To meet business requirements for moderately and highly time-sensitive data in data warehouses, MaxCompute supports real-time data writes and primary key updates within minutes based on Delta tables. This significantly improves the data update efficiency of data warehouses.
Data write scenarios
When you use a traditional relational database or an offline data analysis method to process customer behavior logs related to sudden and hot events, such as comments, ratings, and likes, data can only be analyzed on the next day in most cases. Such scenarios involve issues, such as high resource consumption, high costs, data latency, and complex updates.
To address these issues, you can use the solution that ingests data into data warehouses in real time. This solution helps synchronize incremental data to a Delta table within minutes. This way, the latency from data writing to data query is limited to 5 to 10 minutes. This significantly improves the timeliness of data analysis. If you run a production task to synchronize data to a standard table at the MaxCompute operational data store (ODS) layer, you can use the UPSERT feature of Delta tables to avoid the risk of transforming the production task. This feature can help effectively synchronize data to a Delta table and prevent duplicate data from being stored. This improves storage efficiency and reduces storage costs.

Example
Write Flink data to a Delta table
This topic describes how to write data to a Delta table of MaxCompute in real time by using the Flink connector.
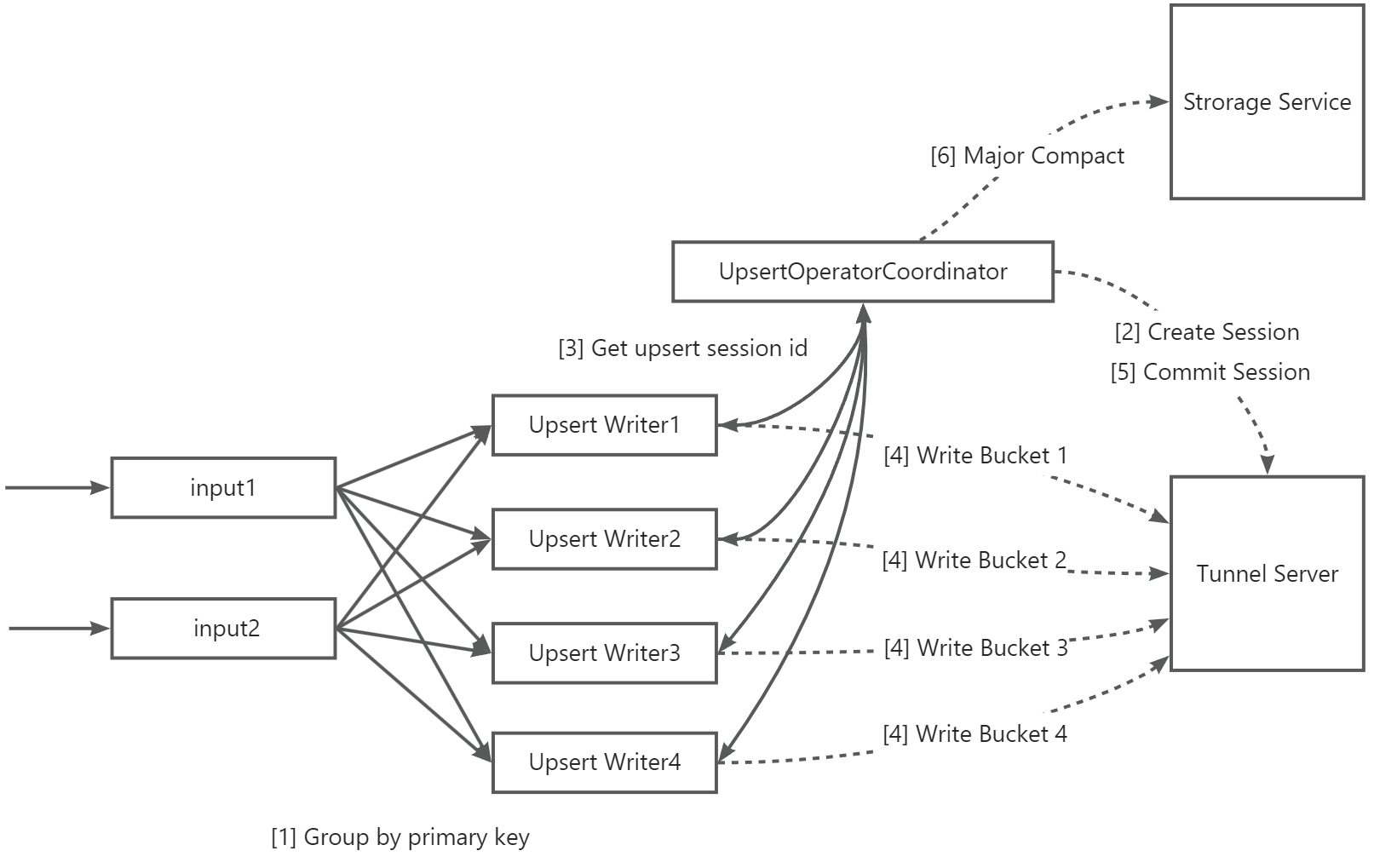
The following table describes the data writing process.
No. | Description |
1 | Data is grouped by primary key and concurrently written to the table. To increase the write throughput, you can also group data by partition key column and write the data to table partitions when the following conditions are met: (1) Data needs to be concurrently written to a large number of partitions. (2) The data is evenly distributed in partitions. (3) The number of buckets for the table is small. For example, less than 10 buckets are configured to store data of the table. |
2 | After UpsertWriterTask receives the data, it parses the partitions to which the data belongs and sends a request to UpsertOperatorCoordinator. Then, UpsertOperatorCoordinator creates an upsert session to write data to the partitions in real time. |
3 | UpsertOperatorCoordinator returns the ID of the created upsert session to UpsertWriterTask. |
4 | UpsertWriterTask creates Upsert Writer based on the upsert session and connects to the Tunnel Server of MaxCompute to continuously write data to the table. If the file cache mode is enabled, data first enters the cache of the local disk of Flink during data transmission. The data is transmitted to the Tunnel Server until the size of the data file reaches a specific threshold or the checkpoint process starts. |
5 | After the checkpoint process is started, Upsert Writer submits all data to the Tunnel Server, and then sends a request to UpsertOperatorCoordinator to trigger the commit operation. After the commit operation succeeds, the data becomes visible. |
6 | If automatic major compaction is enabled, UpsertOperatorCoordinator initiates a major compaction operation to Storage Service when the number of partition commits exceeds a specific threshold. Note This operation may cause a latency for real-time data import based on the size of table data. Therefore, you must use automatic major compaction with caution. |
For more information about how to write Flink data to a Delta table of MaxCompute, see Use Flink to write data to a Delta table.
Parameter configuration suggestions for the UPSERT statement
You can adjust the parameter configuration for the UPSERT statement to improve the system throughput and performance of real-time data writing and ensure system stability to meet different business requirements. For more information about the parameters for the UPSERT statement, see Parameters for the UPSERT statement.
Configurations of common key parameters
The number of buckets for a table affect the maximum write concurrency of the table and may determine the total write throughput. We recommend that you calculate the total write throughput based on the following formula: 1 MB/s × Number of buckets for a table.
The actual throughput that can be achieved is related to specific parameters, such as sink.parallelism. For more information, see Table formats and data governance.
The sink.parallelism parameter specifies the parallelism of sink nodes for data writing. We recommend that you set the number of buckets for a table to an integral multiple of the value of this parameter to achieve better performance. Theoretically, you can achieve optimal performance when the value of the sink.parallelism parameter is the same as the number of buckets for a table.
Parameter configurations for throughput improvement of non-partitioned tables
If the throughput is not improved after you configure the sink.parallelism parameter to increase the write concurrency, the upstream data processing link of the sink node may be inefficient. We recommend that you optimize the data processing link to improve the overall performance.
If the number of buckets for a table is an integral multiple of the value of the sink.parallelism parameter, the number of buckets to which data is written by a single sink node is calculated based on the following formula: Number of buckets for a table/sink.parallelism. If the number of buckets for a table is excessively large, the performance is adversely affected. We recommend that you preferentially adjust the number of buckets for the table and the value of the sink.parallelism parameter. If the value of the upsert.writer.buffer-size parameter divided by the number of buckets to which data is written by a single sink node is less than a specific threshold (such as 128 KB), network transmission efficiency may be reduced. To improve network performance, we recommend that you increase the value of the upsert.writer.buffer-size parameter.
The upsert.flush.concurrent parameter specifies the number of buckets to which data is concurrently flushed. The default value of this parameter is 2. To improve the throughput, you can increase the value of this parameter and observe how the performance improves.
NoteIf you set this parameter to an excessively large value, data may be written to an excessive number of buckets at the same time. This may cause network congestion and reduce the overall throughput. Therefore, you must adjust the value of this parameter to an appropriate value based on your business requirements to ensure stable and efficient operation of the system.
Parameter configurations for increasing the throughput of concurrent writes to a small number of partitions
In this scenario, you can refer to the "Configurations of common key parameters" and "Parameter configurations for throughput improvement of non-partitioned tables" sections. You can also take note of the following points:
Data is written to multiple partitions by a single sink node. During the checkpoint process, data writes to each partition are independently committed. Therefore, the overall write throughput may be affected.
The maximum memory of buffer data for a single sink node is calculated based on the following formula: upsert.writer.buffer-size × Number of partitions. If an out-of-memory (OOM) error occurs, we recommend that you decrease the value of the upsert.writer.buffer-size parameter to prevent memory usage from exceeding the upper limit.
You can increase the value of the upsert.commit.thread-num parameter to reduce the time required for the commit operation during the checkpoint process. The default value of this parameter is 16, which indicates that 16 threads are used to concurrently perform the commit operation for partitions.
NoteYou can increase the value of the upsert.commit.thread-num parameter to improve system performance. However, to avoid issues caused by excessive concurrency, do not increase the value of this parameter to a value greater than 32.
Parameter configurations for increasing the throughput of concurrent writes to a large number of partitions (in file cache mode)
In this scenario, you can refer to the "Parameter configurations for increasing the throughput of concurrent writes to a small number of partitions" section. You can also take note of the following points:
The data of each partition is cached in a local file and then concurrently written to MaxCompute during the checkpoint process.
The default value of the sink.file-cached.writer.num parameter is 16. You can increase the value of this parameter to increase the number of partitions to which data is concurrently written by a single sink node. We recommend that you do not set this parameter to a value greater than 32. We recommend that you set the number of buckets to which data is concurrently written based on the following formula: sink.file-cached.writer.num × upsert.flush.concurrent. However, do not set the sink.file-cached.writer.num parameter to an excessively large value. Otherwise, network congestion may occur and the overall throughput may decrease.
For more information about the parameters for writing data in file cache mode, see Parameters for data writing in file cache mode.
Other suggestions
If the throughput requirements cannot be met or the throughput is unstable after you adjust parameter configurations based on the preceding suggestions, consider the following factors:
The public Tunnel resource groups that can be used free of charge for each project are limited. If the upper limit is reached, data cannot be written. This reduces the overall throughput.
The upstream data processing link of the connector is inefficient, which results in low overall throughput. We recommend that you optimize the data processing link to improve the overall performance.
FAQ
Flink-related issues
Issue 1:
Problem description: The error message "Checkpoint xxx expired before completing" appears.
Cause: The checkpoint process times out. In most cases, this issue occurs because data is written to an excessive number of partitions during the checkpoint process.
Solution:
We recommend that you increase the Flink checkpoint interval.
Configure the sink.file-cached.enable parameter to enable the file cache mode. For more information, see Appendix: Parameters of the Flink connector of the new version.
Issue 2:
Problem description: The error message "org.apache.flink.util.FlinkException: An OperatorEvent from an OperatorCoordinator to a task was lost. Triggering task failover to ensure consistency." appears.
Cause: The communication between the JobManager and a TaskManager is abnormal. The task automatically retries.
Solution: We recommend that you increase the number of task resources to ensure task stability.
Data write issues
Issue 1:
Problem description: An eight-hour time offset occurs after data of the TIMESTAMP type is written to MaxCompute.
Cause: Data of the TIMESTAMP type of Flink does not contain time zone information. In addition, the time zone is not converted when data is written to MaxCompute. Therefore, the data is considered zero time zone data. However, MaxCompute converts the data based on the time zone of the project when MaxCompute reads the data.
Solution: Replace data of the TIMESTAMP type in the MaxCompute sink table with data of the TIMESTAMP_LTZ type.
Tunnel-related issues
Issue 1:
Problem description: A Tengine-related error occurs when data is written. The following error message appears:
<body> <h1>An error occurred.</h1> <p>Sorry, the page you are looking for is currently unavailable.<br/> Please try again later.</p> <p>If you are the system administrator of this resource then you should check the <a href="http://nginx.org/r/error_log">error log</a> for details.</p> <p><em>Faithfully yours, tengine.</em></p> </body> </html>Cause: The Tunnel service is temporarily unavailable.
Solution: Wait until the Tunnel service is restored. Then, the task can successfully retry.
Issue 2:
Problem description: The error message "java.io.IOException: RequestId=xxxxxx, ErrorCode=SlotExceeded, ErrorMessage=Your slot quota is exceeded." appears.
Cause: The write quota exceeds the upper limit. You must reduce the write concurrency or increase the parallelism of exclusive Tunnel resource groups.
Solution:
Decrease the write concurrency to reduce the number of system resources that need to be used.
Increase the parallelism of exclusive Tunnel resource groups to improve the processing capability to meet higher data write requirements.