Celeborn is a service that processes intermediate data. Celeborn can improve the stability, flexibility, and performance of big data compute engines. This topic describes how to use the Celeborn service.
Background information
The current shuffle solution has the following disadvantages:
A data overflow occurs if a large amount of data exists in a shuffle write task. This causes write amplification.
A large number of small-size network packets exist in a shuffle read task. This causes connection reset.
A large number of small-size I/O requests and random reads exist in a shuffle read task. This causes high disk and CPU loads.
If thousands of mappers (M) and reducers (N) are used, a large number of connections are generated, which makes it difficult for jobs to run. The number of connections is calculated by using the following formula: M × N.
The Spark shuffle service runs on NodeManager. If the amount of data involved in shuffling is extremely large, NodeManager will be restarted. This affects the stability of YARN-based task scheduling.
The Celeborn service can optimize the Shuffle solution. The Celeborn service has the following advantages:
Reduces the memory pressure that is caused by mappers by using push-style shuffle instead of pull-style shuffle.
Supports I/O aggregation, reduces the number of connections in a shuffle read task from M × N to N, and converts random read to sequential read.
Uses a two-replica mechanism to reduce the probability of fetch failures.
Supports compute-storage separation. The shuffle service can be deployed in a separated hardware environment.
Eliminates the dependency on local disks when Spark on Kubernetes is used.
The following figure shows the architecture of Celeborn.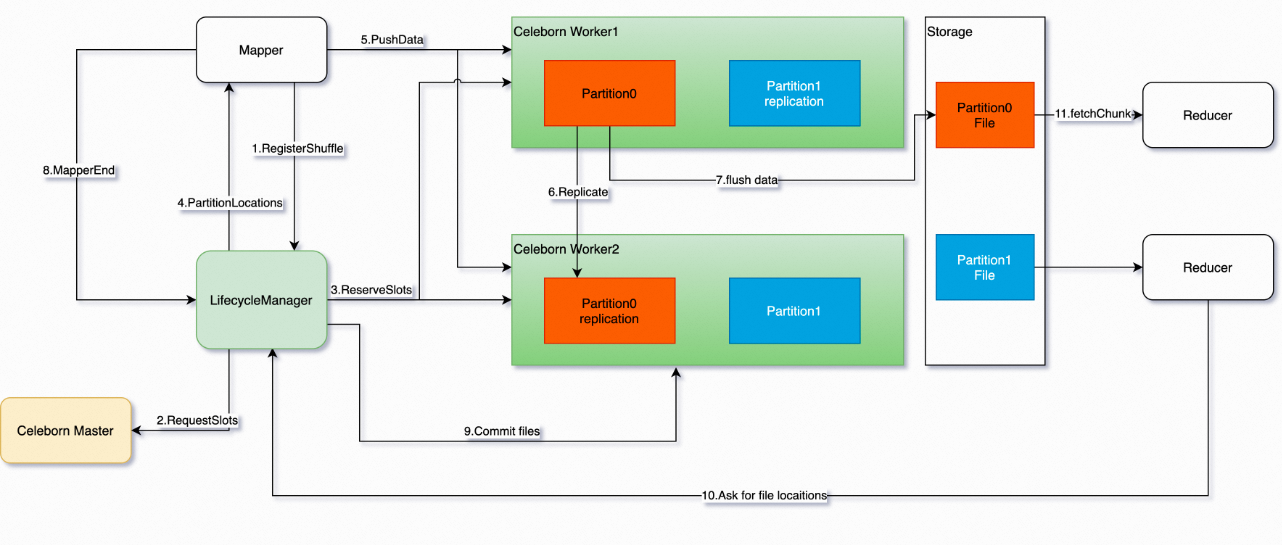
Prerequisites
An E-MapReduce (EMR) DataLake cluster or a custom cluster is created, and the Celeborn service is selected for the cluster. For more information about how to create a cluster, see Create a cluster.
Limits
This topic applies only to the clusters described in the following table.
Cluster | Version |
DataLake cluster | EMR V3.45.0 or a later minor version, and EMR V5.11.0 or a later minor version |
Custom cluster | EMR V3.45.0 or a later minor version, and EMR V5.11.0 or a later minor version |
Procedure
Spark parameters
Parameter | Description |
spark.shuffle.manager |
|
spark.serializer | Set the value to org.apache.spark.serializer.KryoSerializer. |
spark.celeborn.push.replicate.enabled | Specifies whether to enable the two-replica feature. Valid values:
|
spark.shuffle.service.enabled | Change the value of this parameter to false. To use Celeborn, you must disable the external shuffle service. Celeborn does not affect the use of the dynamic allocation feature of Spark. Note
|
spark.celeborn.shuffle.writer | The write mode of Celeborn.
|
spark.celeborn.master.endpoints | Specify a value for this parameter in the <celeborn-master-ip>:<celeborn-master-port> format. Parameters:
If you create a high-availability cluster, we recommend that you configure the IP addresses of all master nodes. |
spark.sql.adaptive.enabled | You can enable adaptive execution for the Celeborn service. You can disable the local shuffle reader to ensure high shuffle performance. You must set the spark.sql.adaptive.enabled parameter to true, the spark.sql.adaptive.localShuffleReader.enabled parameter to false, and the spark.sql.adaptive.skewJoin.enabled parameter to true. |
spark.sql.adaptive.localShuffleReader.enabled | |
spark.sql.adaptive.skewJoin.enabled |
You can enable the Celeborn service in Spark with one click.
Clusters of EMR V5.11.1 or a later minor version and of EMR V3.45.1 or a later minor version
In the Service Overview section of the Status tab of the Spark service page, turn on enableCeleborn.
Clusters of EMR V5.11.0 and of EMR V3.45.0
In the Components section of the Status tab of the Spark service page, find the SparkThriftServer component, move the pointer over the
 icon in the Actions column, and then select enableCeleborn. After you click enableCeleborn, the Spark parameters that are described in the preceding table are automatically modified, and the SparkThriftServer component is restarted. The spark-defaults.conf and spark-thriftserver.conf configuration files are also automatically modified.
icon in the Actions column, and then select enableCeleborn. After you click enableCeleborn, the Spark parameters that are described in the preceding table are automatically modified, and the SparkThriftServer component is restarted. The spark-defaults.conf and spark-thriftserver.conf configuration files are also automatically modified. If you click enableCeleborn, all Spark jobs in the cluster use the Celeborn service.
If you click disableCeleborn, all Spark jobs in the cluster do not use the Celeborn service.
Celeborn parameters
You can view or modify the configurations of all Celeborn parameters on the Configure tab of the Celeborn service page. The following table describes the parameters.
The values of the parameters vary based on the node group.
Parameter | Description | Default value |
celeborn.worker.flusher.threads | The number of threads when data is written to a hard disk (HDD) or a solid-state disk (SSD) disk. |
|
CELEBORN_WORKER_OFFHEAP_MEMORY | The size of the off-heap memory of a worker node. | The default value is calculated based on the cluster settings. |
celeborn.application.heartbeat.timeout | The heartbeat timeout period of your application. Unit: seconds. After the heartbeat timeout period elapses, application-related resources are cleared. | 120s |
celeborn.worker.flusher.buffer.size | The size of a flush buffer. If the size of a flush buffer exceeds the upper limit, flushing is triggered. | 256K |
celeborn.metrics.enabled | Specifies whether to enable monitoring. Valid values:
| true |
CELEBORN_WORKER_MEMORY | The size of the heap memory of a core node. | 1g |
CELEBORN_MASTER_MEMORY | The size of the heap memory of the master node. | 2g |
Restart the CelebornMaster component
On the Status tab of the Celeborn service page, find the CelebornMaster component, move the pointer over the
icon in the Actions column, and then select restart_clean_meta. NoteIf the cluster is a non-high-availability cluster, you can click Restart in the Actions column of the CelebornMaster component.
In the dialog box that appears, turn off Rolling Execution, configure the Execution Reason parameter, and then click OK.
In the Confirm message, click OK.