Distinguished DataWorks users:
To provide better user experience, from October 20, 2023, the DataWorks development team plans to gradually integrate the following types of compute engines in DataWorks into data sources of the same types: MaxCompute, Hologres, AnalyticDB for PostgreSQL, AnalyticDB for MySQL, and ClickHouse. The team also plans to integrate the E-MapReduce (EMR) and Cloudera's Distribution including Apache Hadoop (CDH) compute engines into open source clusters. These integrations aim to facilitate the unified management of compute engines.
Integration of compute engines into data sources
The following types of compute engines in DataWorks are integrated into data sources of the same types: MaxCompute, Hologres, AnalyticDB for PostgreSQL, AnalyticDB for MySQL, and ClickHouse. You must take note of the following items about the preceding types of compute engines after the integration:
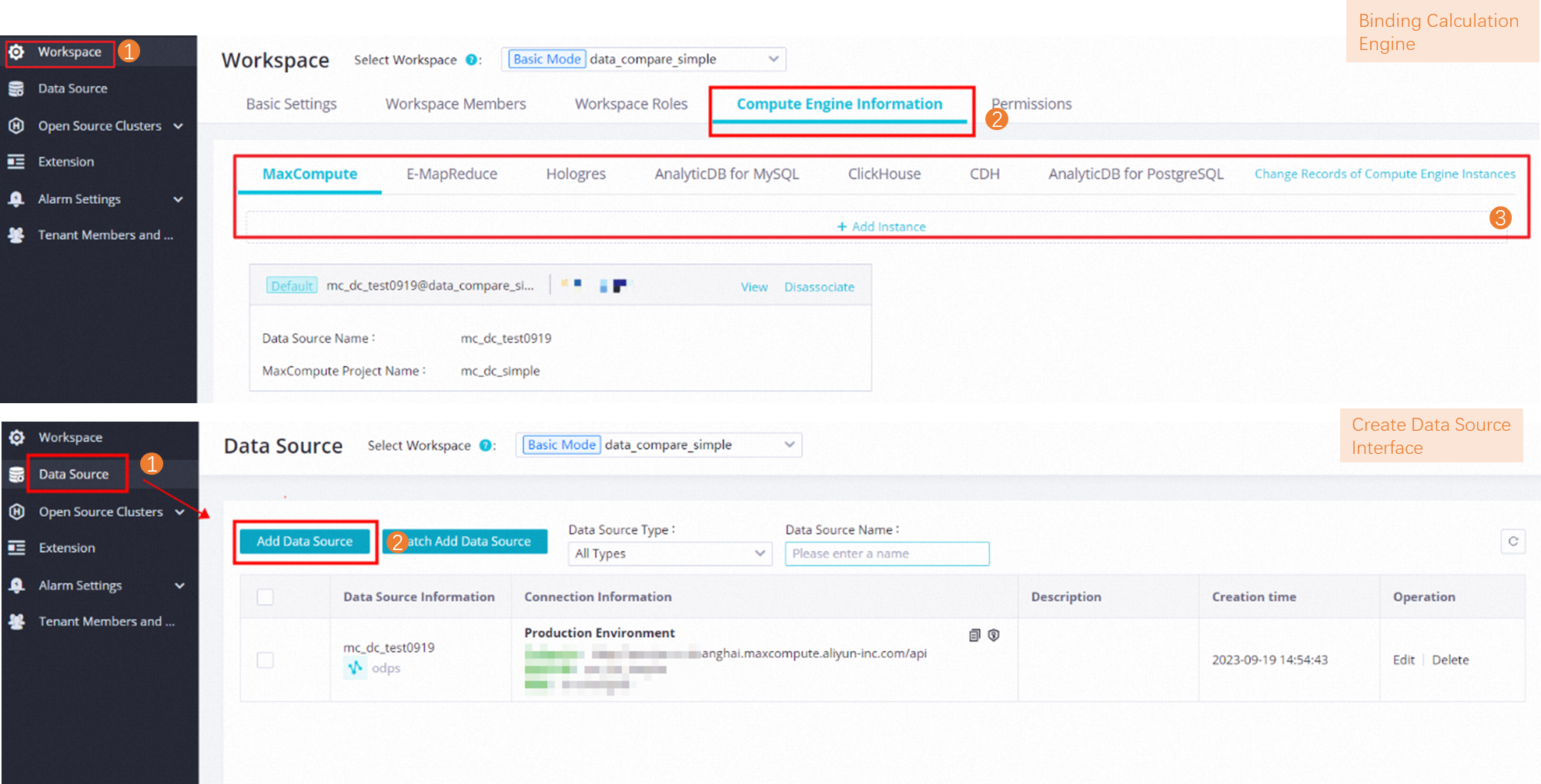
Create a compute engine: The original user interface (UI) for associating the preceding types of compute engines with a workspace as compute engine instances is no longer used. After the integration, you must reference the preceding types of data sources as compute engines. To create a compute engine, you must add a data source first.
 Note
NoteData sources that are added across regions or accounts or added by using AccessKey pairs cannot be used for data development or task scheduling. These data sources can only be used for data synchronization.
If you want to use a data source for data development, you must go to DataStudio and associate the data source with DataStudio.
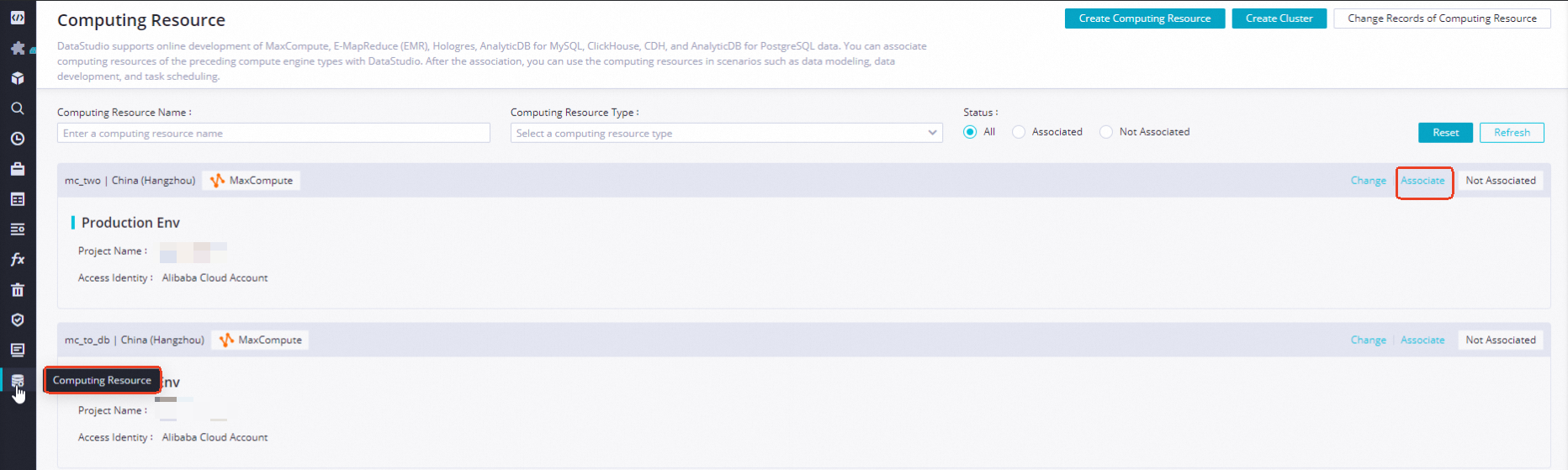
Migrate associated compute engines: The compute engines that are associated with a workspace are migrated to the Computing Resource page in DataStudio in the DataWorks console for unified management.
Edit a compute engine: You can no longer directly edit a compute engine. To edit a compute engine, you can edit the data source that is referenced as the compute engine.
Disassociate a compute engine: A workspace administrator can disassociate a compute engine from a workspace. This operation does not cause the referenced data source to be removed from DataWorks.
Integration of compute engines into open source clusters
EMR and CDH compute engines in DataWorks are integrated into open source clusters for unified management. You must take note of the following items about the preceding types of compute engines after the integration:
Create a compute engine: The original UI for associating the preceding types of compute engines with a workspace as compute engine instances is no longer used. After the integration, if you want to create one of the preceding types of compute engines, you must register a cluster of the compute engine type. After the cluster is registered, you can start data development operations.
NoteClusters that are registered across regions or accounts or registered by using AccessKey pairs cannot be used for data development or task scheduling. These clusters can only be used for data synchronization.
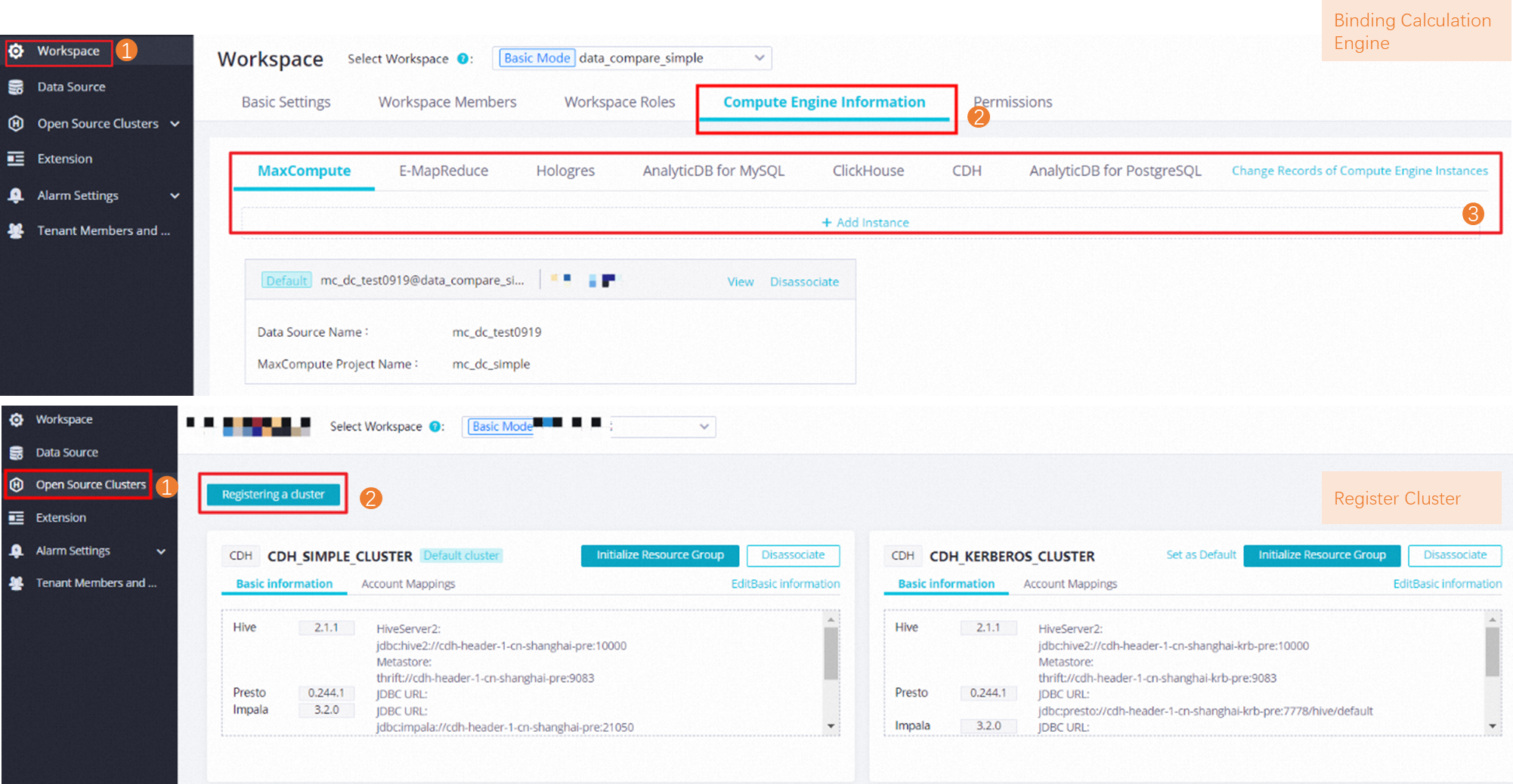
Migrate associated compute engines: The compute engines that are associated with a workspace are migrated to Open Source Clusters in SettingCenter in the DataWorks console for unified management.
Edit a compute engine: You can no longer directly edit a compute engine. To edit a compute engine, you can edit the registered cluster that is of the compute engine type.
Disassociate a compute engine: A workspace administrator can disassociate a compute engine from a workspace. This operation does not cause the registered cluster to be removed from DataWorks.
Description for permission changes
The following permission changes will apply after the integration to ensure high security:
Change on the authentication method: You can no longer add data sources to or associate compute engines with a workspace by using AccessKey pairs. You can still use an AccessKey pair to access an existing data source or compute engine. You must make sure that the AccessKey pair belongs to the Alibaba Cloud account within which the data source is added or the compute engine is associated. Data sources and compute engines that are configured by using AccessKey pairs cannot be used for data development.
Change on the default access identity: If you want to specify the task owner or an identity other than the current logon account as the default access identity of a data source or cluster, you must make sure that the account you use is attached the AdministratorAccess policy.
NoteOnly specific data sources or clusters require the default access identity. You can specify the default access identity for the data sources and clusters based on the requirements in the DataWorks console.
Addition of data sources and registration of clusters across Alibaba Cloud accounts: If you want to add a data source or register a cluster that belongs to another Alibaba Cloud account to a workspace within the current Alibaba Cloud account, you must use a RAM role to access the data source or the cluster.
If you have questions about the preceding changes, you can scan the following QR code to join the DataWorks service DingTalk group and contact technical support.
