This topic describes how to troubleshoot issues related to Hive jobs.
Locate exceptions
If an exception such as a performance exception occurs when you run a job on the Hive client, you can perform the following steps to locate the exception:
View the logs of the Hive client.
The logs of jobs that are submitted by using Hive CLI are stored in the /tmp/hive/$USER/hive.log or /tmp/$USER/hive.log directory of the cluster or gateway node.
The logs of jobs that are submitted by using Hive Beeline or Java Database Connectivity (JDBC) are stored in the directory where HiveServer logs are stored. In most cases, the directory is /var/log/emr/hive or /mnt/disk1/log/hive.
View the logs of the YARN application that is submitted by a Hive job. You can run the yarn command to obtain the logs.
yarn logs -applicationId application_xxx_xxx -appOwner userName
Memory-related issues
An out-of-memory (OOM) error occurs due to insufficient container memory
Error message: java.lang.OutOfMemoryError: GC overhead limit exceeded or java.lang.OutOfMemoryError: Java heap space
Solution: Increase the memory of the container. For a Hive job that runs on MapReduce (MR), you also need to increase the Java virtual machine (JVM) heap memory.
Hive jobs that run on MR: On the Configure tab of the YARN service page, click the mapred-site.xml tab and increase the values of the following mapper and reducer memory parameters.
mapreduce.map.memory.mb=4096 mapreduce.reduce.memory.mb=4096You also need to change the JVM
-Xmxvalues of the mapreduce.map.java.opts and mapreduce.reduce.java.opts parameters to 80% of the values that you specified for the mapreduce.map.memory.mb and mapreduce.reduce.memory.mb parameters, respectively.mapreduce.map.java.opts=-Xmx3276m (Retain the values of other options for the parameter.) mapreduce.reduce.java.opts=-Xmx3276m (Retain the values of other options for the parameter.)Hive jobs that run on Tez
If the memory of the Tez container is insufficient, click the hive-site.xml tab on the Configure tab of the Hive service page and increase the value of the hive.tez.container.size parameter.
hive.tez.container.size=4096If the memory of Tez AppMaster is insufficient, click the tez-site.xml tab on the Configure tab of the Tez service page and increase the value of the tez.am.resource.memory.mb parameter.
tez.am.resource.memory.mb=4096
Hive jobs that run on Spark: On the Configure tab of the Spark service page, click the
spark-defaults.conftab and increase the value of the spark.executor.memory parameter.spark.executor.memory=4g
The container is killed by YARN due to excessive memory usage
Error message: Container killed by YARN for exceeding memory limits
Cause: The memory that is used by a Hive task exceeds the memory that the job requests from YARN. The memory includes JVM heap memory, JVM off-heap memory, and memory that is used by child processes. For example, if the heap size of the Map Task JVM process of a Hive job that runs on MR is 4 GB (mapreduce.map.java.opts=-Xmx4g), and the memory that the job requested from YARN is 3 GB (mapreduce.map.memory.mb=3072), the container will be killed by YARN NodeManager.
Solution:
For a Hive job that runs on MR, increase the values of the mapreduce.map.memory.mb and mapreduce.reduce.memory.mb parameters. Make sure that the values of the parameters are at least 1.25 times the JVM
-Xmxvalues of the mapreduce.map.java.opts and mapreduce.reduce.java.opts parameters.For a Hive job that runs on Spark, increase the value of the spark.executor.memoryOverhead parameter. Make sure that the value of the parameter is at least 25% of the value of the spark.executor.memory parameter.
An OOM error occurs because the sort buffer size is excessively large
Error message:
Error running child: java.lang.OutOfMemoryError: Java heap space at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:986)Cause: The sort buffer size exceeds the memory size that is allocated by a Hive task to the container. For example, the memory size for a container is 1300 MB, but the sort buffer size is 1024 MB.
Solution: Increase the memory size of the container or decrease the sort buffer size.
tez.runtime.io.sort.mb (Hive on Tez) mapreduce.task.io.sort.mb (Hive on MR)
An OOM error occurs due to GroupBy statements
Error message:
22/11/28 08:24:43 ERROR Executor: Exception in task 1.0 in stage 0.0 (TID 0) java.lang.OutOfMemoryError: GC overhead limit exceeded at org.apache.hadoop.hive.ql.exec.GroupByOperator.updateAggregations(GroupByOperator.java:611) at org.apache.hadoop.hive.ql.exec.GroupByOperator.processHashAggr(GroupByOperator.java:813) at org.apache.hadoop.hive.ql.exec.GroupByOperator.processKey(GroupByOperator.java:719) at org.apache.hadoop.hive.ql.exec.GroupByOperator.process(GroupByOperator.java:787) at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:897) at org.apache.hadoop.hive.ql.exec.SelectOperator.process(SelectOperator.java:95) at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:897) at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:130) at org.apache.hadoop.hive.ql.exec.MapOperator$MapOpCtx.forward(MapOperator.java:148) at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:547)Cause: The hash tables that are generated by GroupBy statements occupy excessive memory.
Solution:
Decrease the split size to 128 MB, 64 MB, or less, or increase the job concurrency. For example, you can set the
mapreduce.input.fileinputformat.split.maxsizeparameter to134217728or 67108864.Increase the concurrency of mappers and reducers.
Increase the memory of the container. For more information, see An out of memory (OOM) error occurs due to insufficient container memory.
An OOM error occurs when Snappy files are read
Cause: The format of standard Snappy files that are written by a service such as Log Service is different from the format of Hadoop Snappy files. By default, EMR processes Hadoop Snappy files. As a result, an OOM error is reported when EMR processes standard Snappy files.
Solution: Configure the following parameter for the Hive job:
set io.compression.codec.snappy.native=true;
Metadata-related errors
The operation for dropping a large partitioned table timed out
Error message:
FAILED: Execution ERROR, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timeoutCause: The partitioned table contains an excessive number of partitions. As a result, the drop operation requires a long period of time, and the network timed out when the Hive client accesses the Metastore service.
Solution:
On the Configure tab of the Hive service page in the EMR console, click the hive-site.xml tab and increase the timeout period for the Hive client to access the Metastore service.
hive.metastore.client.socket.timeout=1200sDrop multiple partitions in a batch. For example, you can repeatedly execute statements to drop partitions that meet specific conditions.
alter table [TableName] DROP IF EXISTS PARTITION (ds<='20220720')
A job fails when the insert overwrite statement is executed to insert data into a dynamic partition
Error message: When the
insert overwritestatement is executed in a job to insert data into a dynamic partition, or a similar job that contains theinsert overwritestatement is run, the error "Exception when loading xxx in table" occurs. The following error message appears in the logs of HiveServer:Error in query: org.apache.hadoop.hive.ql.metadata.HiveException: Directory oss://xxxx could not be cleaned up.;Cause: The metadata is inconsistent with the data. The metadata contains information about a partition, but the directory of the partition cannot be found in the data storage system. As a result, an error occurs when the cleanup operation is performed.
Solution: Troubleshoot the metadata issue and run the job again.
The error "java.lang.IllegalArgumentException: java.net.UnknownHostException: emr-header-1.xxx" occurs when a Hive job reads or deletes a table
Cause: If an EMR cluster uses Data Lake Formation (DLF) or a unified metadatabase (supported in the old EMR console) as the storage backend, the initial path of the database that you create is an HDFS path of the EMR cluster. Example:
hdfs://master-1-1.xxx:9000/user/hive/warehouse/test.dborhdfs://emr-header-1.cluster-xxx:9000/user/hive/warehouse/test.db. In this case, the Hive tables that you create in the database are also stored in the HDFS path. Example:hdfs://master-1-1.xxx:9000/user/hive/warehouse/test.db/test_tbl. If you use Hive in a cluster in the new EMR console to read data from or write data to a Hive table or database that is created by a cluster in the old EMR console, the new cluster may fail to connect to the old cluster. In addition, if the old cluster is released, the error "java.net.UnknownHostException" is returned.Solutions:
Solution 1: If data in the Hive table of the old EMR cluster is temporary data or test data, change the path of the Hive table to an Object Storage Service (OSS) path and run the drop table or drop database command again to drop the Hive table or database.
-- Hive SQL alter table test_tbl set location 'oss://bucket/not/exists' drop table test_tbl; alter table test_pt_tbl partition (pt=xxx) set location 'oss://bucket/not/exists'; alter table test_pt_tbl drop partition pt=xxx); alter database test_db set location 'oss://bucket/not/exists' drop datatabase test_dbSolution 2: If data in the Hive table of the old EMR cluster is valid but cannot be accessed from the new cluster, the data is stored in HDFS. In this case, migrate the data to OSS and create a table.
hadoop fs -cp hdfs://emr-header-1.xxx/old/path oss://bucket/new/path hive -e "create table new_tbl like old_tbl location 'oss://bucket/new/path'"
Issues related to Hive UDFs and third-party packages
A conflict occurs due to third-party packages that are placed in the Hive lib directory
Cause: A third-party package of Hive is placed in the $HIVE_HOME/lib directory, or the original Hive JAR package is replaced.
Solution: If a third-party package of Hive is placed in the $HIVE_HOME/lib directory, remove the third-party package from the directory. If the original Hive JAR package is replaced, place the original Hive JAR package back to the directory.
Hive fails to use the reflect function
Cause: Ranger authentication is enabled.
Solution: Remove the reflect function from the blacklist that is configured in the
hive-site.xmlfile.hive.server2.builtin.udf.blacklist=empty_blacklist
Jobs run slowly due to custom UDFs
Cause: If a job runs slowly but no error logs are returned, the issue may be caused by low performance of custom Hive UDFs.
Solution: Identify the performance issue by using the thread dump of a Hive task and optimize the custom Hive UDFs.
An exception occurs when Hive parses the grouping() function
Symptom: When the
grouping()function is used in an SQL statement, the following error message is reported:grouping() requires at least 2 argument, got 1The error message indicates that an exception occurs in parsing the arguments of the
grouping()function.Cause: This issue is caused by a known bug in open source Hive. Parsing of the
grouping()function in Hive is case-sensitive. If you usegrouping()instead ofGROUPING(), Hive may fail to recognize the function, resulting in an argument parsing error.Solution: Change
grouping()in the SQL statement toGROUPING().
Issues related to engine compatibility
The execution result differs because the time zone of Hive is different from that of Spark
Symptom: Hive uses UTC, and Spark uses the local time zone. As a result, the execution result is different.
Solution: Change the time zone of Spark to UTC. Insert the following sample code into Spark SQL:
spark.sql.session.timeZone=UTCYou can also add the following configuration to the configuration file of Spark:
spark.sql.session.timeZone=UTC
Issues related to Hive versions
Hive jobs run slowly on Spark because dynamic resource allocation is enabled (known defect)
Cause: The open source Hive has defects, and the spark.dynamicAllocation.enabled parameter is set to true when you connect to Spark by using Beeline. As a result, the number of shuffle partitions is counted as 1.
Solution: Disable dynamic resource allocation for Hive jobs that run on Spark. Alternatively, run Hive jobs on Tez.
spark.dynamicAllocation.enabled=false
Tez throws an exception when the hive.optimize.dynamic.partition.hashjoin parameter is set to true (known defect)
Error message:
Vertex failed, vertexName=Reducer 2, vertexId=vertex_1536275581088_0001_5_02, diagnostics=[Task failed, taskId=task_1536275581088_0001_5_02_000009, diagnostics=[TaskAttempt 0 failed, info=[Error: Error while running task ( failure ) : attempt_1536275581088_0001_5_02_000009_0:java.lang.RuntimeException: java.lang.RuntimeException: cannot find field _col1 from [0:key, 1:value] at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:296) at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:250)Cause: The open source Hive has defects.
Solution: Set the hive.optimize.dynamic.partition.hashjoin parameter to false.
hive.optimize.dynamic.partition.hashjoin=false
MapJoinOperator throws the NullPointerException exception (known defect)
Error message:
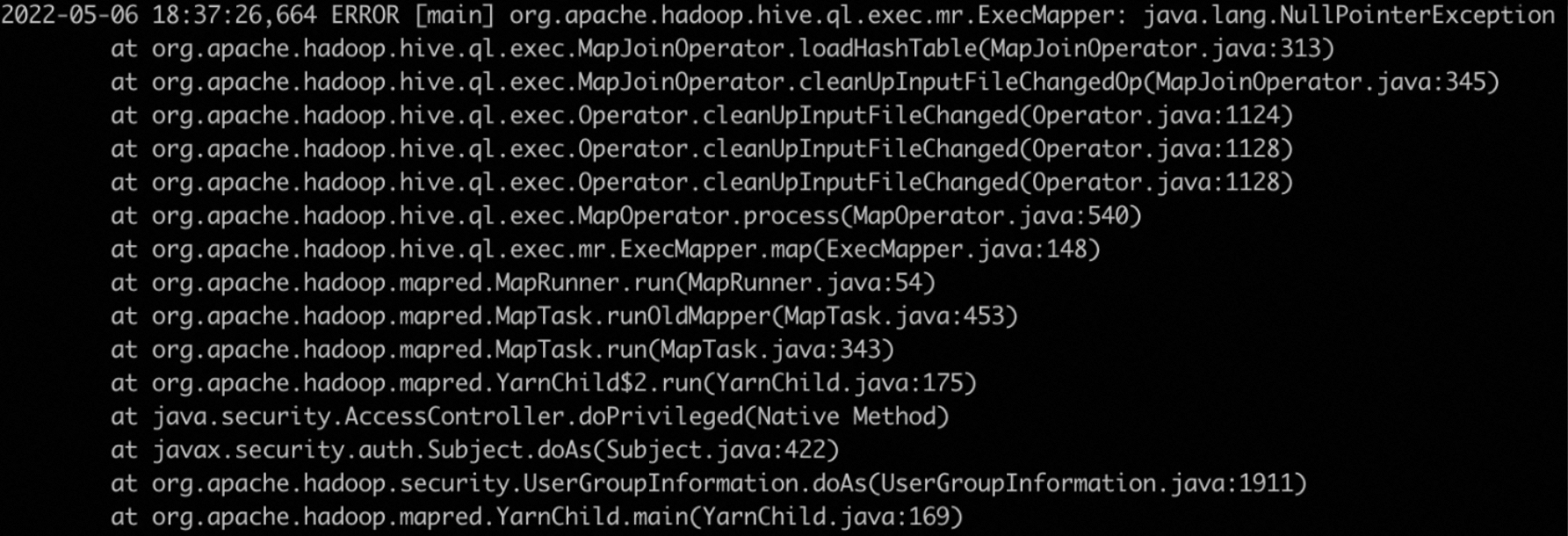
Cause: The hive.auto.convert.join.noconditionaltask parameter is set to true.
Solution: Set the hive.auto.convert.join.noconditionaltask parameter to false.
hive.auto.convert.join.noconditionaltask=false
Hive throws the IllegalStateException exception when a Hive job runs on Tez (known defect)
Error message:
java.lang.RuntimeException: java.lang.IllegalStateException: Was expecting dummy store operator but found: FS[17] at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:296) at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:250) at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:374) at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:73) at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:61) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730) at org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:61) at org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:37) at org.apache.tez.common.CallableWithNdc.call(CallableWithNdc.java:36)Cause: The open source Hive has defects. This issue occurs when the tez.am.container.reuse.enabled parameter is set to true.
Solution: Set the tez.am.container.reuse.enabled parameter to false for Hive jobs.
set tez.am.container.reuse.enabled=false;
Other issues
The result that is obtained by executing the select count(1) statement is 0
Cause: The
select count(1)statement uses the statistics of the Hive table, but the statistics on this table are inaccurate.Solution: Set the hive.compute.query.using.stats parameter to false.
hive.compute.query.using.stats=falseYou can also run the analyze command to recollect the statistics of the Hive table.
analyze table <table_name> compute statistics;
An error occurs when a Hive job is submitted on a self-managed Elastic Compute Service (ECS) instance
If you submit a Hive job on a self-managed ECS instance, an error occurs. Submit Hive jobs on an EMR gateway cluster or by using EMR CLI. For more information, see Use EMR-CLI to deploy a gateway.
An exception occurs on a job due to data skew
Symptoms:
The disk space is exhausted by shuffle data.
Some tasks require a long period of time to execute.
An OOM error occurs in some tasks or containers.
Solutions:
Enable skew join optimization of Hive.
set hive.optimize.skewjoin=true;Increase the concurrency of mappers and reducers.
Increase the memory of the container. For more information, see An out of memory (OOM) error occurs due to insufficient container memory.
The error "Too many counters: 121 max=120" occurs
Symptom: An error is reported when you use Hive SQL to run a job on the Tez or MR engine.
Cause: The number of counters in the current job exceeds the default upper limit.
Solution: On the Configure tab of the YARN service page in the EMR console, search for the mapreduce.job.counters.max parameter, increase the value of the parameter, and then submit the Hive job again. If you use Beeline or JDBC to submit the job, you must restart HiveServer.