This topic shows how to build a batch and stream analytics solution. This solution uses MaxCompute to build an offline data warehouse and Flink and Hologres to build a real-time data warehouse. You can then perform real-time and offline data analytics in Hologres and MaxCompute, respectively.
Background information
As digital transformation accelerates, businesses increasingly demand timely data. Beyond traditional offline scenarios designed for massive-scale data processing, many use cases now require real-time data ingestion, storage, and analysis. To address this need, the concept of unified offline and real-time analytics has emerged.
Unified offline and real-time analytics refers to managing and processing both real-time and offline data on a single platform. It seamlessly integrates real-time data processing with offline analytics to improve efficiency and accuracy. Key benefits include the following:
Improved data processing efficiency: Integrating real-time and offline data on one platform reduces data transfer and transformation costs.
Higher analytics accuracy: Combining real-time and historical data enables more precise and accurate insights.
Reduced system complexity: Simplifies data management and processing workflows.
Greater data value: Maximizes the business value of data to support better decision-making.
Alibaba Cloud offers streamlined solutions for unified offline and real-time analytics. This architecture uses MaxCompute for offline workloads, Hologres for real-time analytics, and Flink for real-time data transformation. These services are the core engine components of Alibaba Cloud's unified data warehouse solution.
Solution architecture
The following diagram shows the end-to-end workflow for unified offline and real-time analytics using GitHub public event datasets with MaxCompute and Hologres.
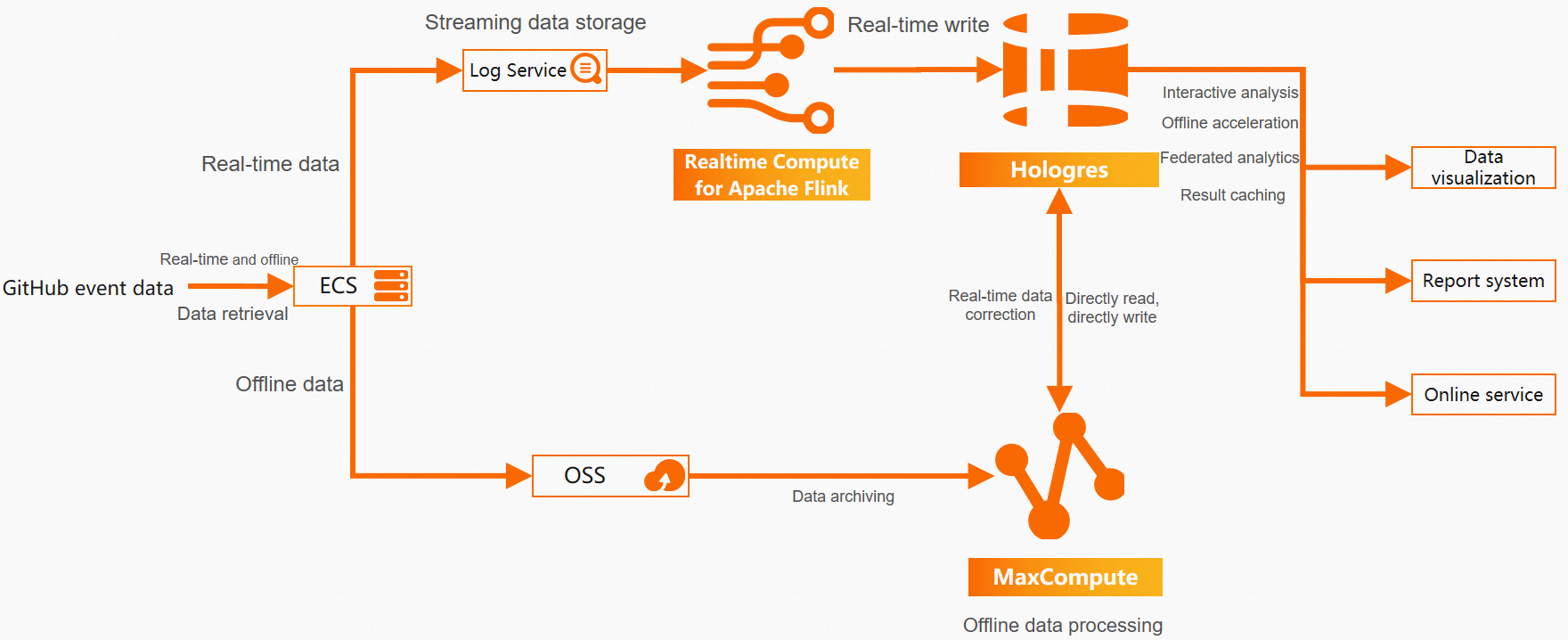
An ECS instance collects and aggregates both real-time and offline GitHub event data. The data then flows into separate real-time and offline pipelines, which ultimately converge in Hologres to provide a unified service layer.
Real-time pipeline: Flink processes data from Simple Log Service (SLS) in real time and writes it to Hologres. Flink is a powerful stream-processing engine. Hologres supports immediate querying of data upon ingestion and native integration with Flink, enabling high-throughput, low-latency, and high-quality real-time analytics. This pipeline meets real-time business needs such as extracting the latest events or analyzing trending activities.
Offline pipeline: MaxCompute processes and archives large volumes of historical data. Alibaba Cloud Object Storage Service (OSS) provides secure, reliable, and cost-effective cloud storage for various data types. In this solution, raw data is stored in JSON format in OSS. MaxCompute is an enterprise-grade cloud data warehouse that uses a software-as-a-service (SaaS) model and is optimized for analytics. It can directly read and parse semi-structured data from OSS using external tables, integrate high-value data into its internal storage, and use DataWorks for data development to build an offline data warehouse.
Hologres and MaxCompute are natively integrated at the storage layer. This allows Hologres to accelerate queries on MaxCompute’s massive historical datasets to satisfy low-frequency but high-performance query requirements. It also enables easy correction of real-time data using offline data to address potential gaps or omissions in the real-time pipeline.
Key advantages of this solution include the following:
Stable and efficient offline pipeline: Supports hourly data updates, batch processing of large-scale datasets, complex computations, reduced computing costs, and improved processing efficiency.
Mature real-time pipeline: Supports real-time ingestion, event computation, and analysis with a simplified architecture and sub-second response times.
Unified storage and service: Hologres serves all data through a consistent interface (OLAP and key-value queries unified under SQL), with centralized storage.
Seamless real-time and offline integration: Minimizes data redundancy and movement while enabling data correction.
With end-to-end development support, this solution delivers sub-second data responsiveness, full pipeline visibility, minimal architecture components, fewer dependencies, and significantly reduced operational and labor costs.
Business and data understanding
Developers create many open source projects on GitHub and generate numerous events during the development process. GitHub records the type and details of each event, the developer, the repository, and other information. It also exposes public events, such as starring and code commits. For more information about specific event types, see Webhook events and payloads.
GitHub publishes real-time public events via OpenAPI. This API only exposes events from the past five minutes. For more information, see Events. You can use this API to obtain real-time data.
The GH Archive project aggregates GitHub public events hourly and makes them available for download. For more information, see GH Archive. You can use this project to obtain offline data.
GitHub business overview
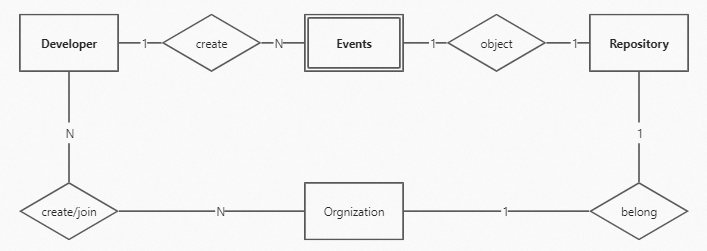
GitHub’s core business revolves around code management and developer collaboration, primarily involving three top-level entities: Developer, Repository, and Organization.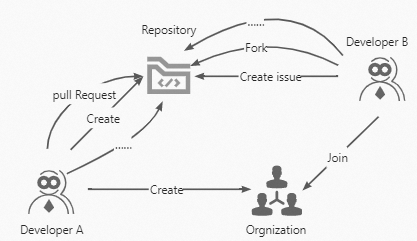
In this solution, Event is treated as a distinct entity for storage and analysis.
Understanding raw public event data
The following example shows a sample raw event in JSON format:
{
"id": "19541192931",
"type": "WatchEvent",
"actor":
{
"id": 23286640,
"login": "herekeo",
"display_login": "herekeo",
"gravatar_id": "",
"url": "https://api.github.com/users/herekeo",
"avatar_url": "https://avatars.githubusercontent.com/u/23286640?"
},
"repo":
{
"id": 52760178,
"name": "crazyguitar/pysheeet",
"url": "https://api.github.com/repos/crazyguitar/pysheeet"
},
"payload":
{
"action": "started"
},
"public": true,
"created_at": "2022-01-01T00:03:04Z"
}This solution covers 15 types of public events, excluding deprecated or unrecorded types. For a detailed list and descriptions, see GitHub public event types.
Prerequisites
Create an Elastic Compute Service (ECS) instance and associate it with an Elastic IP Address (EIP) to extract real-time event data from the GitHub API. For more information, see Create an ECS instance and Elastic IP Address.
Activate Object Storage Service (OSS) and install the ossutil tool on your ECS instance to store JSON data files from GH Archive. For more information, see Activate OSS and Install ossutil.
Activate MaxCompute and create a project. For more information, see Create a MaxCompute project.
Activate DataWorks and create a workspace to build offline scheduling tasks. For more information, see Create a workspace.
Activate Simple Log Service (SLS) and create a project and Logstore to collect data extracted by ECS as logs. For more information, see Use LoongCollector to collect and analyze ECS text logs.
Activate Realtime Compute for Apache Flink to write SLS-collected log data to Hologres in real time. For more information, see Activate Realtime Compute for Apache Flink.
Activate Hologres. For more information, see Purchase a Hologres instance.
Build an offline data warehouse (hourly updates)
Download raw data files using ECS and upload them to OSS
You can use an ECS instance to download JSON data files provided by GH Archive.
For historical data, you can use the
wgetcommand. For example, you can runwget https://data.gharchive.org/{2012..2022}-{01..12}-{01..31}-{0..23}.json.gzto download hourly data from 2012 to 2022.For new hourly data, you can set up a scheduled task as follows.
NoteEnsure that ossutil is installed on your ECS instance. For more information, see Install ossutil. We recommend that you download the ossutil package directly to your ECS instance, install unzip with
yum install unzip, extract ossutil, and move it to the/usr/bin/directory.Create an OSS bucket in the same region as your ECS instance. You can use a custom bucket name. In this example, the bucket name is
githubevents.The example ECS download directory is
/opt/hourlydata/gh_data. You can use a different directory.
Run the following commands to create a file named
download_code.shin the/opt/hourlydatadirectory.cd /opt/hourlydata vim download_code.shPress
ito enter edit mode and add the following script.d=$(TZ=UTC date --date='1 hour ago' '+%Y-%m-%d-%-H') h=$(TZ=UTC date --date='1 hour ago' '+%Y-%m-%d-%H') url=https://data.gharchive.org/${d}.json.gz echo ${url} # Download data to ./gh_data/. You can customize this path. wget ${url} -P ./gh_data/ # Switch to the gh_data directory. cd gh_data # Decompress the downloaded data into a JSON file. gzip -d ${d}.json echo ${d}.json # Switch to the root directory. cd /root # Use ossutil to upload data to OSS. # Create a directory named hr=${h} in the githubevents OSS bucket. ossutil mkdir oss://githubevents/hr=${h} # Upload data from /opt/hourlydata/gh_data (you can customize this path) to OSS. ossutil cp -r /opt/hourlydata/gh_data oss://githubevents/hr=${h} -u echo oss uploaded successfully! rm -rf /opt/hourlydata/gh_data/${d}.json echo ecs deleted!Press Esc, type
:wq, and press Enter to save and exit.Run the following command to schedule the
download_code.shscript to run at the 10th minute of every hour.#1 Run the following command and press I to enter edit mode. crontab -e #2 Add the following line, then press Esc and type :wq to exit. 10 * * * * cd /opt/hourlydata && sh download_code.sh > download.logAfter setup, the script downloads the previous hour’s JSON file at the 10th minute of each hour, decompresses it on the ECS instance, and uploads it to OSS (path:
oss://githubevents). To ensure that only the latest hour’s data is processed later, each upload creates a partition directory namedhr=%Y-%m-%d-%H. Subsequent reads will target only the newest partition.
Import OSS data into MaxCompute using an external table
You can run the following commands in the MaxCompute client or an ODPS SQL node in DataWorks. For more information, see Connect using the local client (odpscmd) or Develop an ODPS SQL task.
Create an external table named
githubeventsto map JSON files stored in OSS:CREATE EXTERNAL TABLE IF NOT EXISTS githubevents ( col STRING ) PARTITIONED BY ( hr STRING ) STORED AS textfile LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/githubevents/' ;For more information about how to create OSS external tables in MaxCompute, see ORC external tables.
Create a fact table named
dwd_github_events_odpsto store the parsed data. The following code provides the DDL statement:CREATE TABLE IF NOT EXISTS dwd_github_events_odps ( id BIGINT COMMENT 'Event ID' ,actor_id BIGINT COMMENT 'Actor ID' ,actor_login STRING COMMENT 'Actor login name' ,repo_id BIGINT COMMENT 'Repository ID' ,repo_name STRING COMMENT 'Full repository name: owner/repository_name' ,org_id BIGINT COMMENT 'Organization ID' ,org_login STRING COMMENT 'Organization name' ,`type` STRING COMMENT 'Event type' ,created_at DATETIME COMMENT 'Event occurrence time' ,action STRING COMMENT 'Event action' ,iss_or_pr_id BIGINT COMMENT 'Issue or pull request ID' ,number BIGINT COMMENT 'Issue or pull request number' ,comment_id BIGINT COMMENT 'Comment ID' ,commit_id STRING COMMENT 'Commit ID' ,member_id BIGINT COMMENT 'Member ID' ,rev_or_push_or_rel_id BIGINT COMMENT 'Review, push, or release ID' ,ref STRING COMMENT 'Name of created or deleted resource' ,ref_type STRING COMMENT 'Type of created or deleted resource' ,state STRING COMMENT 'State of issue, pull request, or pull request review' ,author_association STRING COMMENT 'Relationship between actor and repository' ,language STRING COMMENT 'Programming language of merged code' ,merged BOOLEAN COMMENT 'Whether the merge was accepted' ,merged_at DATETIME COMMENT 'Code merge time' ,additions BIGINT COMMENT 'Number of lines added' ,deletions BIGINT COMMENT 'Number of lines deleted' ,changed_files BIGINT COMMENT 'Number of files changed in pull request' ,push_size BIGINT COMMENT 'Number of commits' ,push_distinct_size BIGINT COMMENT 'Number of distinct commits' ,hr STRING COMMENT 'Hour of event occurrence (e.g., 00:23 → hr=00)' ,`month` STRING COMMENT 'Month of event occurrence (e.g., October 2015 → month=2015-10)' ,`year` STRING COMMENT 'Year of event occurrence (e.g., 2015 → year=2015)' ) PARTITIONED BY ( ds STRING COMMENT 'Date of event occurrence (ds=yyyy-mm-dd)' );Parse JSON data and write it to the fact table.
Run the following commands to add partitions and parse JSON data into the
dwd_github_events_odpstable:msck repair table githubevents add partitions; set odps.sql.hive.compatible = true; set odps.sql.split.hive.bridge = true; INSERT into TABLE dwd_github_events_odps PARTITION(ds) SELECT CAST(GET_JSON_OBJECT(col,'$.id') AS BIGINT ) AS id ,CAST(GET_JSON_OBJECT(col,'$.actor.id')AS BIGINT) AS actor_id ,GET_JSON_OBJECT(col,'$.actor.login') AS actor_login ,CAST(GET_JSON_OBJECT(col,'$.repo.id')AS BIGINT) AS repo_id ,GET_JSON_OBJECT(col,'$.repo.name') AS repo_name ,CAST(GET_JSON_OBJECT(col,'$.org.id')AS BIGINT) AS org_id ,GET_JSON_OBJECT(col,'$.org.login') AS org_login ,GET_JSON_OBJECT(col,'$.type') as type ,to_date(GET_JSON_OBJECT(col,'$.created_at'), 'yyyy-mm-ddThh:mi:ssZ') AS created_at ,GET_JSON_OBJECT(col,'$.payload.action') AS action ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.issue.id')AS BIGINT) END AS iss_or_pr_id ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.number')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.issue.number')AS BIGINT) ELSE CAST(GET_JSON_OBJECT(col,'$.payload.number')AS BIGINT) END AS number ,CAST(GET_JSON_OBJECT(col,'$.payload.comment.id')AS BIGINT) AS comment_id ,GET_JSON_OBJECT(col,'$.payload.comment.commit_id') AS commit_id ,CAST(GET_JSON_OBJECT(col,'$.payload.member.id')AS BIGINT) AS member_id ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.review.id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="PushEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.push_id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="ReleaseEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.release.id')AS BIGINT) END AS rev_or_push_or_rel_id ,GET_JSON_OBJECT(col,'$.payload.ref') AS ref ,GET_JSON_OBJECT(col,'$.payload.ref_type') AS ref_type ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN GET_JSON_OBJECT(col,'$.payload.pull_request.state') WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN GET_JSON_OBJECT(col,'$.payload.issue.state') WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN GET_JSON_OBJECT(col,'$.payload.review.state') END AS state ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN GET_JSON_OBJECT(col,'$.payload.pull_request.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN GET_JSON_OBJECT(col,'$.payload.issue.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="IssueCommentEvent" THEN GET_JSON_OBJECT(col,'$.payload.comment.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN GET_JSON_OBJECT(col,'$.payload.review.author_association') END AS author_association ,GET_JSON_OBJECT(col,'$.payload.pull_request.base.repo.language') AS language ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.merged') AS BOOLEAN) AS merged ,to_date(GET_JSON_OBJECT(col,'$.payload.pull_request.merged_at'), 'yyyy-mm-ddThh:mi:ssZ') AS merged_at ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.additions')AS BIGINT) AS additions ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.deletions')AS BIGINT) AS deletions ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.changed_files')AS BIGINT) AS changed_files ,CAST(GET_JSON_OBJECT(col,'$.payload.size')AS BIGINT) AS push_size ,CAST(GET_JSON_OBJECT(col,'$.payload.distinct_size')AS BIGINT) AS push_distinct_size ,SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),12,2) as hr ,REPLACE(SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,7),'-','-') as month ,SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,4) as year ,REPLACE(SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,10),'-','-') as ds from githubevents where hr = cast(to_char(dateadd(getdate(),-9,'hh'), 'yyyy-mm-dd-hh') as string);Query data.
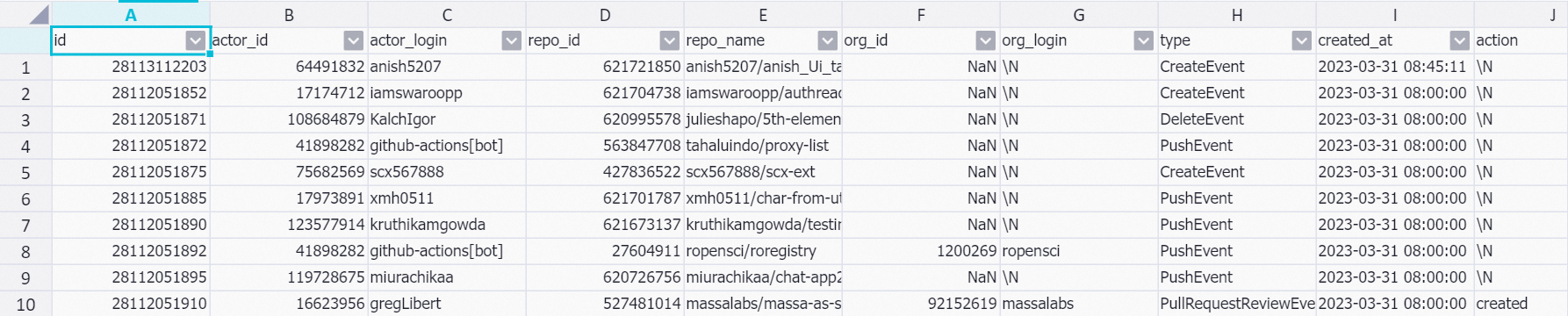
Run the following command to query data from the
dwd_github_events_odpstable:SET odps.sql.allow.fullscan=true; SELECT * FROM dwd_github_events_odps where ds = '2023-03-31' limit 10;Sample output:
Build a real-time data warehouse
Collect real-time data using ECS
You can use an ECS instance to extract real-time event data from the GitHub API. The following script shows one method for collecting real-time data via the GitHub API.
Each script run lasts one minute and collects real-time events available during that interval, storing each event as a JSON object.
This script does not guarantee the capture of all real-time events.
To continuously collect data from the GitHub API, you must provide an Accept header and an Authorization token. The Accept header is a fixed value. The Authorization token requires a personal access token from GitHub. For more information about how to create a token, see Creating a personal access token.
Run the following commands to create a file named
download_realtime_data.pyin the/opt/realtimedirectory.cd /opt/realtime vim download_realtime_data.pyPress
ito enter edit mode and add the following content.#!python import requests import json import sys import time # Get the next page URL from the response headers def get_next_link(resp): resp_link = resp.headers['link'] link = '' for l in resp_link.split(', '): link = l.split('; ')[0][1:-1] rel = l.split('; ')[1] if rel == 'rel="next"': return link return None # Download one page of data from the API def download(link, fname): # Define GitHub API Accept and Authorization headers headers = {"Accept": "application/vnd.github+json","Authorization": "<Bearer> <github_api_token>"} resp = requests.get(link, headers=headers) if int(resp.status_code) != 200: return None with open(fname, 'a') as f: for j in resp.json(): f.write(json.dumps(j)) f.write('\n') print('downloaded {} events to {}'.format(len(resp.json()), fname)) return resp # Download multiple pages of data from the API def download_all_data(fname): link = 'https://api.github.com/events?per_page=100&page=1' while True: resp = download(link, fname) if resp is None: break link = get_next_link(resp) if link is None: break # Get current timestamp in milliseconds def get_current_ms(): return round(time.time()*1000) # Run the script for exactly 1 minute def main(fname): current_ms = get_current_ms() while get_current_ms() - current_ms < 60*1000: download_all_data(fname) time.sleep(0.1) # Execute the script if __name__ == '__main__': if len(sys.argv) < 2: print('usage: python {} <log_file>'.format(sys.argv[0])) exit(0) main(sys.argv[1])Press Esc, type
:wq, and press Enter to save and exit.Create a
run_py.shfile to executedownload_realtime_data.pyand store the data from each run separately. The file contains the following content:python /opt/realtime/download_realtime_data.py /opt/realtime/gh_realtime_data/$(date '+%Y-%m-%d-%H:%M:%S').jsonCreate a
delete_log.shfile to remove old data. The file contains the following content:d=$(TZ=UTC date --date='2 day ago' '+%Y-%m-%d') rm -f /opt/realtime/gh_realtime_data/*${d}*.jsonRun the following commands to collect GitHub data every minute and delete old data daily.
#1 Run the following command and press I to enter edit mode. crontab -e #2 Add the following lines, then press Esc and type :wq to exit. * * * * * bash /opt/realtime/run_py.sh 1 1 * * * bash /opt/realtime/delete_log.sh
Collect ECS data using SLS
You can use Simple Log Service (SLS) to collect real-time event data from an ECS instance as logs.
SLS supports log collection from an ECS instance via Logtail. Because the data is in JSON format, you can use Logtail’s JSON mode to quickly ingest incremental JSON logs from the ECS instance. For more information about collection, see Collect logs using JSON mode. In this solution, SLS parses top-level key-value pairs from the raw data.
The log path parameter in the Logtail configuration is set to /opt/realtime/gh_realtime_data/**/*.json.
After configuration, SLS continuously collects incremental event data from the ECS instance. The following figure shows sample collected data.
Write SLS data to Hologres in real time using Flink
You can use Flink to write SLS-collected log data to Hologres in real time. By defining an SLS source table and a Hologres sink table in Flink, you can stream data from SLS to Hologres. For more information, see Import from SLS.
Create a Hologres internal table.
This table retains selected fields from the raw JSON data. Set the event
idand datedsas the primary key,idas the distribution key,dsas the partition key, andcreated_atas the event time column. You can create additional indexes based on your query patterns to improve performance. For more information about indexes, see CREATE TABLE. The following code provides the sample DDL:DROP TABLE IF EXISTS gh_realtime_data; BEGIN; CREATE TABLE gh_realtime_data ( id bigint, actor_id bigint, actor_login text, repo_id bigint, repo_name text, org_id bigint, org_login text, type text, created_at timestamp with time zone NOT NULL, action text, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id text, member_id bigint, rev_or_push_or_rel_id bigint, ref text, ref_type text, state text, author_association text, language text, merged boolean, merged_at timestamp with time zone, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr text, month text, year text, ds text, PRIMARY KEY (id,ds) ) PARTITION BY LIST (ds); CALL set_table_property('public.gh_realtime_data', 'distribution_key', 'id'); CALL set_table_property('public.gh_realtime_data', 'event_time_column', 'created_at'); CALL set_table_property('public.gh_realtime_data', 'clustering_key', 'created_at'); COMMENT ON COLUMN public.gh_realtime_data.id IS 'Event ID'; COMMENT ON COLUMN public.gh_realtime_data.actor_id IS 'Actor ID'; COMMENT ON COLUMN public.gh_realtime_data.actor_login IS 'Actor login name'; COMMENT ON COLUMN public.gh_realtime_data.repo_id IS 'Repository ID'; COMMENT ON COLUMN public.gh_realtime_data.repo_name IS 'Repository name'; COMMENT ON COLUMN public.gh_realtime_data.org_id IS 'Organization ID'; COMMENT ON COLUMN public.gh_realtime_data.org_login IS 'Organization name'; COMMENT ON COLUMN public.gh_realtime_data.type IS 'Event type'; COMMENT ON COLUMN public.gh_realtime_data.created_at IS 'Event occurrence time'; COMMENT ON COLUMN public.gh_realtime_data.action IS 'Event action'; COMMENT ON COLUMN public.gh_realtime_data.iss_or_pr_id IS 'Issue or pull request ID'; COMMENT ON COLUMN public.gh_realtime_data.number IS 'Issue or pull request number'; COMMENT ON COLUMN public.gh_realtime_data.comment_id IS 'Comment ID'; COMMENT ON COLUMN public.gh_realtime_data.commit_id IS 'Commit ID'; COMMENT ON COLUMN public.gh_realtime_data.member_id IS 'Member ID'; COMMENT ON COLUMN public.gh_realtime_data.rev_or_push_or_rel_id IS 'Review, push, or release ID'; COMMENT ON COLUMN public.gh_realtime_data.ref IS 'Name of created or deleted resource'; COMMENT ON COLUMN public.gh_realtime_data.ref_type IS 'Type of created or deleted resource'; COMMENT ON COLUMN public.gh_realtime_data.state IS 'State of issue, pull request, or pull request review'; COMMENT ON COLUMN public.gh_realtime_data.author_association IS 'Relationship between actor and repository'; COMMENT ON COLUMN public.gh_realtime_data.language IS 'Programming language'; COMMENT ON COLUMN public.gh_realtime_data.merged IS 'Whether the merge was accepted'; COMMENT ON COLUMN public.gh_realtime_data.merged_at IS 'Code merge time'; COMMENT ON COLUMN public.gh_realtime_data.additions IS 'Number of lines added'; COMMENT ON COLUMN public.gh_realtime_data.deletions IS 'Number of lines deleted'; COMMENT ON COLUMN public.gh_realtime_data.changed_files IS 'Number of files changed in pull request'; COMMENT ON COLUMN public.gh_realtime_data.push_size IS 'Number of commits'; COMMENT ON COLUMN public.gh_realtime_data.push_distinct_size IS 'Number of distinct commits'; COMMENT ON COLUMN public.gh_realtime_data.hr IS 'Hour of event occurrence (e.g., 00:23 → hr=00)'; COMMENT ON COLUMN public.gh_realtime_data.month IS 'Month of event occurrence (e.g., October 2015 → month=2015-10)'; COMMENT ON COLUMN public.gh_realtime_data.year IS 'Year of event occurrence (e.g., 2015 → year=2015)'; COMMENT ON COLUMN public.gh_realtime_data.ds IS 'Date of event occurrence (ds=yyyy-mm-dd)'; COMMIT;Write data in real time using Flink.
You can use Flink to further parse SLS data and write it to Hologres in real time. The following Flink SQL filters out dirty data, where the event ID or
created_atis null, and retains only recent events.CREATE TEMPORARY TABLE sls_input ( actor varchar, created_at varchar, id bigint, org varchar, payload varchar, public varchar, repo varchar, type varchar ) WITH ( 'connector' = 'sls', 'endpoint' = '<endpoint>',--The private endpoint of SLS 'accessid' = '<accesskey id>',--The AccessKey ID of your account 'accesskey' = '<accesskey secret>',--The AccessKey secret of your account 'project' = '<project name>',--The name of the SLS project 'logstore' = '<logstore name>',--The name of the SLS LogStore 'starttime' = '2023-04-06 00:00:00'--The start time for data ingestion from SLS ); CREATE TEMPORARY TABLE hologres_sink ( id bigint, actor_id bigint, actor_login string, repo_id bigint, repo_name string, org_id bigint, org_login string, type string, created_at timestamp, action string, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id string, member_id bigint, rev_or_push_or_rel_id bigint, `ref` string, ref_type string, state string, author_association string, `language` string, merged boolean, merged_at timestamp, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr string, `month` string, `year` string, ds string ) WITH ( 'connector' = 'hologres', 'dbname' = '<hologres dbname>', --The name of the Hologres database 'tablename' = '<hologres tablename>', --The name of the destination table in Hologres 'username' = '<accesskey id>', --The AccessKey ID of your Alibaba Cloud account 'password' = '<accesskey secret>', --The AccessKey secret of your Alibaba Cloud account 'endpoint' = '<endpoint>', --The VPC endpoint of the Hologres instance 'jdbcretrycount' = '1', --The number of retries upon a connection failure 'partitionrouter' = 'true', --Specifies whether to write data to a partitioned table 'createparttable' = 'true', --Specifies whether to automatically create partitions 'mutatetype' = 'insertorignore' --The data write mode ); INSERT INTO hologres_sink SELECT id ,CAST(JSON_VALUE(actor, '$.id') AS bigint) AS actor_id ,JSON_VALUE(actor, '$.login') AS actor_login ,CAST(JSON_VALUE(repo, '$.id') AS bigint) AS repo_id ,JSON_VALUE(repo, '$.name') AS repo_name ,CAST(JSON_VALUE(org, '$.id') AS bigint) AS org_id ,JSON_VALUE(org, '$.login') AS org_login ,type ,TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC') AS created_at ,JSON_VALUE(payload, '$.action') AS action ,CASE WHEN type='PullRequestEvent' THEN CAST(JSON_VALUE(payload, '$.pull_request.id') AS bigint) WHEN type='IssuesEvent' THEN CAST(JSON_VALUE(payload, '$.issue.id') AS bigint) END AS iss_or_pr_id ,CASE WHEN type='PullRequestEvent' THEN CAST(JSON_VALUE(payload, '$.pull_request.number') AS bigint) WHEN type='IssuesEvent' THEN CAST(JSON_VALUE(payload, '$.issue.number') AS bigint) ELSE CAST(JSON_VALUE(payload, '$.number') AS bigint) END AS number ,CAST(JSON_VALUE(payload, '$.comment.id') AS bigint) AS comment_id ,JSON_VALUE(payload, '$.comment.commit_id') AS commit_id ,CAST(JSON_VALUE(payload, '$.member.id') AS bigint) AS member_id ,CASE WHEN type='PullRequestReviewEvent' THEN CAST(JSON_VALUE(payload, '$.review.id') AS bigint) WHEN type='PushEvent' THEN CAST(JSON_VALUE(payload, '$.push_id') AS bigint) WHEN type='ReleaseEvent' THEN CAST(JSON_VALUE(payload, '$.release.id') AS bigint) END AS rev_or_push_or_rel_id ,JSON_VALUE(payload, '$.ref') AS `ref` ,JSON_VALUE(payload, '$.ref_type') AS ref_type ,CASE WHEN type='PullRequestEvent' THEN JSON_VALUE(payload, '$.pull_request.state') WHEN type='IssuesEvent' THEN JSON_VALUE(payload, '$.issue.state') WHEN type='PullRequestReviewEvent' THEN JSON_VALUE(payload, '$.review.state') END AS state ,CASE WHEN type='PullRequestEvent' THEN JSON_VALUE(payload, '$.pull_request.author_association') WHEN type='IssuesEvent' THEN JSON_VALUE(payload, '$.issue.author_association') WHEN type='IssueCommentEvent' THEN JSON_VALUE(payload, '$.comment.author_association') WHEN type='PullRequestReviewEvent' THEN JSON_VALUE(payload, '$.review.author_association') END AS author_association ,JSON_VALUE(payload, '$.pull_request.base.repo.language') AS `language` ,CAST(JSON_VALUE(payload, '$.pull_request.merged') AS boolean) AS merged ,TO_TIMESTAMP_TZ(replace(JSON_VALUE(payload, '$.pull_request.merged_at'),'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC') AS merged_at ,CAST(JSON_VALUE(payload, '$.pull_request.additions') AS bigint) AS additions ,CAST(JSON_VALUE(payload, '$.pull_request.deletions') AS bigint) AS deletions ,CAST(JSON_VALUE(payload, '$.pull_request.changed_files') AS bigint) AS changed_files ,CAST(JSON_VALUE(payload, '$.size') AS bigint) AS push_size ,CAST(JSON_VALUE(payload, '$.distinct_size') AS bigint) AS push_distinct_size ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),12,2) as hr ,REPLACE(SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,7),'/','-') as `month` ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,4) as `year` ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,10) as ds FROM sls_input WHERE id IS NOT NULL AND created_at IS NOT NULL AND to_date(replace(created_at,'T',' ')) >= date_add(CURRENT_DATE, -1);For more information about the parameters, see SLS source table and Hologres sink table.
NoteRaw event data from GitHub is in UTC but does not include a time zone attribute, while the default time zone for Hologres is UTC+8. Therefore, you must adjust the data's time zone when Flink writes data to Hologres in real time. To do this, assign the UTC time zone attribute to the source table data in Flink SQL, and add the
table.local-time-zone:Asia/Shanghaistatement in the Flink Configuration section on the Job Startup Configuration page to set the Flink system time zone toAsia/Shanghaiwhen the job starts.Query data.
You can query SLS data written to Hologres by Flink. You can then develop further analytics based on your business needs.
SELECT * FROM public.gh_realtime_data limit 10;Sample output:

Correct real-time data using offline data
In this scenario, the real-time data may have gaps. You can use offline data to correct the real-time data. The following steps show how to correct the previous day's real-time data. You can adjust the correction cycle based on your business needs.
Create a foreign table in Hologres to access MaxCompute offline data.
IMPORT FOREIGN SCHEMA <maxcompute_project_name> LIMIT to ( <foreign_table_name> ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'update',if_unsupported_type 'error');For more information about the parameters, see IMPORT FOREIGN SCHEMA.
You can use offline data to correct the previous day's real-time data by creating a temporary table.
NoteStarting from version 2.1.17, Hologres supports Serverless Computing. For large-scale offline imports, large ETL jobs, and high-volume foreign table queries, Serverless Computing uses extra serverless resources instead of your instance's resources. This improves stability and reduces out-of-memory (OOM) errors. You pay only for the tasks you run. For more information, see Serverless Computing. For usage instructions, see Serverless Computing User Guide.
-- Clean up any existing temporary table DROP TABLE IF EXISTS gh_realtime_data_tmp; -- Create a temporary table SET hg_experimental_enable_create_table_like_properties = ON; CALL HG_CREATE_TABLE_LIKE ('gh_realtime_data_tmp', 'select * from gh_realtime_data'); -- (Optional) Use Serverless Computing for large-scale offline imports and ETL SET hg_computing_resource = 'serverless'; -- Insert data into the temporary table and update statistics INSERT INTO gh_realtime_data_tmp SELECT * FROM <foreign_table_name> WHERE ds = current_date - interval '1 day' ON CONFLICT (id, ds) DO NOTHING; ANALYZE gh_realtime_data_tmp; -- Reset configuration to avoid unnecessary use of serverless resources RESET hg_computing_resource; -- Atomically replace the partition with the corrected data BEGIN; DROP TABLE IF EXISTS "gh_realtime_data_<yesterday_date>"; ALTER TABLE gh_realtime_data_tmp RENAME TO "gh_realtime_data_<yesterday_date>"; ALTER TABLE gh_realtime_data ATTACH PARTITION "gh_realtime_data_<yesterday_date>" FOR VALUES IN ('<yesterday_date>'); COMMIT;
Data analytics
With the collected data, you can perform rich analytics. You can design additional data warehouse layers based on your required time ranges to support real-time, offline, and unified analytics.
The following examples show how to analyze the real-time data collected in the previous steps. You can also analyze specific repositories or developers.
Query today’s total number of public events.
SELECT count(*) FROM gh_realtime_data WHERE created_at >= date_trunc('day', now());Sample output:
count ------ 1006Find the top 5 most active repositories by event count in the past day.
SELECT repo_name, COUNT(*) AS events FROM gh_realtime_data WHERE created_at >= now() - interval '1 day' GROUP BY repo_name ORDER BY events DESC LIMIT 5;Sample output:
repo_name events ----------------------------------------+------ leo424y/heysiri.ml 29 arm-on/plan 10 Christoffel-T/fiverr-pat-20230331 9 mate-academy/react_dynamic-list-of-goods 9 openvinotoolkit/openvino 7Find the top 5 most active developers by event count in the past day.
SELECT actor_login, COUNT(*) AS events FROM gh_realtime_data WHERE created_at >= now() - interval '1 day' AND actor_login NOT LIKE '%[bot]' GROUP BY actor_login ORDER BY events DESC LIMIT 5;Sample output:
actor_login events ------------------+------ direwolf-github 13 arm-on 10 sergii-nosachenko 9 Christoffel-T 9 yangwang201911 7Rank the top programming languages used in the past hour.
SELECT language, count(*) total FROM gh_realtime_data WHERE created_at > now() - interval '1 hour' AND language IS NOT NULL GROUP BY language ORDER BY total DESC LIMIT 10;Sample output:
language total -----------+---- JavaScript 25 C++ 15 Python 14 TypeScript 13 Java 8 PHP 8Rank repositories by stars added in the past day.
NoteThis example does not account for users who remove stars.
SELECT repo_id, repo_name, COUNT(actor_login) total FROM gh_realtime_data WHERE type = 'WatchEvent' AND created_at > now() - interval '1 day' GROUP BY repo_id, repo_name ORDER BY total DESC LIMIT 10;Sample output:
repo_id repo_name total ---------+----------------------------------+----- 618058471 facebookresearch/segment-anything 4 619959033 nomic-ai/gpt4all 1 97249406 denysdovhan/wtfjs 1 9791525 digininja/DVWA 1 168118422 aylei/interview 1 343520006 joehillen/sysz 1 162279822 agalwood/Motrix 1 577723410 huggingface/swift-coreml-diffusers 1 609539715 e2b-dev/e2b 1 254839429 maniackk/KKCallStack 1Query today’s daily active users and repositories.
SELECT uniq (actor_id) actor_num, uniq (repo_id) repo_num FROM gh_realtime_data WHERE created_at > date_trunc('day', now());Sample output:
actor_num repo_num ---------+-------- 743 816