This topic provides answers to some frequently asked questions about Tunnel commands.
Does the Tunnel Upload command support wildcards or regular expressions?
No, the Tunnel Upload command does not support wildcards or regular expressions.
Is the file size limited when I use the Tunnel Upload command to upload files? Is the size of a data record limited? Are the uploaded files compressed?
No, the file size is not limited when you use the Tunnel Upload command to upload files. However, the upload duration cannot exceed 2 hours. You can estimate the maximum size of the data that can be uploaded based on the upload speed and duration.
The size of a data record cannot exceed 200 MB.
By default, the Tunnel Upload command uploads data after the data is compressed. If the upload bandwidth is sufficient, you can set the -cp parameter to false to disable data compression.
Can I run the Tunnel Upload command to upload multiple data files to the same table or partition at the same time?
Yes, you can run the Tunnel Upload command to upload multiple data files to the same table or partition at the same time.
Can multiple clients upload data to the same table at the same time by using the Tunnel Upload command?
Yes, multiple clients can upload data to the same table at the same time by using the Tunnel Upload command.
When I upload data, do I need to make sure that the destination partition specified in the Tunnel Upload command already exists?
Yes, you must make sure that the destination partition already exists. You can also specify the -acp parameter in the Tunnel Upload command to enable the system to automatically create the destination partition if the specified partition does not exist. The default value of this parameter is False. For more information, see Tunnel commands.
Am I charged based on the size of compressed data when I use the Tunnel Upload command to upload data?
Yes, you are charged based on the size of compressed data when you use the Tunnel Upload command to upload data.
Can I control the upload speed when I use the Tunnel Upload command to upload data?
No, you cannot control the upload speed when you use the Tunnel Upload command to upload data.
How do I accelerate data uploads when I use the Tunnel Upload command to upload data?
If data uploads are time-consuming, you can configure the -threads parameter to slice the data into multiple parts, such as 10 parts, before you upload the data. Sample command:
tunnel upload C:\userlog.txt userlog1 -threads 10 -s false -fd "\u0000" -rd "\n";When I use the Tunnel Upload command to upload data, I configure the Tunnel endpoint of the cloud product interconnection network for my MaxCompute project but the project is connected to the public Tunnel endpoint. Why?
In addition to the endpoints of MaxCompute, you must configure the Tunnel endpoints in the odps_config.ini file of the MaxCompute client. For more information about how to configure Tunnel endpoints, see Endpoints. You do not need to configure Tunnel endpoints for MaxCompute projects in the China (Shanghai) region.
What do I do if an error is returned when I use the Tunnel Upload command to upload data to partitions on DataStudio?
Problem description
When the Tunnel Upload command is used to upload data to partitions on DataStudio, the following error message appears:
FAILED: error occurred while running tunnel command.Cause
DataStudio does not support the Tunnel Upload command.
Solution
Use the visualized data import feature that is provided by DataWorks to upload data. For more information, see Import data to a MaxCompute table.
Why does the upload fail when I use the Tunnel Upload command to upload data that contains line feeds or spaces?
If the data contains line feeds or spaces, you can replace the line feeds and spaces in the data with other delimiters and use the -rd and -fd parameters to specify the new delimiters in the Tunnel Upload command. If you cannot change the row or column delimiters in the data, you can upload the data as a single row and use a user-defined function (UDF) to parse the data.
In the following example, the data contains line feeds. To upload the data, you can use the -rd parameter to specify commas (,) as the column delimiter and use the -fd parameter to specify at signs (@) as the row delimiter.
shopx,x_id,100@
shopy,y_id,200@
shopz,z_id,300@Sample command:
tunnel upload d:\data.txt sale_detail/sale_date=201312,region=hangzhou -s false -rd "," -fd "@";The following result is returned:
+-----------+-------------+-------------+-----------+--------+
| shop_name | customer_id | total_price | sale_date | region |
+-----------+-------------+-------------+-----------+--------+
| shopx | x_id | 100.0 | 201312 | hangzhou |
| shopy | y_id | 200.0 | 201312 | hangzhou |
| shopz | z_id | 300.0 | 201312 | hangzhou |
+-----------+-------------+-------------+-----------+--------+What do I do if an OOM error occurs when I use the Tunnel Upload command to upload data?
The Tunnel Upload command allows you to upload a large amount of data. However, if the row delimiters or column delimiters that you configured are invalid, all data may be considered a single row and cached in memory. As a result, an out of memory (OOM) error occurs.
If an OOM error occurs, you can upload a small amount of data to conduct testing. If the testing is successful based on the delimiters specified by the -td and -fd parameters, you can use the Tunnel Upload command to upload all data.
How do I upload all data files in a folder to a table at a time by using the Tunnel Upload command?
You can use the Tunnel Upload command to upload a single file or all files in a single level-1 directory at a time. For more information, see Usage notes.
For example, if you want to upload all files in the d:\data directory at a time, you can run the following command:
tunnel upload d:\data sale_detail/sale_date=201312,region=hangzhou -s false;How do I use the Tunnel Upload command to upload multiple files in a directory to different partitions in a table at a time?
You can use a shell script to perform this operation. In the following example, a shell script is used with the MaxCompute client to upload files in Windows. The operation in Linux is similar. The shell script contains the following content:
#!/bin/sh
C:/odpscmd_public/bin/odpscmd.bat -e "create table user(data string) partitioned by (dt int);" // Create a partitioned table named user that contains the partition keyword dt. In this example, the MaxCompute client file odpscmd.bat is stored in the C:/odpscmd_public/bin directory. You can change the directory based on your business requirements.
dir=$(ls C:/userlog) // Define the dir variable. This variable specifies the directory in which all files are saved.
pt=0 // The pt variable specifies the value of a partition key column. The initial value of this variable is 0, and the value increases by one each time a file is uploaded. This way, the files are saved to different partitions.
for i in $dir // Define a loop to traverse all files in the C:/userlog directory.
do
let pt=pt+1 // The value of the pt variable increases by one each time a loop ends.
echo $i // Display the file name.
echo $pt // Display the partition name.
C:/odpscmd_public/bin/odpscmd.bat -e "alter table user add partition (dt=$pt);tunnel upload C:/userlog/$i user/dt=$pt -s false -fd "%" -rd "@";" // Use the MaxCompute client odpscmd to create partitions and upload files to the partitions.
done The following figure shows the output of the shell script that is used to upload the userlog1 and userlog2 files.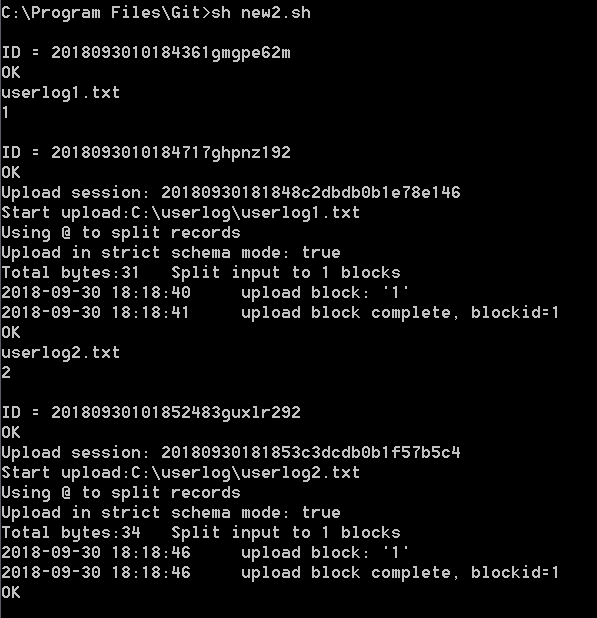
After you upload the files, you can query the data of the table on the MaxCompute client.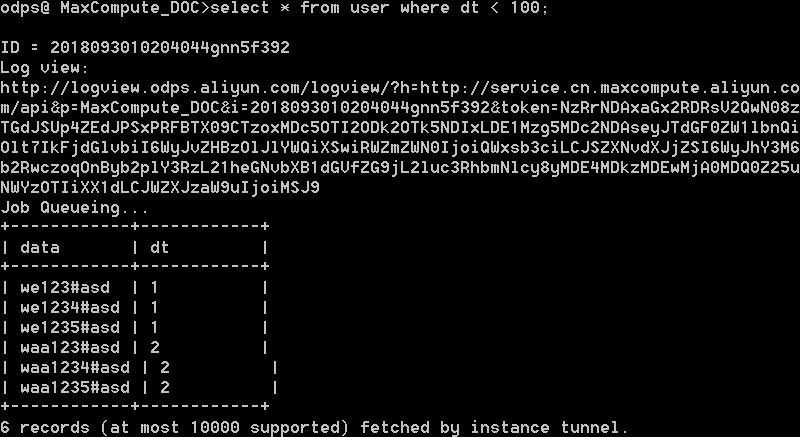
An error is returned when I use the Tunnel Upload command to upload data. Does the Tunnel Upload command provide a parameter that is similar to the -f parameter in MySQL to skip dirty data and continue to upload data?
You can set the -dbr parameter to true in the Tunnel Upload command to skip dirty data. Dirty data is generated when extra columns exist, several columns are missing, or the data types of columns do not match. The default value of the -dbr parameter is false. This value indicates that dirty data is not skipped. If the -dbr parameter is set to true, all data that does not comply with table definitions is skipped. For more information, see Upload.
What do I do if the "You cannot complete the specified operation under the current upload or download status" error message appears when I use the Tunnel Upload command to upload data?
Problem description
When the Tunnel Upload command is used to upload data, the following error message appears:
java.io.IOException: RequestId=XXXXXXXXXXXXXXXXXXXXXXXXX, ErrorCode=StatusConflict, ErrorMessage=You cannot complete the specified operation under the current upload or download status. at com.aliyun.odps.tunnel.io.TunnelRecordWriter.close(TunnelRecordWriter.java:93) at com.xgoods.utils.aliyun.maxcompute.OdpsTunnel.upload(OdpsTunnel.java:92) at com.xgoods.utils.aliyun.maxcompute.OdpsTunnel.upload(OdpsTunnel.java:45) at com.xeshop.task.SaleStatFeedTask.doWork(SaleStatFeedTask.java:119) at com.xgoods.main.AbstractTool.excute(AbstractTool.java:90) at com.xeshop.task.SaleStatFeedTask.main(SaleStatFeedTask.java:305)java.io.IOException: RequestId=XXXXXXXXXXXXXXXXXXXXXXXXX, ErrorCode=StatusConflict, ErrorMessage=You cannot complete the specified operation under the current upload or download status.Cause
The file is being uploaded. You cannot repeatedly perform the upload operation.
Solution
You do not need to repeat the upload operation. Wait until the existing upload task is complete.
What do I do if the "Error writing request body to server" error message appears when I use the Tunnel Upload command to upload data?
Problem description
When the Tunnel Upload command is used to upload data, the following error message appears:
java.io.IOException: Error writing request body to serverCause
This issue occurs when data is uploaded to the server. In most cases, this issue is caused by network disconnections or timeouts during data upload.
If your data source is not a local file and needs to be obtained from data stores, such as a database, the system reads data from the data source before the system can write the data. If you do not upload data within 600 seconds, the upload times out.
If you upload data by using the public endpoint, the upload may time out due to the unstable network performance of the Internet.
Solution
Obtain data and then call Tunnel SDK to upload the data.
You can upload 64 MB to 100 GB of data in a block. To prevent timeouts caused by upload retries, we recommend that you upload a maximum of 10,000 data records in a block. A session supports a maximum of 20,000 blocks. If you want to upload data from Elastic Compute Service (ECS) instances, you must upload data by using endpoints. For more information about endpoints, see Endpoints.
What do I do if the "The specified partition does not exist" error message appears when I use the Tunnel Upload command to upload data?
Problem description
When the Tunnel Upload command is used to upload data, the following error message appears:
ErrorCode=NoSuchPartition, ErrorMessage=The specified partition does not existCause
The partition to which you want to upload data does not exist.
Solution
You can execute the
show partitions table_name;statement to check whether the partition to which you want to upload data exists. If the partition does not exist, execute thealter table table_name add [if not exists] partition partition_specstatement to create a partition.
What do I do if the "Column Mismatch" error message appears when I use the Tunnel Upload command to upload data?
In most cases, this issue occurs because the row delimiters in the data source file are invalid. As a result, multiple data records are considered one data record. To address this issue, you must check whether the row delimiters in the data source file are valid. If the row delimiters are invalid, change the value of the -rd parameter.
What do I do if the ODPS-0110061 error is returned in multi-thread upload scenarios?
Problem description
The following error message appears in multi-thread data upload scenarios:
FAILED: ODPS-0110061: Failed to run ddltask - Modify DDL meta encounter exception : ODPS-0010000:System internal error - OTS transaction exception - Start of transaction failed. Reached maximum retry times because of OTSStorageTxnLockKeyFail(Inner exception: Transaction timeout because cannot acquire exclusive lock.)Cause
When you upload data, a large number of write operations are performed on the same table at the same time.
Solution
Reduce the number of parallel write operations. Configure a latency between requests and allow for retries when an error occurs.
How do I skip the table header in a CSV file when I use the Tunnel Upload command to upload the CSV file?
Set the -h parameter to true in the Tunnel Upload command.
When I use the Tunnel Upload command to upload a CSV file, a large portion of data in the file is missing after the upload. Why?
This issue occurs because the encoding format of the data is invalid or the delimiters in the data are invalid. We recommend that you modify the invalid encoding format or delimiters before you upload the data.
How do I use a shell script to upload data in a TXT file to a MaxCompute table?
In the command-line interface (CLI) of the MaxCompute client, you can specify parameters in the Tunnel Upload command to upload data. The following command shows an example:
...\odpscmd\bin>odpscmd -e "tunnel upload "$FILE" project.table"For more information about the startup parameters of the MaxCompute client, see MaxCompute client (odpscmd).
When I use the Tunnel Upload command to upload files in a folder at a time, the "Column Mismatch" error message appears, but the files can be separately uploaded. What do I do?
In the Tunnel Upload command, set -dbr=false -s true to check the data format.
In most cases, the "Column Mismatch" error message appears because the number of columns in the data that you want to upload is inconsistent with the number of columns in the table or partition to which you want to upload the data. For example, if the column delimiters that you configured are invalid or the file ends with line feeds, the number of columns in the data that you want to upload is not the same as the number of columns in the table or partition to which you want to upload the data.
When I use the Tunnel Upload command to upload two files, the second file is not uploaded but no error message appears after the first file is uploaded. Why?
If the upload parameters that are configured on the MaxCompute client include --scan, an error occurs during parameter transfer in rerun mode. You can remove --scan=true from the Tunnel Upload command and retry the upload.
When I use the Tunnel Upload command to upload data, the data is split into 50 blocks. When the data in the twenty-second block is uploaded, the "Upload Fail" error message appears. When I retry the upload operation, the system starts the upload from the twenty-third block. What do I do?
One block corresponds to one HTTP request. Multiple blocks can be uploaded at the same time. Parallel upload operations are atomic. The data upload of a block is not affected regardless of whether the synchronization requests for other blocks are successful.
The number of upload retries is limited. If the number of upload retries for data in a block exceeds the limit, the system uploads the next block. After the data is uploaded, you can execute the select count(*) from table; statement to check whether data is missing.
The size of the website logs that are collected per day by the local server is 10 GB. When I use the Tunnel Upload command to upload these logs to MaxCompute, the upload speed is about 300 KB/s. How do I increase the upload speed?
The upload speed for the Tunnel Upload command is not limited. The upload speed varies based on the network bandwidth and server performance. To improve server performance, you can upload data by partition or by table. You can also upload data by using multiple ECS instances.
The lifecycle of an upload session is one day. When I upload an oversized table, the upload task fails due to a session timeout. What do I do?
We recommend that you split the upload task into two subtasks.
What do I do if an upload is time-consuming when a large number of upload sessions exist?
You can configure the size of each block based on your business requirements. The maximum block ID is 20000. You can configure the session lifecycle based on your business requirements. Data can be displayed only after you submit a session. We recommend that you create a session at an interval of no less than 5 minutes and set the size of each block in a session to a value greater than 64 MB.
Why do extra \r symbols exist in the last line of the data that I uploaded?
Line feeds in Windows are represented by \r\n, and line feeds in macOS and Linux are represented by \n. Tunnel commands use the line feeds of the operating system as the default column delimiter. Therefore, if the file that you want to upload is edited and saved in Windows, \r symbols are written to the table to which the file is uploaded when you upload the file in macOS or Linux.
What do I do if commas (,) are used as column delimiters and the field values that I want to upload contain commas (,) when I use the Tunnel Upload command to upload data?
If the field values contain commas (,), you can change the delimiters in the data file first and use the -fd parameter to specify the new delimiters in the Tunnel Upload command.
What do I do if spaces are used as column delimiters in the data that I want to upload or the data needs to be filtered based on regular expressions when I use the Tunnel Upload command to upload data?
The Tunnel Upload command does not support regular expressions. You can use MaxCompute UDFs if spaces are used as the column delimiters in the data that you want to upload or the data needs to be filtered based on regular expressions.
In the following sample source data, spaces are used as column delimiters and line feeds are used as row delimiters. Some of the data that you want to obtain is enclosed in double quotation marks ("), and some data, such as hyphens (-), needs to be filtered out. You can use regular expressions to upload the data.
10.21.17.2 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73477.html" 200 0 81615 81615 "-" "iphone" - HIT - - 0_0_0 001 - - - -
10.17.5.23 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73478.html" 206 0 49369 49369 "-" "huawei" - HIT - - 0_0_0 002 - - - -
10.24.7.16 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73479.html" 206 0 83821 83821 "-" "vivo" - HIT - - 0_0_0 003 - - - -Procedure:
Create a table that contains only one column to store the data that you want to upload. Sample command:
create table userlog1(data string);Use
\u0000as the column delimiter for the source data and upload the data. This way, the source data is uploaded as a single row. Sample command:tunnel upload C:\userlog.txt userlog1 -s false -fd "\u0000" -rd "\n";After you upload the source data, use MaxCompute Studio to write and create a Python UDF or Java UDF. For more information about how to write and create a Java UDF or a Python UDF, see Develop a UDF or Develop a Python UDF.
The following sample UDF code shows that a UDF named ParseAccessLog is created.
from odps.udf import annotate from odps.udf import BaseUDTF import re # The code of the regular expression function. regex = '([(\d\.)]+) \[(.*?)\] - "(.*?)" (\d+) (\d+) (\d+) (\d+) "-" "(.*?)" - (.*?) - - (.*?) (.*?) - - - -' # The regular expression that you want to use. # line -> ip,date,request,code,c1,c2,c3,ua,q1,q2,q3 @annotate('string -> string,string,string,string,string,string,string,string,string,string,string') # In this example, 11 strings are used. The number of strings must be the same as the columns of the source data. class ParseAccessLog(BaseUDTF): def process(self, line): try: t = re.match(regex, line).groups() self.forward(t[0], t[1], t[2], t[3], t[4], t[5], t[6], t[7], t[8], t[9], t[10]) except: passAfter you create the UDF, you can use the UDF to process the source data that you uploaded to the userlog1 table. You must make sure that the column name is valid. In this example, the column name is data. You can use the standard SQL syntax to create a table to store the processed data. In this example, a table named userlog2 is created. Sample command:
create table userlog2 as select ParseAccessLog(data) as (ip,date,request,code,c1,c2,c3,ua,q1,q2,q3) from userlog1;After the data is processed, you can query the data of the userlog2 table to check whether the data is split into columns.
select * from userlog2; -- The following result is returned: +----+------+---------+------+----+----+----+----+----+----+----+ | ip | date | request | code | c1 | c2 | c3 | ua | q1 | q2 | q3 | +----+------+---------+------+----+----+----+----+----+----+----+ | 10.21.17.2 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73477.html | 200 | 0 | 81615 | 81615 | iphone | HIT | 0_0_0 | 001 | | 10.17.5.23 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73478.html | 206 | 0 | 4936 | 4936 | huawei | HIT | 0_0_0 | 002 | | 10.24.7.16 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73479.html | 206 | 0 | 83821 | 83821 | vivo | HIT | 0_0_0 | 003 | +----+------+---------+------+----+----+----+----+----+----+----+
What do I do if dirty data exists after I use the Tunnel Upload command to upload data?
We recommend that you write all data to a non-partitioned table or to a partition at a time. If you write data to the same partition multiple times, dirty data may be generated. You can run the tunnel show bad <sessionid>; command on the MaxCompute client to query dirty data. If dirty data is found, you can delete the dirty data by using one of the following methods:
Execute the
drop table ...;statement to drop the entire table or execute thealter table ... drop partition;statement to drop the partition and then upload the data again.If the WHERE clause can be used to filter out dirty data, use the INSERT statement with the WHERE clause to insert data into a new table or insert data to overwrite the existing data of the destination partition or table that has the same name as the source partition or table.
How do I synchronize data of the GEOMETRY type to MaxCompute?
MaxCompute does not support the GEOMETRY data type. If you want to synchronize data of the GEOMETRY type to MaxCompute, you must convert the data of the GEOMETRY type to the STRING type.
GEOMETRY is a special data type, which is different from the standard data type in SQL. GEOMETRY is not supported in the general framework of Java Database Connectivity (JDBC). Therefore, special processing is required to import and export data of the GEOMETRY type.
Which formats of the files can I export by using the Tunnel Download command?
You can use the Tunnel Download command to export only the files that are in the TXT or CSV format.
Why am I charged when I use the Tunnel Download command to download data in the region of my MaxCompute project?
If you use the Tunnel Download command to download data in the region of your MaxCompute project, you must configure the Tunnel endpoint of the cloud product interconnection network or the Tunnel endpoint of a virtual private cloud (VPC). Otherwise, the data may be routed to other regions. You are charged when you download data over the Internet.
What do I do if a timeout message appears when I use the Tunnel Download command to download data?
In most cases, this issue occurs because the Tunnel endpoint that you configured is invalid. To check whether the Tunnel endpoint is valid, you can use Telnet to test the network connectivity.
What do I do if the "You have NO privilege" error message appears when I use the Tunnel Download command to download data?
Problem description
When the Tunnel Download command is used to download data, the following error message appears:
You have NO privilege 'odps:Select' on {acs:odps:*:projects/XXX/tables/XXX}. project 'XXX' is protected.Cause
The data protection feature is enabled for the MaxCompute project.
Solution
Only the owner of the project can export data from the project to another project.
How do I use Tunnel to download specified data?
Tunnel does not support data computing or filtering. To compute or filter data, you can use one of the following methods:
Run an SQL job to save the data that you want to download as a temporary table. After you download the data, delete the temporary table.
If you want to download a small amount of data, you can execute an SQL statement to query the required data without the need to download the data.
How long can I save the information about historical Tunnel commands?
The information storage is not related to the storage duration. By default, you can store a maximum of 500 data records.
How do I upload data by using Tunnel?
To upload data by using Tunnel, perform the following steps:
Prepare the source data, such as a source file or a source table.
Design the table schema and specify partition definitions, convert data types, and then create a table on the MaxCompute client.
Add partitions to the MaxCompute table. If the table is a non-partitioned table, skip this step.
Upload data to the specified partition or table.
Can the names of Tunnel directories contain Chinese characters?
Yes, the names of Tunnel directories can contain Chinese characters.
What are the points that I must take note of when I use delimiters in Tunnel commands?
When you use delimiters in Tunnel commands, take note of the following points:
The
-rdparameter specifies the row delimiter, and the-fdparameter specifies the column delimiter.The column delimiter that is specified by the
-fdparameter cannot include the row delimiter that is specified by the-rdparameter.In Windows, the default delimiter for Tunnel commands is
\r\n. In Linux, the default delimiter for Tunnel commands is\n.When you start to upload data, you can view and confirm the row delimiter that is used in the upload operation. This feature is supported in MaxCompute client V0.21.0 or later.
Can Tunnel file paths contain spaces?
Yes, Tunnel file paths can contain spaces. If a Tunnel file path contains a space, you must enclose the path in a pair of double quotation marks (") in the Tunnel command.
Does Tunnel support non-encrypted database files with the .dbf extension?
Tunnel supports only text files. Binary files are not supported.
What are the valid speed ranges for Tunnel uploads and downloads?
Tunnel uploads and downloads are subject to network status. If the network status is normal, the upload speed ranges from 1 MB/s to 20 MB/s.
How do I obtain public Tunnel endpoints?
Public Tunnel endpoints vary based on the region and network. For more information about public Tunnel endpoints, see Endpoints.
What do I do if I fail to upload or download data by using Tunnel commands?
Obtain Tunnel endpoints from the odps_config.ini file in the ..\odpscmd_public\conf directory. In the CLI of the MaxCompute client, run the curl -i Endpoint command, such as curl -i http://dt.odps.aliyun.com, to test the network connectivity. If the network connectivity is abnormal, check the network status or use a valid Tunnel endpoint.
What do I do if the "Java heap space FAILED" error message appears when I run a Tunnel command?
Problem description
When Tunnel commands are used to upload or download data, the following error message appears:
Java heap space FAILED: error occurred while running tunnel commandCauses
Cause 1: The size of a single row of data that you want to upload is excessively large.
Cause 2: The amount of data that you want to download is excessively large, and the memory of the MaxCompute client is insufficient.
Solutions
Solution to Cause 1:
Check whether the delimiters that you used are valid. If the delimiters are invalid, all data records are uploaded as a single row and the size of the row is excessively large.
If the delimiters that you used are valid and the size of one row is still large, the memory of the client is insufficient. You must adjust the startup parameters of MaxCompute client processes. In the odpscmd script file in the client installation directory
bin, increase the values of-Xms64mand -Xmx512m injava -Xms64m -Xmx512m -classpath "${clt_dir}/lib/*:${clt_dir}/conf/"com.aliyun.openservices.odps.console.ODPSConsole "$@"based on your business requirements.
Solution to Cause 2: In the odpscmd script file in the client installation directory
bin, increase the values of-Xms64mand -Xmx512m injava -Xms64m -Xmx512m -classpath "${clt_dir}/lib/*:${clt_dir}/conf/"com.aliyun.openservices.odps.console.ODPSConsole "$@"based on your business requirements.
Does a session have a lifecycle? What do I do if the lifecycle of a session times out?
Yes, each session on the server has a lifecycle of 24 hours. The lifecycle starts after you create the session. If the lifecycle of a session times out, the session cannot be used. In this case, you must recreate a session to rewrite data.
Can multiple processes or threads share the same session?
Yes, multiple processes or threads can share the same session. However, you must make sure that each block ID is unique.
What is the routing feature of Tunnel?
If you do not configure a Tunnel endpoint, traffic is automatically routed to the Tunnel endpoint of the network in which MaxCompute resides. If you configure a Tunnel endpoint, traffic is routed to the specified endpoint and automatic routing is not performed.
Does Tunnel support parallel upload and download operations?
Yes, Tunnel supports parallel upload and download operations. The following command shows an example:
tunnel upload E:/1.txt tmp_table_0713 --threads 5;