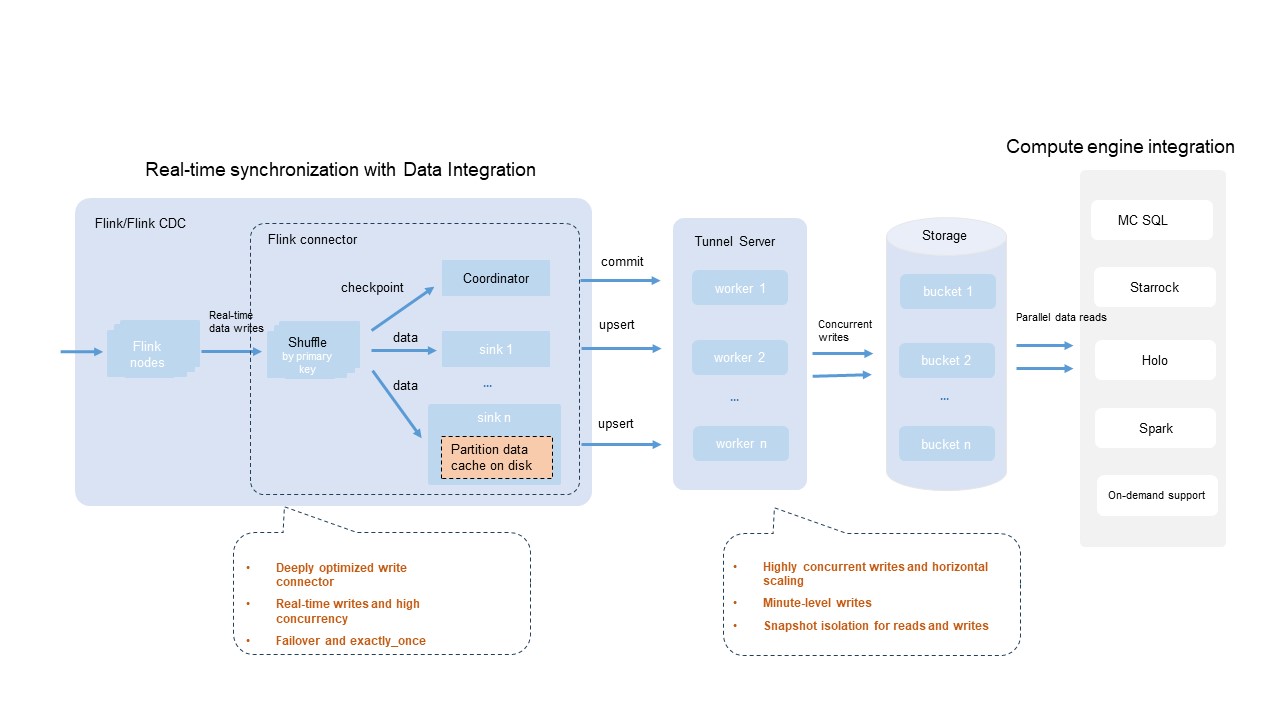
As shown in the preceding figure:
Most compute engines and tools that are compatible with the Flink ecosystem allow you to configure Flink deployments to efficiently use the MaxCompute Flink connector to write data to Delta tables in real time.
You can adjust the write.bucket.num parameter for Delta tables to flexibly configure the write parallelism. This helps speed up write operations.
MaxCompute is efficiently optimized. If you set the write.bucket.num parameter for a Delta table to an integer multiple of the Flink sink parallelism, MaxCompute provides the best write performance.
You can use the built-in checkpoint mechanism of Flink to implement fault tolerance. This ensures that the data processing follows the exactly_once semantics.
You can write data to thousands of partitions at the same time. This meets the requirements for concurrently writing data to a large number of partitions.
The data is visible in minutes and snapshot isolation is supported for read and write operations.
Different environments and configurations may adversely affect the traffic throughput. You can estimate the maximum traffic throughput based on the processing capability (1 MB/s) of a single bucket. For MaxCompute Tunnel, the shared Tunnel resource group is used by default. This may cause unstable throughputs especially when intense resource competition occurs. Limits are also imposed on resource consumption.
Real-time data synchronization from databases - DataWorks Data Integration
Database systems and big data processing engines are tailored to different data processing scenarios. To meet complex business requirements, you need to use online transaction processing (OLTP), online analytical processing (OLAP), and offline analysis engines together to perform comprehensive and in-depth data analysis and processing. In this case, data needs to be transferred among different engines. A typical business process is to seamlessly synchronize new records in a single table or in an entire database to MaxCompute in real time for data processing and analysis.
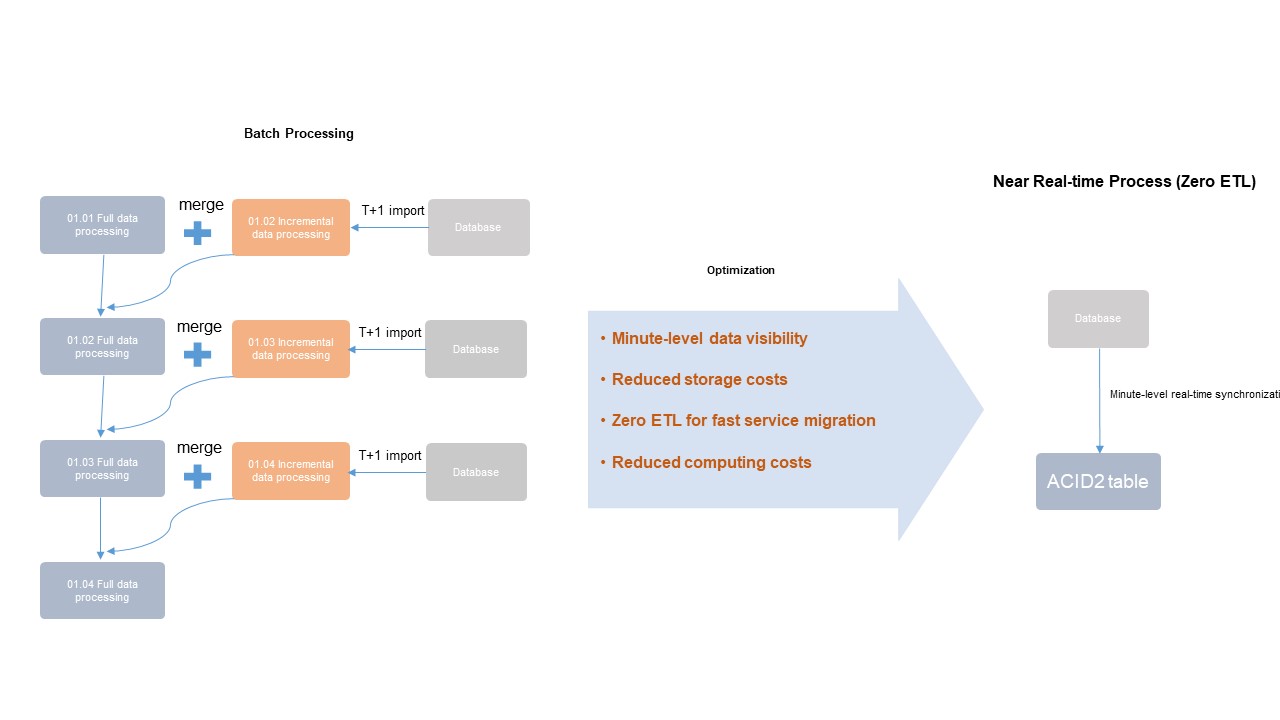
In the preceding figure:
The left workflow shows the architecture of batch data processing in MaxCompute. In most cases, incremental data is imported to a new table or partition at a time in hours or days. Then, a specified offline ETL process is triggered to perform join and merge operations on incremental data and existing table data to generate new full data. This offline process has a long latency and consumes resources and storage space.
The right workflow shows the integrated architecture for near real-time full and incremental data storage and processing. Compared with the batch processing architecture in MaxCompute, periodic data extraction and merging are not required in the integrated architecture, and new records are read from databases in minutes. You can update data only by using Delta tables. This minimizes computing and storage costs.
Batch processing by using SQL DML statements and upserts
The Compiler, Optimizer, and Runtime modules in the SQL engine are modified and optimized for MaxCompute to facilitate operations on Delta tables and complex data queries and operations. Features such as the parsing of a specific syntax, optimization plans, primary key-based deduplication logic, and runtime upserts are implemented to provide full support for the SQL syntax. The following figure shows the implementation logic.
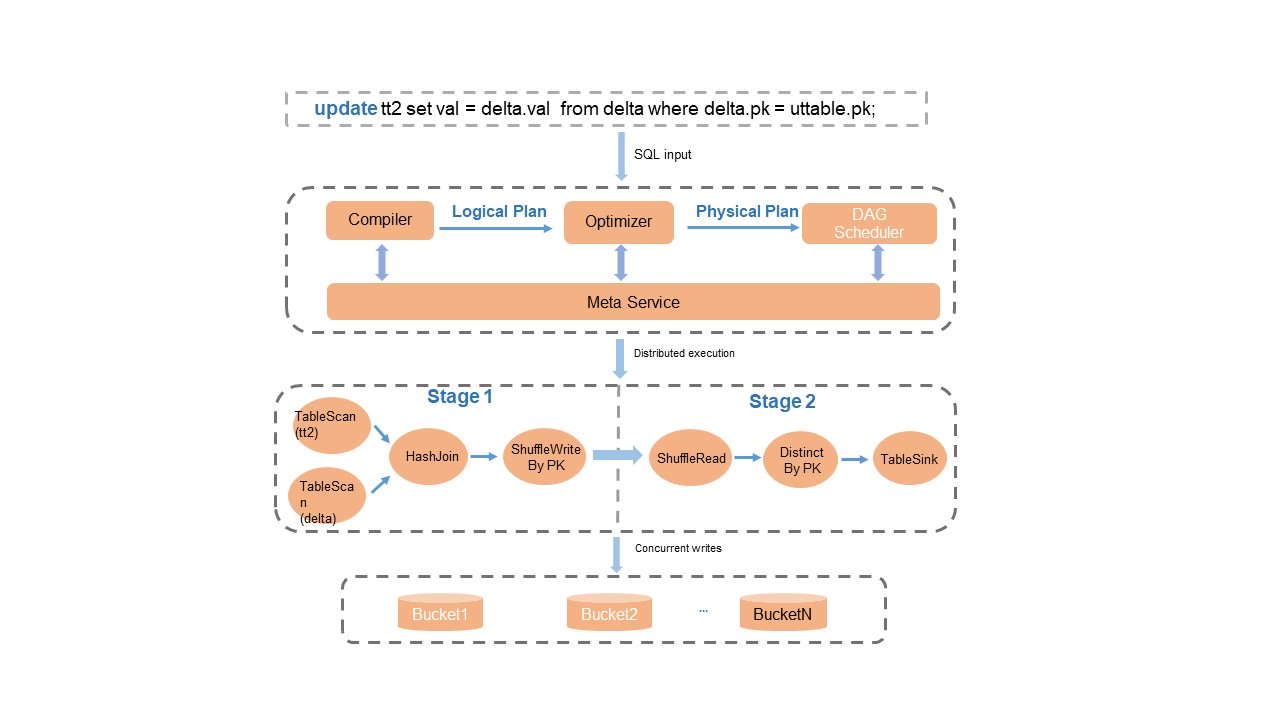
Take note of the following items:
After data processing is complete, the metadata service performs operations such as transaction conflict detection and atomic updates on metadata in data files to ensure the isolation of read and write operations and transaction consistency.
In terms of upserts, the system automatically merges records based on primary keys during queries on Delta tables. Therefore, you do not need to use the complex syntax of UPDATE and MERGE INTO for scenarios in which INSERT and UPDATE operations are involved. Instead, you can use INSERT INTO to insert new data. This reduces read I/O overheads and saves computing resources. For more information about the SQL DML syntax, see DML operations.
Data queries
Time travel queries
The MaxCompute Delta table compute engine is suitable for typical business scenarios in which the time travel query feature is enabled. If you enable the time travel query feature, you can query data of historical versions. This feature can be used to backtrack historical business data or restore historical data for data correction when data errors occur. You can also directly use the restore operation to restore data to a specified historical version. The following statements show examples.
// Query the historical data with a specified timestamp.
SELECT * FROM tt2 TIMESTAMP AS OF '2024-04-01 01:00:00';
// Query the historical data that are generated 5 minutes before the query time.
SELECT * FROM tt2 TIMESTAMP AS OF CURRENT_TIMESTAMP() - 300;
// Query the historical data that is written for the last second commit.
SELECT * FROM tt2 TIMESTAMP AS OF GET_LATEST_TIMESTAMP('tt2', 2);The following figure shows how to perform a time travel query.
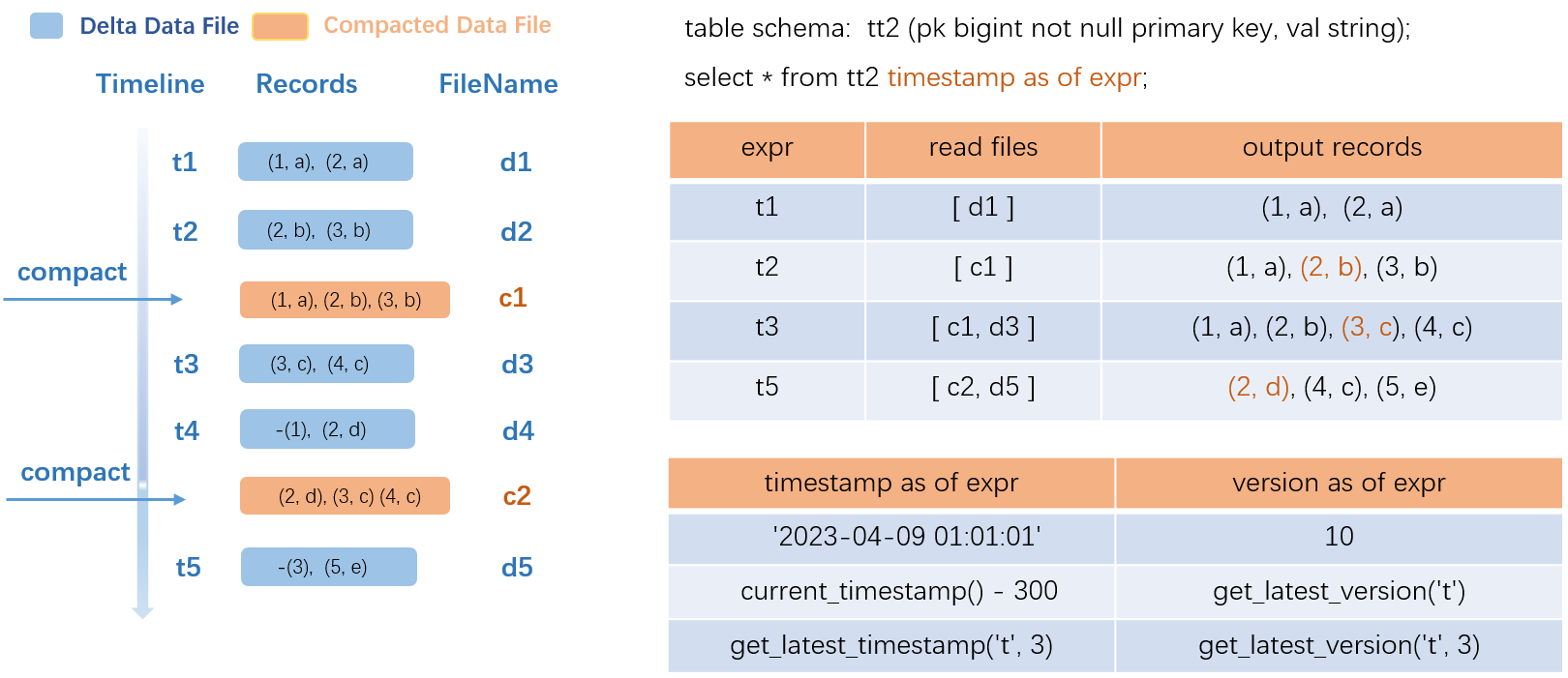
After you enter a time travel query statement, the system parses the historical data version from the metadata service, obtains the compacted data files and delta data files from which you want to read data, and then merges data for output. Compacted data files can be used to accelerate queries and improve read efficiency.
The preceding figure uses a transactional table named src as an example.
The left side of the figure shows the data update process. t1 to t5 represent the time versions of five transactions. Five data write transactions are executed, and five delta data files are generated. At t2 and t4, COMPACTION operations are executed, and two compacted data files named c1 and c2 are generated. In the c1 file, the intermediate historical record
(2,a)is deleted and the latest record(2,b)is retained.To query the historical data at t1, the system reads data from only the delta data file d1 and returns the output. To query the historical data at t2, the system reads data from only the compacted data file c1 and returns three output records. To query the historical data at t3, the system returns data in the compacted data file c1 and the delta data file d3 and merges the data for output. You can apply the same rules to obtain query results at other time points. If you use compacted data files, queries are accelerated but COMPACTION operations are frequently triggered. You need to select an appropriate trigger policy based on your business requirements.
In the SQL syntax, you can directly specify constants and common functions. You can also use the TIMESTAMP AS OF expr and VERSION AS OF expr functions to perform precise queries.
Incremental queries
To optimize incremental queries and incremental computing for Delta tables, MaxCompute designs and develops a new SQL incremental query syntax. For more information about the incremental query syntax, see the "Parameters and limits of incremental queries" section in Time travel queries and incremental queries. The following figure shows the incremental query process.

After you enter SQL statements, the MaxCompute engine parses the historical incremental data versions to be queried, obtains the compacted data files to be read, merges the file data, and then returns the output result. The preceding figure uses a transactional table named src as an example.
The left side of the figure shows the data update process. t1 to t5 represent the time versions of five transactions. Five data write transactions are executed, and five compacted data files are generated. At t2 and t4, COMPACTION operations are executed, and two compacted data files named c1 and c2 are generated.
For example, if begin is t1-1 and end is t1, the system reads data from only the delta data file d1 at t1 for output. If end is t2, the system reads two delta data files d1 and d2. If begin is t1 and end is t2-1, the query time range is from t1 to t2. No incremental data is inserted in the time range. As a result, empty rows are returned.
The data in the c1 and c2 files generated by the compaction and merge operations is not considered as new data for output.
Optimized primary key-based data skipping
The data distribution and indexes of Delta tables are basically built based on primary key column values. When you query data from Delta tables, you can filter data based on a specific primary key value. This can significantly reduce the amount of data to be read, accelerate queries, and greatly reduce resource consumption. Query efficiency may be improved by hundreds to thousands of times. The optimized primary key-based data skipping process covers multiple levels of precise filtering to efficiently locate and read data with a specified primary key value. For example, a Delta table contains 100 million data records. You can filter the table data based on a primary key value. After the filtering, only 10,000 data records may need to be read from the table. The following figure shows the data query process.
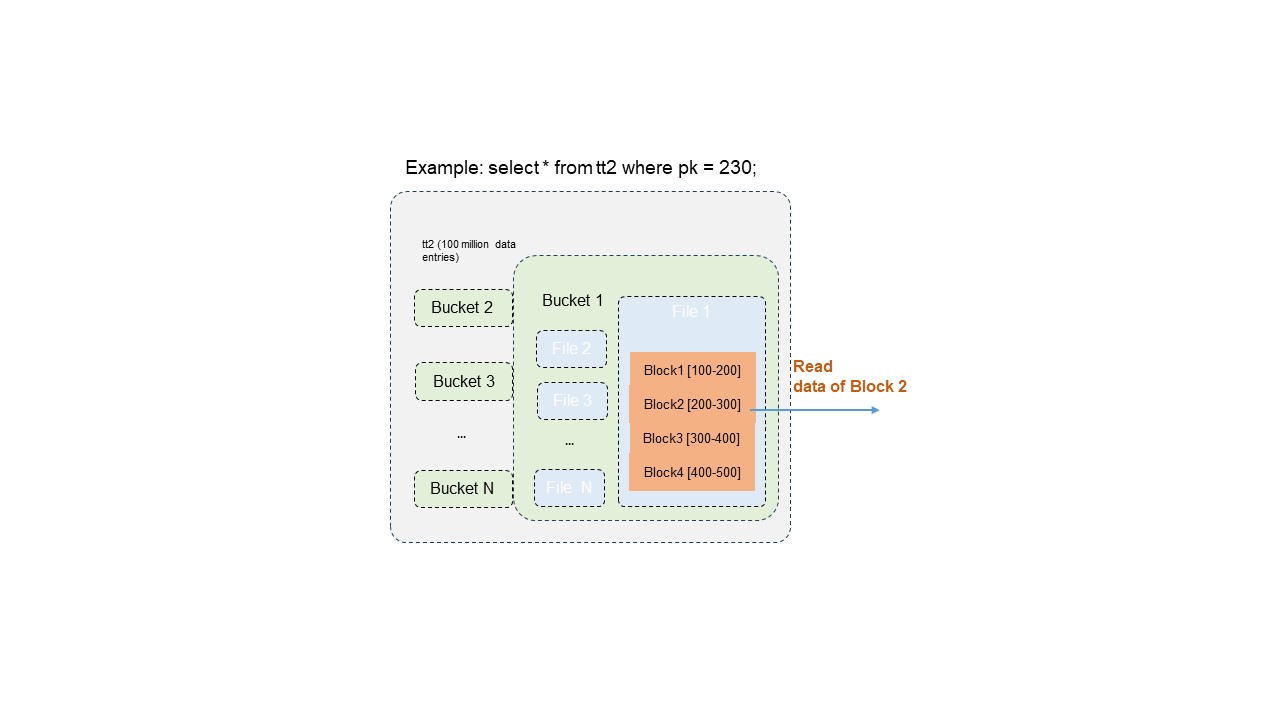
Procedure:
Bucket pruning: The system locates the bucket in which the specific primary key value is stored. This eliminates the need to scan data in unnecessary buckets.
Data file pruning: The system further performs filtering to locate the data files that contain the primary key value in the specified bucket. This improves read efficiency.
Block-level primary key value range filtering: The system performs accurate filtering based on the distribution of primary key values of blocks in files. This way, only blocks that contain the specified primary key value can be extracted.
Optimized SQL query and analysis plans
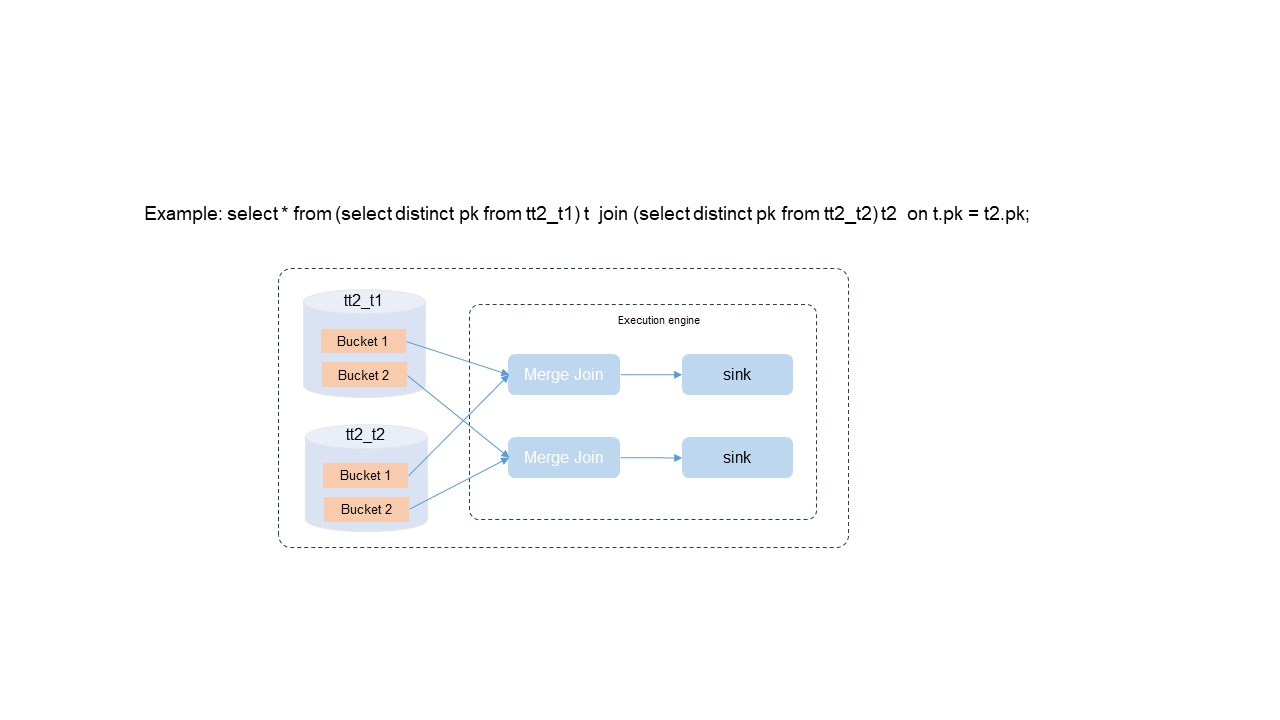
In the preceding figure, the data of a Delta table in specific buckets is processed based on primary key values. The data in each bucket is unique and sorted. The SQL Optimizer module performs optimization from the following aspects:
The DISTINCT operation is not required due to the uniqueness of primary key column values. Due to the uniqueness of the primary key columns in queries, the SQL Optimizer module can identify and skip the DISTINCT operation. This prevents the generation of additional computing overheads.
The bucket local join policy prevents global shuffling. The join key field is the same as the primary key column. The SQL Optimizer module can select the bucket local join policy to prevent global shuffling. This helps greatly alleviate requirements for large-scale data exchanges among nodes, reduces resource consumption, and improves the data processing speed and overall system performance.
Based on the orderliness of data, the merge join algorithm is used instead of the sort operation. The data in each bucket is ordered. The SQL Optimizer module can select an efficient merge join algorithm for join operations without sorting the data in advance. This simplifies data computing and saves computing resources.
After highly resource-consuming operations such as DISTINCT, sorting, and global shuffling are eliminated, the query performance is improved by 100%. This fully reflects the efficient use of the Delta table feature and the significant positive impact of this feature on query efficiency.