After you create a MongoDB catalog, you can access a MongoDB collection in the Realtime Compute for Apache Flink console without the need to define the schema of the collection. This topic describes how to create, view, use, and drop a MongoDB catalog in the Realtime Compute for Apache Flink console.
Background information
A MongoDB catalog automatically parses Binary JSON (BSON)-formatted documents to infer the schema of a collection. Therefore, you can use a MongoDB catalog to obtain specific fields of a collection without the need to declare the schema of the collection in the Realtime Compute for Apache Flink SQL. When you use a MongoDB catalog, take note of the following points:
The name of a table of a MongoDB catalog matches the name of a MongoDB collection. This way, you do not need to execute DDL statements to register a MongoDB table to access the MongoDB collection. This improves data development efficiency and data accuracy.
Tables of MongoDB catalogs can be used as source tables, dimension tables, and result tables in the deployments of the Realtime Compute for Apache Flink SQL.
In Realtime Compute for Apache Flink that uses Ververica Runtime (VVR) 8.0.6 or later, you can use MongoDB catalogs together with the CREATE TABLE AS statement or the CREATE DATABASE AS statement to synchronize table schema changes.
This topic describes the operations that you can perform to manage MongoDB catalogs:
Limits
Only Realtime Compute for Apache Flink that uses Ververica Runtime (VVR) 8.0.5 or later supports MongoDB catalogs.
You cannot modify the existing MongoDB catalogs by executing DDL statements.
You can only query data from tables by using MongoDB catalogs. You are not allowed to create, modify, or delete databases and tables by using MongoDB catalogs.
Create a MongoDB catalog
In the code editor of the Scripts tab on the SQL Editor page, enter the statement for creating a MongoDB catalog.
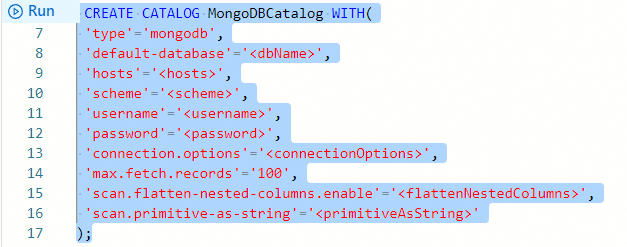
CREATE CATALOG <yourcatalogname> WITH( 'type'='mongodb', 'default-database'='<dbName>', 'hosts'='<hosts>', 'scheme'='<scheme>', 'username'='<username>', 'password'='<password>', 'connection.options'='<connectionOptions>', 'max.fetch.records'='100', 'scan.flatten-nested-columns.enable'='<flattenNestedColumns>', 'scan.primitive-as-string'='<primitiveAsString>' );Parameter
Data type
Description
Required
Remarks
yourcatalogname
STRING
The name of the MongoDB catalog.
Yes
Enter a custom name.
ImportantYou must remove the angle brackets (<>) when you replace the value of the parameter with the name of your catalog. Otherwise, an error is returned during the syntax check.
type
STRING
The type of the catalog.
Yes
Set the value to mongodb.
hosts
STRING
The name of the host where the MongoDB instance resides.
Yes
Separate multiple hostnames with commas (
,).default-database
STRING
The name of the default MongoDB database.
Yes
N/A.
scheme
STRING
The connection protocol that is used by the MongoDB database.
No
Valid values:
mongodb: The default MongoDB protocol is used to access the MongoDB database. This is the default value.mongodb+srv: The DNS SRV record protocol is used to access the MongoDB database.
username
STRING
The username that is used to connect to the MongoDB database.
No
This parameter is required if the identity verification feature is enabled for the MongoDB database.
password
STRING
The password that is used to connect to the MongoDB database.
No
This parameter is required if the identity verification feature is enabled for the MongoDB database.
NoteTo prevent password leaks, we recommend that you use the key management method to specify your password. For more information, see Manage variables and keys.
connection.options
STRING
The parameters that are configured for the connection to the MongoDB database.
No
The parameters are key-value pairs that are in the
key=valueformat and separated by ampersands (&), such as connectTimeoutMS=12000&socketTimeoutMS=13000.max.fetch.records
INT
The maximum number of documents that the MongoDB catalog can attempt to obtain when the MongoDB catalog parses BSON-formatted documents.
No
Default value: 100.
scan.flatten-nested-columns.enabled
BOOLEAN
Specifies whether to recursively expand nested columns in the documents when BSON-formatted documents are parsed.
No
Valid values:
true: Nested columns are recursively expanded. Realtime Compute for Apache Flink uses the path that indexes the value of the column that is expanded as the name of the column. For example, the col column in
{"nested": {"col": true}}is named nested.col after the column is expanded.false: Nested BSON-formatted documents are parsed as the STRING type. This is the default value.
ImportantOnly tables of MongoDB catalogs that are used as source tables in the deployments of the Realtime Compute for Apache Flink SQL support this parameter.
scan.primitive-as-string
BOOLEAN
Specifies whether to infer all basic data types as the STRING type when BSON-formatted documents are parsed.
No
Valid values:
true: All basic data types are inferred as the STRING type.
false: Data types are inferred based on the data type mappings. This is the default value. For more information about the data type mappings, see Learn about the details of a table of a MongoDB catalog.
Select the code that is used to create a catalog and click Run on the left side of the code.
In the Catalogs pane on the left side of the Catalog List page, view the catalog that you create.
View a MongoDB catalog
In the code editor of the Scripts tab on the SQL Editor page, enter the following statement:
DESCRIBE `${catalog_name}`.`${db_name}`.`${collection_name}`;Parameter
Description
${catalog_name}
The name of the MongoDB catalog.
${db_name}
The name of the ApsaraDB for MongoDB database.
${collection_name}
The name of the ApsaraDB for MongoDB collection.
Select the code that is used to view a catalog and click Run on the left side of the code.
After the code is run, you can view the information about the table in the result.

Use a MongoDB catalog
If a table of a MongoDB catalog is used as a source table, you can read data from the MongoDB collection that matches the table.
INSERT INTO ${other_sink_table} SELECT... FROM `${mongodb_catalog}`.`${db_name}`.`${collection_name}` /*+OPTIONS('scan.incremental.snapshot.enabled'='true')*/;NoteIf you want to specify other parameters in the WITH clause when you use a MongoDB catalog, we recommend that you use SQL hints to add the parameters. In the preceding SQL statement, SQL hints are used to enable the parallel reading mode in the initial snapshot phase. For more information about other parameters, see MongoDB connector.
If a table of a MongoDB catalog is used as a source table, you can execute the CREATE TABLE AS statement or CREATE DATABASE AS statement to synchronize data from the MongoDB collection that matches the table to the destination table.
ImportantWhen you use the CREATE TABLE AS or CREATE DATABASE AS statement to synchronize data from a MongoDB collection that matches the table to the destination table, make sure that the following business requirements are met:
The VVR version is 8.0.6 or later. The MongoDB database version is 6.0 or later.
The scan.incremental.snapshot.enabled and scan.full-changelog parameters are set to true in the SQL hints.
The preimage feature is enabled in the MongoDB database. For more information about how to enable the preimage feature, see Document Preimages.
Synchronize data from a single topic in real time.
CREATE TABLE IF NOT EXISTS `${target_table_name}` WITH(...) AS TABLE `${mongodb_catalog}`.`${db_name}`.`${collection_name}` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */;Synchronize data from multiple topics in a deployment.
BEGIN STATEMENT SET; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table0` AS TABLE `mongodb-catalog`.`database`.`collection0` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table1` AS TABLE `mongodb-catalog`.`database`.`collection1` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table2` AS TABLE `mongodb-catalog`.`database`.`collection2` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */; END;You can use the CREATE TABLE AS statement together with MongoDB catalogs to synchronize data from multiple MongoDB collections in a deployment. To synchronize data from multiple MongoDB collections in a deployment, make sure that the configurations of the following parameters for all tables in the deployment are the same:
Parameters related to the MongoDB database, including hosts, scheme, username, password, and connectionOptions
scan.startup.mode
Synchronize data from the entire MongoDB database.
CREATE DATABASE IF NOT EXISTS `some_catalog`.`some_database` AS DATABASE `mongodb-catalog`.`database` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */;
Read data from a MongoDB dimension table.
INSERT INTO ${other_sink_table} SELECT ... FROM ${other_source_table} AS e JOIN `${mysql_catalog}`.`${db_name}`.`${table_name}` FOR SYSTEM_TIME AS OF e.proctime AS w ON e.id = w.id;Write result data to a MongoDB table.
INSERT INTO `${mysql_catalog}`.`${db_name}`.`${table_name}` SELECT ... FROM ${other_source_table}
Drop a MongoDB catalog
After you drop a MongoDB catalog, the deployments that are running are not affected. However, the deployment that uses a table of the catalog cannot find the table when the deployment is published or restarted. Proceed with caution when you drop a MongoDB catalog.
In the code editor of the Scripts tab on the SQL Editor page, enter the following statement:
DROP CATALOG ${catalog_name};${catalog_name} specifies the name of the MongoDB catalog that you want to drop.
Right-click the statement that is used to delete the catalog and choose Run from the shortcut menu.
View the Catalogs pane on the left side of the Catalog List page to check whether the catalog is dropped.
Schema inference description
When a MongoDB catalog infers the schema of a table, the MongoDB catalog automatically adds default parameters and primary key information to the table. This helps you easily learn about the details of the table. When a MongoDB catalog parses BSON-formatted documents to obtain the schema of a collection, the MongoDB catalog attempts to consume data records. The maximum number of data records that the MongoDB catalog can attempt to consume is specified by the max.fetch.records parameter. The catalog parses the schema of each data record and merges the schemas of data records into the schema of the collection. The schema of a collection consists of the following parts:
Physical columns
The MongoDB catalog infers physical columns based on BSON-formatted documents.
Default primary key that is added
For a table of a MongoDB catalog, the _id column is used as the primary key to prevent duplicate data.
After the MongoDB catalog obtains a group of BSON-formatted documents, the MongoDB catalog parses the documents in sequence and merges the obtained physical columns to obtain the schema of the collection based on the following rules: This function merges JSON documents based on the following rules:
If a field in the obtained physical columns is not contained in the schema of the collection, the MongoDB catalog automatically adds the field to the schema of the collection.
If specific physical columns that are obtained after parsing are named the same as specific columns in the topic schema, perform operations based on your business scenario:
If the columns are of the same data type but different precision, the Kafka JSON catalog merges the columns of the larger precision.
If the columns are of different data types, the Kafka JSON catalog uses the smallest parent node in the tree structure that is shown in the following figure as the type of the columns that have the same name. If columns of the DECIMAL and FLOAT types are merged, the columns are merged into the DOUBLE type to retain the precision.

The following table describes the data type mappings between BSON and Realtime Compute for Apache Flink SQL when the schema of a collection is inferred.
BSON data type | Data type of Realtime Compute for Apache Flink SQL |
Boolean | BOOLEAN |
Int32 | INT |
Int64 | BIGINT |
Binary | BYTES |
Double | DOUBLE |
Decimal128 | DECIMAL |
String | STRING |
ObjectId | STRING |
DateTime | TIMESTAMP_LTZ(3) |
Timestamp | TIMESTAMP_LTZ(0) |
Array | STRING |
Document | STRING |
References
For more information about how to use the MongoDB connector, see MongoDB connector.
If the built-in catalogs of Realtime Compute for Apache Flink cannot meet your business requirements, you can use custom catalogs. For more information, see Manage custom catalogs.