You can deploy Kubeflow Pipelines included in the cloud-native AI suite and then use Kubeflow Pipelines to build and deploy portable and scalable machine learning workflows based on containers. This topic describes how to use Kubeflow Pipelines to create workflows and view workflows.
Prerequisites
A Container Service for Kubernetes (ACK) cluster is created. In this example, an ACK cluster that contains GPU-accelerated nodes is created. For more information, see Use the default GPU scheduling mode.
Nodes in the cluster can access the Internet. For more information, see Enable an existing ACK cluster to access the Internet.
A persistent volume (PV) and a persistent volume claim (PVC) are created. For more information, see Configure a shared NAS volume or Mount a statically provisioned OSS volume.
A Jupyter notebook is created. For more information, see Create and use notebooks.
Background information
Kubeflow Pipelines is a platform for building end-to-end machine learning workflows. Kubeflow Pipelines consists of the following components:
Kubeflow Pipelines UI: allows you to create and view experiments, pipelines, and runs.
Kubeflow Pipelines SDK: allows you to define and build components and pipelines.
Workflow Engine: executes workflows.
Kubeflow Pipelines provides the following features:
You can use the Workflow feature of Kubeflow Pipelines to build CI/CD pipelines for your machine learning projects
You can use the Experiment feature of Kubeflow Pipelines to compare and analyze how a pipeline runs with different parameters or data.
You can use the Tracking feature of Kubeflow Pipelines to record the data, code, configuration, and inputs and outputs of each release of a model.
For more information about Kubeflow Pipelines, see Kubeflow Pipelines.
Procedure
In this example, the KFP SDK and KFP Arena SDK are used to build a machine learning workflow. The Jupyter notebook is used to install the SDKs for Python, orchestrate a workflow, and submit the workflow. For more information about the KFP SDK, see Introduction to the Pipelines SDK.
Install Kubeflow Pipelines.
If the cloud-native AI suite is not installed, you must first install the cloud-native AI suite and select Kubeflow Pipelines in the Workflow section. For more information, see Deploy the cloud-native AI suite.
If the cloud-native AI suite is installed, perform the following operations:
Log on to the ACK console. In the left-side navigation pane, click Clusters.
On the Clusters page, find the cluster that you want to manage and click its name. In the left-side pane, choose .
In the Components section, find ack-ai-dashboard and ack-ai-dev-console and click Upgrade in the Actions column. Then, find ack-ai-pipeline and click Deploy in the Actions column.
Component
Description
ack-ai-dashboard
You must update the component to 1.0.7 or later.
ack-ai-dev-console
You must update the component to 1.0.13 or later.
ack-ai-pipeline
When you deploy ack-ai-pipeline, the system checks whether a Secret named kubeai-oss exists. If the kubeai-oss Secret exists, Object Storage Service (OSS) is used to store artifacts. If the kubeai-oss Secret does not exist, the pre-installed MinIO is used to store artifacts.
Run the following command to install KFP SDK for Python and KFP Arena SDK for Python.
You can use the KFP SDK to orchestrate and submit pipelines.
The KFP Arena SDK provides components that can be used out-of-the-box.
Use the following Python file to orchestrate and submit a workflow.
The workflow defines the following operations: download datasets and train a model based on the downloaded datasets.
import kfp from kfp import compiler from arena import standalone_job_op, pytorch_job_op def mnist_train_pipeline(): #The operation to download datasets to a PVC. download_op = standalone_job_op(namespace="default-group", name="download-mnist-dataset", image="kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/download-mnist-dataset:demo", working_dir="/root", data=["training-data:/mnt"], command="/root/code/mnist-pytorch/download_mnist_dataset.sh /mnt/pytorch_data") #The operation to train a model based on the datasets in the PVC and save the model data to the PVC after the training is complete. The datasets are downloaded by the download_op operation. train_op = pytorch_job_op(namespace="default-group", annotation="kubai.pipeline:test", name="pytorch-dist-step", gpus=1, workers=3, working_dir="/root", image="registry.cn-beijing.aliyuncs.com/ai-samples/pytorch-with-tensorboard:1.5.1-cuda10.1-cudnn7-runtime", sync_mode="git", sync_source='https://code.aliyun.com/370272561/mnist-pytorch.git', data=["training-data:/mnt"], logdir="/mnt/pytorch_data/logs", command="python /root/code/mnist-pytorch/mnist.py --epochs 10 --backend nccl --dir /mnt/pytorch_data/logs --data /mnt/pytorch_data/") train_op.after(download_op) #Create a client and submit data. client = kfp.Client() client.create_run_from_pipeline_func(mnist_train_pipeline, namespace="default-group", arguments={})The following table describes the parameters in the preceding sample code block.
Parameter
Required
Description
Default value
name
Yes
Specifies the name of the job that you want to submit. The name must be globally unique.
N/A
working_dir
No
Specifies the directory where the command is executed.
/root
gpus
No
Specifies the number of GPUs that are used by the worker node where the specified job runs.
0
image
Yes
Specifies the address of the image that is used to deploy the runtime.
N/A
sync_mode
No
Specifies the synchronization mode. Valid values: git and rsync. The git-sync mode is used in this example.
N/A
sync_source
No
Specifies the address of the repository from which the source code is synchronized. This parameter is used together with the --sync-mode parameter. The git-sync mode is used in this example. Therefore, you must specify a Git repository address, such as the URL of a project on GitHub or Alibaba Cloud. The source code is downloaded to the code/ directory under --working-dir. The directory in this example is /root/code/tensorflow-sample-code.
N/A
data
No
Mounts a shared PV to the runtime where the training job runs. The value of this parameter consists of two parts that are separated by a colon (
:). Specify the name of the PVC to the left side of the colon. To obtain the name of the PVC, run thearena data listcommand. This command queries the PVCs that are available for the cluster. Specify the path to which the PV claimed by the PVC is mounted to the right side of the colon, which is also the local path where your training job reads the data. This way, your training job can retrieve the data stored in the corresponding PV claimed by the PVC.NoteRun the
arena data listcommand to query the PVCs that are available for the specified cluster.NAME ACCESSMODE DESCRIPTION OWNER AGE training-data ReadWriteMany 35mIf no PVC is available, you can create one. For more information, see Configure a shared NAS volume.
N/A
tensorboard
No
Specifies that TensorBoard is used to visualize training results. You can set the --logdir parameter to specify the path from which TensorBoard reads event files. If you do not set this parameter, TensorBoard is not used.
N/A
logdir
No
Specifies the path from which TensorBoard reads event files. You must specify both this parameter and the --tensorboard parameter.
/training_logs
The following figure shows a sample success response:

View the pipeline.
In the left-side navigation pane, click Kubeflow Pipelines.
In the left-side navigation pane, click Runs. Then, click the Active tab. You can view details about a run of the pipeline.

Click the run to view the run details.
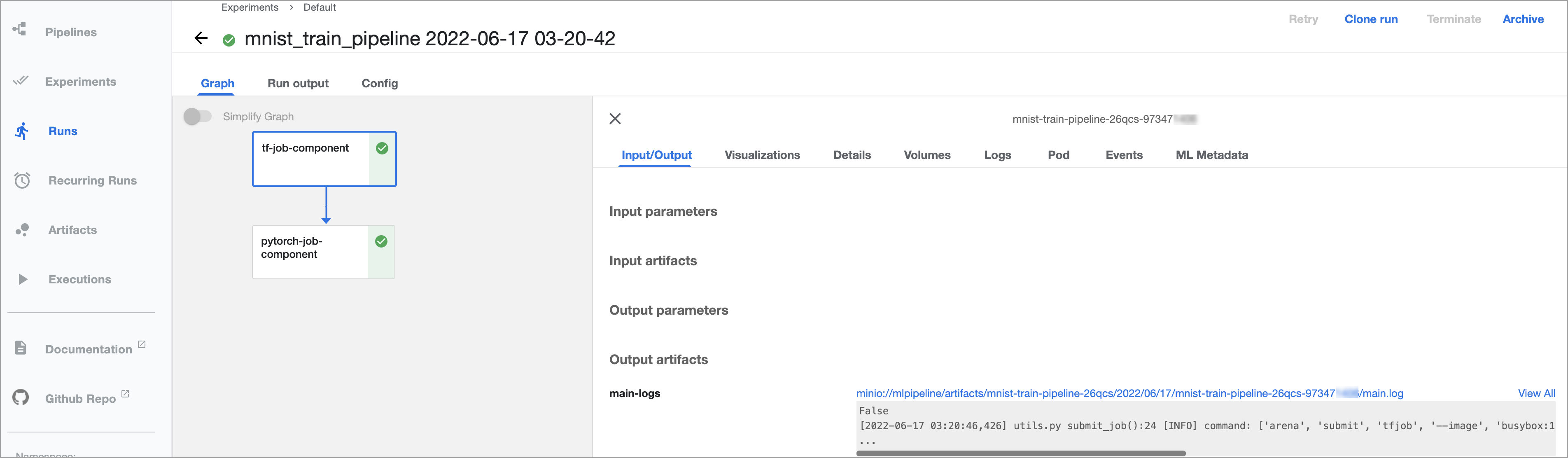
In this example, the KFP SDK and KFP Arena SDK are used.
pip install https://kube-ai-ml-pipeline.oss-cn-beijing.aliyuncs.com/sdk/kfp-1.8.10.5.tar.gzpip install https://kube-ai-ml-pipeline.oss-cn-beijing.aliyuncs.com/sdk/kfp-arena-0.1.3.tar.gz