This topic describes how to count the total number of rows in a Lindorm wide table.
Usage notes
Lindorm is a NoSQL database that uses the Log-Structured Merge-Tree (LSM-Tree) storage structure. To query the exact number of rows in a Lindorm wide table, you must scan the entire table. The larger the table, the longer this operation takes. Therefore, do not perform frequent COUNT operations on Lindorm wide tables. You can use one of the following methods to count the rows.
To obtain an estimated number of rows in a Lindorm wide table, you can view the information on the Table Overview page in the Lindorm cluster management system. For more information, see View the estimated number of rows using the cluster management system.
Count the number of rows using the HBase Shell tool
Before you begin, connect to LindormTable using HBase Shell. For more information, see Access LindormTable using Lindorm Shell.
You can use the COUNT command in the HBase Shell tool to accurately count the number of rows in an HBase table. The COUNT command works by scanning all table data in batches to compile statistics. Run the COUNT command on an ECS client in the same virtual private cloud (VPC). If you run the COUNT command over the Internet, network usage is high, which reduces the efficiency of the count operation. The scan speed varies based on the table schema. The speed of a full table scan using the COUNT command can be less than 100,000 rows per second. Execute the following statement to count the total number of rows in the table.
count 'table'The following result is returned:
Count the number of rows using HBase RowCounter
Before you begin, connect to LindormTable using HBase Shell. For more information, see Access LindormTable using Lindorm Shell.
RowCounter starts a local, pseudo-distributed MapReduce job to perform the COUNT operation. By default, this operation is single-threaded. The counting speed is similar to running the COUNT command in HBase Shell. To increase the counting speed, you can use multiple threads by specifying Dmapreduce.local.map.tasks.maximum=number_of_threads. Note the following:
The number of threads must be less than or equal to the number of regions in the table.
A larger number of threads can cause high cluster loads and affect online services. Set the number of threads according to your requirements.
In HBase Shell, execute the following code to count the number of rows in a Lindorm wide table.
Count the total number of rows in the table.
./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter "table"Count the total number of rows in the table using 16 concurrent threads.
./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter -Dmapreduce.local.map.tasks.maximum=16 "table"Count the total number of rows in the table that is in the ns namespace.
./alihbase-2.0.18/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter "ns:table"
The result is saved in the hbase.log file in the Log directory.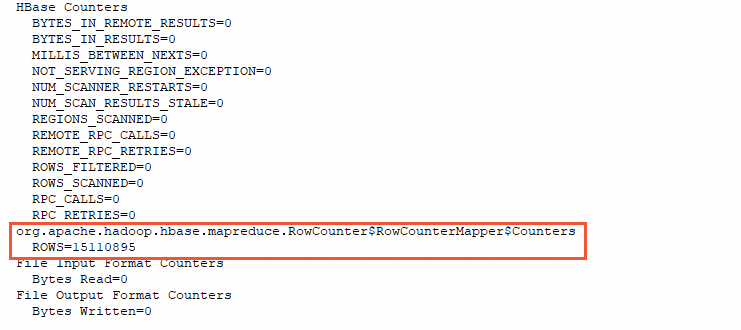
Count the number of rows using Lindorm SQL
Count the exact number of rows
Before you begin, connect to LindormTable using Lindorm-cli.
Counting rows with Lindorm SQL is faster than with HBase RowCounter. This is because Lindorm automatically distributes the COUNT logic to each Lindorm process, which is equivalent to using multiple threads. In contrast, HBase Shell is single-threaded. However, the COUNT operation still requires a full table scan. The default timeout for a Lindorm SQL statement is 120 seconds. If the count is not completed within 120 seconds, the statement times out and returns an error. The counting speed with Lindorm SQL can reach hundreds of thousands of rows per second per server. Because the COUNT operation is distributed, the speed increases with the number of servers in the cluster.
Execute the following code to count the number of rows in the table.
SELECT COUNT(*) FROM table;The following result is returned:
+--------+
| EXPR$0 |
+--------+
| 16000 |
+--------+Counting the number of rows requires a full table scan. Perform this operation with caution. If the table contains more than one million rows, use a search index to accelerate the query. For more information, see Query data in a wide table using a search index.
Count the estimated number of rows
This feature requires LindormTable version 2.8.2.6 or later and Lindorm SQL version 2.8.2.6 or later.
Execute the following SQL statement to count the estimated number of rows in a table:
SHOW ESTIMATED ROWS FROM table;The following result is returned:
+---------------------+
| ESTIMATED_ROW_COUNT |
+---------------------+
| 15000 |
+---------------------+View the estimated number of rows using the cluster management system
Before you begin, log on to the cluster management system.
In the Lindorm cluster management system, you can view the estimated number of rows for a table on the Overview page. This value is calculated by adding the row count metadata from each data file. This value can be inaccurate. If you update or delete data, the same row might exist in multiple files. The row count metadata is collected when the data files are created. If you use the time-to-live (TTL) feature, some data in these files may have expired. Therefore, this value is only an estimate. However, if your table has no updates, deletions, or expired data due to TTL, the displayed row count is completely accurate. You can use this value to check data integrity after a data migration is complete.
In the Lindorm cluster management system, click Overview in the navigation pane on the left. In the Current IDC area, find the target table. Then, click View in the EstimateRowCount column to view the estimated number of rows.
If your table contains data but the estimated number of rows is 0, the minor version of LindormTable may be too old. In this case, you can upgrade the minor version of LindormTable. For more information, see Upgrade the minor version.