MaxCompute allows you to write data from business systems or external data sources to MaxCompute or from MaxCompute to business systems or external data sources by using various methods.
Data transfer methods
Tunnel SDK
External tables (data lakehouse solution)
Java Database Connectivity (JDBC) driver
Scenarios: Write data to MaxCompute
Batch writing of offline data (MaxCompute Tunnel)
Scenario characteristics
Tasks are periodically scheduled to run by hour or day.
The business is not sensitive to data latency. Business requirements can be met only if the task is complete within the scheduling cycle.
Typical scenarios
Scenario type
Scenario
Batch synchronization from databases
Offline data synchronization by using Data Integration
Data migration to the cloud
MaxCompute Migration Assist (MMA)
Upload of local files
Data upload by using Tunnel commands in the MaxCompute console
Other custom data uploads
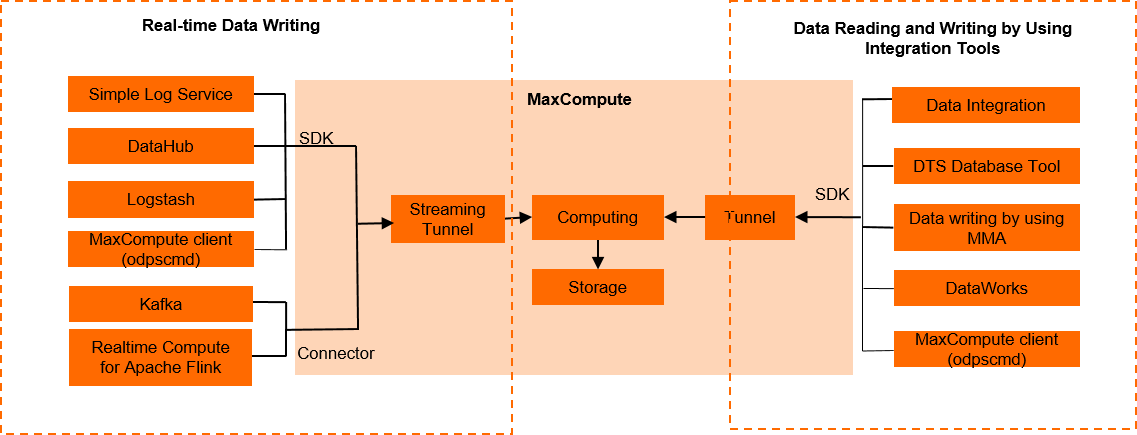
Batch data writing by using Tunnel SDK
Offline data writing in streaming mode (MaxCompute Tunnel)
Scenario characteristics
Data is continuously written in streaming mode.
The business has a high tolerance for data visibility latency. Occasional hour-level latency is acceptable.
The business has a high tolerance for request latency. Occasional minute-level latency is acceptable.
Typical scenarios
Scenario type
Scenario
Collection of binary logs from databases
Real-time data synchronization from databases by using Data Integration
Data Transmission Service (DTS)
Log collection
Real-time data synchronization from Simple Log Service by using Data Integration
Data shipping of Simple Log Service
Log collection client Logstash
Data writing by using a stream computing task
Data writing to a MaxCompute result table by using Flink
Data writing by using a streaming data synchronization task
Data synchronization from DataHub to MaxCompute
Data synchronization from KafKa to MaxCompute
Custom data writing
Data writing by using Streaming Tunnel SDK
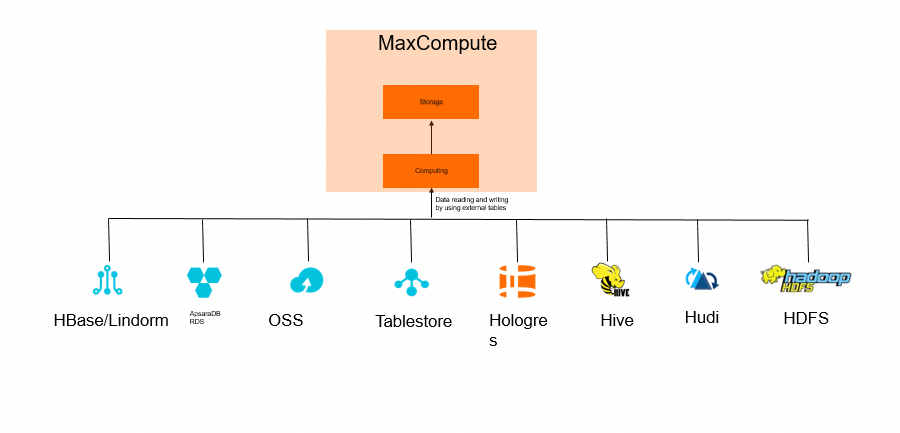
Batch writing of offline data (data writing from external tables by using the data lakehouse solution)
Scenario characteristics: Federated queries and analysis are required. Data occasionally needs to be migrated.
Typical scenarios
Scenario type
Scenario
Upload of Object Storage Service (OSS) and MaxCompute data
Data upload by using the LOAD command
Data writing from external tables by using the data lakehouse solution
Data writing from Hologres to MaxCompute
Hologres data directly read by MaxCompute
Data writing from other data sources, such as Tablestore, ApsaraDB RDS for MySQL, ApsaraDB for HBase, Lindorm, Hudi, Hadoop Distributed File System (HDFS), and Hive, to MaxCompute
N/A
Real-time data writing (MaxCompute Tunnel)
Data visibility with latency is acceptable.
The business has a high tolerance for data visibility latency. Occasional hour-level latency is acceptable.
The business has a low tolerance for request latency. Only stable latency in seconds is acceptable.
We recommend that you write real-time data to DataHub and then synchronize the data to MaxCompute.
Data must be visible in real time.
The business has a low tolerance for data visibility latency. Only stable latency in minutes is acceptable.
The business has a low tolerance for request latency. Only stable latency in seconds is acceptable.
We recommend that you use a real-time data warehouse product such as Hologres.
Scenarios: Read data from MaxCompute
Batch data reading (MaxCompute Tunnel)
Scenario characteristics
Tasks are periodically scheduled to run by hour or day.
The business is not sensitive to data latency. Business requirements can be met only if the task is complete within the scheduling cycle.
Typical scenarios
Scenario type
Scenario
Batch data export from a data warehouse
Batch data export by using Data Integration
Data reading from MaxCompute tables by using Flink
Data reading from MaxCompute source tables by using Flink
Data download to a local file
Data download by using Tunnel commands in the MaxCompute console
Other custom data downloads
Data reading by using MaxCompute Tunnel SDK
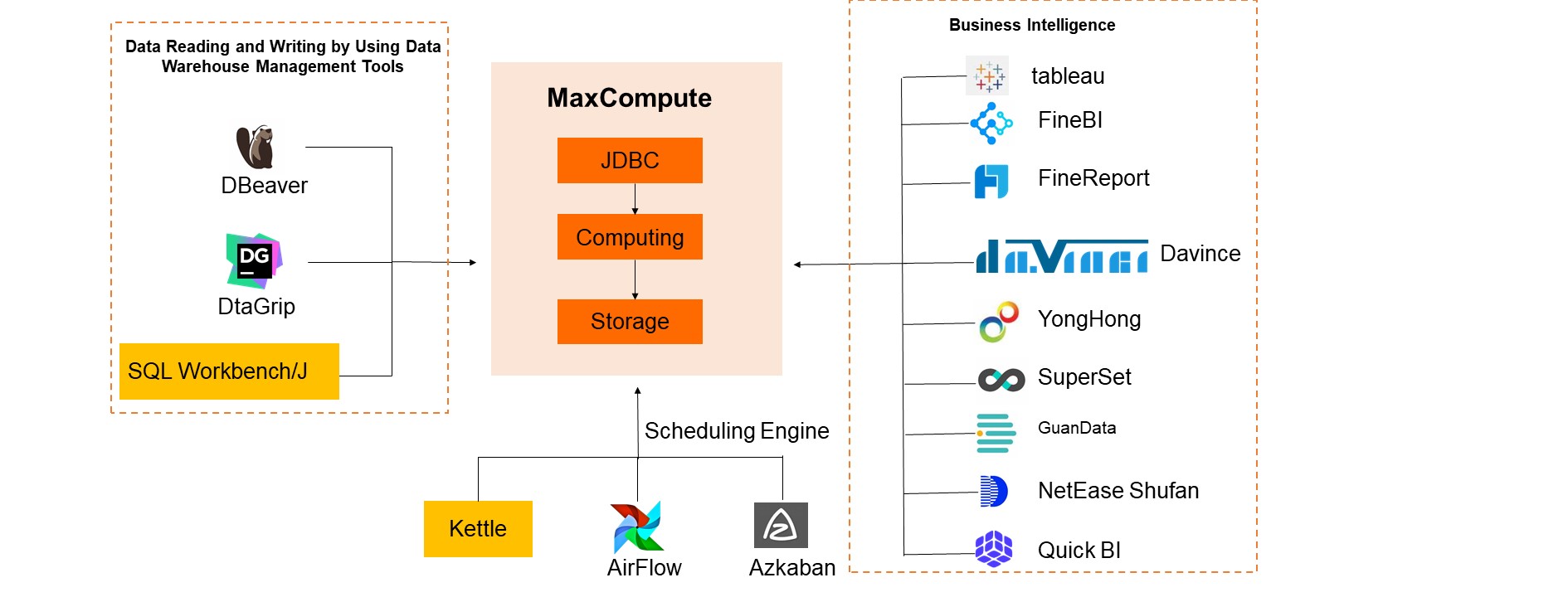
Batch data reading (JDBC driver)
Scenario characteristics
Sample data needs to be queried for data management, data development, data governance, and data asset management. Sample data also needs to be viewed on data maps.
Data analysis and summary and data visualization are required.
Typical scenarios
Scenario type
Scenario
Data previewed by data warehouse administrators
Data analysis, data management, and data development and scheduling in the DataWorks console by using MaxCompute Tunnel
Kettle
Business intelligence, reports, and kanban
Quick BI
Superset
Batch reading of offline data (data reading from MaxCompute to external tables by using the data lakehouse solution)
Scenario characteristics: Federated queries and analysis are required. Data occasionally needs to be migrated.
Typical scenarios
Scenario type
Typical scenario
Download of OSS and MaxCompute data
Data download by using the UNLOAD command
Data reading from MaxCompute to external tables by using the data lakehouse solution
Data reading from MaxCompute to Hologres
Data directly read by using Hologres external tables
Data reading from MaxCompute to services such as Tablestore or ApsaraDB RDS for MySQL
N/A